目录
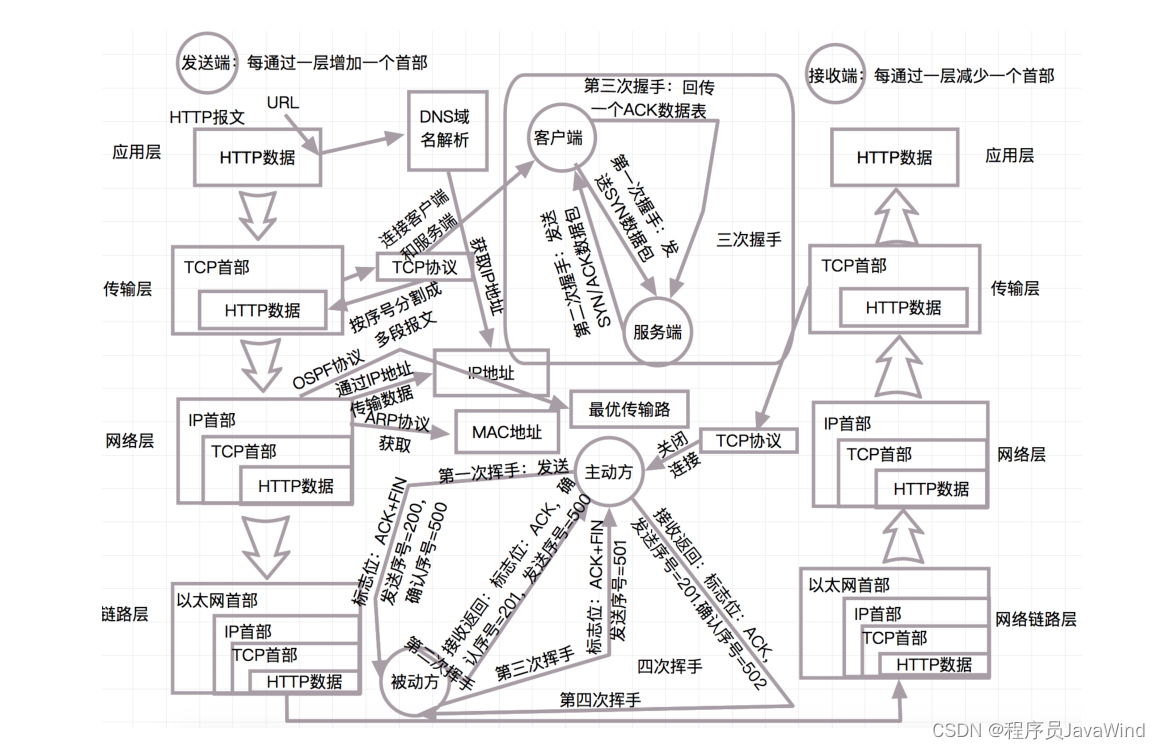
一、重定向
1、输出重定向
2、输入重定向
3、追加重定向
4、dup2 系统调用
二、理性理解Linux系统下“一切皆文件”
了解硬件接口
三、缓冲区
1、为什么要有缓冲区?
2、刷新策略
3、缓冲模式改变导致发生写时拷贝
未创建子进程时
创建子进程时
使用fflush()刷新缓冲区
4、C标准库维护的缓冲区
四、模拟实现C语言文件接口
五、实现shell重定向
1. 定义常量和全局变量
2. 重定向检查函数 CheckRedir
3. 主函数 main
一、重定向
1、输出重定向
在这段代码中,我们首先关闭了文件描述符1(通常是标准输出stdout),然后打开了一个新的文件log.txt。由于文件描述符1被关闭,新打开的文件将会占用这个最小且未被使用的文件描述符,也就是1。
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main() {
// 关闭文件描述符1,即关闭标准输出。
close(1);
// 打开"log.txt"文件。因为文件描述符1是最小的且当前未被使用的,它将被分配给"log.txt"。
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
// 如果打开文件失败,则打印错误信息并退出程序。
perror("open");
return 1;
}
// 此时,printf将输出到文件描述符1,也就是"log.txt"。
printf("fd: %d\n", fd); // 输出将被写入"log.txt"
return 0;
}接着,通过printf函数打印信息时,输出实际上被重定向到了log.txt文件。这是因为printf默认使用文件描述符1(stdout)进行输出,而现在文件描述符1指向了log.txt而非标准输出。
运行这个程序后,你不会在控制台看到任何输出,因为printf的输出已经被重定向到了log.txt。如果你查看log.txt(使用cat log.txt),你会看到输出fd: 1。
[hbr@VM-16-9-centos redirect]$ ./myfile
[hbr@VM-16-9-centos redirect]$ ls
buffer_rd.c log.txt makefile myfile myfile.c
[hbr@VM-16-9-centos redirect]$ cat log.txt
fd: 1
这个过程展示了重定向的本质:在操作系统内部更改文件描述符对应的目标。通过关闭和重新打开文件描述符,我们改变了标准输出的指向,从而实现了输出重定向。
2、输入重定向
输入重定向是一种将程序的输入从键盘转向文件或另一个程序的过程。在这个例子中,通过将"log.txt"文件作为程序的输入,实现了输入重定向。这样程序就不再从键盘读取输入,而是从"log.txt"文件中读取数据。
首先关闭了标准输入文件描述符(文件描述符0),然后使用open函数以只读模式打开了"log.txt"文件,并将返回的文件描述符存储在fd变量中。如果打开文件失败,会输出错误信息并返回1。
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main() {
close(0); // 关闭标准输入文件描述符(文件描述符0)
// 打开"log.txt"文件,以只读模式打开
int fd = open("log.txt", O_RDONLY);
if (fd < 0) {
perror("open"); // 输出错误信息
return 1; // 返回错误码
}
printf("fd: %d\n", fd); // 打印文件描述符
char buffer[64];
// 从标准输入(实际上是从"log.txt"文件)中读取一行内容到buffer中
fgets(buffer, sizeof(buffer), stdin);
// 打印buffer中的内容
printf("%s\n", buffer);
return 0;
}接着程序会打印出fd的值,然后使用fgets函数从标准输入(stdin)中读取最多sizeof(buffer)个字符到buffer数组中。最后,程序会打印出读取到的内容。
在执行程序后,可以看到程序输出了"fd: 0",表示成功打开"log.txt"文件并将其文件描述符存储在fd中。然后程序从"log.txt"文件中读取了内容"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa",并将其打印出来。
cat log.txt
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
./myfile
fd: 0
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa3、追加重定向
在打开文件后关闭了标准输出文件描述符(文件描述符1),然后用open函数打开了一个名为"log.txt"的文件,设置了写入、追加和创建标志。接着使用fprintf函数尝试往标准输出(stdout)写入内容,但实际上因为之前关闭了标准输出,所以内容被重定向到了"log.txt"文件中。
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{
close(1); // 关闭标准输出文件描述符(文件描述符1)
// 打开或创建一个文件"log.txt",并以写入模式打开,
//如果文件不存在则创建它,如果文件已存在则在文件末尾追加写入
int fd = open("log.txt", O_WRONLY | O_APPEND | O_CREAT);
if (fd < 0)
{
perror("open"); // 输出错误信息
return 1; // 返回错误码
}
// 将消息写入标准输出(实际上是写入"log.txt"文件,因为标准输出已被重定向)
fprintf(stdout, "you can see me\n");
return 0;
}在执行程序后,可以看到"log.txt"文件中出现了"you can see me"这行内容。每次运行程序时,都会在"log.txt"文件中追加相同的内容。
[hbr@VM-16-9-centos redirect]$ ./myfile
[hbr@VM-16-9-centos redirect]$ ll
total 36
-rw-rw-r-- 1 hbr hbr 317 Mar 17 14:01 buffer_rd.c
-rw-rw-r-- 1 hbr hbr 360 Mar 17 14:49 input.c
-rw--wx--- 1 hbr hbr 15 Mar 17 14:54 log.txt
-rw-rw-r-- 1 hbr hbr 73 Mar 16 15:19 makefile
-rwxrwxr-x 1 hbr hbr 8560 Mar 17 14:54 myfile
-rw-rw-r-- 1 hbr hbr 310 Mar 17 14:54 myfile.c
-rw-rw-r-- 1 hbr hbr 674 Mar 17 14:18 output.c
[hbr@VM-16-9-centos redirect]$ cat log.txt
you can see me
[hbr@VM-16-9-centos redirect]$ ./myfile
[hbr@VM-16-9-centos redirect]$ ./myfile
[hbr@VM-16-9-centos redirect]$ ./myfile
[hbr@VM-16-9-centos redirect]$ ./myfile
[hbr@VM-16-9-centos redirect]$ cat log.txt
you can see me
you can see me
you can see me
you can see me
you can see me
4、dup2 系统调用
dup2 函数是一个系统调用,用于复制文件描述符。它的原型如下:
#include <unistd.h>
int dup2(int oldfd, int newfd);oldfd是要复制的文件描述符。newfd是新的文件描述符。
dup2 函数的作用是将 oldfd 复制到 newfd,如果 newfd 已经打开,则会先关闭 newfd。这样可以实现文件描述符的重定向,非常有用,特别是在重定向标准输入、输出和错误流时。
使用 dup2 函数可以实现文件描述符的复制和重定向,使得一个文件描述符可以指向同一个文件或设备。这在编程中经常用于重定向标准输入、输出和错误流,或者在进程间通信时复制文件描述符。
使用dup2函数配合命令行参数实现指定内容输出重定向到文件中:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main(int argc,char *argv[])
{
if(argc!=2)
{
return 2;
}
int fd=open("log.txt",O_WRONLY|O_CREAT|O_TRUNC);
if(fd<0)
{
perror("open");
return 1;
}
dup2(fd,1);
fprintf(stdout,"%s\n",argv[1]);
return 0;
}
- 这段代码中,程序接受一个命令行参数,并将该参数写入到"log.txt"文件中。首先,程序检查命令行参数的数量是否为2,如果不是则返回2表示参数错误。
- 然后,程序尝试以写入方式打开"log.txt"文件,如果打开失败则打印错误信息并返回1。接着,使用
dup2函数将文件描述符fd复制到文件描述符1(标准输出),这样所有标准输出都将被重定向到"log.txt"文件中。 - 最后,程序使用
fprintf函数将命令行参数argv[1]写入到标准输出(stdout),实际上是写入到"log.txt"文件中。 - 当你运行程序时,传递一个参数给程序,程序会将该参数写入"log.txt"文件中。每次运行程序并传递不同的参数,文件中的内容会被更新为最新的参数值。这样实现了将程序的输出重定向到文件中。
[hbr@VM-16-9-centos redirect]$ ./myfile hello
[hbr@VM-16-9-centos redirect]$ cat log.txt
hello
[hbr@VM-16-9-centos redirect]$ ./myfile world
[hbr@VM-16-9-centos redirect]$ cat log.txt
world
二、理性理解Linux系统下“一切皆文件”
在Linux中,一切皆文件的哲学深深植根于其设计之中。这一理念通过虚拟文件系统(VFS)得到体现,使得不同的硬件设备能够通过统一的接口与操作系统交互。在C语言环境下,虽然我们没有面向对象编程语言中的类和对象,但我们可以通过结构体(structs)和函数指针来模拟面向对象的特性,进而实现类似的封装和多态行为。

- Linux内核利用
struct file结构体来表示一个打开的文件或设备。每个struct file实例包含了一系列的函数指针,比如read和write,这些指针指向具体的函数实现。这样,不同的设备驱动可以提供自己的read和write实现,而上层应用通过struct file接口与之交互时,无需关心具体的硬件差异。 - 这种设计实现了一个抽象层,使得所有外部设备看起来都具有相同的接口。每种硬件设备的驱动程序负责将这些通用操作翻译成设备特定的操作。这种方法不仅提高了代码的复用性,也简化了应用程序与硬件设备之间的交互。
- 同时,在链表中管理
struct file结构体的做法,进一步增强了系统的灵活性和扩展性。当需要操作特定硬件时,系统遍历链表,找到对应的struct file,然后通过其内部的函数指针调用相应的操作。这样的设计既实现了对不同硬件的抽象,又保留了向特定设备发送特定指令的能力。 - 总结来说,通过在C语言中巧妙地使用结构体和函数指针,Linux内核实现了一种面向对象的设计模式,这使得操作系统能够以统一的方式看待和操作各种各样的硬件设备。这种设计模式的核心在于抽象化和封装,它使得开发者能够在不直接面对复杂硬件细节的情况下,进行高效的设备管理和操作,充分体现了Linux中“一切皆文件”的哲学。
了解硬件接口
系统调用是操作系统提供给用户程序的接口,允许用户程序请求操作系统的服务,如文件操作、进程管理、通信等。这些调用形成了用户空间(用户程序运行的区域)和内核空间(操作系统核心部分运行的区域)之间的接口。
操作系统通过一系列的抽象层来管理硬件接口的操作。这些抽象层使用户程序不需要直接与硬件交互,提高了操作系统的可用性和安全性。下面是操作系统如何安排对硬件接口操作的基本概览:
-
硬件抽象层(HAL):操作系统内部包含一个硬件抽象层(HAL),它提供了统一的接口来隐藏不同硬件之间的差异。这使得操作系统能够在不同的硬件平台上运行,而无需每个平台编写特定的代码。
-
设备驱动程序:对于每种硬件设备(如硬盘、显卡、网络接口等),操作系统使用特定的设备驱动程序来进行通信。设备驱动程序负责将操作系统的通用操作转换为设备特定的指令,以及管理设备状态和执行操作系统的命令。
-
内核模式与用户模式:现代操作系统设计中,CPU提供了至少两种模式:内核模式(也称为监督模式或特权模式)和用户模式。操作系统内核和设备驱动程序在内核模式下运行,可以直接访问硬件资源。用户程序在用户模式下运行,不能直接访问硬件,必须通过系统调用来请求操作系统的服务。
-
中断和异常处理:操作系统使用中断(来自硬件设备的信号)和异常(来自CPU的错误或特殊情况信号)来响应外部事件或错误条件。当硬件设备需要CPU注意时(例如,数据已经从网络卡接收完毕),它会产生一个中断,操作系统会中断当前的处理流程,执行相应的中断处理程序,以响应和处理该事件。
-
系统调用和硬件操作:当用户程序执行系统调用请求操作系统服务时(如读写文件、发送网络数据包等),操作系统内核会根据请求的服务类型,通过调用相应的设备驱动程序和管理逻辑来操作硬件设备,完成用户程序的请求。
三、缓冲区
1、为什么要有缓冲区?
缓冲区是计算机内存中的一块区域,用于临时存储数据,以便在数据最终处理或传输之前对其进行批量处理。这块内存空间可以由操作系统、程序语言运行时环境或用户程序提供。
缓冲区的存在是为了提高系统的整体效率和加快对用户操作的响应速度。可以用小明发送快递给同学的例子来形象化:
- 当用户完成数据写入操作时,若无缓冲区,这就像小明每次都要亲自下楼、出门、乘坐火车或飞机将书送到同学手中,这种方式(相当于写透模式,WT)不仅耗时长,成本也高。相反,拥有缓冲区就像小明将快递暂存到快递站,然后快递站负责集中派送,这样小明就可以迅速回到宿舍继续他的活动,大大节省了时间和精力(对应写回模式,WB),既快速又降低了成本。
具体到计算机系统中,缓冲区的存在使得数据可以集中写入或读出,从而减少了对磁盘或网络的频繁访问,这就像小明发快递,快递服务批量发送学生们的包裹,提高了效率和速度。
2、刷新策略
缓冲区的刷新策略决定了数据何时从缓冲区移动到目的地。常见的刷新策略包括:
- 立即刷新:数据一旦进入缓冲区就立刻被处理或发送,适用于对实时性要求高的场景。
- 行刷新(行缓冲):通常用于与显示器等实时交互的设备。这种模式下,数据会被缓存直到缓冲区满、遇到换行符,或者缓冲区被显式刷新。行缓冲模式旨在平衡用户交互的实时性和系统的效率。例如,当你向终端打印文本时,系统可能会采用行缓冲,以便用户可以即时看到输出结果,而不必等待缓冲区完全填满。
- 满刷新(全缓冲):只常用于对效率要求较高的场合,如磁盘文件操作。在这种模式下,数据会在缓冲区完全填满后才进行实际的写入操作。这种策略显著减少了磁盘I/O操作的次数,从而提高了效率。对于需要频繁读写的应用,全缓冲可以有效减少对外设访问的次数,优化系统性能
除了这些常规策略,还有特殊情况如:
- 用户强制刷新(例如使用
fflush函数) - 进程退出时的自动刷新
注意:
- 在与外部设备进行I/O操作时,经常发生的瓶颈并非数据量的大小,而是预备I/O过程本身的时间开销。每一次的I/O操作都涉及到复杂的系统调用,可能还需要设备响应,因此尽可能减少I/O操作的次数是提高系统效率的关键。
- 不同的应用场景可能需要不同的缓冲策略。例如,显示器需要即时反馈给用户信息,因此行缓冲更为合适;而磁盘文件操作则更倾向于使用全缓冲以提高效率。在某些特殊情况下,开发者甚至可以根据具体需求自定义缓冲区的刷新策略,以达到最佳的性能和用户体验的平衡。
缓冲区的核心优势在于:
- 提高数据处理效率:通过集中处理或传输数据,减少了对存储设备或网络资源的频繁访问,从而提高了效率。
- 增强系统响应速度:应用程序可以继续执行而不必等待每个写入操作直接完成,这样用户就不会感到明显的延迟。
- 降低资源消耗:通过减少对硬件的直接操作,延长设备寿命,同时也减少了能源消耗。
3、fsync() 、fflush()
fsync()和fflush()是用于刷新文件缓冲区的函数,它们在不同的情况下有不同的作用。
fsync():
fsync()是系统调用,用于将与打开的文件描述符关联的所有修改过的文件数据和属性同步到存储介质上。- 当你需要确保数据被写入磁盘而不仅仅是缓存在内存中时,可以使用
fsync()函数。 - 这对于需要持久化数据,如数据库操作或重要文件写入时很有用。
- 一般情况下,
fsync()比fflush()更耗时,因为它确保数据被写入磁盘而不仅仅是刷新到文件系统缓存。
示例用法:
#include <unistd.h>
int fd = open("file.txt", O_WRONLY);
// 写入数据到文件
write(fd, data, size);
// 确保数据被写入磁盘
fsync(fd);fflush():
fflush()是C标准库中的一个函数,用于清空用户空间的文件输出缓冲区。它通常与标准I/O库中的函数(如printf、fprintf等)一起使用。- 当你需要立即将缓冲区中的数据写入文件时,可以使用
fflush()函数。 - 通常用于标准I/O流(如
stdout、stderr)或文件流。 fflush()可以确保数据被写入文件,但不会像fsync()那样直接写入磁盘。
示例用法:
#include <stdio.h>
FILE *file = fopen("file.txt", "w");
// 写入数据到文件流
fprintf(file, "Hello, World!\n");
// 确保数据被写入文件
fflush(file);区别
- 使用场景:
fflush()用于标准I/O库函数,作用于用户空间的缓冲区。fsync()用于文件描述符,确保数据持久化到磁盘。 - 功能:
fflush()只将数据从用户空间缓冲区刷新到操作系统的文件系统缓冲区。fsync()确保所有挂起的更改都物理写入存储介质。 - 适用范围:
fflush()适用于使用标准I/O库的情况。fsync()适用于底层文件描述符,与使用open()、write()等系统调用时一起使用。
4、缓冲模式改变导致发生写时拷贝
未创建子进程时
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
//C语言提供的
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
const char *s="hello fputs\n";
fputs(s,stdout);
// OS提供的
const char* ss="hello write\n";
write(1,ss,strlen(ss));
return 0;
}
没有创建子进程时,C语言写入函数按顺序正常刷新缓冲区,打印到显示器上,而write()系统调用将字符串"hello write\n"直接写入到文件描述符1(标准输出)。
当重定向输出到文件时,输出将不再显示在终端上,而是写入到文件中,因为对磁盘操作,所以刷新策略变成了全缓冲。
- 在这个情况下,"hello write" 是第一个写入到文件中的字符串,因为它直接使用系统调用
write()写入到标准输出,这个操作没有经过标准库的缓冲区。 - 而后续的输出,如"hello printf"、"hello fprintf" 和 "hello fputs",它们使用了标准库提供的函数,它们的输出会被缓冲,直到程序结束或者缓冲区被填满时才会被写入文件。所以,"hello write" 是第一个写入到文件中的字符串。
[hbr@VM-16-9-centos redirect]$ ./myfile
hello printf
hello fprintf
hello fputs
hello write
[hbr@VM-16-9-centos redirect]$ ./myfile > log.txt
[hbr@VM-16-9-centos redirect]$ cat log.txt
hello write
hello printf
hello fprintf
hello fputs
创建子进程时
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
const char *s="hello fputs\n";
fputs(s,stdout);
const char* ss="hello write\n";
write(1,ss,strlen(ss));
fork();
return 0;
}查看log.txt中的内容可以发现hello write被写入1次,其他都是两次。
我们推测这种现象一定和fork有关!
[hbr@VM-16-9-centos redirect]$ make
gcc -std=c99 -o myfile myfile.c
[hbr@VM-16-9-centos redirect]$ ./myfile
hello printf
hello fprintf
hello fputs
hello write
[hbr@VM-16-9-centos redirect]$ ./myfile > log.txt
[hbr@VM-16-9-centos redirect]$ cat log.txt
hello write
hello printf
hello fprintf
hello fputs
hello printf
hello fprintf
hello fputs
向显示器打印时:默认采用行缓冲模式,即每当遇到换行符时,缓冲区的内容会被刷新(写入到显示器)。因此,在执行fork()之前,所有通过标准C库函数输出的内容都已经被刷新到显示器上了。
向磁盘文件打印时:输出重定向到文件后,标准输出变为全缓冲模式。
write系统调用直接通过操作系统进行I/O操作,绕过了C标准库的缓冲机制,因此它的输出不受上述缓冲策略的影响,即使在fork()之后也只会出现一次。- 在全缓冲模式下,换行符\n已经失效了,缓冲区的内容只有在缓冲区满、程序正常结束或显式调用刷新函数时才会被写入文件。
- 当执行
fork()时,缓冲区内可能还有未刷新的数据。这些数据就是C库的I/O函数,进程退出会导致缓冲区刷新,刷新会把数据写到系统里,这个刷新的过程就是写入的过程,所以子进程退出的过程发生了写时拷贝,fork()会复制进程的内存空间,包括文件描述符和缓冲区的内容,这导致父进程和子进程各自拥有一份相同的缓冲区副本。当这两个进程结束时,它们各自的缓冲区内容都会被写入到同一个文件中,这就是为什么标准C库的输出会出现两次的原因。
使用fflush()刷新缓冲区
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
const char *s="hello fputs\n";
fputs(s,stdout);
const char* ss="hello write\n";
write(1,ss,strlen(ss));
fflush(stdout);
fork();
return 0;
}通过手动刷新缓冲区写入文件,缓冲区被清空,子进程退出时无需刷新缓冲区,所以不会导致写时拷贝。
[hbr@VM-16-9-centos redirect]$ ./myfile
hello printf
hello fprintf
hello fputs
hello write
[hbr@VM-16-9-centos redirect]$ ./myfile > log.txt
[hbr@VM-16-9-centos redirect]$ cat log.txt
hello write
hello printf
hello fprintf
hello fputs
5、C标准库维护的缓冲区
C语言的struct FILE结构除了包含文件描述符,内部包含了该文件的语言层的缓冲区结构。
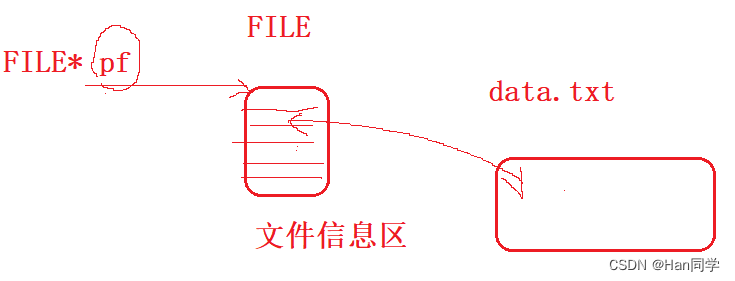
在C语言中,FILE结构是标准库用于处理文件操作的核心数据类型。这个结构不仅封装了底层的文件描述符,也维护了一层高于操作系统的缓冲机制。这种语言层面的缓冲区架构,设计用来提高文件I/O操作的效率和性能。
当你通过C标准库的I/O函数(如fread, fwrite, printf, scanf等)进行文件操作时,FILE结构中的缓冲区起到了中介的作用。这意味着数据可能首先被存储在这个缓冲区中,然后才会在适当的时机真正地写入到文件中(或从文件中读出)。这种延迟写入(或批量读取)的机制能够减少对底层存储设备或系统调用的频繁访问,从而提高了整体的文件处理性能。
四、模拟实现C语言文件接口
这段代码实现了一个简单的文件操作库,模拟了类似 FILE 结构的 MyFILE 结构和相关函数,来进行基本的文件操作,包括文件的打开、写入、刷新和关闭操作。然后我们来通过 main 函数使用这个自定义库来写入和管理文件。
#include <stdio.h>
#include <string.h>//用于 strcpy 和 strlen 函数,处理字符串。
#include <unistd.h>//用于 fork、close 和 write 函数,进行进程控制和文件操作。
#include <sys/types.h>//与 open 函数配合使用
#include <sys/stat.h>//与 open 函数配合使用
#include <fcntl.h>//用于 open 函数的标志定义,如 O_WRONLY、O_TRUNC、O_CREAT。
#include <assert.h>/断言
#include <stdlib.h>//用于 malloc 和 free 函数,进行内存分配和释放。
#define NUM 1024
struct MyFILE_{
int fd; // 文件描述符
char buffer[1024]; // 缓冲区
int end; // 缓冲区中数据的结束位置
};
typedef struct MyFILE_ MyFILE;
// 打开文件,模仿fopen函数
MyFILE *fopen_(const char *pathname,const char *mode)
{
assert(pathname);
assert(mode);
MyFILE *fp=NULL;
if(strcmp(mode,"r")==0){}
else if(strcmp(mode,"r+")==0){}
else if(strcmp(mode,"w")==0)
{
// 以写模式打开文件,如果文件存在,则截断
int fd=open(pathname,O_WRONLY|O_TRUNC|O_CREAT,0666);
if(fd>=0)
{
fp=(MyFILE*)malloc(sizeof(MyFILE));
memset(fp,0,sizeof(MyFILE));
fp->fd=fd;
}
}
// 其他模式的处理(未实现)
else if(strcmp(mode, "w+") == 0){}
else if(strcmp(mode, "a") == 0){}
else if(strcmp(mode, "a+") == 0){}
return fp;
}
// 将消息写入文件,模仿fputs函数
void fputs_(const char *message,MyFILE *fp)
{
assert(message);
assert(fp);
strcpy(fp->buffer+fp->end,message);
fp->end+=strlen(message);
printf("%s\n", fp->buffer); // 调试用:打印缓冲区内容
// 特殊处理标准输入/输出/错误(未实现)
if(fp->fd==0){}
else if(fp->fd==1)
{
// 缓冲区末尾如果是换行符,则写入标准输出
if(fp->buffer[fp->end-1]=='\n')
{
write(fp->fd,fp->buffer,fp->end);
fp->end=0;
}
}
else if(fp->fd == 2){}
else
{
// 其他文件的处理(未实现)
}
}
// 强制刷新缓冲区,写入文件
void fflush_(MyFILE*fp)
{
assert(fp);
if(fp->end!=0)
{
write(fp->fd,fp->buffer,fp->end);
syncfs(fp->fd); // 同步文件系统
fp->end=0;
}
}
// 关闭文件,模仿fclose函数
void fclose_(MyFILE *fp)
{
assert(fp);
fflush_(fp); // 刷新缓冲区
close(fp->fd); // 关闭文件描述符
free(fp); // 释放分配的内存
}
int main()
{
// 示例:使用自定义的文件操作函数
MyFILE *fp = fopen_("./log.txt", "w");
if(fp == NULL)
{
printf("open file error\n");
return 1;
}
fputs_("one: hello world", fp);
fork(); // 创建子进程
fclose_(fp); // 在父进程和子进程中关闭文件
}-
fopen_函数创建一个MyFILE结构体,并打开一个文件(这里是 "log.txt")用于写入("w" 模式)。如果文件已经存在,它会被截断。 -
fputs_函数将字符串 "one: hello world" 写入到MyFILE结构体的缓冲区中,并且立即通过打印(printf)显示在屏幕上。 -
fork()调用创建了一个子进程。此时,父进程和子进程都拥有打开的文件描述符和相应的MyFILE结构体副本。 -
fclose_函数在父进程和子进程中都被调用,导致MyFILE结构体中的缓冲区内容被写入文件,文件描述符被关闭,并释放结构体内存。 -
fflush_函数在fclose_中调用,确保所有缓冲的数据都被写入文件。syncfs被调用来强制将缓冲数据同步到磁盘。
输出结果
[hbr@VM-16-9-centos myCfunc]$ ./myfile
one: hello world
[hbr@VM-16-9-centos myCfunc]$ ./myfile > log.txt
[hbr@VM-16-9-centos myCfunc]$ cat log.txt
one: hello world
one: hello world-
当直接运行程序(不重定向标准输出到文件)时,你看到 "one: hello world" 打印在终端上。这是因为
fputs_函数中的printf语句直接输出到了标准输出。 -
当将程序的输出重定向到 "log.txt" 文件时,"one: hello world" 不再显示在终端上,因为标准输出被重定向了。然而,由于
fork()创建了一个子进程,这个字符串被两次写入文件:一次由父进程,一次由子进程。这就是为什么在 "log.txt" 中看到两次 "one: hello world" 的原因。 -
通过
fork()后,父进程和子进程都独立执行fclose_,导致相同的数据被写入文件两次。
五、实现shell重定向
使用C语言编写一个简单的shell程序,实现了命令行输入、命令解析、环境变量处理、内置命令执行、外部命令执行,以及文件重定向的基本功能。
1. 定义常量和全局变量
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#define NUM 1024 // 命令行最大长度
#define SIZE 32 // 参数最大数量
#define SEP " " // 命令行参数分隔符
char cmd_line[NUM]; // 保存完整的命令行字符串
char *g_argv[SIZE]; // 保存打散之后的命令行字符串
char g_myval[64]; // 环境变量的buffer,用来测试
#define INPUT_REDIR 1 // 输入重定向标识
#define OUTPUT_REDIR 2 // 输出重定向标识
#define APPEND_REDIR 3 // 追加重定向标识
#define NONE_REDIR 0 // 无重定向标识
int redir_status = NONE_REDIR; // 重定向状态NUM和SIZE分别用于定义命令行最大长度和参数最大数量。cmd_line用于存储用户输入的完整命令行字符串。g_argv是一个指针数组,用于存储分解后的命令行参数。g_myval用作环境变量的测试缓冲区。redir_status用于标识当前的重定向状态,如输入重定向、输出重定向等。
2. 重定向检查函数 CheckRedir
char *CheckRedir(char *start)
{
assert(start);
char *end = start + strlen(start) - 1; //ls -a -l\0
while(end >= start)
{
if(*end == '>')
{
if(*(end-1) == '>')
{
redir_status = APPEND_REDIR;
*(end-1) = '\0';
end++;
break;
}
redir_status = OUTPUT_REDIR;
*end = '\0';
end++;
break;
//ls -a -l>myfile.txt
//ls -a -l>>myfile.txt
}
else if(*end == '<')
{
//cat < myfile.txt,输入
redir_status = INPUT_REDIR;
*end = '\0';
end++;
break;
}
else{
end--;
}
}
if(end >= start)
{
return end; //要打开的文件
}
else{
return NULL;
}
}-
初始化:函数接收一个字符串
start作为参数,这是用户输入的命令行字符串。它还定义了一个指针end指向字符串的末尾。 -
逆向遍历字符串:从字符串的末尾开始向前遍历,寻找重定向符号(
>、>>、<)。 -
设置重定向状态:
- 如果找到
>,设置重定向状态为OUTPUT_REDIR,表示输出重定向。 - 如果找到
>>,设置重定向状态为APPEND_REDIR,表示追加输出重定向。 - 如果找到
<,设置重定向状态为INPUT_REDIR,表示输入重定向。
- 如果找到
-
修改命令行字符串:在找到的重定向符号处,将其替换为字符串结束符
\0,从而将命令行字符串分割为命令部分和文件名部分。 -
返回文件名:如果找到重定向符号,
end指针会被移动到文件名的开始位置,并返回这个指针。如果没有找到重定向符号,返回NULL。
关键点:
- 重定向状态:通过
redir_status全局变量记录当前的重定向状态,这对于后续的文件打开和处理很重要。 - 字符串修改:函数直接修改传入的命令行字符串,这是通过在重定向符号处插入
\0实现的,从而分离命令和文件名。 - 逆向遍历:这个函数从字符串的末尾开始向前遍历,这样做是因为重定向符号通常位于命令的末尾。
3. 主函数 main
int main()
{
extern char** environ; // 外部环境变量声明
while (1) {
printf("[root@我的主机 myshell]# ");
fflush(stdout);
memset(cmd_line, '\0', sizeof(cmd_line)); // 清空命令行字符串
// 获取用户输入
if (fgets(cmd_line, sizeof(cmd_line), stdin) == NULL) {
continue;
}
cmd_line[strlen(cmd_line) - 1] = '\0'; // 去除末尾的换行符
char *sep = CheckRedir(cmd_line); // 检查重定向
// 解析命令行
g_argv[0] = strtok(cmd_line, SEP); // 解析第一个命令或参数
int index = 1;
if (strcmp(g_argv[0], "ls") == 0 || strcmp(g_argv[0], "ll") == 0) {
// 对ls和ll命令进行特殊处理
if (strcmp(g_argv[0], "ll") == 0) {
g_argv[0] = "ls";
g_argv[index++] = "-l";
}
g_argv[index++] = "--color=auto";
}
while ((g_argv[index++] = strtok(NULL, SEP))); // 继续解析剩余命令或参数
// 处理内置命令
if (strcmp(g_argv[0], "export") == 0 && g_argv[1] != NULL) {
strcpy(g_myval, g_argv[1]);
if (putenv(g_myval) == 0) {
printf("%s export success\n", g_argv[1]);
}
continue;
}
if (strcmp(g_argv[0], "cd") == 0) {
if (g_argv[1] != NULL) chdir(g_argv[1]);
continue;
}
// 创建子进程执行其他命令
pid_t id = fork();
if (id == 0) { // 子进程
if (sep != NULL) {
int fd = -1;
// 根据重定向类型处理文件描述符
switch (redir_status) {
case INPUT_REDIR:
fd = open(sep, O_RDONLY);
dup2(fd, 0); // 将标准输入重定向到fd指定的文件
break;
case OUTPUT_REDIR:
// 创建新文件或覆盖旧文件
fd = open(sep, O_WRONLY | O_TRUNC | O_CREAT, 0666);
dup2(fd, 1); // 将标准输出重定向到fd指定的文件
break;
case APPEND_REDIR:
// 追加到文件
fd = open(sep, O_WRONLY | O_APPEND | O_CREAT, 0666);
dup2(fd, 1); // 将标准输出重定向到fd指定的文件
break;
}
if (fd != -1) close(fd); // 关闭文件描述符
}
execvp(g_argv[0], g_argv); // 使用execvp执行命令,这会替换当前子进程的映像
exit(EXIT_FAILURE); // 如果execvp返回,说明发生了错误,子进程退出
}
// 父进程(shell)等待子进程完成
int status = 0;
waitpid(id, &status, 0);
if (WIFEXITED(status)) { // 如果子进程正常退出
printf("exit code: %d\n", WEXITSTATUS(status)); // 打印子进程的退出码
}
}
return 0; // main函数结束
}-
初始化和循环等待用户输入:
- 使用
while (1)创建一个无限循环,这样shell会不断等待用户的输入。 - 打印提示符
[root@我的主机 myshell]#,提示用户输入命令。 - 使用
fgets函数读取用户输入的命令行字符串到cmd_line数组中。
- 使用
-
处理命令行输入:
- 去除命令行输入末尾的换行符。
- 调用
CheckRedir函数检查是否有重定向操作,并处理命令行字符串,分离出重定向的文件名。
-
解析命令行参数:
- 使用
strtok函数,以空格为分隔符,将命令行字符串分解成命令和参数,存储在g_argv数组中。 - 特别处理
ls和ll命令,为ls命令自动添加--color=auto参数,将ll命令转换为ls -l。
- 使用
-
处理内置命令:
- 检查命令是否为
export或cd,并执行相应的操作。export命令用于设置环境变量,cd命令用于改变当前工作目录。
- 检查命令是否为
-
创建子进程执行外部命令:
- 使用
fork创建子进程。 - 在子进程中,根据重定向状态,打开相应的文件,并使用
dup2函数重定向标准输入或输出到该文件。 - 使用
execvp函数执行命令。 - 子进程执行完命令后退出。
- 使用
-
父进程等待子进程结束:
- 使用
waitpid函数等待子进程结束,并获取子进程的退出状态。 - 打印子进程的退出码。
- 使用