🔥博客主页: A_SHOWY
🎥系列专栏:力扣刷题总结录 数据结构 云计算 数字图像处理 力扣每日一题_
1.安装pytorch以及anaconda配置


尽量保持默认的通道,每次写指令把镜像地址写上就行。
defaults优先级是最低的,如果添加了新的通道,会先去新添加的里面找有没有想要的包,没有的话就去defaults里再找。



PyCharm添加Anaconda中的虚拟环境,Python解释器出现Conda executable is not found
PyCharm添加Anaconda中的虚拟环境,Python解释器出现Conda executable is not found-CSDN博客![]() https://blog.csdn.net/s1hjf/article/details/128759758?ops_request_misc=%7B%22request%5Fid%22%3A%22167612835216800213082077%22%2C%22scm%22%3A%2220140713.130102334..%22%7D&request_id=167612835216800213082077&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-2-128759758-null-null.142^v73^pc_search_v2,201^v4^add_ask,239^v1^insert_chatgpt&utm_term=conda excutable is not found&spm=1018.2226.3001.4187
https://blog.csdn.net/s1hjf/article/details/128759758?ops_request_misc=%7B%22request%5Fid%22%3A%22167612835216800213082077%22%2C%22scm%22%3A%2220140713.130102334..%22%7D&request_id=167612835216800213082077&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-2-128759758-null-null.142^v73^pc_search_v2,201^v4^add_ask,239^v1^insert_chatgpt&utm_term=conda excutable is not found&spm=1018.2226.3001.4187
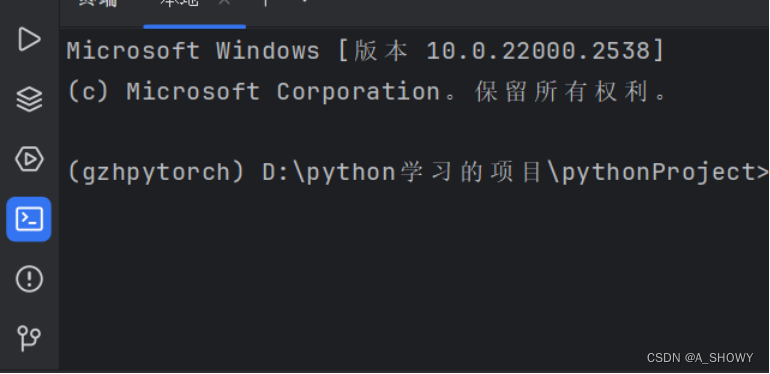
这个终端设置以后,点击可以出来anaconda的命令行
下载新的项目的时候,在pycharm里打开项目,然后点击文件-设置-项目-python解释器-添加解释器
有的项目里会有requirements文件,点进去会非常智能的弹出来install requirements,然后就把所有需要的包装上了。
直接运行项目,看哪个包不存在报错,然后打开anaconda命令行先activate然后再conda install 包名,有时候不行可能因为包名不是这个,就把conda install 包名复制到必应搜索是什么复制过去安装就行。有时候conda install找不到但是pip install能找到。
还有一种方法打开项目文件然后找到路径复制进命令行窗口(前面输入一个cd/d )(cd不能跨盘使用),然后再输入下面的pip install -r requirements.txt


就会把所有需要的包都安装上

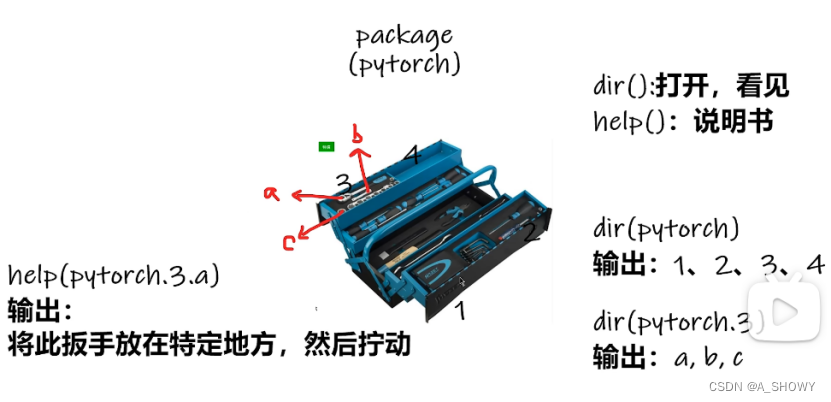
help函数看到官方的解释文档
2.pytorch加载数据
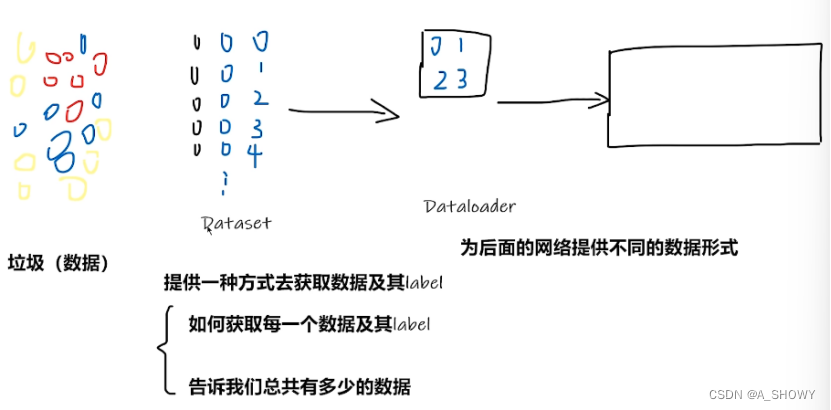
Dataset提供一种方式去获取数据及其label
Dataloader为后面的网络提供不同的数据形式
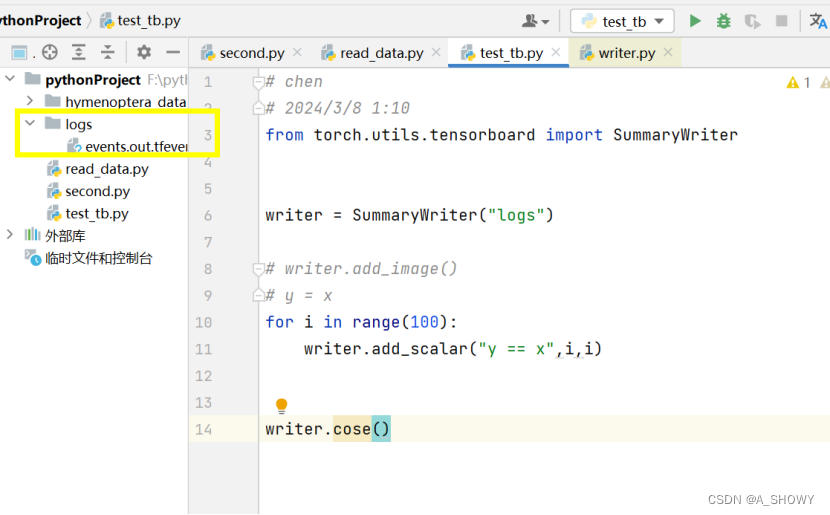
3.Tensorboard的使用
tensorboard --logdir=logs --port=6007要是想打开网页就不能ctrl+c停止,终端要一直运行着
在tensorboard显示需要tensor图片类型
![]()
这里要指定文件夹,不然会自动出来runs文件夹,这样的话要写--logdir=runs(事件文件所在文件夹名称)才可以。
#Tendorboard

自定义端口

4.Transform的使用
transform的结构和用法
# chen
# 2024/3/10 17:10
from PIL import Image
from torchvision import transforms
#python的用法——》tensor数据类型
#transforms两个左行
#1.transforms如何使用
#2.为什么需要tensor 的数据类型
img_path = "F:\\pythonLearn\\pythonProject\\hymenoptera_data\\train\\ants\\7759525_1363d24e88.jpg"
img = Image.open(img_path)
print(img)#<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x333 at 0x24347D59F60>
#1怎么用
tensor_1 = transforms.ToTensor()
tensor_img = tensor_1(img)
print(tensor_img)
#2.为什么用
# 包装了一些反向神经网络一些理论的参数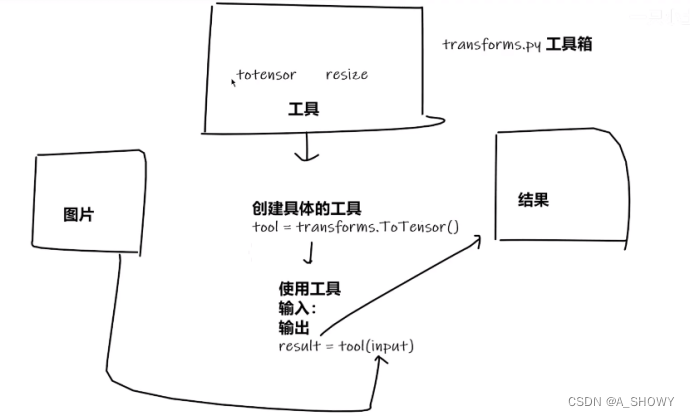
image_path="dataset/train/ants_image/0013035.jpg"
img=Image.open(image_path)
tensor_trans=transforms.ToTensor()
# 创建了一个实例,并把实例赋值给了tensor_trans
tensor_img=tensor_trans(img)
# 一个类定义了 __call__ 方法,那么该类的实例可以像函数一样被调用,就不用用.来调用了
应用到tensorboard
#应用到tensorboard
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
image_path = "hymenoptera_data/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
tensor_1 = transforms.ToTensor()
tensor_img = tensor_1(img_PIL)
writer.add_image("test",tensor_img)常见的transform

Call的用法
不用加点调用函数,就是方便
# chen
# 2024/3/11 15:55
class Person:
def __call__(self, name):
print("__call__" + "hello" + name)
def sayhello(self,name):
print("hello" + name)
person = Person()
person("zhangsan")
person.sayhello("lisi")Normalize方法

主要是关注输入输出类型,多看官方文档,
关注方法需要什么参数(有等于号的就是默认的可以不写的参数),
输出不知道的时候可以直接print(img)或者print(type(img))就会出来数据类型
# chen
# 2024/3/8 1:10
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
image_path = "hymenoptera_data/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
#tosonser的使用
tensor_1 = transforms.ToTensor()
tensor_img = tensor_1(img_PIL)
writer.add_image("test",tensor_img)
writer.close()
#normalize方法
print(tensor_img[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(tensor_img)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
writer.close()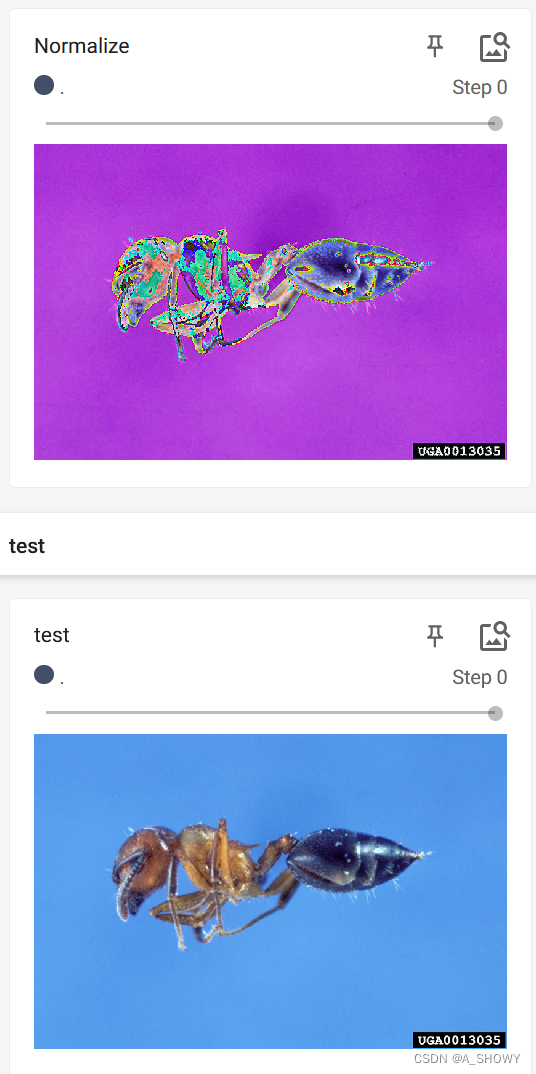
resize的使用
#resize方法
print(img_PIL.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img_PIL)
#转成tonser去tensorboard看
img_resize = tensor_1(img_resize)
print(img_PIL.size)
writer.add_image("Resize",img_resize)
writer.close()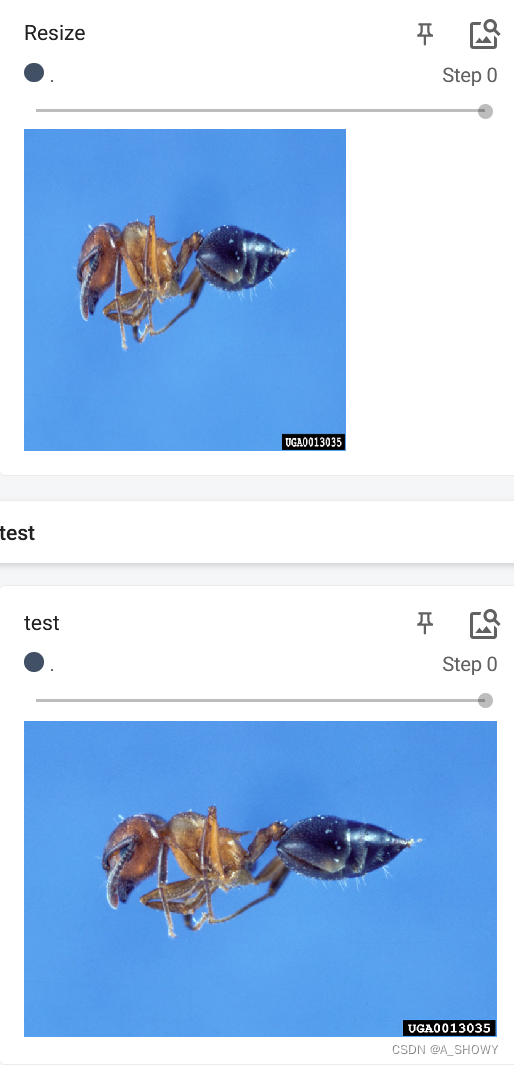
resize2-compose的使用
#compose___Resize2
trans_resize_2 = transforms.Resize(512)
trans_comp = transforms.Compose([trans_resize_2,tensor_1])#一个是刚创建的对象,一个是tosensor的对象,后一个的输入和前一个的输出一定匹配
img_com = trans_comp(img_PIL)
writer.add_image("Compose",img_com,0)
writer.close()随机裁剪
#randomCrop随机裁剪
trans_random = transforms.RandomCrop(512)
trans_comp_2 = transforms.Compose([trans_random,tensor_1])#先随机裁剪,再转为tensor
for i in range(10):
img_crop = trans_comp_2(img_PIL)
writer.add_image("randomCrop",img_crop,i)
writer.close()5.Torchvision中数据集的使用
可以按住ctrl放在CIFAR10上面
![]()
,然后去原始文件里找下载路径,放到迅雷里下载,download一直设置为True就行。下载好了把压缩包复制到自己创建的文件夹下(这个文件夹要和代码里写的名字一样),运行python会自动解压校验。
# chen
# 2024/3/12 11:32
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_tran = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Resize(512)])
train_set = torchvision.datasets.CIFAR10(root = "./dataset",train = True,transform=dataset_tran,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train = False,transform=dataset_tran,download=True)
print(test_set[0])
writer = SummaryWriter("p10")
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()6.Dataloader的使用
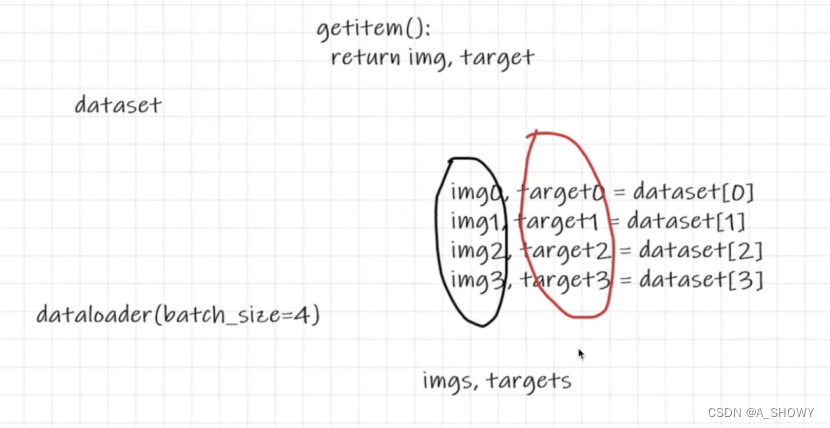
Dataset像一摞扑克牌,dataloader就是一次取出一组扑克牌
test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
batch_size就是一次取出多少张图片,shuffle就是每次要不要打乱顺序,drop就是要不要舍弃余数。
imgs和targets都是被打包的。
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10(root = "./dataset",train = False,transform=torchvision.transforms.ToTensor(),download=True)
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)#在数据集中,每次取四个打乱数据集打包
#测试数据集中第一张图片及target
img,target = test_data[0]
# print(img.shape)
# print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("epoch2:{}".format(epoch),imgs,step)
step = step + 1
writer.close()
每次取的四张图片,3通道32×32的图片,对target在进行打包
7.神经网络的基本骨架-nn.Module的使用
Neural-network
卷积操作
import torch.nn.functional as F
output3=F.conv2d(input,kernel,stride=1,padding=1)
这个kernel是卷积核,stride是卷积核每次移动的步数,padding是是否对input进行填充,padding=1就是对input上下左右都填充一行,默认填充值是0
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
#torch类型是shape的转换
input = torch.reshape(input,(1,1,5,5))#一个图像所以batch是1,二维矩阵通道数也是1
kernel = torch.reshape(kernel,(1,1,3,3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input,kernel,stride=1)
print(output)8.卷积层
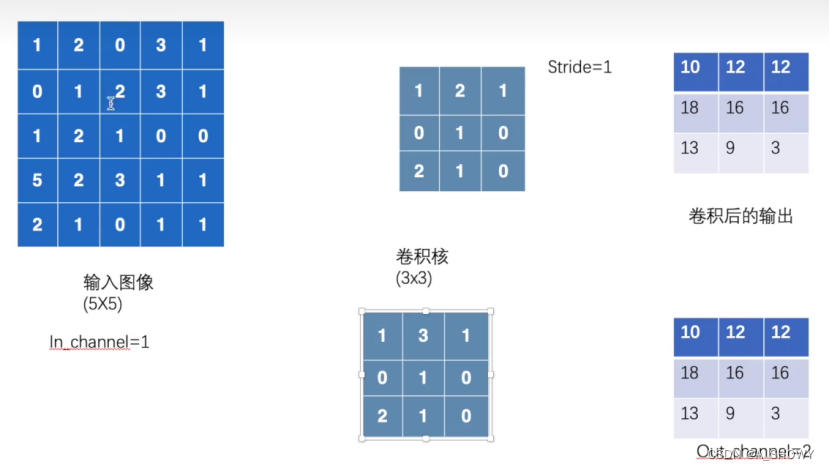
两个卷积核->两个输出通道
6个channel不会显示了
import torchvision
import torch
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("..\data",train = False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Guozi(nn.Module):
def __init__(self):
super(Guozi,self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x = self.conv1(x)
return x
guozi = Guozi()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs,target = data
output = guozi(imgs)
print(imgs.shape)
print(output.shape)
writer.add_images("input",imgs,step)
output = torch.reshape(output,(-1,3,30,30))#6个channel不会显示了,转换一下
writer.add_images("output",output,step)
step = step + 1
writer.close()9.最大池化的使用
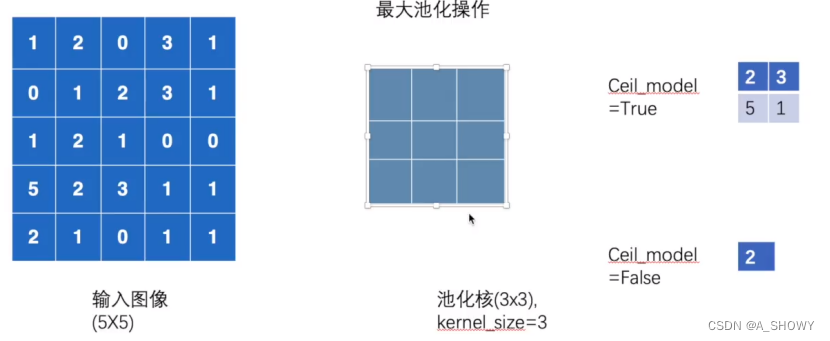
Ceil_model是True就保留不足九个的那块的最大值,默认是False的
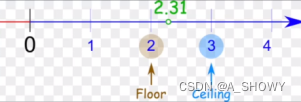
相当于把参数数量变小了,但是还保留特征
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("chihua",train = False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Guozi(nn.Module):
def __init__(self):
super(Guozi,self).__init__()
self.maxPool1 = MaxPool2d(kernel_size=3,ceil_mode=False)
def forward(self,input):
output = self.maxPool1(input)
return output
guozi2 = Guozi()
writer = SummaryWriter("logs2")
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = guozi2(imgs)
writer.add_images("output",output,step)
step = step + 1
writer.close()
10.非线性激活(提高泛化能力)
(常用Sigmoid(雅俗灰度范围),Relu:输出图像灰度大于0 的部分)

建议第二种,防止数据丢失(默认就是false)
11.tensor数据类型
张量
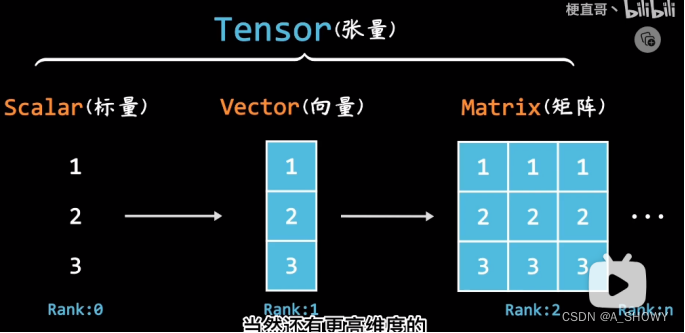
学numpy
12.线性层及其它层介绍
self.linear1=Linear(in_features=196608,out_features=10) #这是一个vgg16model
# output=torch.reshape(imgs,(1,1,1,-1)) #这个-1是让他根据前面设置的参数自动计算
# 也可以用torch.flatten()
output=torch.flatten(imgs)
class Guozi(nn.Module):
def __init__(self):
super(Guozi,self).__init__()
self.linear1 = Linear(196608,10)
def forward(self,input):
output = self.linear1(input)
return output
guozi = Guozi()
for data in dataloader:
imgs,target = data
print(imgs.shape)
#想变成1* 1 *1 * %的形式
output = torch.reshape(imgs,(1,1,1,-1))
print(output.shape)
output = guozi(output)
print(output.shape)
# output = torch.reshape(imgs,(1,1,1,-1))
output = torch.flatten(imgs)#flatten,把输入的数据展成一行

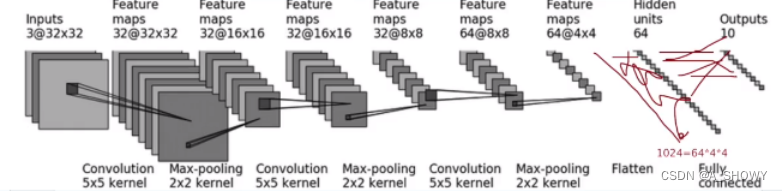
13.sequential的使用和搭建小实战
import torch
from torch import nn
from torch.nn import MaxPool2d, Flatten, Linear,Conv2d
class Guozi(nn.Module):
def __init__(self):
super(Guozi,self).__init__()
self.conv1 = Conv2d(3,32,5,padding = 2)
self.maxpool = MaxPool2d(2)
self.conv2 = Conv2d(32,32,5,padding=2)
self.maxpool2 = MaxPool2d(2)
#这里有一个公式,如果尺寸不变,padding = (f -1)/2,f是kernel
self.conv3 = Conv2d(32,64,5,padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.Liner1 = Linear(1024,64)
self.Liner2 = Linear(64,10)
def forward(self,x):
x = self.conv1(x)
x = self.maxpool(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.Liner1(x)
x = self.Liner2(x)
return x
guozi = Guozi()
print(guozi)
#检验网络结构
input = torch.ones((64,3,32,32))
output = guozi(input)
print(output.shape)
画的那是两个线性层

用sequential可以简化
class Guozi(nn.Module):
def __init__(self):
super(Guozi,self).__init__()
# self.conv1 = Conv2d(3,32,5,padding = 2)
# self.maxpool = MaxPool2d(2)
# self.conv2 = Conv2d(32,32,5,padding=2)
# self.maxpool2 = MaxPool2d(2)
# #这里有一个公式,如果尺寸不变,padding = (f -1)/2,f是kernel
# self.conv3 = Conv2d(32,64,5,padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.Liner1 = Linear(1024,64)
# self.Liner2 = Linear(64,10)
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
# x = self.conv1(x)
# x = self.maxpool(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.Liner1(x)
# x = self.Liner2(x)
x = self.model1(x)
return x
#用tensorboard可视化一下
writer = SummaryWriter("logs_seq")
writer.add_graph(guozi,input)
writer.close()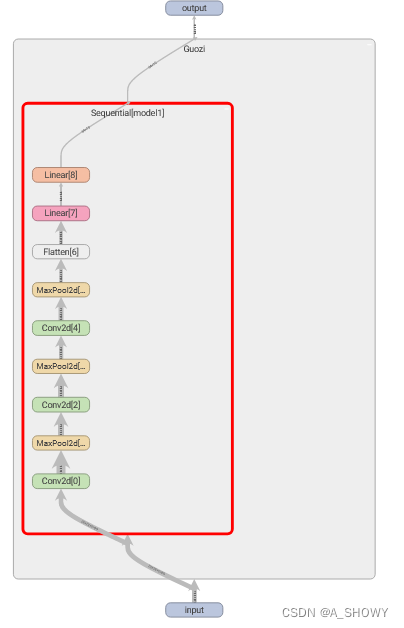
14.损失函数与反向传播
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
loss = L1Loss()
result = loss(inputs,targets)
print(result)
loss = L1Loss(reduction='sum')
result = loss(inputs,targets)
print(result)


反向传播以后会出来每个参数对应的梯度grad
#反向传播+交叉熵
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d, Flatten, Linear, Conv2d, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data",train =False,transform=torchvision.transforms.ToTensor(),
download = True)
dataloader = DataLoader(dataset,batch_size=1)
class Guozi(nn.Module):
def __init__(self):
super(Guozi,self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()#交叉熵
guozi = Guozi()
for data in dataloader:
imgs,targets = data
outputs = guozi(imgs)
result_loss = loss(outputs,targets)
print(result_loss)
#反向传播
result_loss.backward()
15.优化器(torch.OPTIM)
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d, Flatten, Linear, Conv2d, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data",train =False,transform=torchvision.transforms.ToTensor(),
download = True)
dataloader = DataLoader(dataset,batch_size=1)
class Guozi(nn.Module):
def __init__(self):
super(Guozi,self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()#交叉熵
guozi = Guozi()
optim = torch.optim.SGD(guozi.parameters(),lr = 0.01)#选择优化器,然后传入参数
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs,targets = data
outputs = guozi(imgs)
result_loss = loss(outputs,targets)
#反向传播
optim.zero_grad() # 把上一次的梯度清零
result_loss.backward()#得到了每个参数调节的梯度,必不可少
optim.step() # 对每个参数进行调优
running_loss += result_loss# running_loss是每一轮训练的误差求和
print(running_loss)16.现有网络模型的使用及修改
import torchvision.datasets
#
# train_data = torchvision.datasets.ImageNet("../data_image_net",split = "train",download=True
# ,transform=torchvision.transforms.ToTensor())
vgg16_false =torchvision.models.vgg16(pretrained=False)#仅仅加载网络模型,相当于只写了网络架构,没有训练的参数,参数随机
vgg16_true = torchvision.models.vgg16(pretrained=True)#下载参数,数据集上训练好的参数
print(vgg16_true)
***
import torchvision.datasets
from torch import nn
#
# train_data = torchvision.datasets.ImageNet("../data_image_net",split = "train",download=True
# ,transform=torchvision.transforms.ToTensor())
vgg16_false =torchvision.models.vgg16(pretrained=False)#仅仅加载网络模型,相当于只写了网络架构,没有训练的参数,参数随机
vgg16_true = torchvision.models.vgg16(pretrained=True)#下载参数,数据集上训练好的参数
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10("../data",transform=torchvision.transforms.ToTensor(),train = True,
download=True)
#在最后加新的一层
vgg16_true.add_module('add_linear',nn.Linear(1000,10))
#直接在classifier加
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))
print(vgg16_true)
# 直接改某一层
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096,10)
print((vgg16_false))
17.模型的保存与读取
#保存方式1,不仅保存了网络模型结构,还保存了模型参数
torch.save(vgg16,"vgg16_method1.pth")
#保存方式2(推荐)加载模型结构,参数也都加载进来了
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
#读取
#方式1
model = torch.load("vgg16_method1.pth")
print(model)
#方式2
#重新建立网络模型结构
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
# model = torch.load("vgg16_method2.pth")
print(model)陷阱:如果用方式1加载自己建立的模型的话,需要把模型定义复制过来,或者是import定义模型的文件 *。但是不需要这一步了guozi = Guozi( )
18.完整的模型训练套路(以CIFAR10为例)
放在train和model文件下面了
# chen,model
# 2024/3/18 0:40
#搭建神经网络
import torch
from torch import nn
class Chenzi(nn.Module):
def __init__(self):
super(Chenzi,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
chenzi = Chenzi()
input = torch.ones((64,3,32,32))
output = chenzi(input)
print(output.shape)
#输出torch.Size([64, 10]),意思是输入了64个图片,返回64行数据,代表每一个图片在10个类中概率
# chen,train
# chen
# 2024/3/18 0:25
#准备数据集
import torch.optim.optimizer
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from shizhan.model import Chenzi
#准备数据集
train_data = torchvision.datasets.CIFAR10(root = "../data",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root = "../data",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
#获得数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用dataloader加载数据集
train_dataloader = DataLoader(train_data,64)
test_dataloader = DataLoader(test_data,64)
#创建网络模型
chenzi = Chenzi()
#损失函数
loss_fn = nn.CrossEntropyLoss()
#优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(chenzi.parameters(),lr = learning_rate)
#设置训练网络一些参数
#记录训练次数,测试数目,和训练轮数
total_train_step = 0
total_test_step = 0
epoch = 10
#添加tensorboard
writer = SummaryWriter("../logs_train")
#多次训练
chenzi.train()
for i in range(epoch):
# 训练步骤开始
print("--------第{}论训练开始---------".format(i+1))
for data in train_dataloader:
imgs,target= data
outputs = chenzi(imgs)
loss = loss_fn(outputs,target)
#先清零,优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:#每逢100输出
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
chenzi.eval()
total_test_loss = 0
total_accuracy =0
with torch.no_grad():#没有梯度
for data in test_dataloader:
imgs,targets = data
outputs = chenzi(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss.item()
#正确率
accuracy = (outputs.argmax(1) ==targets).sum()
total_accuracy += accuracy
print("整体测试集的loss:{}".format(total_test_loss))
print("整体测试集的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
#保存每一轮训练的模型
torch.save(chenzi,"chenzi_{}.pth".format(i))
print("模型已保存")
writer.close()
补充:检验分类问题的正确性
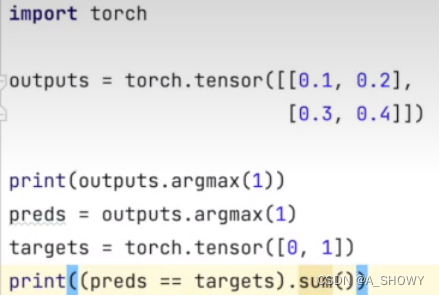
比如2分类问题:input×2,得到output=[0.1,0.2],[0.3,0.4],需要区分的是类别0和类别1,通过函数argmax可以把output转换成preds=[1][1],input targets=[0][1],然后让preds==input targets就会得到[false,true],然后[false,true].sum()=1
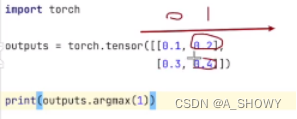
1是横着看,0是竖着看

这两点不是必要的,有的人的代码会写,只对一些层有用

19.使用GPU训练
方法一:

找到这几个部分调用.cuda(),然后再返回一个值就行
比如网络模型gzh=gzh.cuda()
数据ims=imgs.cuda() targets=targets.cuda()测试集上也要
在每个调用的时候都判断一下
![]()
Google colab可以免费用GPU
修改->笔记本设计->硬件加速器:GPU
想在像终端输入命令,先输入一个!

#准备数据集
import time
import torch.optim.optimizer
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from shizhan.model import Chenzi
#准备数据集
train_data = torchvision.datasets.CIFAR10(root = "../data",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root = "../data",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
#获得数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用dataloader加载数据集
train_dataloader = DataLoader(train_data,64)
test_dataloader = DataLoader(test_data,64)
#创建网络模型
class Chenzi(nn.Module):
def __init__(self):
super(Chenzi,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x = self.model(x)
return x
chenzi = Chenzi()
chenzi = chenzi.cuda()
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()
#优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(chenzi.parameters(),lr = learning_rate)
#设置训练网络一些参数
#记录训练次数,测试数目,和训练轮数
total_train_step = 0
total_test_step = 0
epoch = 30
#添加tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time()
#多次训练
chenzi.train()
for i in range(epoch):
# 训练步骤开始
print("--------第{}论训练开始---------".format(i+1))
for data in train_dataloader:
imgs,target= data
imgs = imgs.cuda()
target = target.cuda()
outputs = chenzi(imgs)
loss = loss_fn(outputs,target)
#先清零,优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:#每逢100输出
end_time = time.time()
# print("时间:{}".format(end_time -start_time))
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
chenzi.eval()
total_test_loss = 0
total_accuracy =0
with torch.no_grad():#没有梯度
for data in test_dataloader:
imgs,targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = chenzi(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss.item()
#正确率
accuracy = (outputs.argmax(1) ==targets).sum()
total_accuracy += accuracy
print("整体测试集的loss:{}".format(total_test_loss))
print("整体测试集的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
#保存每一轮训练的模型
torch.save(chenzi,"chenzi_{}.pth".format(i))
print("模型已保存")
writer.close()方法二:
(这里可以不另外赋值,直接写tudui.to(device))
![]()
loss_fn一样不需要赋值
imgs,targets一样的方法,但是需要赋值
都赋值也没问题
用GPU训练torch.device(“cuda”)
torch.device(“cuda:0”)单显卡这两种没区别
![]()
这样写更好
# chen
# 2024/3/18 11:57
# chen
# 2024/3/18 0:25
#准备数据集
import torch.optim.optimizer
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from shizhan.model import Chenzi
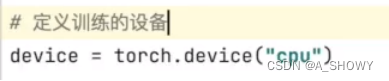
#定义训练设备
device = torch.device("cuda")
#准备数据集
train_data = torchvision.datasets.CIFAR10(root = "../data",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root = "../data",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
#获得数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用dataloader加载数据集
train_dataloader = DataLoader(train_data,64)
test_dataloader = DataLoader(test_data,64)
#创建网络模型
class Chenzi(nn.Module):
def __init__(self):
super(Chenzi,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x = self.model(x)
return x
chenzi = Chenzi()
chenzi = chenzi.to(device)
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
#优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(chenzi.parameters(),lr = learning_rate)
#设置训练网络一些参数
#记录训练次数,测试数目,和训练轮数
total_train_step = 0
total_test_step = 0
epoch = 10
#添加tensorboard
writer = SummaryWriter("../logs_train")
#多次训练
chenzi.train()
for i in range(epoch):
# 训练步骤开始
print("--------第{}论训练开始---------".format(i+1))
for data in train_dataloader:
imgs,target= data
imgs = imgs.to(device)
target = target.to(device)
outputs = chenzi(imgs)
loss = loss_fn(outputs,target)
#先清零,优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:#每逢100输出
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
chenzi.eval()
total_test_loss = 0
total_accuracy =0
with torch.no_grad():#没有梯度
for data in test_dataloader:
imgs,targets = data
imgs= imgs.to(device)
targets = targets.to(device)
outputs = chenzi(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss.item()
#正确率
accuracy = (outputs.argmax(1) ==targets).sum()
total_accuracy += accuracy
print("整体测试集的loss:{}".format(total_test_loss))
print("整体测试集的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
#保存每一轮训练的模型
torch.save(chenzi,"chenzi_{}.pth".format(i))
print("模型已保存")
writer.close()20.完整的模型验证
完整的模型验证测试/demo道路-利用已经训练好的模型,然后给它提供输入
# chen
# 2024/3/18 12:17
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "../dog/dog.png"
image = Image.open(image_path)
print(image)
#保证3通道,适应PNGJPG
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Chenzi(nn.Module):
def __init__(self):
super(Chenzi,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x = self.model(x)
return x
#加载
model = torch.load("../shizhan/chenzi_9.pth")
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))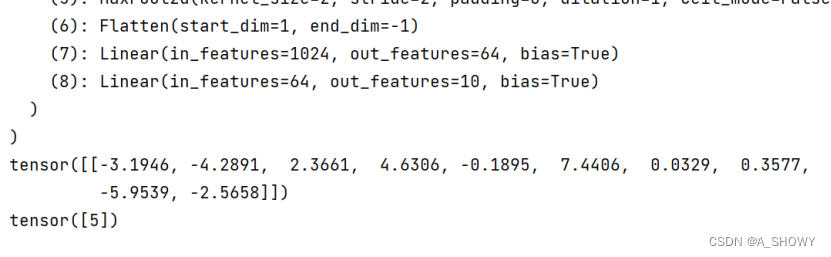
用谷歌gpu训练好以后的保存的模型可以下载下来,右键下载,再复制到pycharm文件夹下面就行
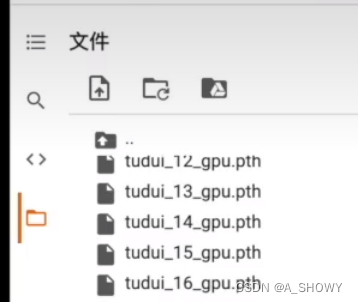
如果用gpu训练的模型,只是用在cpu上测试,要在torch.load()里写这个