LangChain 中的“代理”和“链”的差异究竟是什么?
在链中,一系列操作被硬编码(在代码中)。在代理中,语言模型被用作推理引 擎来确定要采取哪些操作以及按什么顺序执行这些操作。 
Agent 的关键组件
- 代理(Agent):这个类决定下一步执行什么操作。它由一个语言模型和一个提示 (prompt)驱动。提示可能包含代理的性格(也就是给它分配角色,让它以特定方式进行 响应)、任务的背景(用于给它提供更多任务类型的上下文)以及用于激发更好推理能力的 提示策略(例如 ReAct)。LangChain 中包含很多种不同类型的代理。
- 工具(Tools):工具是代理调用的函数。这里有两个重要的考虑因素:一是让代理能访问 到正确的工具,二是以最有帮助的方式描述这些工具。
- 工具包(Toolkits):工具包是一组用于完成特定目标的彼此相关的工具,每个工具包中包 含多个工具。 比如 LangChain 的 Office365 工具包中就包含连接 Outlook、读取邮件列表、发送邮件等一系列工具。
- 代理执行器(AgentExecutor):代理执行器是代理的运行环境,它调用代理并执行代理 选择的操作。执行器也负责处理多种复杂情况,包括处理代理选择了不存在的工具的情况、 处理工具出错的情况、处理代理产生的无法解析成工具调用的输出的情况,以及在代理决策 和工具调用进行观察和日志记录。
深挖 AgentExcutor 的运行机制
llm = OpenAI(temperature=0) # 大语言模型
tools = load_tools(["serpapi", "llm-math"], llm=llm) # 工具-搜索和数学运算
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True) # 代理
agent.run("目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?") # 运行代理
上面的代码很简单,但是我们需要弄清楚2个问题:
- 代理每次给大模型的具体提示是什么样子的?能够让模型给出下一步的行动指南,这个提示
的秘密何在? - 代理执行器是如何按照 ReAct 框架来调用模型,接收模型的输出,并根据这个输出来调用
工具,然后又根据工具的返回结果生成新的提示的。
开始 Debug
在 agent.run 这个语句设置一个断点, 直到我们进入了 agent.py 文件的 AgentExecutor 类的内部方法 _take_next_step。
你可以看到 self.agent.plan 方法被调用,这是计划开始之处 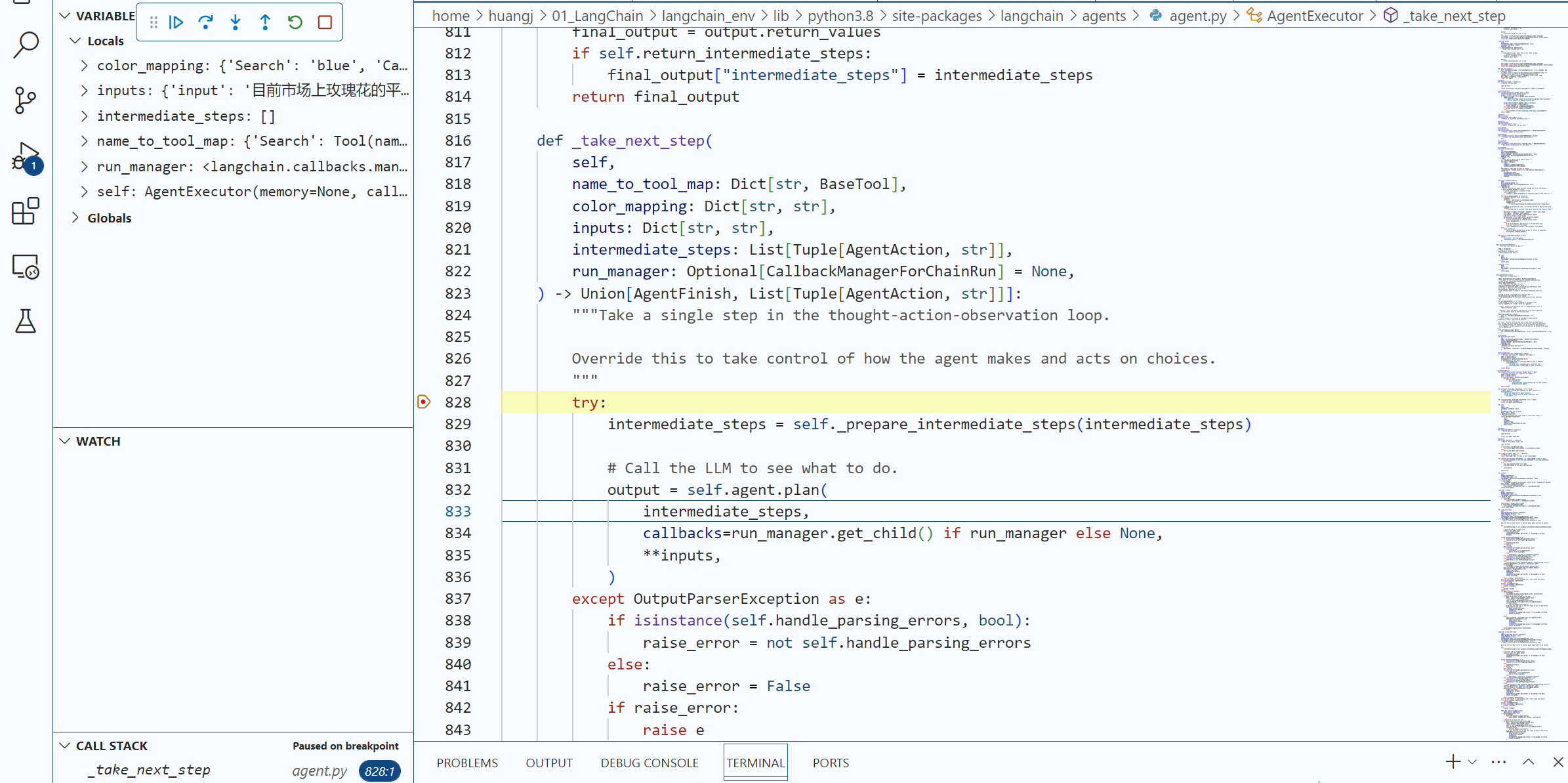
第一轮思考:模型决定搜索
深入 self.agent.plan 方法 ,这个 Plan 的具体细节是由 Agent 类的 Plan 方法来完成的,你可以看到,输入的问题将会被传递给 llm_chain,然后接 收 llm_chain 调用大模型的返回结果 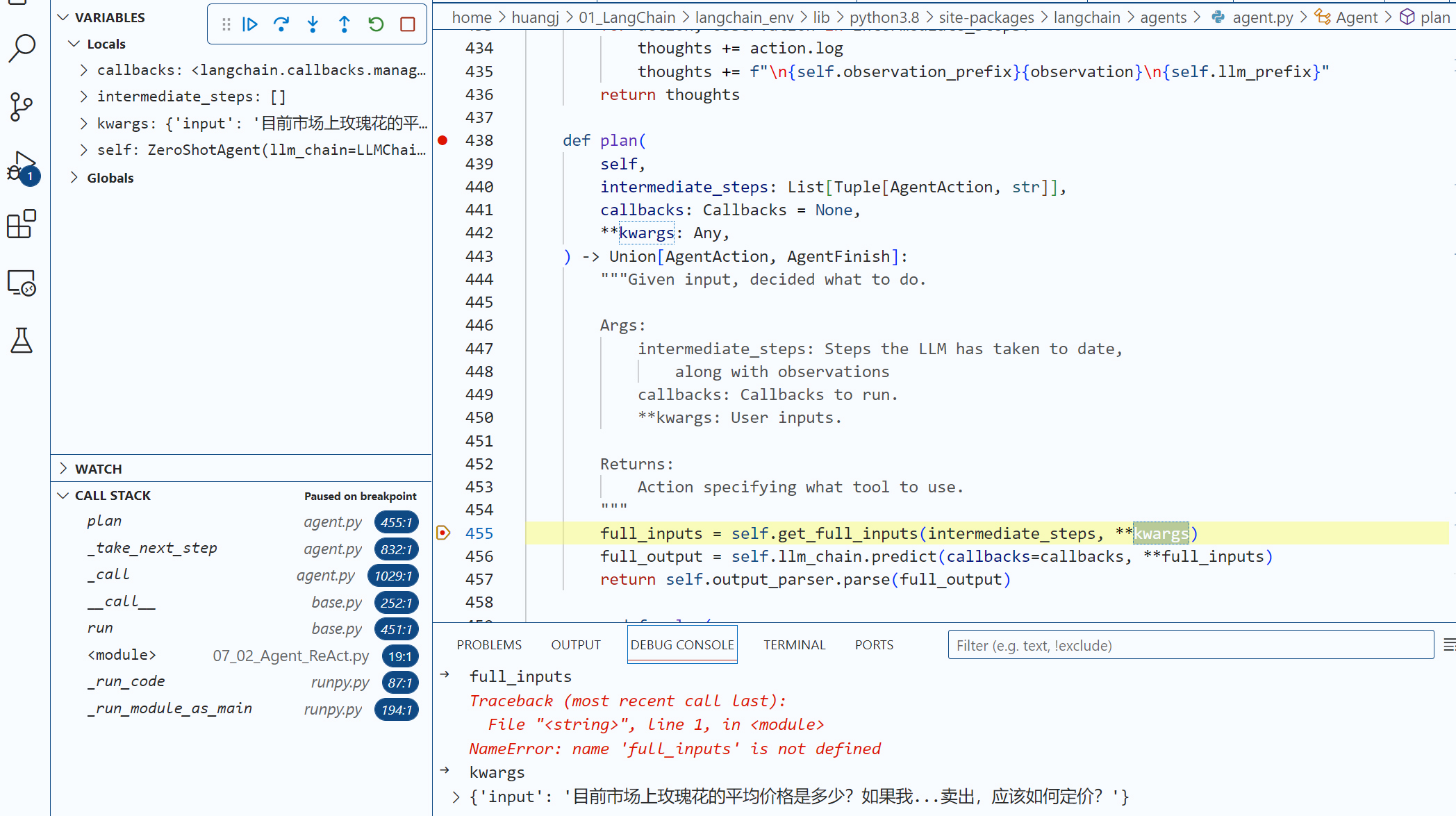
0: StringPromptValue(text='Answer the following questions as best you can. You have access to the following tools:\n\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\nCalculator: Useful for when you need to answer questions about math.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [Search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?\nThought:
我来给你详细拆解一下这个 prompt。注意,下面的解释文字不是原始提示,而是我添加的说明。
0: StringPromptValue(text='Answer the following questions as best you can. You have access to the following tools:\n\n
这句提示是让模型尽量回答问题,并告诉模型拥有哪些工具。
Search: A search engine. Useful for when you need to answer questions about
current events. Input should be a search query.\n
这是向模型介绍第一个工具:搜索。
Calculator: Useful for when you need to answer questions about math.\n\n
这是向模型介绍第二个工具:计算器。
Use the following format:\n\n (指导模型使用下面的格式)
Question: the input question you must answer\n (问题)
Thought: you should always think about what to do\n (思考)
Action: the action to take, should be one of [Search, Calculator]\n (行动)
Action Input: the input to the action\n (行动的输入)
Observation: the result of the action\n… (观察:行动的返回结果)
(this Thought/Action/Action Input/Observation can repeat N times)\n (上面这个过
程可以重复多次)
Thought: I now know the final answer\n (思考:现在我知道最终答案了)
Final Answer: the final answer to the original input question\n\n (最终答案)
上面,就是给模型的思考框架。具体解释可以看一下括号中的文字
Begin!\n\n
开始
Question: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价 15% 卖出,应该
如何定价?\nThought:')
具体的任务
上面我一句句拆解的这个提示词,就是 Agent 之所以能够趋动大模型,进行思考 - 行动 - 观 察行动结果 - 再思考 - 再行动 - 再观察这个循环的核心秘密。有了这样的提示词,模型就会不 停地思考、行动,直到模型判断出问题已经解决,给出最终答案,跳出循环。 

调用大模型之后,模型具体返回了什么结果呢? 
Debug过程中,我们发现调用模型之后的outputs中包含下面的内容。
0: LLMResult(generations=[[Generation(text=' I need to find the current market price of roses and then calculate the new price with a 15% markup.\n
Action: Search\nAction Input: "Average price of roses"', generation_info={'finish_reason': 'stop', 'logprobs': None})]],
llm_output={'token_usage': {'completion_tokens': 36, 'total_tokens': 294, 'prompt_tokens': 258}, 'model_name': 'text-davinci-003'}, run=None)
把上面的内容拆解如下:
'text': ' I need to find the current market price of roses and then calculate the new price with a 15% markup.\n (Text:问题文本)
Action: Search\n (行动:搜索)
Action Input: "Average price of roses"' (行动的输入:搜索玫瑰平均价格)
它自己根据现有知识解决不了,下一步行动是需要选择工具箱中的搜索工具。

第二轮思考:模型决定计算
因为任务尚未完成,第二轮思考开始,程序重新进入了Plan环节。
此时,LangChain的LLM Chain根据目前的input,也就是历史对话记录生成了新的提示信息
0: StringPromptValue(text='Answer the following questions as best you can. You have access to the following tools:\n\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\nCalculator: Useful for when you need to answer questions about math.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [Search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?\nThought: I need to find the current market price of roses and then calculate the new price with a 15% markup.\nAction: Search\nAction Input: "Average price of roses"\nObservation: The average price for a dozen roses in the U.S. is $80.16. The state where a dozen roses cost the most is Hawaii at $108.33. That\'s 35% more expensive than the national average. A dozen roses are most affordable in Pennsylvania, costing $66.15 on average.\nThought:
我们再来拆解一下这个prompt。
0: StringPromptValue(text='Answer the following questions as best you can. You have access to the following tools:\n\n
这句提示是让模型尽量回答问题,并告诉模型拥有哪些工具。
Search: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\n
这是向模型介绍第一个工具:搜索。
Calculator: Useful for when you need to answer questions about math.\n\n
这是向模型介绍第二个工具:计算器。
Use the following format:\n\n (指导模型使用下面的格式)
Question: the input question you must answer\n (问题)
Thought: you should always think about what to do\n (思考)
Action: the action to take, should be one of [Search, Calculator]\n (行动)
Action Input: the input to the action\n (行动的输入)
Observation: the result of the action\n… (观察:行动的返回结果)
(this Thought/Action/Action Input/Observation can repeat N times)\n (上面这个过程可以重复多次)
Thought: I now know the final answer\n (思考:现在我知道最终答案了)
Final Answer: the final answer to the original input question\n\n (最终答案)
上面仍然是一段比较细节的解释说明,看一下括号中的文字。
Begin!\n\n
现在开始!
Question: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?\n
具体问题,也就是具体任务。
这句之前的提示,与我们在第一轮思考时看到的完全相同。
Thought: I need to find the current market price of roses and then calculate the new price with a 15% markup.\n (思考:我需要找到玫瑰花的价格,并加入15%的加价)
Action: Search\nAction (行动:搜索)
Input: “Average price of roses”\n (行动的输入:玫瑰花的平均价格)
Observation: The average price for a dozen roses in the U.S. is $80.16. The state where a dozen roses cost the most is Hawaii at $108.33. That’s 35% more expensive than the national average. A dozen roses are most affordable in Pennsylvania, costing $66.15 on average.\n (观察:这里时搜索工具返回的玫瑰花价格信息)
Thought:’
思考:后面是大模型应该进一步推理的内容。
大模型根据上面这个提示,返回了下面的output信息。

AgentAction(tool='Calculator', tool_input='80.16 * 1.15', log=' I need to calculate the new price with a 15% markup.\nAction: Calculator\nAction Input: 80.16 * 1.15')
这个输出显示,模型告诉自己,“我需要计算新的Price,在搜索结果的基础上加价15%”,并确定Action为计算器,输入计算器工具的指令为80.16*1.15。这是一个非常有逻辑性的思考。
经过解析之后的Thought在命令行中的输出如下:
有了上面的Thought做指引,AgentExecutor调用了第二个工具:LLMMath。现在开始计算。

0: StringPromptValue(text='Translate a math problem into a expression that can be executed using Python’s numexpr library. Use the output of running this code to answer the question.\n\n
指定模型用 Python 的数学库来编程解决数学问题,而不是自己计算。这就规避了大模型数学推理能力弱的局限。
Question: KaTeX parse error: Undefined control sequence: \n at position 30: … math problem.}\̲n̲ ̲(**问题**)<br />t…{single line mathematical expression that solves the problem} n
\n (**问题的数学描述**)<br />...numexpr.evaluate(text)...\n(通过 Python 库运行问题的数学描述)
output\n${Output of running the code}\n```\n (输出的 Python 代码运行结果)
Answer: ${Answer}\n\n(问题的答案)
Begin.\n\n (开始)
从这里开始是两个数学式的解题示例。
Question: What is 37593 * 67?\n
text\n37593 * 67\n
\n…numexpr.evaluate(“37593 * 67”)…\noutput\n2518731\n\n
Answer: 2518731\n\n
Question: 37593^(1/5)\ntext\n37593**(1/5)\n\n…
numexpr.evaluate(“37593**(1/5)”)…\noutput\n8.222831614237718\n\n
Answer: 8.222831614237718\n\n
两个数学式的解题示例结束。
Question: 80.16 * 1.15\n’)
这里是玫瑰花问题的具体描述。
下面,就是模型返回结果。
observation
'Answer: 92.18399999999998'
第三轮思考:模型完成任务
第三轮思考开始。此时,Executor的Plan应该进一步把当前的新结果传递给大模型,不出所料的话,大模型应该有足够的智慧判断出任务此时已经成功地完成了。


0: StringPromptValue(text='Answer the following questions as best you can. You have access to the following tools:\n\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\nCalculator: Useful for when you need to answer questions about math.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [Search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?\nThought: I need to find the current market price of roses and then calculate the new price with a 15% markup.\nAction: Search\nAction Input: "Average price of roses"\nObservation: The average price for a dozen roses in the U.S. is $80.16. The state where a dozen roses cost the most is Hawaii at $108.33. That\'s 35% more expensive than the national average. A dozen roses are most affordable in Pennsylvania, costing $66.15 on average.\nThought: I need to calculate the new price with a 15% markup.\nAction: Calculator\nAction Input: 80.16 * 1.15\nObservation: Answer: 92.18399999999998\nThought:')
拆解
0: StringPromptValue(text='Answer the following questions as best you can. You have access to the following tools:\n\n
这句提示是让模型尽量回答问题,并告诉模型拥有哪些工具。
Search: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\n
这是向模型介绍第一个工具:搜索。
Calculator: Useful for when you need to answer questions about math.\n\n
这是向模型介绍第二个工具:计算器。
Use the following format:\n\n (指导模型使用下面的格式)
Question: the input question you must answer\n (问题)
Thought: you should always think about what to do\n (思考)
Action: the action to take, should be one of [Search, Calculator]\n (行动)
Action Input: the input to the action\n (行动的输入)
Observation: the result of the action\n… (观察:行动的返回结果)
(this Thought/Action/Action Input/Observation can repeat N times)\n (上面这个过程可以重复多次)
Thought: I now know the final answer\n (思考:现在我知道最终答案了)
Final Answer: the final answer to the original input question\n\n (最终答案)
仍然是比较细节的说明,看括号文字。
Begin!\n\n
现在开始!
Question: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?\n
具体问题,也就是具体任务。
Thought: I need to find the current market price of roses and then calculate the new price with a 15% markup.\n (思考:我需要找到玫瑰花的价格,并加入15%的加价)
Action: Search\nAction (行动:搜索)
Input: “Average price of roses”\n (行动的输入:玫瑰花的平均价格)
Observation: The average price for a dozen roses in the U.S. is $80.16. The state where a dozen roses cost the most is Hawaii at $108.33. That’s 35% more expensive than the national average. A dozen roses are most affordable in Pennsylvania, costing $66.15 on average.\n (观察:这里时搜索工具返回的玫瑰花价格信息)
这句之前的提示,与我们在第二轮思考时看到的完全相同。
Thought: I need to calculate the new price with a 15% markup.\n (思考:我需要计算玫瑰花15%的加价)
Action: Calculator\n (行动:计算器工具)
Action Input: 80.16 * 1.15\n (行动输入:一个数学式)
Observation: Answer: 92.18399999999998\n (观察:计算得到的答案)
Thought:’ (思考)
可见,每一轮的提示都跟随着模型的思维链条,逐步递进,逐步完善。环环相扣,最终结果也就呼之欲出了。
继续Debug,发现模型在这一轮思考之后的输出中终于包含了 “I now know the final answer.”,这说明模型意识到任务已经成功地完成了。

总结
这些本质上都是给大模型提供Prompt, Prompt是会越来越多的,可以看看langchain是怎么解决 token上限。 此外,在AgentExecutor中,还构建了自主计划和调用 工具的逻辑。
Profile : 定义了Agent的个性、知识和经验。 提供了“选择操作序列”时推理所需的高层次背景信息。 当Agent处理特定的任务时,它会考虑Profile中的信息来做出与其“个性”和“经验”相一致的决策。
Memory (记忆): 让Agent能够记住之前的交互和决策,帮助其更好地适应和处理后续的任务。 在LLM的编程中,它可以帮助模型跟踪和使用之前的交互来生成更准确的操作序列。
Plan (计划): 是你提到的“定义操作序列”的部分。 在LLM编程范式中,这意味着Agent不是依靠硬编码的规则来执行任务,而是生成、选择和执行计 划,这些计划是基于其当前的Profile和Memory生成的。
Tool (工具): 允许Agent与外部系统和API进行交互,执行具体的任务。 在LLM编程范式中,这意味着模型可以调用外部工具或API来实现某些操作,而不仅仅是生成文本。
当你提到的“反思Reflect”是指模型的自我反思和自我调整能力,这确实是指导LLM生成推理所需的中 观信息。它可以帮助模型更好地适应任务和上下文,生成更准确的操作序列。
基于你的业务需求,使用Agent的四个模块框架是一个很好的思路。在工程化时,你可以考虑如何整 合这四个模块,并结合LLM的编程范式来处理复杂的业务逻辑和交互。
- 请你在 agent.py 文件中找到AgentExecutor类。
- 请你在AgentExecutor类中找到_take_next_step方法,对应本课的内容,分析AgentExecutor类是怎样实现Plan和工具调用的。
- 代码,AgentExecutor类的 实现细节
- 代码,LLMChain类的 实现细节






![若依 ruoyi-cloud [网关异常处理]请求路径:/system/user/getInfo,异常信息:404](https://img-blog.csdnimg.cn/direct/c7f85c51c4604dabafcbf179add1177d.png#pic_center)