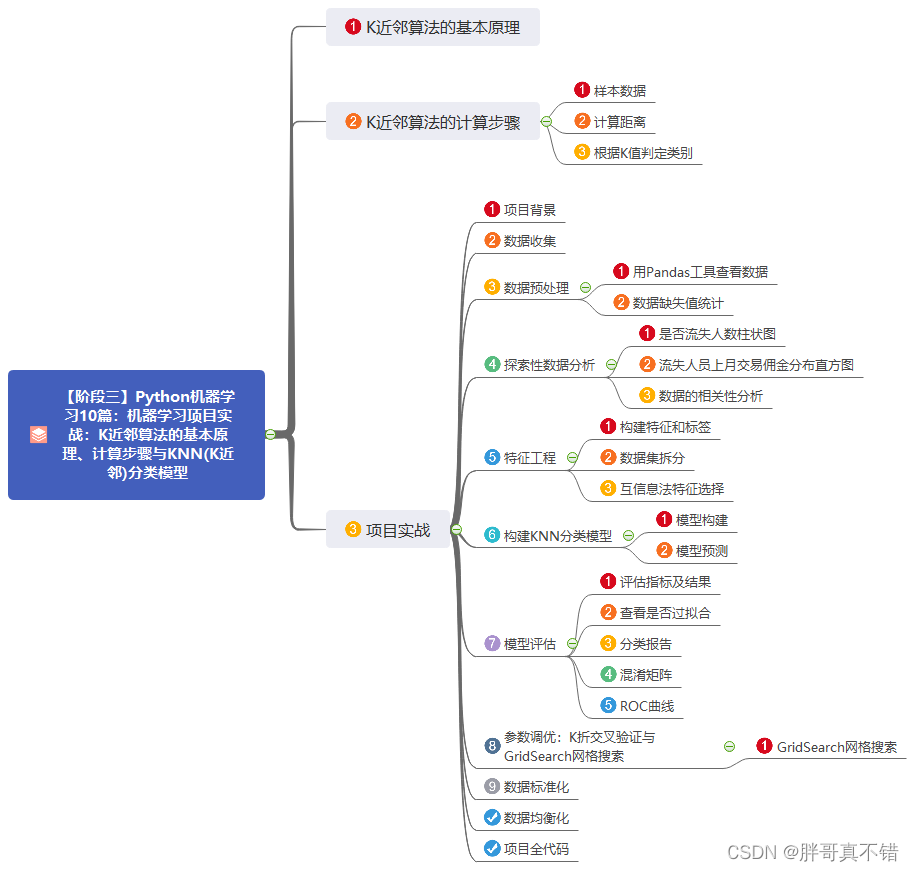
本篇的思维导图:
K近邻算法(英文为K-Nearest Neighbor,因而又简称KNN算法)是非常经典的机器学习算法。
K近邻算法的基本原理
K近邻算法的原理非常简单:对于一个新样本,K近邻算法的目的就是在已有数据中寻找与它最相似的K个数据,或者说“离它最近”的K个数据,如果这K个数据大多数属于某个类别,则该样本也属于这个类别。
以下图为例,假设五角星代表爱情片,三角形代表科幻片。此时加入一个新样本正方形,需要判断其类别。当选择以离新样本最近的3个近邻点(K=3)为判断依据时,这3个点由1个五角星和2个三角形组成,根据“少数服从多数”原则,可以认为新样本属于三角形的类别,即新样本是一部科幻片。同理,当选择离新样本最近的5个近邻点(K=5)为判断依据时,这5个
【阶段三】Python机器学习10篇:机器学习项目实战:K近邻算法的基本原理、计算步骤与KNN(K近邻)分类模型
news2026/2/15 4:22:47
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/152966.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
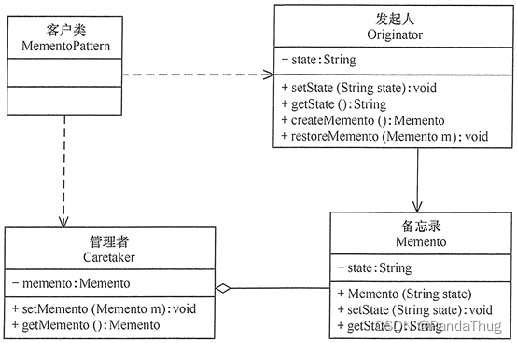
设计模式——备忘录模式
备忘录模式一、基本思想二、应用场景三、结构图四、代码五、优缺点5.1 优点5.2 缺点一、基本思想
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便以后当需要时能将该对象恢复到原先保存的状态。该模式又叫…
Bilibili支持了AV1编码,关于AV1编码你知道吗?
Bilibili支持了AV1编码,关于AV1编码你知道吗?
AV1编码是一种新的视频编码标准,由联合开发的开源编码器,它由英特尔、微软、谷歌、苹果、Netflix、AMD、ARM、NVIDIA和其他一些公司共同开发,旨在替代H.264和HEVC等现有的…

Word控件 Aspose.words for.NET 授权须知
Aspose.Words 是一种高级Word文档处理API,用于执行各种文档管理和操作任务。API支持生成,修改,转换,呈现和打印文档,而无需在跨平台应用程序中直接使用Microsoft Word。此外,
Aspose API支持流行文件格式处…

实验 2 灰度变换与空间滤波
目录实验 2 灰度变换与空间滤波一、实验目的二、实验例题1. 灰度变换函数 imadjust2. 使用对数变换压缩动态范围。3. 直方图均衡化 histogram equalization实验 2 灰度变换与空间滤波
一、实验目的
掌握灰度变换的原理和应用。掌握对数变换、幂律变换和直方图均衡化的原理和应…
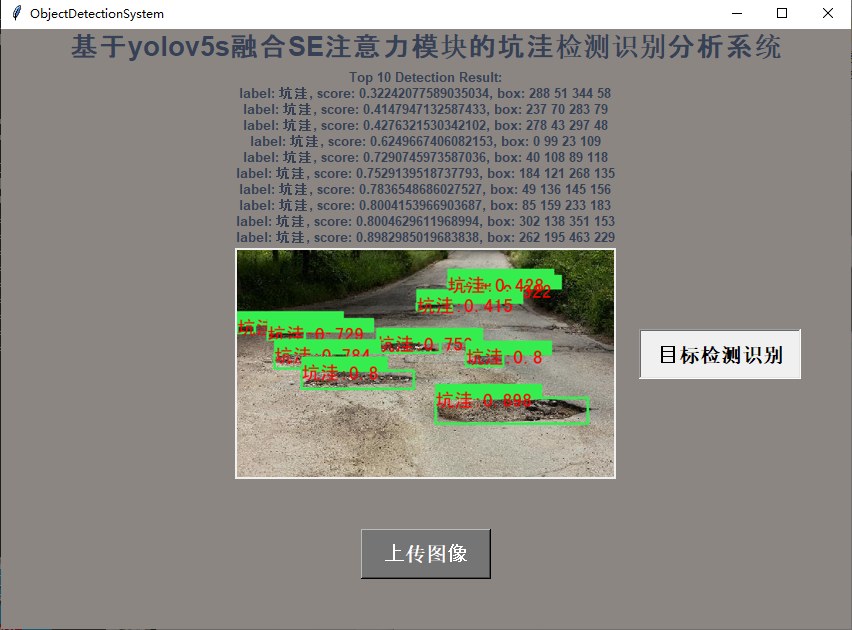
融合注意力模块SE基于轻量级yolov5s实践路面坑洼目标检测系统
在很多的项目实战中验证分析注意力机制的加入对于模型最终性能的提升发挥着积极正向的作用,在我之前的一些文章里面也做过了一些尝试,这里主要是想基于轻量级的s系列模型来开发构建路面坑洼检测系统,在模型中加入SE注意力模块,以期…
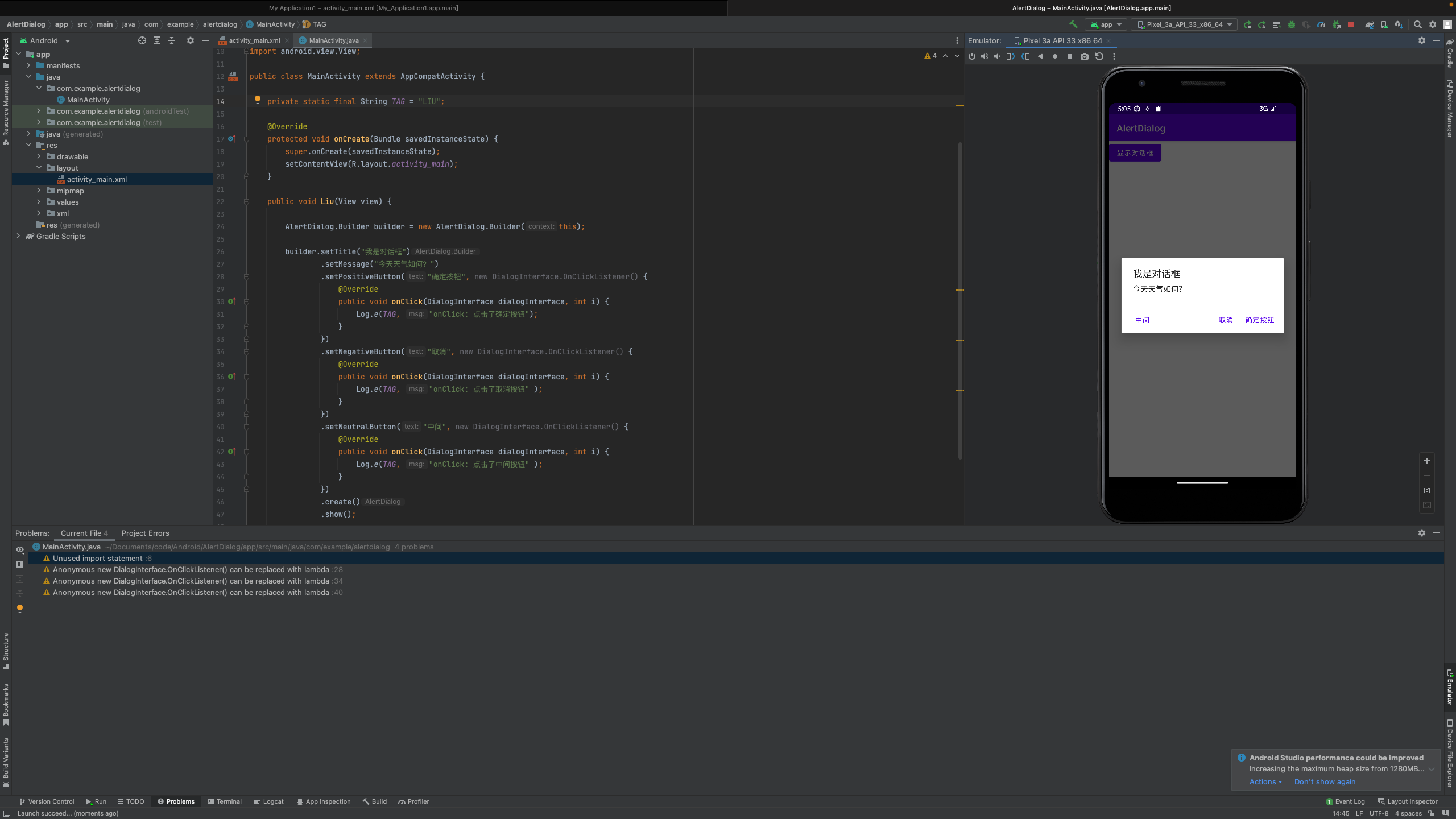
Android开发-AS学习(二)
1.5 ProgressBar常用属性描述android:max进度条的最大值android:progress进度条已完成进度值android:indeterminate如果设置为true,则进度条不精确显示进度style“?android:attr/progressBarStyleHorizontal"水平进度条MainActivity.java package c…

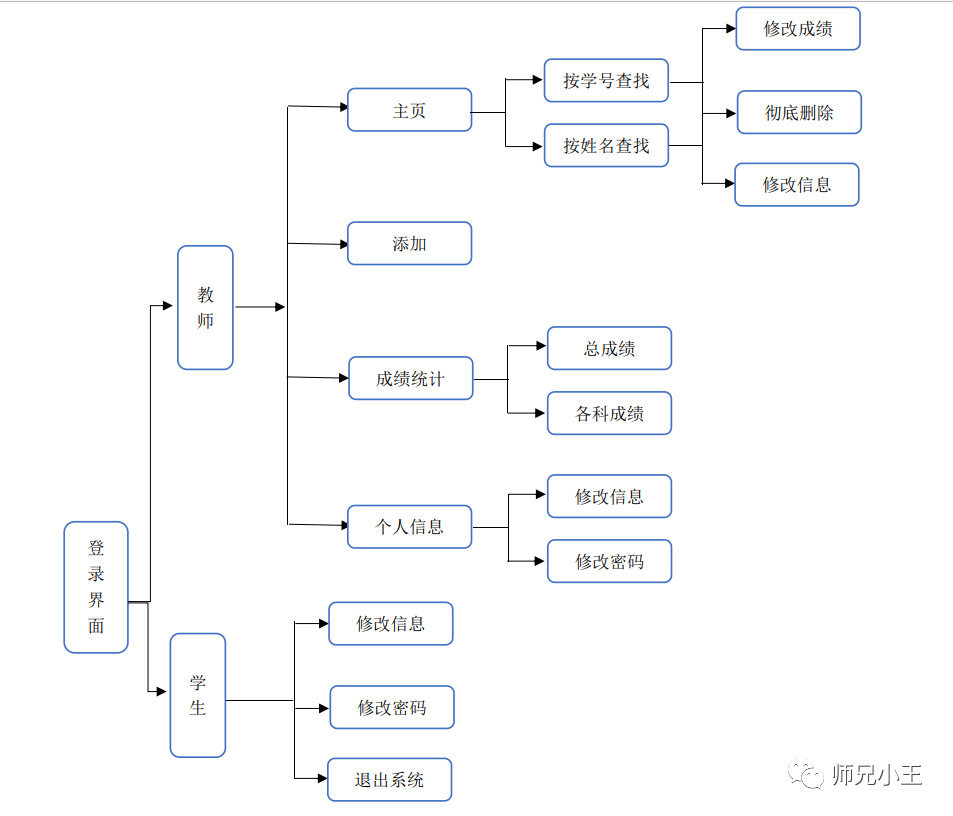
Java课程设计——学生成绩管理系统
1 需求分析1.1 需求分析概述需求分析是开发软件系统的重要环节,是系统开发的第一步和基础环节。通过需求分析充分认识系统的目标、系统的各个组成部分、各部分的任务职责、工作流程、工作中使用的各种数据及数据结构、各部门的业务关系和数据流程等, 为系…

nacos的配置管理
前言 此博客对nacos的配置管理进行简单介绍,如果降配置文件放在项目中,那么每次进行修改后都要重新编译部署项目,是极其不方便的,如果将配置文件放在一个固定的位置,尽管解决了以上的问题,但是管理起来还不…

【Java寒假打卡】Java基础-File
【Java寒假打卡】Java基础-File概述-三种构造方法绝对路径和相对路径File的创建功能File的删除功能File的判断和获取功能listFile方法练习1:在当前模块下面aaa文件夹创建一个文件a.txt练习2:删除一个多级文件夹练习3:统计一个文件夹中每一种文…

UE插件和项目目录结构学习笔记
Plugins插件的二种安装方式
1、安装到虚幻引擎(推荐) 转到虚幻引擎安装位置的插件文件夹 Engine/Plugins 将解压得到的插件文件夹放入Marketplace文件夹下(如没有新建一个)。 启动虚幻引擎打开项目,菜单->编辑->…
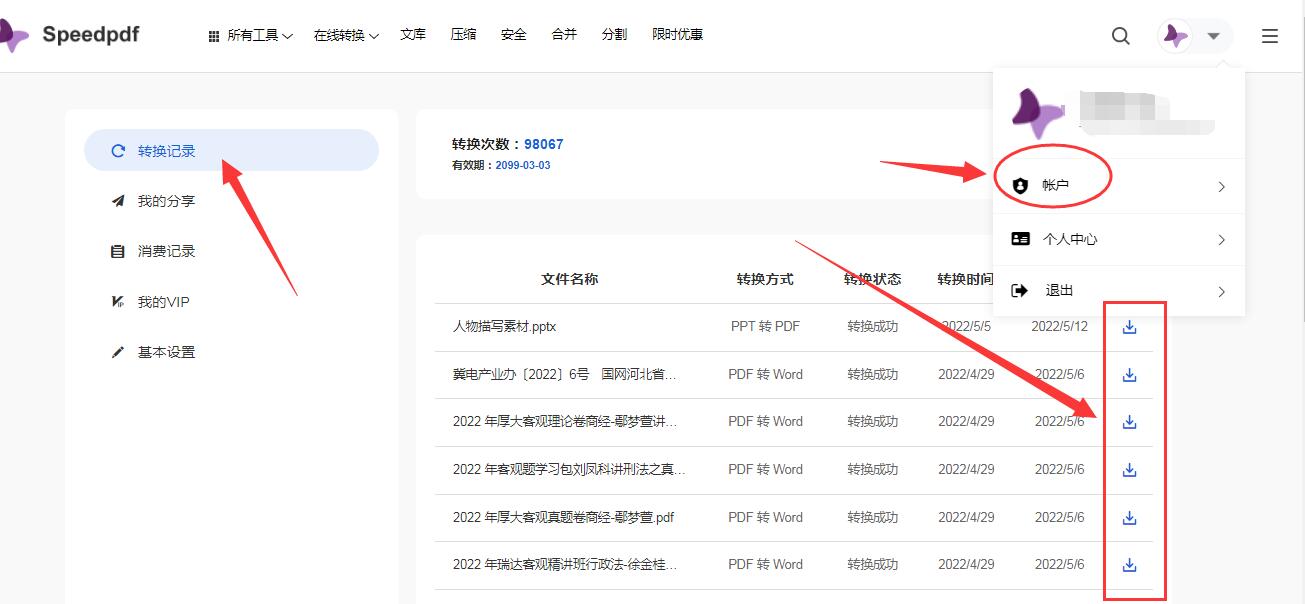
如何在线免费将PPT转PDF格式
我们经常会遇到制作演示文稿PPT的格式,但是这种格式一般在传阅的过程中稳定性都较差,所以很多人会选择转成PDF格式,那么有没有免费的处理方式呢?
打开浏览器搜索speedpdf找到并打开在线转换工具首页,选择主页上的PPT转…

Python表白妙招,把情书写进她的照片里
前言
我的好兄弟们,2022年可算是过去了,这不马上要过年了吗
就是说,各位兄弟有对象了吗,没有的回家还要面对亲戚的各种提问 退一步来说,有心仪的人吗,如果有的话,就来看看这篇 程序员的表白小…

【Vue + Koa 前后端分离项目实战7】使用开源框架==>快速搭建后台管理系统 -- part7 前端实现最新期刊管理【增删查改】
人生没有白走的路,每一步都作数。 对应后端部分章节回顾:
【Vue Koa 前后端分离项目实战5】使用开源框架>快速搭建后台管理系统 -- part5 后端实现最新期刊列表管理【增删查改】_小白Rachel的博客-CSDN博客 效果展示: 目录
一、…
少儿Python每日一题(15):回文数
原题解答
本次的题目如下所示: 【编程实现】 回文数是指一个像14641这样“对称”的数,即:将这个数的各位数字按相反的顺序重新排列后,所得到的数和原来的数一样。请编程求不同位数数字的回文数的个数。用户输入一个正整数M(2<M<7),M作为回文数的位数。要求输出M位…

【Javascript】高阶函数,JSON
❤️ Author: 老九 ☕️ 个人博客:老九的CSDN博客 🙏 个人名言:不可控之事 乐观面对 😍 系列专栏: 文章目录高阶函数箭头函数apply函数JSON高阶函数
把函数作为参数,或者返回一个函数ÿ…

【并发】并发锁机制-深入理解synchronized(一)
【并发】并发锁机制-深入理解synchronized(一)
synchronized 基础篇(使用)
一、Java共享内存模型带来的线程安全问题
1. 代码示例
2. 运行结果
3. 问题分析
4. 临界区(Critical Section)
5. 竞态条件…
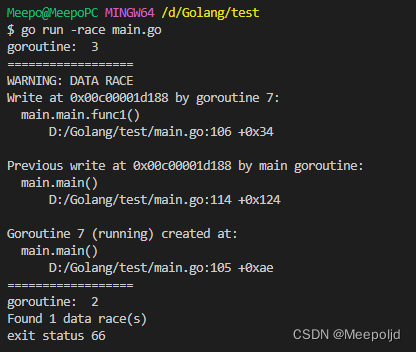
【Go】内存模型中的内存可见性
前言
使用go必然会使用到协程以及其他的并发操作,初期学习的时候,经常在启动协程时操作变量出现问题,要么就是变量没更新,要么就是各种崩溃,或者vscode报告警之类的,于是浅看了一下Go的内存模型࿰…

离散制造业ERP系统对生产物料管理有哪些帮助?
在离散制造企业生产加工过程中,生产物料管理是一个至关重要的环节。车间物料能不能管控好,影响着整个产品的品质、工作效率及制造成本的控制等。离散制造业通常需要品类、属性繁多的原材料和配套件,而各类物料的及时供应十分重要;…

优思学院|QCC 是什么意思?有什么用?
QCC 的中文意思是质量控制圈,也有人称为品质圈。
质量控制圈(QCC)是来自日本的一种质量管理方法,这个概念的作者是石川馨、日本科学家和工程师联盟(JUSE)共同发明。 QCC的方法是建立由5-11名成员组成的小团…