首先讲下 ES的倒排序索引
入门-倒排索引
正排索引(传统)
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
倒排索引
| keyword | id |
|---|---|
| name | 1001, 1002 |
| zhang | 1001 |
正排索引:我想查name,这时候是模糊的查询,会循环遍历并且同时也会使索引失效
倒排索引:我相查name,这时候直接就查到id==1001,1002,然后再关联文章内容
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。 为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。
es, 倒排索引优点
倒排索引是不可更改的,一旦它被建立了,里面的数据就不会再进行更改。这样做就带来了以下几个好处:
1. 不用给索引加锁,因为不允许被更改,只有读操作,所以就不用考虑多线程导致互斥等问题。
2. 索引一旦被加载到了缓存中,大部分访问操作都是对内存的读操作,省去了访问磁盘带来的io开销。
3. 倒排索引具有不可变性,所有基于该索引而产生的缓存也不需要更改,因为没有数据变更。
4. 倒排索引可以压缩数据,减少磁盘io及对内存的消耗。
如何在ES上创建索引
首先打开kibanba
进入到控制台然后开始创建索引
之前说过es中索引对应的是mysql的数据库,所以我们应该先创建索引
创建索引语法:put shooping
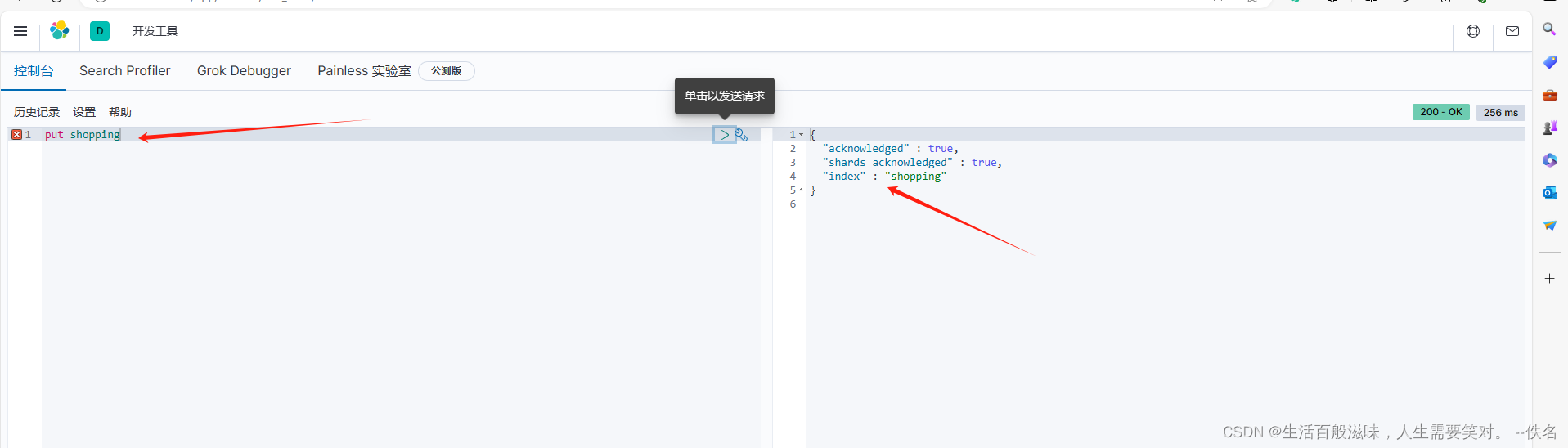
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "shopping"
}
会返回这几个字段,分别代表
acknowledged:代表是创建索引创建成功
shards_acjnowledged: 代表所有分片创建成功
index:代表索引的名字
然后再次put的,会出现这种情况 put是具有幂等性的

{
"error" : {
"root_cause" : [
{
"type" : "resource_already_exists_exception",
"reason" : "index [shopping/32XXUAigSX-96lF9wV49Aw] already exists",
"index_uuid" : "32XXUAigSX-96lF9wV49Aw",
"index" : "shopping"
}
],
"type" : "resource_already_exists_exception",
"reason" : "index [shopping/32XXUAigSX-96lF9wV49Aw] already exists",
"index_uuid" : "32XXUAigSX-96lF9wV49Aw",
"index" : "shopping"
},
"status" : 400
}
error:表示错误
root_cause:表示错误的列表
type:表示错误类型
reason:错误的原因
index_uuid:唯一标识
index:索引名字
如果想用post请求会发送什么,post是不具有幂等性的

Incorrect HTTP method for uri [/shopping?pretty=true] and method [POST], allowed: [HEAD, PUT, GET, DELETE]",
方法不能使用post,直接报错
查询索引语法:get shopping

{
"shopping" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1710766914710",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "32XXUAigSX-96lF9wV49Aw",
"version" : {
"created" : "7080099"
},
"provided_name" : "shopping"
}
}
}
}
shopping:索引名字
aliases:索引别名
mappings:意识就是文档结构和字段类型
settings:设置索引的信息
index:索引级的设置
creation_date:创建时间
number_of_shards:索引分片的数量
number_of_replicas:每个分片的副本数量
uuid:uuid
version:版本号
provided_name:提供的索引名字
查询全部索引语法:get _cat/indices?v

表头 含义
health 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
status 索引打开、关闭状态
index 索引名
uuid 索引统一编号
pri 主分片数量
rep 副本数量
docs.count 可用文档数量
docs.deleted 文档删除状态(逻辑删除)
store.size 主分片和副分片整体占空间大小
pri.store.size 主分片占空间大小
删除索引语法:delete shopping
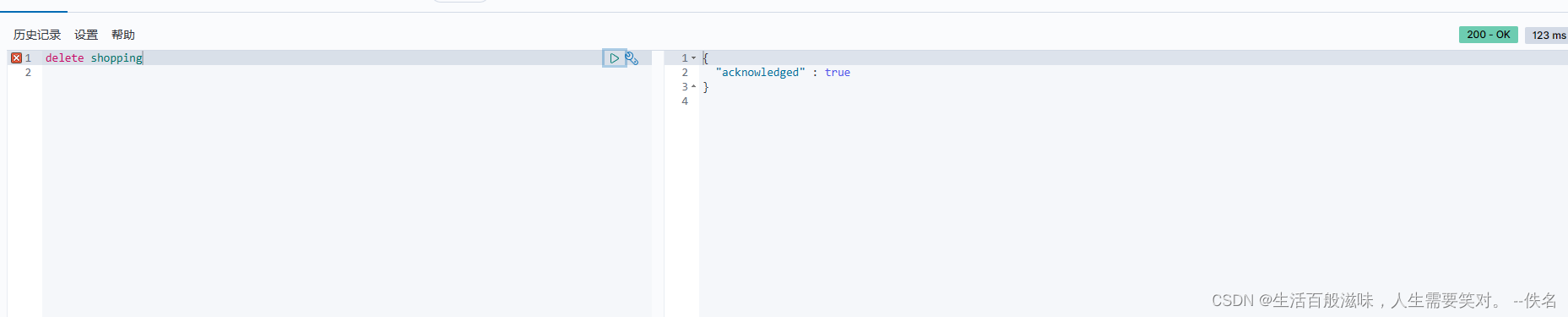
{
"acknowledged" : true
}
acknowledged:是否成功
创建es数据语法:post /shopping/_doc
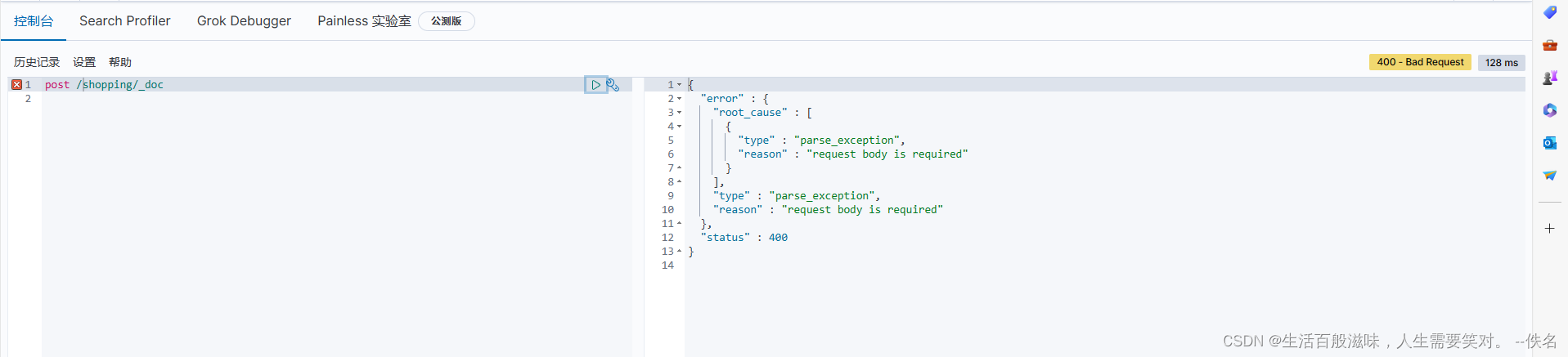
{
"error" : {
"root_cause" : [
{
"type" : "parse_exception",
"reason" : "request body is required"
}
],
"type" : "parse_exception",
"reason" : "request body is required"
},
"status" : 400
}
文档对应的是数据库中数据
这个原因就是没有body数据,并且我们传递数据是json
试着这种修改一下
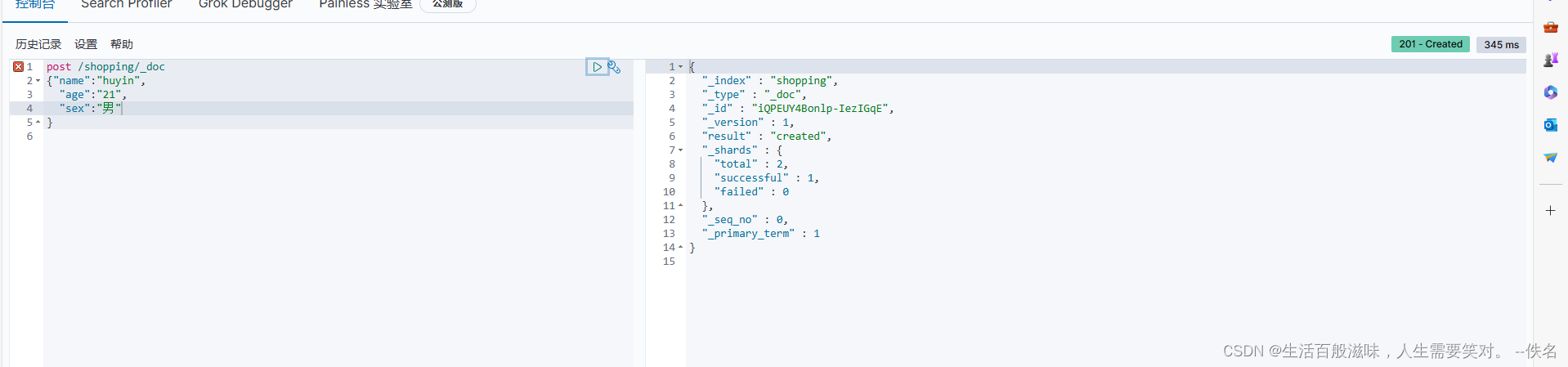
{
"_index" : "shopping",
"_type" : "_doc",
"_id" : "iQPEUY4Bonlp-IezIGqE",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
index:索引
type:文档
id:唯一标识
result:结果
shards:分配
total:分片总数
successful:成功数量
failed:失败数量
seq_no:文档序列号,序列号越大标识越新
_primary_term:文档所属的主要分片的任期号
当在发送一模一样的请求
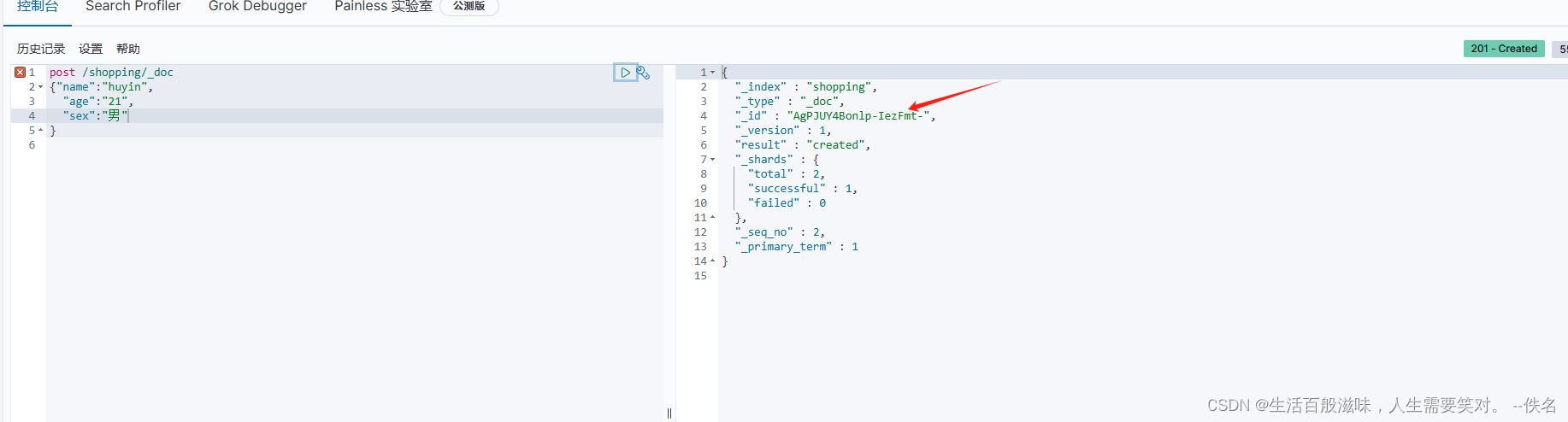
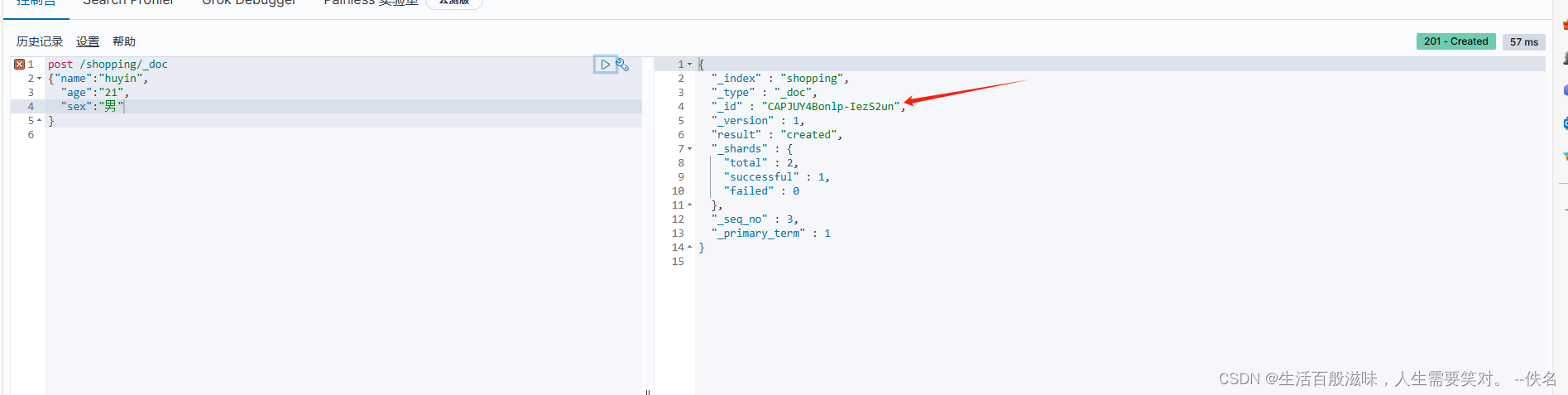
id一直在变化,如果我们想查询某个数据,id太麻烦了,如果想自定义呢
创建es数据指定id语法:post /shopping/_doc/1001

如果我们指定了id,这时候就可以用put,因为他是幂等性

主键查询和全局查询语法
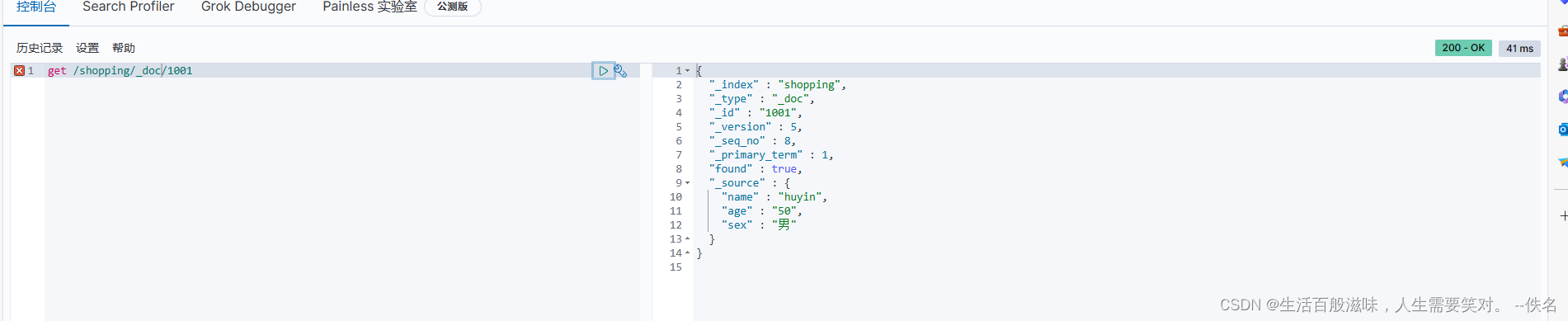
主键查询:get /shopping/_doc/1001
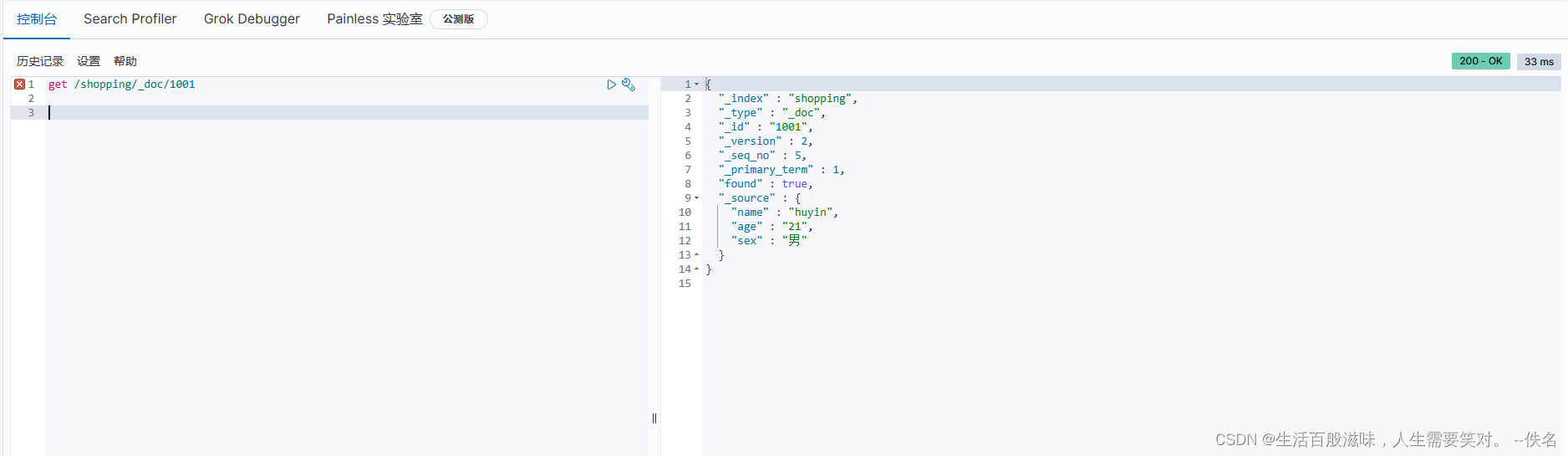
{
"_index" : "shopping", //索引
"_type" : "_doc", //类型
"_id" : "1001", //id
"_version" : 2, //版本号
"_seq_no" : 5, //序列号
"_primary_term" : 1,
"found" : true, //成功
"_source" : { //信息
"name" : "huyin",
"age" : "21",
"sex" : "男"
}
}
查询没有的数据
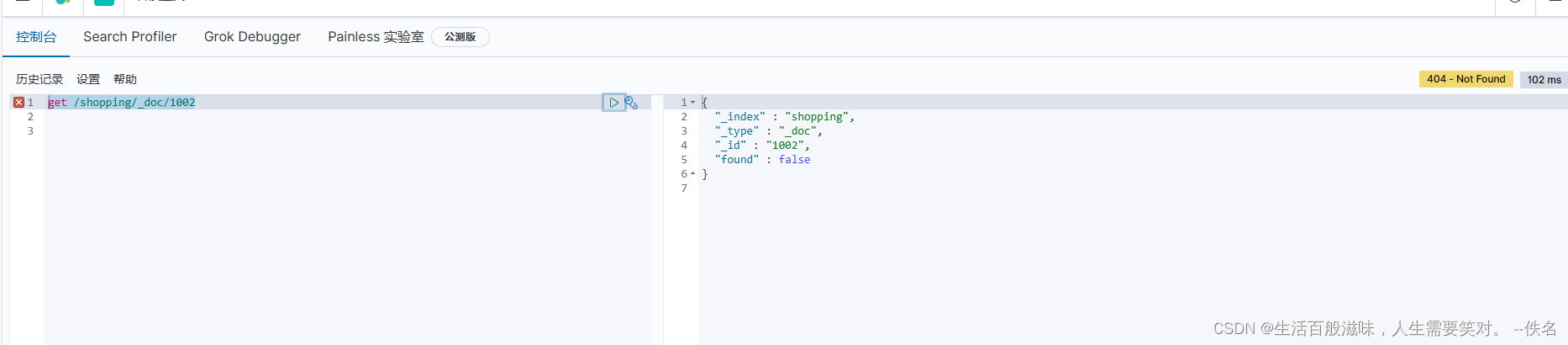
{
"_index" : "shopping",
"_type" : "_doc",
"_id" : "1002",
"found" : false
}
查询全部数据语法:get /shopping/_search

{
"took" : 0, // 耗时
"timed_out" : false, // 超时
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [ //命中
{
"_index" : "shopping",
"_type" : "_doc",
"_id" : "iQPEUY4Bonlp-IezIGqE",
"_score" : 1.0,
"_source" : {
"name" : "huyin",
"age" : "21",
"sex" : "男"
}
},
{
"_index" : "shopping",
"_type" : "_doc",
"_id" : "AQPJUY4Bonlp-IezE2v3",
"_score" : 1.0,
"_source" : {
"name" : "huyin",
"age" : "21",
"sex" : "男"
},
]
}
}
全局修改和局部修改语法
全局修改:put /shopping/_doc/1001
put具有幂等性所以可以用
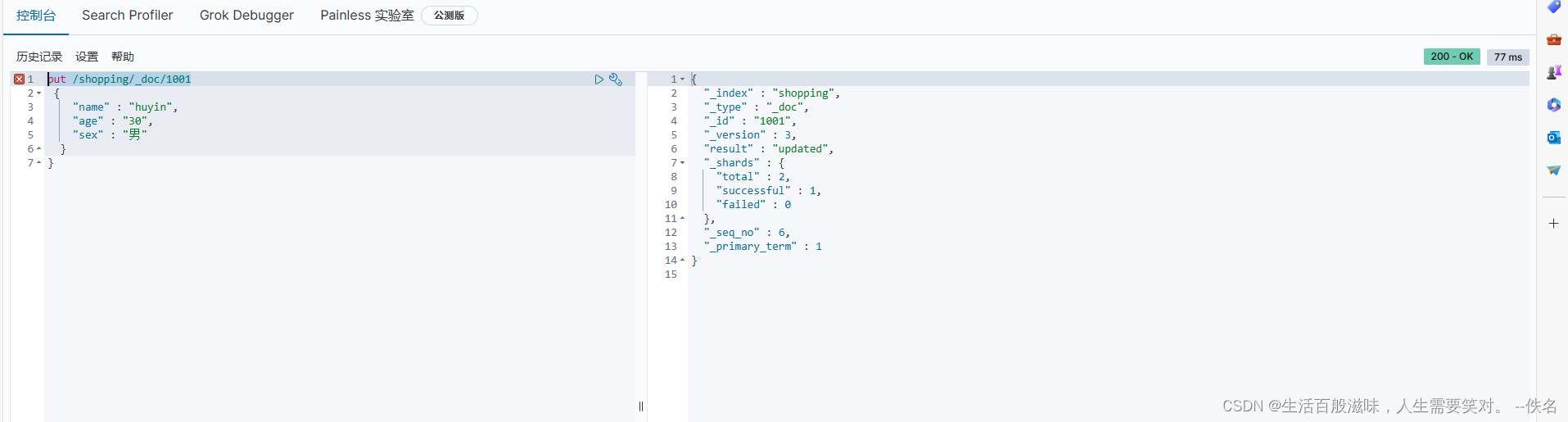
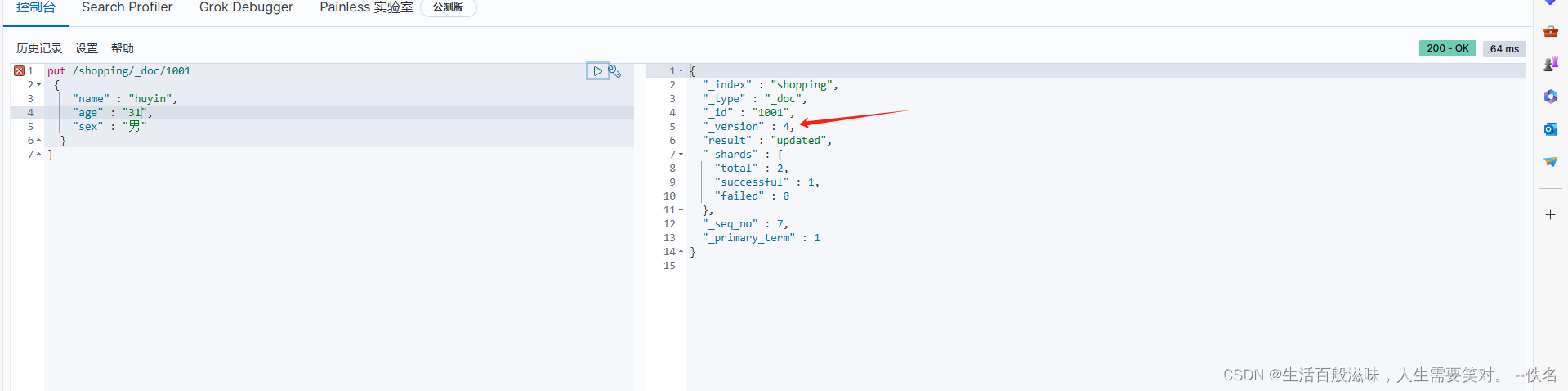 {
{
"_index" : "shopping",
"_type" : "_doc",
"_id" : "1001",
"_version" : 3, // 版本号是一直变化的
"result" : "updated", 结果:updated 修改
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 1
}
局部修改:post /shopping/_update/1001
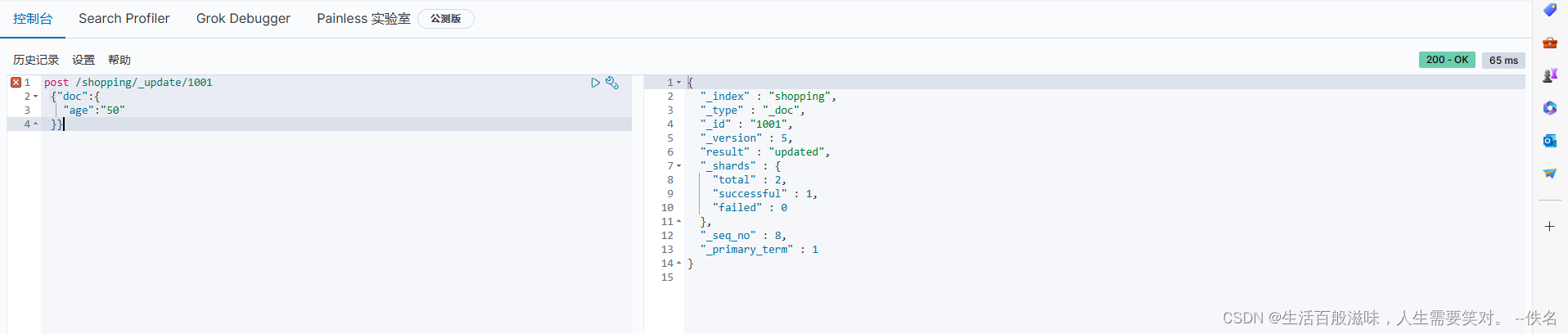
get请求一个:get /shopping/_doc/1001