String编码转换底层原理
String对象为什么把大于39字节或者44字节的字符串编码为raw,小于的时候编码为embstr?
在Redis3.2以前的版本中,SDS作为字符串类型中存储字符串内容的结构,源码如下:
3.2版本SDS结构
struct sdshdr {
// 记录buf数组中已使用字节的数量
// 等于SDS保存字符串的长度 4byte
int len;
// 记录buf数组中未使用字节的数量 4byte
int free;
// 字节数组,用于保存字符串 字节\0结尾的字符串占用了1byte
char buf[];
}
Redis对象头
一个字符串对象不仅仅包含SDS结构,还包含了RedisObject(Redis对象头),这时每个Redis对象都要携带的一种结构跟Java对象类似,Java对象也有相应的对象头,它的结构如下
// Redis对象
typedef struct redisObject {
// 类型 4bits; 即【String、List、Hash、Set、Zset】中的一个
unsigned type:4
// 编码方式 4 bits, encoding表示对象底层所使用的编码
unsigned encoding:4;
// LRU时间(相对于server.lrulock) 24bits;
unsigned lru:24;
// 引用计数 Redis里面的数据可以通过引用计数进行共享 32bits
int refcount;
// 指向对象的值 64bit
void* ptr;
} robj; // 16bytes
操作系统中的内存分配
由于操作系统使用jmalloc和tmalloc进行内存的分配,而内存分配的单位都是2的N次方,所以是2,4,8,16,32,64,如果Redis采取32字节分配的化,那么32-16(RedisObject)-9(3.2版本的SDS)=7,相当于可使用字节数为7字节,Redis认为太过于小了,所以Redis采取分配的是64字节,即64-25=39。
SDS结构优化
在Redis之后的版本中,为了进一步优化字符串对象在一次操作系统的内存分配中扩大可使用的空间,又将sdshdr分为了sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64结构如下
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
// 一些变量的定义
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
结构示例图
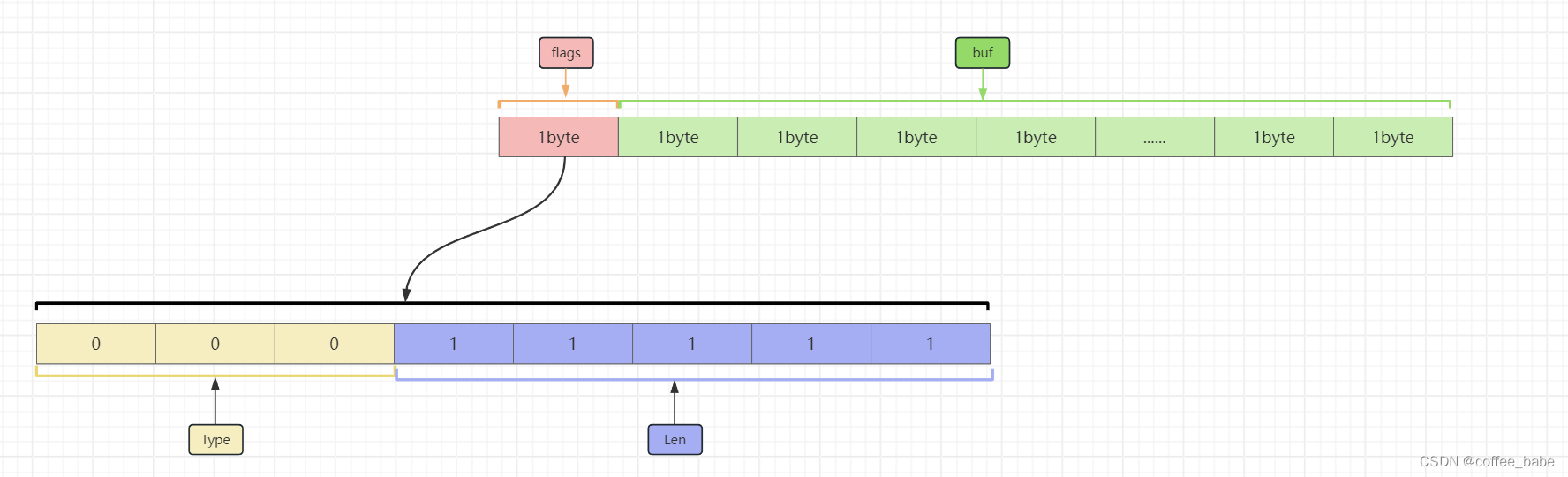
- sdshdr5的结构如图
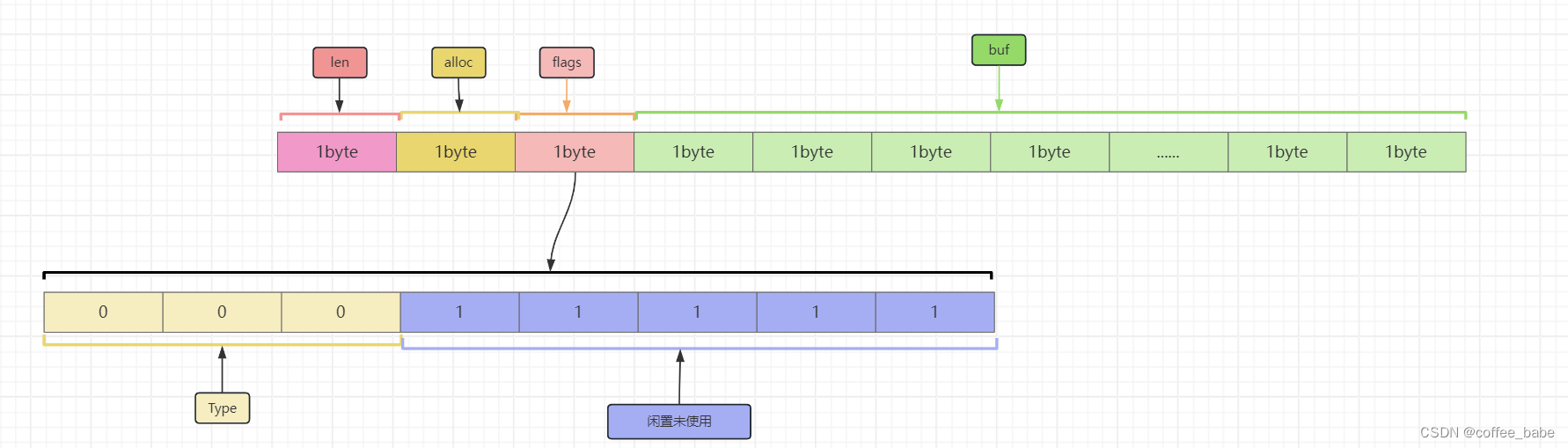
- sdshdr8的结构如图
疑惑解答
有人可能会问既然分出来这么多的结构,如果用sdshdr5的结构,那么64-16-1-1=46个字节,跟平常说的44个字节不一样,如果我们用sdshdr5的结构,那么这个结构的flags中只有5个bit可以让我们使用,
表示的空间地址就是2^5=32个长度,表示的空间太小了,所以我们得用sdshdr8的结构那么可以表示的空间地址
将会是2^8=256,但实际上,在Redis内部中,键是使用sdshdr5的结构,因为键不大可能会更新,而值会经常更新,所以干脆直接sdshdr8来表示值对象
Redis6.0新特性
多线程
概述
redis6.0提供了多线程的支持,redis6以前的版本,严格来说也是多线程,只不过执行用户命令的请求是单线程模型,还有一些线程用来执行后台任务,比如unlink删除大key,rdb持久化等
redis6.0提供了多线程的读写IO,但是最终执行用户命令的线程依然是单线程的,这样,就没有多线程数据的竞争关系,依然很高效
线程模型

- redis6.0以前线程执行模式,如下操作再一个线程中执行完成
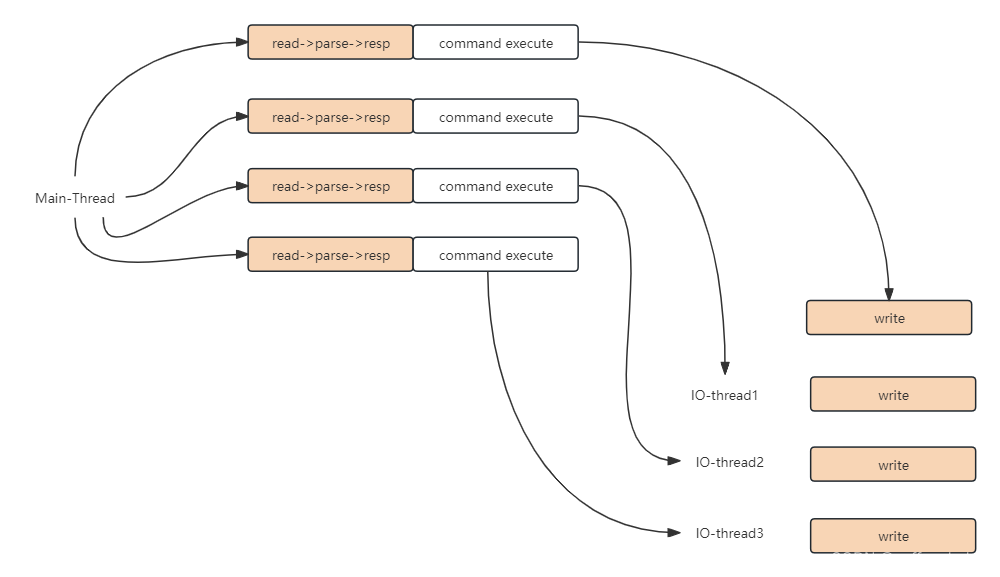
- redis6.0线程执行模式:
参数配置
可以通过如下参数配置多线程模型:
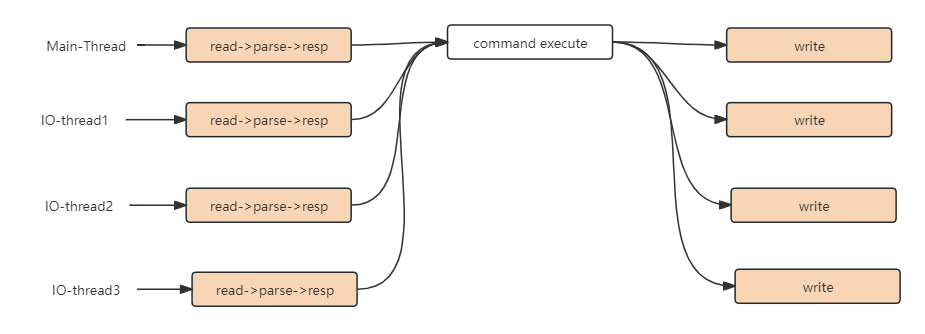
io-threads 4 // 这里说 有三个IO线程,还有一个线程是main线程,main线程负责IO读写和命令执行操作
默认情况下,如上配置,有三个IO线程,这三个IO线程只会执行IO中的write操作,也就是说,read和命令执行都由main线程执行,最后多线程讲数据写回客户端。
开启了如下参数:
io-threadas-do-reads yes // 将支持IO线程执行 读写任务
Client side caching(客户端缓存)
概述
redis6提供了服务端追踪key的变化,客户端缓存数据的特性,这需要客户端实现
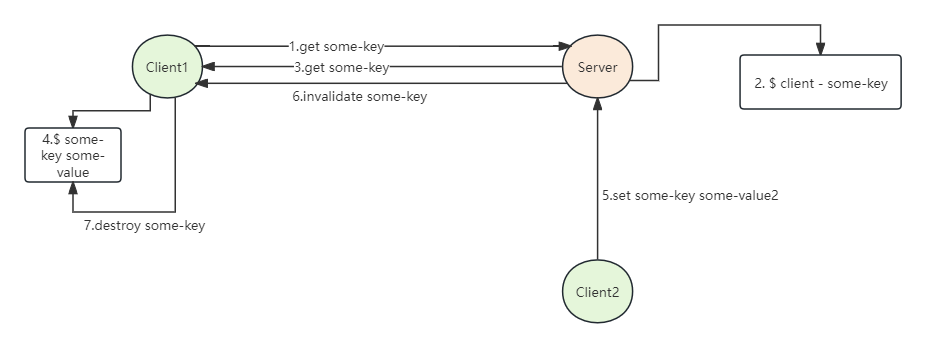
执行流程
当客户端访问某个key时,服务端将记录key和client,客户端拿到数据后,进行客户端缓存,这时,当key再次被访问时,key将被直接返回,避免了与redis服务器的再次交互,节省服务端资源,当数据被其他请求修改时,服务端将主动通知客户端失效的key,客户端进行本地失效,下次请求时,重新获取最新数据目前只有lettuce对其进行了支持:
代码示例
- 依赖导入
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce‐core</artifactId>
<version>6.0.0.RELEASE</version>
</dependency>
- Java代码
public class Main {
public static void main(String[] args) {
RedisClient redisClient = RedisClient.create("redis://127.0.0.1");
Map<String, String> clientCache = new ConcurrentHashMap<>();
StatefulRedisConnection<String, String> myself = redisClient.connect();
CacheFrontend<String, String> frontend =
ClientSideCaching.enable(CacheAccessor.forMap(clientCache),
myself,
TrackingArgs.Builder.enabled().noloop));
String key = "csk";
int count = 0;
while (true) {
System.out.println(frontend.get(key));
TimeUnit.SECONDS.sleep(3);
if (count++ == Integer.MAX_VALUE) {
myself.close();
redisClient.shutdown();
}
}
}
}