引言:探索文本分类中的个性化示例数量
在自然语言处理(NLP)领域,预测模型已经从零开始训练演变为使用标记数据对预训练模型进行微调。这种微调的极端形式涉及到上下文学习(In-Context Learning, ICL),其中预训练生成模型的输出(冻结的解码器参数)仅通过输入字符串(称为指令或提示)的变化来控制。ICL的一个重要组成部分是在提示中使用少量标记数据实例作为示例。尽管现有工作在推理过程中对每个数据实例使用固定数量的示例,但本研究提出了一种根据数据动态调整示例数量的新方法。这类似于在k-最近邻(k-NN)分类器中使用可变大小的邻域。 该研究提出的自适应ICL(Adaptive ICL, AICL)工作流程中,在特定数据实例上的推理过程中,通过分类器的Softmax后验概率来预测使用多少示例。这个分类器的参数是基于ICL中正确推断每个实例标签所需的最佳示例数量来拟合的,假设与训练实例相似的测试实例应该使用相同(或接近匹配)的少量示例数量。实验表明,AICL方法在多个标准数据集上的文本分类任务中取得了改进。
论文标题:
‘One size doesn’t fit all’: Learning how many Examples to use for In-Context Learning for Improved Text Classification
论文链接:
https://arxiv.org/pdf/2403.06402.pdf
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
理解在上下文学习中使用示例的动机
上下文学习(In-Context Learning, ICL),通过改变输入字符串(称为指令或提示)来控制预训练生成模型(冻结的解码器参数)的输出。ICL的一个重要组成部分是在提示中使用少量标记数据实例作为示例。
动机来源于信息检索(IR),不同的查询由于信息需求的固有特性或查询的制定质量,表现出不同的检索性能。将IR中的查询类比为ICL中的测试实例,以及将本地化示例视为潜在相关文档,假设某些测试实例与训练示例的关联更好(即包含它们作为提示的一部分可以导致正确预测),因此包含少量示例就足够了。另一方面,某些测试实例作为查询的检索质量不佳,因此需要进一步查看排名列表以收集有用的示例。这意味着需要替换查询与文档相关性的概念,以及测试实例对示例的下游有用性。
选择可变数量的本地化示例的想法也类似于为k-NN分类选择可变大小的邻域,关键是同质邻域可能只需要相对较小的邻域就能做出正确预测,而非同质邻域可能需要更大的邻域。这个想法可以应用于ICL,其中一个测试实例如果与多个具有冲突标签的训练实例相似,可能需要更多的示例。

上下文学习(ICL)方法介绍
1. ICL的定义和工作原理
上下文学习(ICL)与监督学习不同,不涉及在标记示例上训练一组参数θ。相反,后验概率是以下因素的函数:a) 输入测试实例的文本,b) 预训练LLM的解码器参数,c) 提示指令,d) 可选的一组k个输入示例(通常称为k-shot学习)。在这里,与监督设置不同,函数f没有参数化表示,可以使用带有梯度下降的训练集进行学习。函数本身依赖于预训练的LLM参数,当前输入的标签预测,以及由Nk(x)表示的k个文本单元组成的提示。
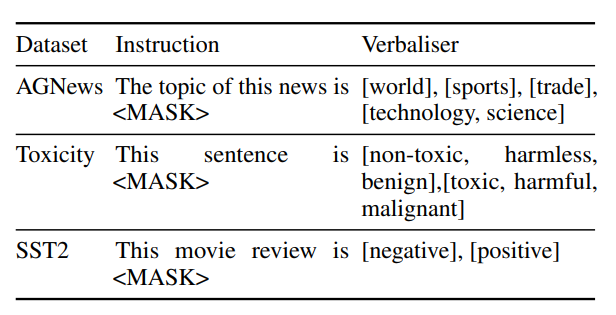
由于LLM的解码器生成一系列单词w1, ..., wl(l是序列的最大长度),类别后验概率通过将p个可能的类别映射到p组不同的等效单词集V(y)来计算,其中y ∈ Zp,这些集合通常称为verbalisers。
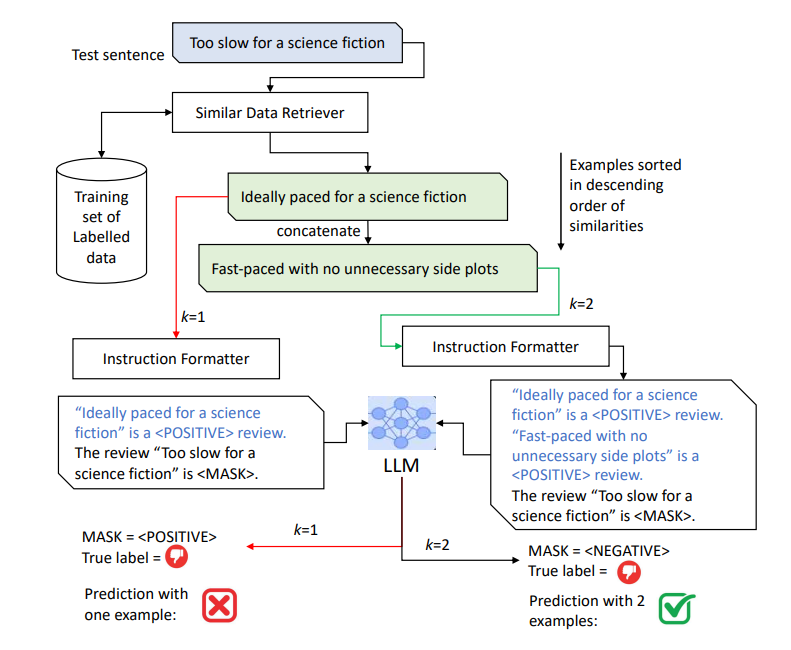
2. ICL中的示例选择和其重要性
ICL的一个最重要的组成部分是搜索组件,它输出训练集中与当前实例相似的top-k候选集。虽然原则上可以在提示中包含来自训练集的随机示例,但已经证明本地化示例(即与当前实例主题相似的示例)可以提供更好的性能。
上下文学习中的自适应(AICL)
1. AICL的动机和理论基础
自适应在上下文学习(Adaptive In-Context Learning,简称AICL)的动机源自信息检索(IR)领域的实践,其中不同的查询由于信息需求的固有特性或查询的构造方式而表现出不同的检索性能。类似地,在自然语言处理(NLP)中,特定的测试实例在使用上下文学习(In-Context Learning,简称ICL)时,可能会因为训练示例的选择而影响预测结果。AICL的理论基础与k-最近邻(k-NN)分类器中使用可变大小邻域的概念相似,即对于同质的邻域,可能只需要较小的邻域就能做出正确的预测,而对于非同质的邻域,则可能需要更大的邻域。AICL的目标是动态地适应每个数据实例所需的示例数量,以提高文本分类任务的性能。
2. AICL工作流程
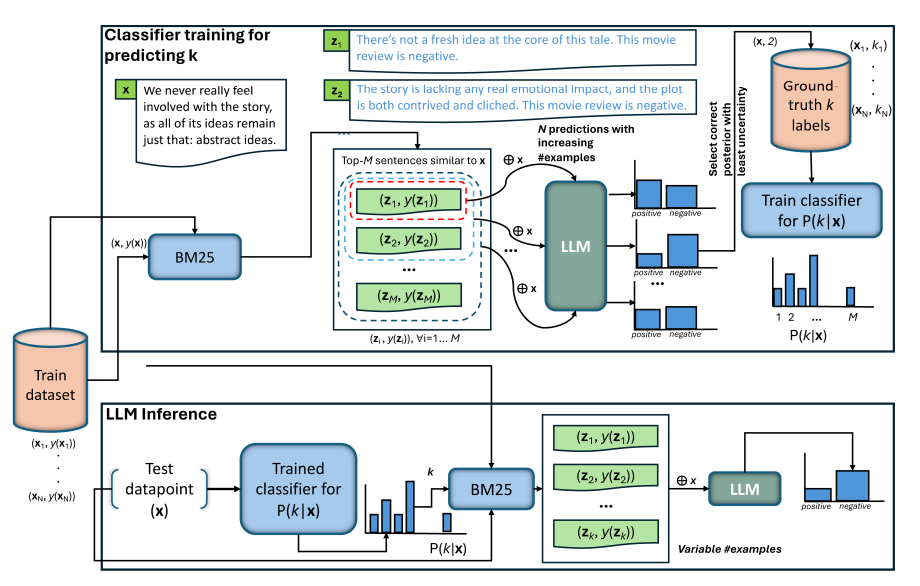
ICL的工作流程包括两个主要阶段:训练和推理。在训练阶段,首先对训练集中的每个实例执行k-shot推理,逐步增加k的值,然后基于一些标准(例如最少示例数量导致正确预测)来确定最佳的示例数量。这个最佳示例数量随后用于训练一个分类器,该分类器能够根据训练数据中的相似实例预测测试实例所需的示例数量。在推理阶段,给定一个测试实例,首先使用训练好的分类器预测所需的示例数量,然后将这些示例作为额外上下文输入到预训练的语言模型(LLM)中,以进行下游任务的预测。
3. 选择示例数量的方法
选择示例数量的方法是通过监督学习来解决的。对于训练集中的每个实例,首先使用逐渐增加的示例数量进行k-shot推理,然后根据一些启发式标准(例如最小示例数量或分类置信度)来确定理想的示例数量。这些理想的示例数量随后用于训练一个分类器,该分类器能够泛化到未见过的数据上,预测测试实例所需的示例数量。

实验设计与数据集
1. 使用的数据集和任务说明
实验使用了三个文本分类数据集:AGNews、Jigsaw Toxic Comment和SST2。AGNews是一个主题分类数据集,包含来自网络的新闻文章,分为世界、体育、商业和科技四个类别。Jigsaw Toxic Comment数据集包含从维基百科的讨论页中提取的评论,这些评论被人类评估者按照六个代表有害行为的类别进行了注释。SST2是一个情感分析数据集,包含从电影评论中提取的句子,用于二元分类任务。
2. AICL的不同变体和比较方法
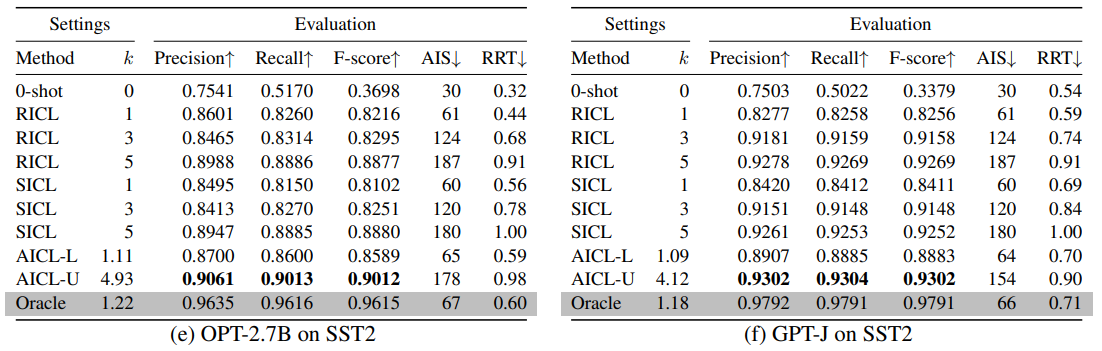
AICL的变体包括AICL-L和AICL-U,分别应用最小示例数量和基于置信度的启发式来训练预测示例数量的分类器。此外,还比较了0-shot、静态ICL(SICL)和随机ICL(RICL)方法。SICL使用固定数量的示例作为输入,而RICL使用从训练集中随机采样的固定数量的示例。这些方法的性能通过精确度、召回率和F分数等指标进行评估,并考虑了平均输入大小(AIS)和相对运行时间(RRT)作为效率指标。


实验分析
1. AICL与其他基线方法比较
实验结果表明,自适应上下文学习(AICL)方法在文本分类任务上优于静态ICL(SICL)和随机ICL(RICL)等基线方法。AICL通过动态调整用于推断的示例数量,避免了非相关(无用)示例的负面影响。AICL学习了主题内容与所需上下文量之间的潜在关系,有效地指导了解码器输出的正确方向。
2. AICL在不同数据集上的表现
在AGNews、Toxicity和SST2等标准数据集上的实验显示,AICL在不同的文本分类任务中均表现出色。例如,在AGNews数据集上,AICL的平均精度、召回率和F分数均超过了SICL和RICL。这表明AICL能够自动适应特定领域,而无需进行领域特定的调整。
3. AICL的效率和准确性分析
AICL不仅在准确性上表现出色,而且在效率上也有所提升。AICL能够使用更少的输入大小(平均k值和AIS值),这意味着在与SICL相匹配的示例数量下,AICL的计算速度更快。此外,AICL与测试集标签访问的oracle方法相比,仅在有效性和效率上略有落后,尤其是在主题分类和电影评论检测任务(AGNews和SST2)上。
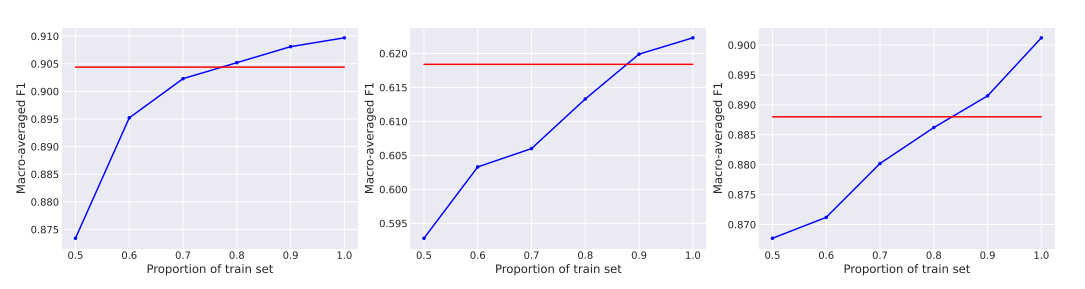
AICL的实际应用
1. 训练κ分类器的实际性
训练κ分类器以预测测试实例的理想示例数量可能在大型训练数据集上不切实际。然而,实验表明,使用训练数据的80%就足以超过SICL的性能,这表明κ分类器可以在较小的数据集上有效地训练。
2. AICL在不同训练数据规模下的表现
在不同比例的训练数据上进行的实验表明,即使在训练数据较少的情况下,AICL也能够保持良好的性能。这为在资源受限的环境中部署AICL提供了可能性,同时也表明AICL对训练数据的规模不太敏感。
结论与未来展望
1. AICL方法总结
本研究提出了一种新颖的自适应上下文学习(Adaptive In-Context Learning, AICL)方法,旨在改进文本分类任务的性能。AICL方法的核心思想是动态调整用于推理的示例数量,而不是在所有测试实例中使用固定数量的示例。这种方法类似于k-最近邻(k-NN)分类器中使用可变大小的邻域。通过预测每个测试实例所需的示例数量,AICL能够根据数据本身的特性来调整示例的数量,从而提高预测的准确性和运行时效率。
实验结果表明,AICL在多个标准数据集上的文本分类任务中,相比静态上下文学习(Static ICL, SICL)方法,能够取得更好的效果。AICL通过学习训练集中每个实例所需的最佳示例数量,并将这一信息泛化到未见过的数据上,从而实现了对测试实例的有效推理。此外,AICL在计算效率上也表现出色,因为使用较少的示例可以减少输入字符串的长度,从而缩短解码时间。
2. 未来展望
未来的研究将探索自适应上下文学习(AICL)方法的其他潜在改进方向,例如调整语言模型的提示模板和口令(verbaliser)。此外,研究将考虑如何在不同的任务和数据集上进一步优化AICL方法,以及如何将AICL与其他类型的学习策略(例如主动学习或元学习)结合起来,以提高模型的泛化能力和适应性。
考虑到在大型训练数据集上进行语言模型推理可能在实践中不太可行,未来的工作还将探讨如何在较小的数据集上有效地训练κ分类器。初步的实验结果表明,使用训练数据的80%就足以超过静态上下文学习(SICL)的性能,这为在资源受限的情况下训练κ分类器提供了可能性。
总之,AICL方法为自然语言处理中的上下文学习提供了一种有效的改进策略,未来的研究将继续在这一方向上深入探索,以实现更加智能和高效的文本处理能力。











![[精选]通义灵码做活动,送挺多礼品,快来薅羊毛!!!](https://img-blog.csdnimg.cn/direct/5f3e5baa90ad4378b07facdc9badeba3.jpeg)
