LLM4Decompile: Decompiling Binary Code with Large Language Models
相关链接:arxiv github
关键字:反编译、大型语言模型、二进制代码、源代码、程序语义
摘要
LLM4Decompile是一种使用大型语言模型(LLMs)进行二进制代码反编译的方法。该方法旨在将编译后的机器代码或字节码转换回高级编程语言。LLM4Decompile通过级联三个生成对抗网络(GANs)来处理低分辨率的汇编代码,并通过频带扩展和立体声混音将其上采样为高分辨率的源代码。与以往的工作相比,LLM4Decompile提出了一个统一的基于GAN的生成器和鉴别器架构,以及每个阶段的训练过程。此外,还提出了一种新的快速、与循环一致的频带扩展模块,以及一种新的快速循环一致的单声道到立体声模块,确保输出中保留单声道内容。通过客观和主观的听力测试评估了该方法,并发现其在音频质量、空间化控制方面具有可比性或更优,并且推理速度显著快于以往的工作。
核心方法
- 大型语言模型(LLMs)的应用:利用LLMs处理编程任务,将编译后的代码恢复到人类可读的源代码形式。
- LLM4Decompile模型:发布了第一个开源的LLM,专门用于反编译,预训练在4亿个C源代码和相应的汇编代码的标记上。
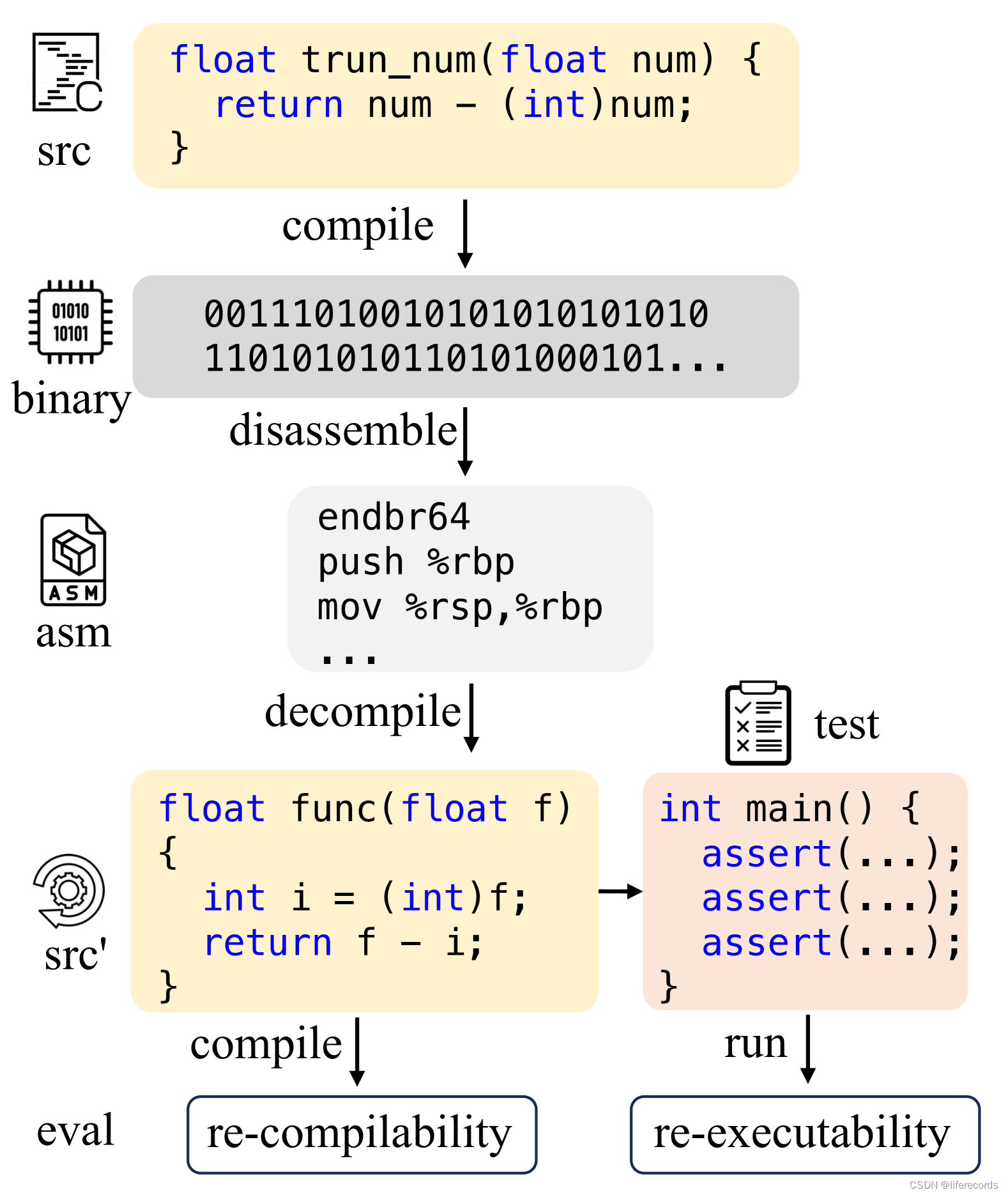
- Decompile-Eval数据集:引入了第一个考虑重新编译和重新执行的反编译数据集,强调从程序语义的角度评估反编译模型的重要性。
实验说明
实验使用了AnghaBench(一个包含一百万可编译C文件的公共集合)来构建汇编-源代码对。通过GCC编译器的不同配置将源代码编译成汇编代码。然后,使用objdump工具将汇编指令反汇编为人类可读的源代码格式。为了评估反编译代码的质量,测试其能否成功重新编译,并在测试用例中通过所有断言。
实验结果数据
| 模型 | 可重新编译性 | 可重新执行性 |
|---|---|---|
| GPT-4 | 0.895 | 0.085 |
| DeepSeek-Coder-33B | 0.113 | 0.000 |
| LLM4Decompile-1B | 0.864 | 0.105 |
| LLM4Decompile-6B | 0.873 | 0.214 |
| LLM4Decompile-33B | 0.820 | 0.214 |
结论
LLM4Decompile是第一个专门用于反编译的开源大型语言模型,它在构建的反编译基准上展示了其能力,特别是在重新编译和重新执行方面。通过在多样化的编译C代码数据集上的分析,LLM4Decompile展示了其在语法理解和语义保留方面的潜力。作为数据驱动反编译的初步探索,我们的工作建立了一个开放的基准,以激励未来的努力。公共数据集、模型和分析代表了向通过新颖技术增强反编译迈出的鼓舞人心的第一步。