概述
在 《设计原则 - 10.实战:针对非业务的通用框架开发,如何做需求分析和设计及如何实现一个支持各种统计规则的性能计数器》中,我们讲解了如何对一个性能计数器框架进行分析、设计与实现,并且实践了一些设计原则和设计思想。当时提到,小步快跑、逐步迭代式一种非常实用的开发模式。所以,针对这个框架的开发,我们分多个版本来逐步完善。
《设计原则 - 10.实战:针对非业务的通用框架开发,如何做需求分析和设计及如何实现一个支持各种统计规则的性能计数器》中,我们实现了框架的第一个版本,它只包含最近的一些功能,在设计与实现上还有很不足。所以,下接下来,我们针对这些不足,继续迭代开发两个版本:版本 2 和版本 3,分别对应本章内容的第一节和第二节。
性能计数器项目 - 版本2
回顾版本 1 的设计与实现
先回顾下性能计数器项目版本 1 中的设计与实现。在版本 1 中,整个框架的代码被划分为下面这几个类。
MetricsCollector:负责打点采集原始数据,包括记录每次接口请求的响应时间和请求时间戳,并调用MetricsStorage的接口来存储这些原始数据。MetricsStorage和RedisMetricsStorage:负责原始数据的存储和读取。Aggregator是一个工具类,负责各种统计数据的计算,比如响应时间的最大值、最小值、平均值、百分位值、接口访问次数、tps。ConsoleReporter和EmailReporter相当于上地类,定时根据给定的时间区间,从数据库中读出数据,借助Aggregator类完成统计工作,并将统计结果输出到相应的终端,比如命令行、邮件。
MetricsCollector、MetricsStorage、RedisMetricsStorage 的设计与实现比较简单,不是版本 2 重构的重点。今天我们来看下 Aggregator、ConsoleReporter 和 EmailReporter 这几个类。
先看下 Aggregator 类存在的问题
Aggregator 类只有一个静态函数,有 50 行左右的代码,负责各种统计数据的计算。当要添加新的统计功能时,需要修改 genertate() 函数代码。一旦越来越多的统计功能添加进来后,这个函数的代码量会持续增加,可读性、可维护性就变差了。因此,我们需要在版本 2 中对其进行重构。
下面是 Aggregator 类重构前的代码。
public class Aggregator {
public static RequestStat aggregate(List<RequestInfo> requestInfos, long durationInMills) {
double maxRespTime = Double.MIN_VALUE;
double minRespTime = Double.MAX_VALUE;
double avgRespTime = -1;
double p999RespTime = -1;
double p99RespTime = -1;
double sumRespTime = 0;
long count = 0;
for (RequestInfo requestInfo : requestInfos) {
++count;
double respTime = requestInfo.getRespTime();
if (maxRespTime < respTime) {
maxRespTime = respTime;
}
if (minRespTime > respTime) {
minRespTime = respTime;
}
sumRespTime += respTime;
}
if (count != 0) {
avgRespTime = sumRespTime / count;
}
long tps = count / durationInMills * 100;
Collections.sort(requestInfos, new Comparator<RequestInfo>() {
@Override
public int compare(RequestInfo o1, RequestInfo o2) {
double diff = o1.getRespTime() - o2.getRespTime();
if (diff < 0.0) {
return -1;
} else if (diff > 0.0) {
return 1;
} else {
return 0;
}
}
});
int idx999 = (int) (count * 0.999);
int idx99 = (int) (count * 0.99);
if (count != 0) {
p99RespTime = requestInfos.get(idx99).getRespTime();
p999RespTime = requestInfos.get(idx999).getRespTime();
}
RequestStat requestStat = new RequestStat();
requestStat.setMaxRespTime(maxRespTime);
requestStat.setMinRespTime(minRespTime);
requestStat.setAvgRespTime(avgRespTime);
requestStat.setP999RespTime(p999RespTime);
requestStat.setP99RespTime(p99RespTime);
requestStat.setCount(count);
requestStat.setTps(tps);
return requestStat;
}
}
public class RequestStat {
private double maxRespTime;
private double minRespTime;
private double avgRespTime;
private double p999RespTime;
private double p99RespTime;
private double sumRespTime;
private long count;
private long tps;
// 省略构造函数、setter、getter
}
再看下 ConsoleReporter 和 EmailReporter 存在的问题
ConsoleReporter 和 EmailReporter 存在代码重复的问题。在这两个类中,从数据库中读取数据、做统计的逻辑都是相同的,可以抽取出来复用,否则就违反了 DRY 原则。
整个类负责的事情比较多,不相干的逻辑糅合在里面,职责不够单一。特别是显示部分的代码可能会比较复杂(比如 Email 的显示方式),最后能将这部分显示逻辑单独玻璃出来,设计成一个独立的类。
此外,因为代码中设计线程操作,且调用了 Aggregator 的静态函数,所以代码的可测试性也有待提高。
public class ConsoleReporter {
private MetricsStorage metricsStorage;
private ScheduledExecutorService executor;
public ConsoleReporter(MetricsStorage metricsStorage) {
this.metricsStorage = metricsStorage;
this.executor = Executors.newSingleThreadScheduledExecutor();
}
// 第4个代码逻辑:定义触发第1、2、3代码逻辑的执行
public void startRepeatedReport(long periodInSeconds, long durationInSeconds) {
executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
long durationInMillis = durationInSeconds * 1000;
long endTimeMillis = System.currentTimeMillis();
long startTimeMillis = endTimeMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos = metricsStorage.getRequestInfos(startTimeMillis, endTimeMillis);
Map<String, RequestStat> stats = new HashMap<>();
for (Map.Entry<String, List<RequestInfo>> entry : requestInfos.entrySet()) {
String apiName = entry.getKey();
List<RequestInfo> requestInfosApi = entry.getValue();
// 第2个代码逻辑:根据原始数据,计算得到统计数据
RequestStat requestStat = Aggregator.aggregate(requestInfosApi, durationInMillis);
stats.put(apiName, requestStat);
}
// 第3个代码逻辑:将统计数据显示到终端(命令行获邮件)
System.out.println("Time Span: [" + startTimeMillis + ", " + endTimeMillis + "]");
Gson gson = new Gson();
System.out.println(gson.toJson(stats));
}
}, 0, periodInSeconds, TimeUnit.SECONDS);
}
}
public class EmailReporter {
private static final Long DAY_HOURS_IN_SECONDS = 86400L;
private MetricsStorage metricsStorage;
private EmailSender emailSender;
private List<String> toAddresses = new ArrayList<>();
public EmailReporter(MetricsStorage metricsStorage) {
this.metricsStorage = metricsStorage;
this.emailSender = new EmailSender(/*省略参数*/);
}
public EmailReporter(MetricsStorage metricsStorage, EmailSender emailSender) {
this.metricsStorage = metricsStorage;
this.emailSender = emailSender;
}
public void addToAddress(String toAddress) {
toAddresses.add(toAddress);
}
public void startRepeatedReport(long periodInSeconds, long durationInSeconds) {
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.DATE, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
Date firstTime = calendar.getTime();
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
long durationInMillis = DAY_HOURS_IN_SECONDS * 1000;
long endTimeMillis = System.currentTimeMillis();
long startTimeMillis = endTimeMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos = metricsStorage.getRequestInfos(startTimeMillis, endTimeMillis);
Map<String, RequestStat> stats = new HashMap<>();
for (Map.Entry<String, List<RequestInfo>> entry : requestInfos.entrySet()) {
String apiName = entry.getKey();
List<RequestInfo> requestInfosApi = entry.getValue();
// 第2个代码逻辑:根据原始数据,计算得到统计数据
RequestStat requestStat = Aggregator.aggregate(requestInfosApi, durationInMillis);
stats.put(apiName, requestStat);
}
// 格式化为html格式,并发送邮件
}
}, firstTime, DAY_HOURS_IN_SECONDS * 1000);
}
}
针对版本 1 的问题进行重构
Aggregator 类和 ConsoleReporter、EmailReporter 类主要负责统计显示的工作。在《设计原则 - 10.实战:针对非业务的通用框架开发,如何做需求分析和设计及如何实现一个支持各种统计规则的性能计数器》中,我们提到,如果我们把统计显示所要完成的功能逻辑细分一下,主要包含下面 4 点:
- 根据给定的时间区间,从数据库中拉取数据;
- 根据原始数据,计算得到统计数据;
- 将统计数据显示到终端(命令行或邮件);
- 定时触发以上三个过程的执行。
之前的划分方法是将所有逻辑都放到 ConsoleReporter、EmailReporter 这两个上帝类中,而 Aggregator 只是一个包含静态方法的工具类。这样的划分方法存在前面提到的一些问题,我们需要对其进行重新划分。
面向对象设计的最后一步是组装类并提供执行入口,所以,组装前三部分逻辑的上帝类是必须要有的。我们可以将上帝类做的很轻量级,把核心逻辑都剥离出去,形成独立的类,上帝类只负责组装类和串联执行流程。这样做的好处是,代码结构更加清晰,底层核心逻辑更加容易被复用。按照这个设计思路,具体的重构工作包括 4 个方面。
第 1 个逻辑,根据给定的时间区间,从数据库中拉取数据。这部分逻辑已经被封装在 MetricsStorage 类中,所以这部分不需要处理。
第 2 个逻辑,根据原始数据,计算得到统计数据。我们可以将这部分逻辑移动到 Aggregator 类中。这样 Aggregator 类就不仅仅只包含方法的工具类了。按照这个思路,重构之后的代码如下所示:
public class Aggregator {
public Map<String, RequestStat> aggregate(
Map<String, List<RequestInfo>> requestInfos, long durationInMillis) {
Map<String, RequestStat> stats = new HashMap<>();
for (Map.Entry<String, List<RequestInfo>> entry : requestInfos.entrySet()) {
String apiName = entry.getKey();
List<RequestInfo> requestInfosApi = entry.getValue();
RequestStat requestStat = this.doAggregate(requestInfosApi, durationInMillis);
stats.put(apiName, requestStat);
}
return stats;
}
private RequestStat doAggregate(List<RequestInfo> requestInfos, long durationInMills) {
double maxRespTime = Double.MIN_VALUE;
double minRespTime = Double.MAX_VALUE;
double avgRespTime = -1;
double p999RespTime = -1;
double p99RespTime = -1;
double sumRespTime = 0;
long count = 0;
for (RequestInfo requestInfo : requestInfos) {
++count;
double respTime = requestInfo.getRespTime();
if (maxRespTime < respTime) {
maxRespTime = respTime;
}
if (minRespTime > respTime) {
minRespTime = respTime;
}
sumRespTime += respTime;
}
if (count != 0) {
avgRespTime = sumRespTime / count;
}
long tps = count / durationInMills * 100;
Collections.sort(requestInfos, new Comparator<RequestInfo>() {
@Override
public int compare(RequestInfo o1, RequestInfo o2) {
double diff = o1.getRespTime() - o2.getRespTime();
if (diff < 0.0) {
return -1;
} else if (diff > 0.0) {
return 1;
} else {
return 0;
}
}
});
int idx999 = (int) (count * 0.999);
int idx99 = (int) (count * 0.99);
if (count != 0) {
p99RespTime = requestInfos.get(idx99).getRespTime();
p999RespTime = requestInfos.get(idx999).getRespTime();
}
RequestStat requestStat = new RequestStat();
requestStat.setMaxRespTime(maxRespTime);
requestStat.setMinRespTime(minRespTime);
requestStat.setAvgRespTime(avgRespTime);
requestStat.setP999RespTime(p999RespTime);
requestStat.setP99RespTime(p99RespTime);
requestStat.setCount(count);
requestStat.setTps(tps);
return requestStat;
}
}
第 3 个逻辑,将统计数据显示到终端(命令行或邮件)。我们将这部分逻辑玻璃出来,设计成两个类:ConsoleViewer 和 EmailViewer 类,分别负责将统计结果显示到命令行和邮件中。具体的实现代码如下所示:
public interface StatViewer {
void output(Map<String, RequestStat> requestStats, long startTimeInMillis, long endTimeInMillis);
}
public class ConsoleViewer implements StatViewer {
@Override
public void output(Map<String, RequestStat> requestStats, long startTimeMillis, long endTimeMillis) {
System.out.println("Time Span: [" + startTimeMillis + ", " + endTimeMillis + "]");
Gson gson = new Gson();
System.out.println(gson.toJson(requestStats));
}
}
public class EmailViewer implements StatViewer{
private EmailSender emailSender;
private List<String> toAddresses = new ArrayList<>();
public EmailViewer() {
emailSender = new EmailSender(/*省略参数*/);
}
public EmailViewer(EmailSender emailSender) {
this.emailSender = emailSender;
}
public void addToAddress(String toAddress) {
toAddresses.add(toAddress);
}
@Override
public void output(Map<String, RequestStat> requestStats, long startTimeInMillis, long endTimeInMillis) {
// 格式化为html格式,并发送邮件
}
}
第 4 个逻辑,定时触发以上三个过程的执行。在讲核心逻辑剥离出来之后,这个类代码变得更加简洁、清晰,只负责组装各个类(MetricsStorage、Aggregator、StatViewer)来完成整个工作流程。重构之后的代码如下所示:
public class ConsoleReporter {
private MetricsStorage metricsStorage;
private Aggregator aggregator;
private StatViewer viewer;
private ScheduledExecutorService executor;
public ConsoleReporter(MetricsStorage metricsStorage, Aggregator aggregator, StatViewer viewer) {
this.metricsStorage = metricsStorage;
this.aggregator = aggregator;
this.viewer = viewer;
this.executor = Executors.newSingleThreadScheduledExecutor();
}
public void startRepeatedReport(long periodInSeconds, long durationInSeconds) {
executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
long durationInMillis = durationInSeconds * 1000;
long endTimeMillis = System.currentTimeMillis();
long startTimeMillis = endTimeMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos = metricsStorage.getRequestInfos(startTimeMillis, endTimeMillis);
Map<String, RequestStat> stats = aggregator.aggregate(requestInfos, durationInMillis);
viewer.output(stats, startTimeMillis, endTimeMillis);
}
}, 0, periodInSeconds, TimeUnit.SECONDS);
}
}
public class EmailReporter {
private static final Long DAY_HOURS_IN_SECONDS = 86400L;
private MetricsStorage metricsStorage;
private Aggregator aggregator;
private StatViewer viewer;
public EmailReporter(MetricsStorage metricsStorage, Aggregator aggregator, StatViewer viewer) {
this.metricsStorage = metricsStorage;
this.aggregator = aggregator;
this.viewer = viewer;
}
public void startDailyReport() {
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.DATE, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
Date firstTime = calendar.getTime();
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
long durationInMillis = DAY_HOURS_IN_SECONDS * 1000;
long endTimeMillis = System.currentTimeMillis();
long startTimeMillis = endTimeMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos = metricsStorage.getRequestInfos(startTimeMillis, endTimeMillis);
Map<String, RequestStat> stats = aggregator.aggregate(requestInfos, durationInMillis);
viewer.output(stats, startTimeMillis, endTimeMillis);
}
}, firstTime, DAY_HOURS_IN_SECONDS * 1000);
}
经过上面的重构之后,现在再来看下框架该如何使用。
我们需要再应用启动时,创建好 ConsoleReporter 对象,并调用它的 startRepeatedReport() 函数,来启动定时统计并输出数据到终端。同理,还需要创建好 EmailReporter 对象,并调用它的 startDailyReort() 函数,来启动每日统计并输出数据到指定邮件地址。我们通过 MetricsCollector 类来收集接口的访问情况,这部分收集代码会跟业务逻辑代码耦合在一起,或者同一放到类似 Spring AOP 的切面中完成。具体的使用代码如下:
public class PerfCounterTest {
public static void main(String[] args) {
MetricsStorage storage = new RedisMetricsStorage();
Aggregator aggregator = new Aggregator();
// 定时触发统计并将结果显示到终端
ConsoleViewer consoleViewer = new ConsoleViewer();
ConsoleReporter consoleReporter = new ConsoleReporter(storage, aggregator, consoleViewer);
consoleReporter.startRepeatedReport(60,60);
// 定时触发统计并将结果输出到邮件
EmailViewer emailViewer = new EmailViewer();
emailViewer.addToAddress("test@test.com");
EmailReporter emailReporter = new EmailReporter(storage, aggregator, emailViewer);
emailReporter.startDailyReport();
// 收集接口访问数据
MetricsCollector collector = new MetricsCollector(storage);
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("login", 123, 10234));
collector.recordRequest(new RequestInfo("login", 123, 10234));
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Review 版本 2 的设计与实现
重构之后,MetricsStorage 负责存储, Aggregator 负责统计,StatsViewer 负责显示,三个类各司其职。 ConsoleReportor 和 EmailReportor 负责组装这三个类,将获取原始数据、聚合统计、显示统计结构到终端这三个工作串联起来,定时触发执行。
此外,MetricsStorage、Aggregator、StatsViewer 三个类的设计也符合迪米特法则。它们只与跟自己有直接相关的数据进行交互。MetricsStorage 输入的是 RequestInfo 数据,输出的是 RequestStat 数据。StatsViewer 输入的是 RequestStat 数据。
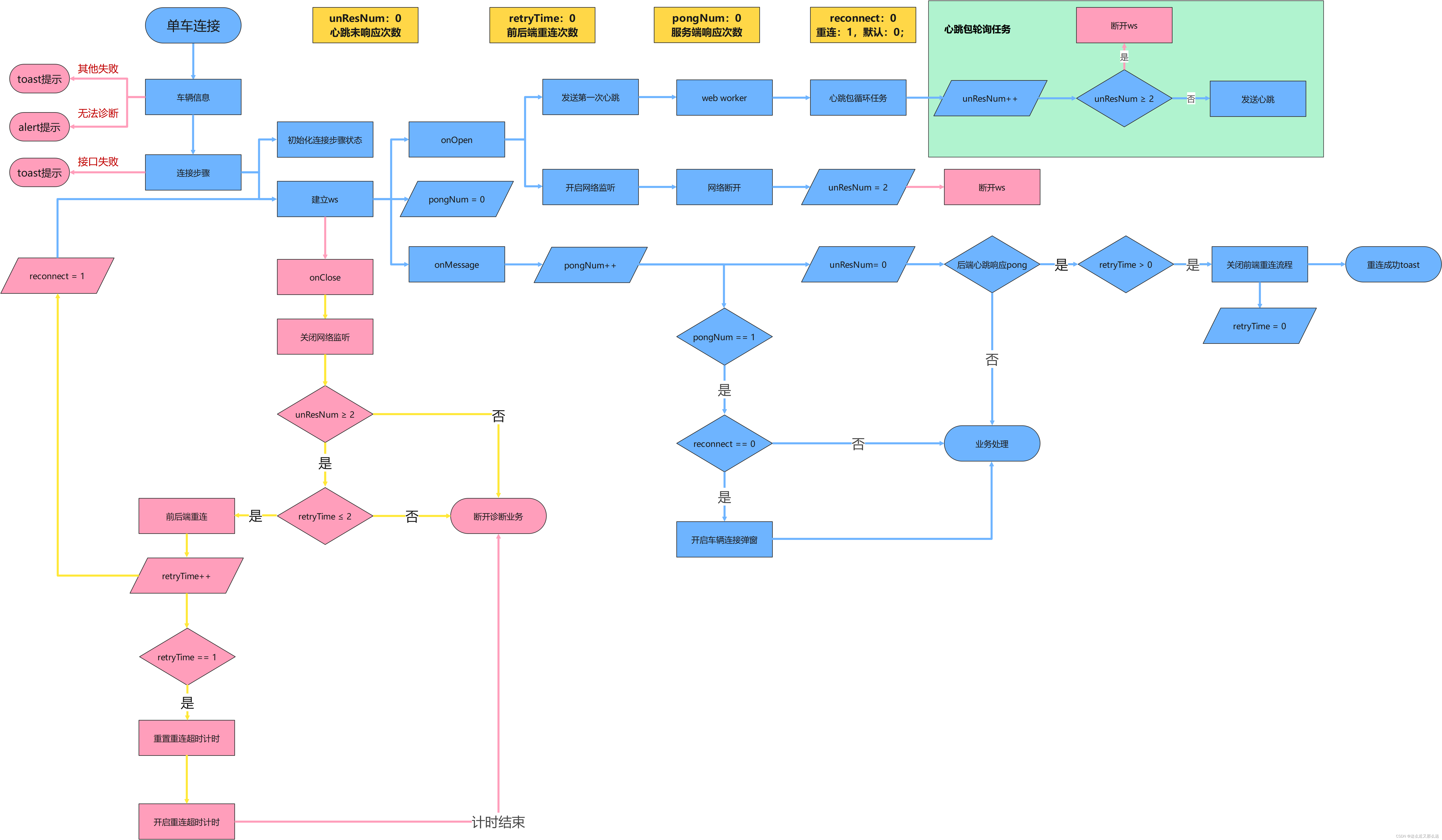
版本 1 和版本 2,我画了一张它们的类之间的依赖关系的对比图,如下所示。从图中,可以看出,重构之后的代码结构更加清晰、有条理。这也印证了之前提到的:面向对象设计和实现要做的事情,就是把合适的代码放到合适的类中。

刚刚分析了整体结构和依赖关系,现在再看下每个类的设计。
Aggregator 类从只包含一个静态函数的工具类,编程了一个普通的聚合统计类。现在,可以通过依赖注入的方式,将其组装进 ConsoleReportor 和 EmailReportor 类中,这样就更加容易编写单元测试。
Aggregator 类在重构前,所有的逻辑都集中在 aggregate() 函数内,代码行数较多,代码的可读性和可维护性较差。在重构之后,我们将每个统计逻辑拆分成独立的函数,aggregate() 函数变得单薄,可读性提高了。尽管我们要添加新的统计功能,还是要修改 aggregate() 函数,但现在的 aggregate() 函数代码行数很少,结构非常清晰,修改起来也更加容易,可维护性提高。
目前来看 Aggregator 的设计还算合理。但是,如果随着更多的统计功能的加入,Aggregator 类的代码会越来越多。这个时候,我们可以将统计函数剥离出来,设计成独立的类,以解决 Aggregator 类的无限膨胀问题。不过,暂时来说没有必要这么做,毕竟将每个统计函数独立成类,会增加类的个数,也会影响到代码的可读性。
ConsoleReportor 和 EmailReportor 经过重构之后,代码的重复问题变小了,但扔没有完全解决。尽管这两个类不再调用 Aggregator 的静态方法,但因为涉及多线程和时间相关的计算,代码的测试性仍不够好。
版本2重构回顾
面向对象设计中的最后一步是组装类并提供执行入口,也就是上帝类要做的事情。这个上帝类是没办法去掉的,但我们可以将上帝类做得很轻量级,把核心逻辑都剥离出去,下沉形成独立的类。上帝类只负责组装类和串联执行流程。这样做的好处是,代码结构更加清晰,底层核心逻辑更容易被复用。
面向对象设计和实现要做的事情,就是把合适的代码放到合适的类中。当我们要实现某个功能的时候,不管如何设计,所需要编写的代码量基本上是一样的,唯一的区别就是如何将这些代码划分到不同的类中。不同的人有不同的划分方法,对应得到的代码结构(比如类与类之间交互等)也不尽相同。
好的设计一定是结构清晰、有条理、逻辑性强,看起来一目了然,读完之后常常有一种原来如此的感觉。差的设计往往逻辑、代码乱塞一通,没有什么设计思路可言,看起来莫名其妙,读完之后一头雾水。
性能计数器项目 - 版本3
在版本 3 中,我们继续完善框架的功能和非功能需求。比如,让原始数据的采集和存储异步执行,解决聚合统计在数据量大的情况下会导致内存吃紧的问题,以提高框架的易用性等,让它成为一个能有且好用的框架。
代码重构优化
我们知道继承能解决代码重复的问题。可以将 ConsoleReportor 和 EmailReportor 中相同的代码逻辑,提取到父类 ScheduledReporter 中,以解决代码重复的问题。按照这个思路,重构之后的代码如下所示:
public abstract class ScheduledReporter {
protected MetricsStorage metricsStorage;
protected Aggregator aggregator;
protected StatViewer viewer;
public ScheduledReporter(MetricsStorage metricsStorage, Aggregator aggregator, StatViewer viewer) {
this.metricsStorage = metricsStorage;
this.aggregator = aggregator;
this.viewer = viewer;
}
protected void doStatAndReport(long startTimeInMillis, long endTimeInMillis) {
long durationInMillis = endTimeInMillis - startTimeInMillis;
Map<String, List<RequestInfo>> requestInfos = metricsStorage.getRequestInfos(startTimeInMillis, endTimeInMillis);
Map<String, RequestStat> stats = aggregator.aggregate(requestInfos, durationInMillis);
viewer.output(stats, startTimeInMillis, endTimeInMillis);
}
}
ConsoleReportor 和 EmailReportor 的代码重复问题解决了,我们在看下代码的可测试性。因为 ConsoleReportor 和 EmailReportor 的代码比较相似,且 EmailReportor 的代码更复杂,所以关于如何重构来提高其可测试性,我们拿 EmailReportor 来举例说明。将重复代码提取到父类 ScheduledReporter 之后,EmailReportor 代码如下所示:
public class EmailReporter extends ScheduledReporter {
private static final Long DAY_HOURS_IN_SECONDS = 86400L;
public EmailReporter(MetricsStorage metricsStorage, Aggregator aggregator, StatViewer viewer) {
super(metricsStorage, aggregator, viewer);
}
public void startDailyReport() {
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.DATE, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
Date firstTime = calendar.getTime();
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
long durationInMillis = DAY_HOURS_IN_SECONDS * 1000;
long endTimeMillis = System.currentTimeMillis();
long startTimeMillis = endTimeMillis - durationInMillis;
doStatAndReport(startTimeMillis, endTimeMillis);
}
}, firstTime, DAY_HOURS_IN_SECONDS * 1000);
}
}
前面说过, EmailReportor 的可测试不会,一方面时因为用到了线程(定时器也相当于多线程),另一方面是因为涉及时间的计算逻辑。
经过上一轮的重构之后, EmailReportor 中的 startDailyReport() 函数的核心逻辑已经被抽离出去了,较复杂、容易出 BUG 的就只剩下计算 firstTime 的那部分代码了。我们可以将这部分代码继续抽离出来,封装成一个函数,然后单独针对这个函数写单元测试。重构之后的代码如下:
public class EmailReporter extends ScheduledReporter {
// 省略其他代码...
public void startDailyReport() {
Date firstTime = trimTimeFieldToZeroOfNextDay();
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
// 省略其他代码...
}
}, firstTime, DAY_HOURS_IN_SECONDS * 1000);
}
// 设置成protected而非private是为了方便些单元测试
@VisibleForTesting
protected Date trimTimeFieldToZeroOfNextDay() {
Calendar calendar = Calendar.getInstance(); // 这里可以获取当前时间
calendar.add(Calendar.DATE, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
return calendar.getTime();
}
}
简单的代码抽离成 trimTimeFieldToZeroOfNextDay() 之后,虽然代码更加清晰了,一眼就能从名字上知道这段代码的意图(获取当前时间的下一天的 0 点时间),但是这个函数的可测试性仍然不好,因为它强依赖当前系统的时间。实际上,这个问题挺普遍的。一般的解决方法是,将强依赖的部分通过参数传递进来,有点类似依赖注入。按照这个思路,再对 trimTimeFieldToZeroOfNextDay() 进行重构。
public class EmailReporter extends ScheduledReporter {
// 省略其他代码...
public void startDailyReport() {
Date firstTime = trimTimeFieldToZeroOfNextDay(new Date());
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
// 省略其他代码...
}
}, firstTime, DAY_HOURS_IN_SECONDS * 1000);
}
// 设置成protected而非private是为了方便些单元测试
@VisibleForTesting
protected Date trimTimeFieldToZeroOfNextDay(Date date) {
Calendar calendar = Calendar.getInstance(); // 这里可以获取当前时间
calendar.setTime(date); // 重新设置时间
calendar.add(Calendar.DATE, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
return calendar.getTime();
}
}
经过这次重构之后, trimTimeFieldToZeroOfNextDay() 函数不再强依赖当前的系统时间,所以非常容易对其编写单元测试。
不过 ConsoleReportor 和 EmailReportor 还设计多线程操作,针对这个函数该如何写单元测试呢? 其实这个函数不需要些单元测试。
为什么这么说呢?
可以回到单元测试的初衷来分析这个问题。单元测试是为了提高代码质量,减少 bug。如果代码足够简单,简单到 bug 无处隐藏,那我们就没必要为了写单元测试而写单元测试,或者为了追求单元测试覆盖率而写单元测试。经过多次重构之后,startDailyReport() 函数里面已经没有多少代码逻辑了,所以完全没有必要对其写单元测试了。
功能需求完善
经过多个版本的迭代、重构,我们在 Review 下,目前的设计是否已经完全满足功能需求了。
最初的需求面试是下面这个样子的:
设计开发一个小的框架,能够获取接口调用的各种统计信息,比如,响应时间的最大值(max)、最小值(min)、平均值(avg)、百分位值(percentile)、接口调用次数(count)、频率(tps)等,并且支持将统计结果以各种显示格式(比如:JSON、网页格式、自定义显示格式等)输出到终端(Console、HTTP 网页、Email、日志文件、自定义输出终端等),以方便查看。
经过整理拆解之后的需求列表如下:
- 接口统计信息: 包括接口响应时间的统计信息,以及接口的调用次数的统计信息。
- 统计信息类型:max、min、avg、percentile、count、tps。
- 统计信息显示格式:JSON、HTML、自定义显示格式。
- 统计信息显示终端:Console、HTTP 网页、Email、日志文件、自定义输出终端。
经过挖掘,我们还得到一些隐藏的需求:
- 统计的触发方式:包括主动和被动。
- 主动表示以一定的频率定时统计数据,并主动推送到显示终端,比如邮件推送。
- 被动表示用户触发统计,比如用户在网页中选择要统计的时间区间,触发统计,并将结果显示给用户。
- 统计时间区间:框架需要支持自定义统计时间区间,比如统计最近 10 分钟的某接口 tps、访问次数,或者统计 3 月 7 日 00 点到 3 月 8 日 00 点之间某接口响应的最大值、最小值、平均值等。
- 统计时间间隔:对于主动触发统计,我们还要支持指定统计时间间隔,也就是多久触发一次统计显示。比如,每隔 10s 统计一次接口信息并显示到命令行中,每隔 24 小时发送一封统计信息邮件。
版本 3 已经实现了大部分的功能,还有一下几个小的功能没实现。你可以自己实现下。
- 被动触发统计的方式,也就是需求中提到的通过网页展示统计信息。实际上,这部分代码的实现也不难。我们可以复用框架现在的代码,编写一些展示页面和提供获取统计数据的接口接口。
- 对于自定义显示中断,比如显示数据到自己开发的监控平台,这就有点类似通过网页来显示数据,不过更加简单,只需要提供一些获取统计数据的接口,监控平台通过这些接口拉取数据来显示即可。
- 自定义显示格式。在框架现在的代码实现中,显示格式和显示终端(比如 Console、Email)是紧密耦合在一起的,比如,Console 只能通过 JSON 格式来显示统计数据,Email 只能通过某种固定的 HTML 格式显示数据,这样的设计还不够灵活。可以将显示格式设计成独立的类,将显示终端和显示格式的代码分离,让显示终端支持配置不同的显示格式。
非功能需求完善
非功能性需求包括:易用性、性能、扩展性、容错性、通用性。
1.易用性
所谓易用性,就是框架是否好用。框架的使用者将框架集成到自己的系统中,主要用到 MetricsCollector 和 EmailReporter 、 ConsoleReporter 这几个类。通过 MetricsCollector 类来采集数据,通过 EmailReporter 、 ConsoleReporter 类来触发主动统计数据、显示统计结果。
public class PerfCounterTest {
public static void main(String[] args) {
MetricsStorage storage = new RedisMetricsStorage();
Aggregator aggregator = new Aggregator();
// 定时触发统计并将结果显示到终端
ConsoleViewer consoleViewer = new ConsoleViewer();
ConsoleReporter consoleReporter = new ConsoleReporter(storage, aggregator, consoleViewer);
consoleReporter.startRepeatedReport(60,60);
// 定时触发统计并将结果输出到邮件
EmailViewer emailViewer = new EmailViewer();
emailViewer.addToAddress("test@test.com");
EmailReporter emailReporter = new EmailReporter(storage, aggregator, emailViewer);
emailReporter.startDailyReport();
// 收集接口访问数据
MetricsCollector collector = new MetricsCollector(storage);
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("login", 123, 10234));
collector.recordRequest(new RequestInfo("login", 123, 10234));
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
从上面的示例中,可以看出,框架用起来还是稍微有些复杂的,需要组织各种类,比如需要创建 MetricsStorage 对象、Aggregator 对象、ConsoleViewer 对象,然后注入到 ConsoleReporter 中,才能使用 ConsoleReporter。此外,还可能存在误用的情况,比如把 EmailViewer 传递进了 ConsoleReporter 中。总体上来讲,框架的使用暴露了太多的细节,过于灵活也带来了易用性的降低。
为了让框架使用简单,又不是灵活性,也不降低代码的可测试性,我们可以额外提供一些封装了默认依赖的构造函数,让使用者自主选择使用哪种构造函数来构造对象。
public class MetricsCollector {
private MetricsStorage metricsStorage; // 基于接口而非实现编程
// 兼顾代码的易用性,新增一个封装了默认依赖的构造函数
public MetricsCollector() {
this(new RedisMetricsStorage());
}
// 兼顾灵活性和代码的可测试性,这个代码继续保留
public MetricsCollector(MetricsStorage metricsStorage) {
this.metricsStorage = metricsStorage;
}
// ...
}
public class ConsoleReporter extends ScheduledReporter {
private ScheduledExecutorService executor;
// 兼顾代码的易用性,新增一个封装了默认依赖的构造函数
public ConsoleReporter() {
this(new RedisMetricsStorage(), new Aggregator(), new ConsoleViewer());
}
// 兼顾灵活性和代码的可测试性,这个代码继续保留
public ConsoleReporter(MetricsStorage metricsStorage, Aggregator aggregator, StatViewer viewer) {
this.metricsStorage = metricsStorage;
this.aggregator = aggregator;
this.viewer = viewer;
this.executor = Executors.newSingleThreadScheduledExecutor();
}
// ...
}
public class EmailReporter extends ScheduledReporter {
private static final Long DAY_HOURS_IN_SECONDS = 86400L;
// 兼顾代码的易用性,新增一个封装了默认依赖的构造函数
public EmailReporter(List<String> toAddresses) {
this(new RedisMetricsStorage(), new Aggregator(), new EmailViewer(toAddresses));
}
// 兼顾灵活性和代码的可测试性,这个代码继续保留
public EmailReporter(MetricsStorage metricsStorage, Aggregator aggregator, StatViewer viewer) {
this.metricsStorage = metricsStorage;
this.aggregator = aggregator;
this.viewer = viewer;
}
// ...
}
现在,再看下框架如何使用。
public class PerfCounterTest {
public static void main(String[] args) {
ConsoleReporter consoleReporter = new ConsoleReporter();
consoleReporter.startRepeatedReport(60,60);
List<String> toAddresses = new ArrayList<String>();
toAddresses.add("test@test.com");
EmailReporter emailReporter = new EmailReporter(toAddresses);
emailReporter.startDailyReport();
MetricsCollector collector = new MetricsCollector();
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("login", 123, 10234));
collector.recordRequest(new RequestInfo("login", 123, 10234));
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
不知道你发现每一行, RedisMetricsStorage 和 EmailViewer 还需要一些配置信息才能构建成功。这些配置信息可以放到配置文件中,在框架启动时,读取配置文件的配置信息到一个 Configuration 单例类。RedisMetricsStorage 和 EmailViewer 可以从这个 Configuration 类中获取需要的配置信息来构建自己。
2.性能
对于需要继承到业务系统的框架来说,不希望框架本身代码的执行效率,对业务系统有太多性能上的影响。对于性能计数器这个框架来说,一方面,希望它是低延迟的,也就是说统计代码不影响甚至很少会影响接口本身的响应时间;另一方面,希望框架本身对内存的消耗不能太大。
落实到具体的代码层面,需要解决两个问题:
- 一个是采集和存储要异步来执行,因为存储基于外部存储,会比较慢,异步存储可以降低对接口响应时间的影响。
- 另一个是当需要聚合统计的数据量比较大时,一次性加载太多的数据到内存,有可能会导致内存吃紧,甚至内存溢出,这样整个系统都会瘫痪掉。
针对第一个问题,我们通过在 MetricsCollector 中引入 Google Guava EventBus 来解决。
Google Guava EventBus可以看作是一个 “生产者-消费者” 模型,
采集的数据先放入内存共享队列中,两一个线程读取共享队列中的数据,写入到外部存储(如 Redis)中。具体的代码如下所示:
public class MetricsCollector {
private static final int DEFAULT_STORAGE_THREAD_POOL_SIZE = 20;
private MetricsStorage metricsStorage;
private EventBus eventBus;
public MetricsCollector() {
this(new RedisMetricsStorage(), DEFAULT_STORAGE_THREAD_POOL_SIZE);
}
public MetricsCollector(MetricsStorage metricsStorage, int threadNumToSaveData) {
this.metricsStorage = metricsStorage;
this.eventBus = new AsyncEventBus(Executors.newFixedThreadPool(threadNumToSaveData));
this.eventBus.register(new EventListener());
}
public void recordRequest(RequestInfo requestInfo) {
if (requestInfo == null || StringUtils.isBlank(requestInfo.getApiName())) {
return;
}
this.eventBus.post(requestInfo);
}
public class EventListener {
@Subscribe
public void saveRequestInfo(RequestInfo requestInfo) {
metricsStorage.saveRequestInfo(requestInfo);
}
}
}
针对第二个问题,解决的思路比较简单,但代码实现稍微有点复杂。当统计的时间间隔较大时,需要统计的数据量就会比较大。我们可以将其划分为一些小的时间区间(比如以10分钟为一个统计单元),针对每个小的时间分别进行统计,然后将统计得到的结果再进行聚合,得到最终整个时间区间的统计结果。不过这个思路只适合响应时间的 max、min、avg,及接口请求 count、tps 的统计,对应响应时间 percentile 的统计并不适用。
对于 percentile 的统计要复杂一些,具体的解决思路是这样的: 分批从 Redis 中读取数据,然后存储到本地文件中,再根据响应时间从小到大利用外部排序算法来进行排序。排序完成之后,再从文件中读取第 count*percentile 个数据,就是对应的 percentile 响应时间。
count 表示总的数据个数,percentile 就是百分比,99百分位就是 0.99。
这里只给出了除 percentile 的统计信息的计算代码。对于 percentile 的计算,你可以自己实现。
public abstract class ScheduledReporter {
private static final long MAX_STAT_DURATION_IN_MILLIS = 10 * 60 * 1000; // 10 minutes
protected MetricsStorage metricsStorage;
protected Aggregator aggregator;
protected StatViewer viewer;
public ScheduledReporter(MetricsStorage metricsStorage, Aggregator aggregator, StatViewer viewer) {
this.metricsStorage = metricsStorage;
this.aggregator = aggregator;
this.viewer = viewer;
}
protected void doStatAndReport(long startTimeInMillis, long endTimeInMillis) {
Map<String, RequestStat> stats = doStat(startTimeInMillis, endTimeInMillis);
viewer.output(stats, startTimeInMillis, endTimeInMillis);
}
private Map<String, RequestStat> doStat(long startTimeInMillis, long endTimeInMillis) {
Map<String, List<RequestStat>> segmentStats = new HashMap<>();
long segmentStartTimeMillis = startTimeInMillis;
while (segmentStartTimeMillis <= endTimeInMillis) {
long segmentEndTimeMillis = segmentStartTimeMillis + MAX_STAT_DURATION_IN_MILLIS;
if (segmentEndTimeMillis > endTimeInMillis) {
segmentEndTimeMillis = endTimeInMillis;
}
Map<String, List<RequestInfo>> requestInfos =
metricsStorage.getRequestInfos(segmentStartTimeMillis, segmentEndTimeMillis);
if (requestInfos == null || requestInfos.isEmpty()) {
continue;
}
Map<String, RequestStat> segmentStat = aggregator.aggregate(requestInfos,
segmentEndTimeMillis - segmentStartTimeMillis);
addStat(segmentStats, segmentStat);
segmentStartTimeMillis += MAX_STAT_DURATION_IN_MILLIS;
}
long durationInMillis = endTimeInMillis - startTimeInMillis;
Map<String, RequestStat> aggregatedStats = aggregateStats(segmentStats, durationInMillis);
return aggregatedStats;
}
private void addStat(Map<String, List<RequestStat>> segmentStats, Map<String, RequestStat> segmentStat) {
for (Map.Entry<String, RequestStat> entry : segmentStat.entrySet()) {
String apiName = entry.getKey();
RequestStat stat = entry.getValue();
List<RequestStat> statList = segmentStats.putIfAbsent(apiName, new ArrayList<>());
statList.add(stat);
}
}
private Map<String, RequestStat> aggregateStats(Map<String, List<RequestStat>> segmentStats, long durationInMillis) {
Map<String, RequestStat> aggregatedStats = new HashMap<>();
for (Map.Entry<String, List<RequestStat>> entry : segmentStats.entrySet()) {
String apiName = entry.getKey();
List<RequestStat> apiStats = entry.getValue();
double maxRespTime = Double.MIN_VALUE;
double minRespTime = Double.MAX_VALUE;
long count = 0;
long sumRespTime = 0;
for (RequestStat stat : apiStats) {
if (stat.getMaxRespTime() > maxRespTime) {
maxRespTime = stat.getMaxRespTime();
}
if (stat.getMinRespTime() < minRespTime) {
minRespTime = stat.getMinRespTime();
}
count += stat.getCount();
sumRespTime += stat.getSumRespTime();
}
RequestStat aggregatedStat = new RequestStat();
aggregatedStat.setMaxRespTime(maxRespTime);
aggregatedStat.setMinRespTime(minRespTime);
aggregatedStat.setAvgRespTime(sumRespTime / count);
aggregatedStat.setCount(count);
aggregatedStat.setTps(count / durationInMillis * 1000);
aggregatedStats.put(apiName, aggregatedStat);
}
return aggregatedStats;
}
}
3.扩展性
框架的扩展性有别于代码的扩展性,它是从使用者角度来讲的,特指使用者可以在不修改框架源码,甚至拿不到框架源码的情况下为框架扩展性功能。
在上面给出了框架如何使用的示例。从示例中,可以发现,框架在兼顾易用性的同时,也可以灵活地替换各种类对象,比如 MetricsStorage、StatsViewer 。比如说,我们想要让框架基于 HBase 来存储原始数据而非 Redis,那我们只需要设计一个实现 MetricsStorage 接口的 HBaseMetricsStorage,传递给 MetricsCollertor 和 ConsoleReportor、EmailReportor 类即可。
4.容错性
容错性非常重要。对于框架来说,不能因为框架本身的异常导致接口请求出错。所以,对框架可能存在的各种情况,需要考虑全面。
性能计数器项目,采集和存储是异步执行的,即便 Redis 挂掉或者写入超时,也不会影响到接口的正常响应。此外,Redis 异常,可能会影响到数据统计显示,但并不会影响到接口的响应。
5.通用性
为了提高框架的复用性,能够灵活应用到各种场景中,框架在设计的时候,要尽可能通用。我们要多思考下,除了接口统计这个需求外,框架还可以适用到其他哪些场景中。比如,是否还可以处理其他事件的统计信息。例如 SQL 请求时间的统计、业务统计(比如支付成功率)等。关于这一点,你可以自己思考一下,本课程没有讲到这块。
版本 3-总结
在《设计原则 - 10.实战:针对非业务的通用框架开发,如何做需求分析和设计及如何实现一个支持各种统计规则的性能计数器》,我们提到,针对性能计数器这个框架的开发,要想一下子罗列所有的功能,对任何人来说是比较有挑战的。经过这几次版本的迭代后,不知不觉地就完成了几乎所有的需求,包括功能性需求和非功能性需求。
《设计原则 - 10.实战:针对非业务的通用框架开发,如何做需求分析和设计及如何实现一个支持各种统计规则的性能计数器》的第一小节,我们实现了一个最小原型,虽然简陋,所有的代码都塞在一个类中,但它帮我们理清了需求。
《设计原则 - 10.实战:针对非业务的通用框架开发,如何做需求分析和设计及如何实现一个支持各种统计规则的性能计数器》的第二小节,实现了框架的第 1 个版本,这个版本只包含最基本的功能,并且初步利用面向对象方法,把不同功能的代码划分到了不同的类中。
在本章第 1 小节,我们实现了框架的第 2 个版本,这个版本对第 1 个版本的代码结构进行了比较大的调整,让整体代码结构更加合理、清晰、有逻辑性。
在本章第 2 小节,我们实现了框架的第 3 个版本,对版本 2 遗留的细节问题进行了重构,并且重构点解决了框架的易用性和性能问题。
从上面的迭代过程可以发现,大部分情况下,我们都是针对问题解决问题,每个版本都聚焦一小部分,所以整个代码也没有感觉有太大难度。尽管迭代了 3 个版本,但目前的设计和实现还有很多进一步优化和完善的地方,后续优化的工作留给你自行完成。
最后,这个项目希望你不仅仅关注这个框架本身的设计和实现,更重要的是学会逐步优化的方法,以及其中涉及的一些编程技巧、设计思路,能举一反三地用在其他项目中。