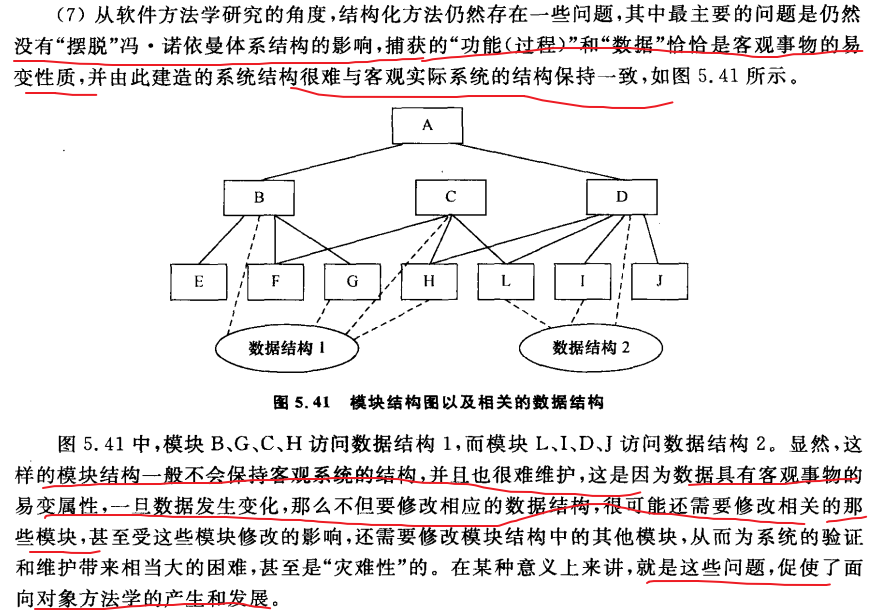
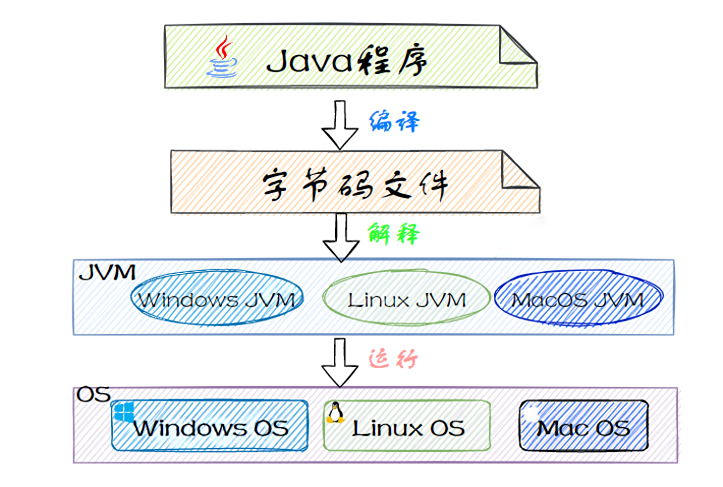
1、什么是 Java?

Java是一种广泛使用的编程语言,由Sun Microsystems(现为Oracle Corporation的一部分)在1995年首次发布。它是一种面向对象的语言,这意味着它支持通过类和对象的概念来构造程序。
Java设计有一个核心理念:“编写一次,到处运行”,这得益于Java虚拟机(JVM)的架构,允许Java程序在任何支持JVM的平台上运行而无需修改。
Java被用于各种计算平台,从嵌入式设备和移动电话到企业服务器和超级计算机。
由于其易用性、跨平台能力、面向对象特性和安全性,Java在企业环境、移动应用开发、网站开发和大数据处理中非常受欢迎。
Java生态系统非常庞大,包括标准版(Java SE)、企业版(Java EE)和微型版(Java ME),以及各种框架、库和工具,使得Java能够适应从小型应用到大型企业级应用的开发需要。
2、Java 语言有哪些特点?
Java语言的主要特点体现在它的设计哲学和功能上,旨在提供一个安全、可移植、高性能和高度对象化的编程环境。下面是Java语言的一些关键特点:

1、简单性: Java设计时去除了C++中的一些难以理解的特性(如指针和多重继承),使其更加简洁易懂。它提供了一个清晰的编程模型和垃圾收集机制,减少了内存泄漏和其他错误的可能性。
2、面向对象: Java是一种纯面向对象的编程语言,几乎所有的代码都是基于类和对象的概念。这促进了代码的模块化和可重用性,使得大型软件开发和维护变得更加容易。
3、平台无关性: Java最著名的特点之一是“编写一次,到处运行”(WORA),这得益于Java虚拟机(JVM)。这意味着Java程序被编译成与平台无关的字节码格式,可以在任何安装了JVM的设备上运行。
4、安全性: Java提供了一个安全的运行环境,通过沙箱机制限制代码的执行,防止恶意代码对主机系统造成损害。Java的安全特性包括类加载器、字节码验证器和安全管理器。
5、健壮性: Java的强类型机制、异常处理和垃圾收集等特性都有助于创建健壮的应用程序。这些特性减少了程序崩溃的可能性和安全风险。
6、多线程: Java内置了强大的多线程功能,允许开发者构建平滑运行的交互式应用程序。Java线程模型简化了并发编程,提高了应用程序的响应性和性能。
7、高性能: 虽然Java的性能历史上被认为不如编译型语言如C或C++,但随着即时编译技术(JIT编译器)的发展,Java的运行速度有了显著提高。
8、编译与解释并存: Java能够适应不断发展的环境。它支持动态链接,即在运行时加载类。这使得Java应用可以保持轻量级,只在需要时才加载必要的资源。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
3、JVM、JDK 和 JRE 有什么区别?
理解Java开发和运行环境时,JVM、JDK和JRE这三个概念至关重要。它们之间的主要区别如下:
1、JVM(Java虚拟机): JVM是Java虚拟机的简称,它是一个抽象的计算机,为Java字节码提供运行环境。JVM是实现平台无关性的关键,因为它允许Java程序在任何操作系统上运行,只要该操作系统上有为该系统设计的JVM。JVM主要负责两大功能:加载代码、验证代码、执行代码和提供运行时环境。
2、JRE(Java运行环境): JRE是Java Runtime Environment的简称,包括Java虚拟机(JVM)、Java平台核心类库和支持Java运行所需的其它组件。如果你仅仅想要运行一个Java程序,那么你只需要安装JRE。
3、JDK(Java开发工具包): JDK是Java Development Kit的简称,它是提供给Java开发者的一个软件开发工具包。JDK包括了JRE,以及编译Java源码的编译器javac、用于文档生成的工具javadoc、调试器等工具。简而言之,JDK提供了开发Java应用所需的一切工具和资源。
简单来说,JDK 包含 JRE,JRE 包含 JVM。

4、说说什么是跨平台性?原理是什么?
跨平台性是指软件应用、程序或操作系统能够在多种硬件架构或操作系统上运行的能力。
这意味着开发者可以编写一次程序,在不同的系统和设备上运行,无需为每个平台重新编写或修改代码。跨平台性极大地提高了软件的可用性和可达性,减少了开发和维护成本。
跨平台性的原理主要依赖于以下几种技术实现:
1、中间件(Middleware): 中间件提供了一个通用的编程抽象层,使得软件可以在这个层上运行,而不是直接在操作系统或硬件上。这样,只要中间件在不同的平台上可用,软件就能够在这些平台上运行。
2、虚拟机技术: 虚拟机(如Java虚拟机JVM)为应用程序提供了一个标准化的执行环境,独立于底层的硬件和操作系统。应用程序首先被编译成一种中间代码(如Java的字节码),然后由虚拟机解释执行或即时编译(JIT)到本地代码。这使得相同的应用程序可以在安装有相应虚拟机的任何平台上运行。
3、跨平台开发框架和工具: 如React Native、Flutter等,它们允许开发者使用统一的编程语言和API编写应用程序,然后编译成可在不同操作系统上运行的本地代码。这些框架和工具隐藏了底层平台的差异,使得开发者可以聚焦于应用逻辑的开发。
4、容器化技术: 如Docker,提供了一种将应用程序及其依赖打包在一个轻量级、可移植的容器中的方法。容器在任何支持容器运行时(如Docker Engine)的平台上以相同的方式运行,实现了应用级别的跨平台。
Java 程序是通过 Java** 虚拟机(JVM)**在系统平台上运行的,只要该系统可以安装相应的 Java 虚拟机,该系统就可以运行 java 程序。
5、什么是字节码?采用字节码的好处是什么?
字节码是一种中间代码形式,通常由编译器从源代码(如Java源代码)编译而来,然后由虚拟机(如Java虚拟机,JVM)执行。
它称为“字节码”是因为它通常是以字节为单位的指令集合,既不是完全的机器代码也不是高级语言代码,而是位于两者之间的中间形态。
Java 程序从源代码到运行主要有三步:
- 编译:将我们的代码(.java)编译成虚拟机可以识别理解的字节码(.class)
- 解释:虚拟机执行 Java 字节码,将字节码翻译成机器能识别的机器码
- 执行:对应的机器执行二进制机器码

采用字节码的好处包括:
1、跨平台性: 最显著的好处是实现了软件的跨平台运行。源代码被编译成字节码后,可以在任何安装有相应虚拟机的平台上运行,而无需针对每个特定的硬件平台重新编译。这正是Java语言“编写一次,到处运行”(WORA)概念的基础。
2、安全性: 字节码在执行前会被虚拟机检查验证,确保没有安全威胁,如非法的内存访问等。这一层次的检查为应用程序的运行提供了一个安全的保障。
3、高效性: 虽然字节码需要通过虚拟机解释执行或即时编译(JIT)转换为机器码,这可能相对直接执行机器码慢一些,但现代虚拟机技术(如JIT编译技术)极大地优化了执行效率,减少了性能差距。
4、动态性: 字节码使得动态加载和执行代码变得可能。虚拟机可以在运行时动态地加载、验证和执行字节码,支持动态语言特性,如反射和动态代理等。
5、优化机会: 在字节码到机器码的转换过程中,虚拟机可以根据目标平台的具体情况进行优化,甚至可以在程序运行时根据行为进行适应性优化,提高程序性能。
6、为什么说 Java 语言“编译与解释并存”?
Java语言被描述为“编译与解释并存”的语言,这是因为它在程序的执行过程中同时采用了编译和解释两种机制。这个过程可以分为两个主要阶段:
1、编译阶段: 在开发环境中,Java源代码(.java文件)首先被Java编译器(javac)编译成字节码(.class文件)。字节码是一种中间代码,它不针对任何特定的处理器架构设计,而是为了在Java虚拟机(JVM)上运行。这个过程是典型的编译过程,将高级语言转换成中间表示的字节码。
2、解释/执行阶段: 当运行Java程序时,Java虚拟机(JVM)负责执行字节码。JVM可以通过两种方式来执行这些字节码:解释执行和即时编译(JIT编译)。在解释执行中,JVM的解释器读取字节码,将每条指令解释为对应平台的机器指令并立即执行。即时编译器(JIT编译器)则是在程序运行时将字节码动态转换(编译)成目标平台的机器代码,以提高程序执行效率。JIT编译器通过编译热点代码(即执行频率高的代码)来减少解释执行的开销,提高程序的运行速度。
Java 语言既具有编译型语言的特征,也具有解释型语言的特征,因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(*.class 文件),这种字节码必须再经过 JVM,解释成操作系统能识别的机器码,在由操作系统执行。因此,我们可以认为 Java 语言编译与解释并存。
7、Java 有哪些数据类型?
Java的数据类型可以分为两大类:基本数据类型和引用数据类型。
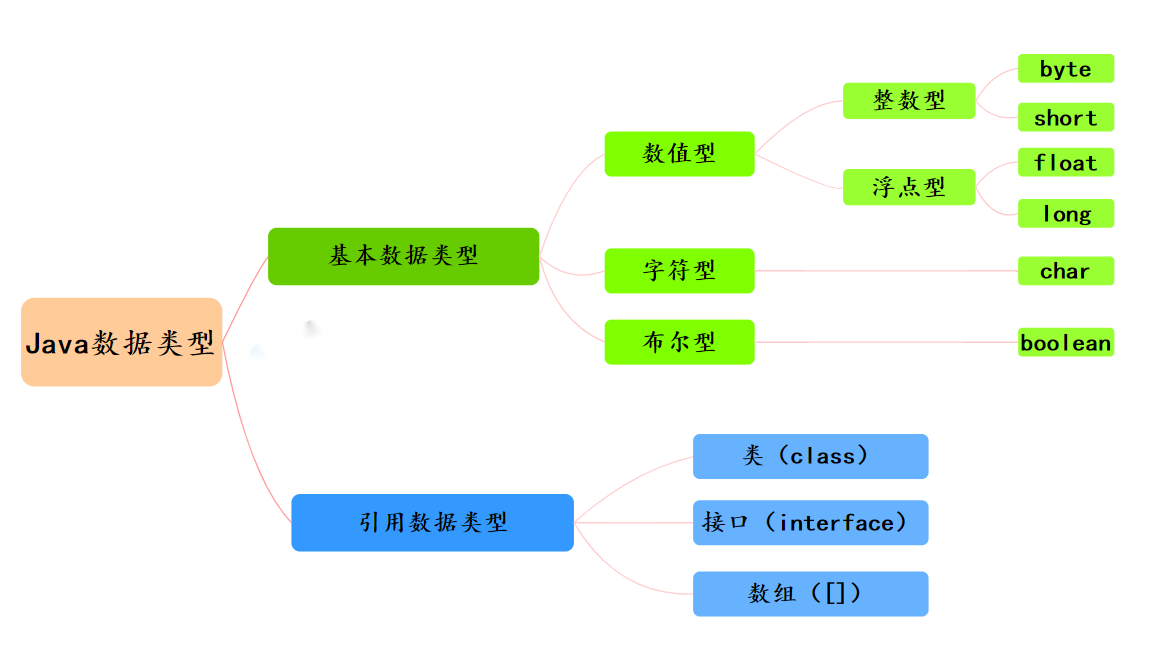
基本数据类型:
Java定义了八种基本数据类型,分别为四种整型、两种浮点型、一种用于表示Unicode编码的字符单元的字符类型和一种用于表示真值的布尔类型。
基本数据类型:
- 数值型
- 整数类型(byte、short、int、long)
- 浮点类型(float、double)
- 字符型(char)
- 布尔型(boolean)
Java 基本数据类型范围和默认值:
| 基本类型 | 位数 | 字节 | 默认值 | 范围 |
|---|---|---|---|---|
| int | 32 | 4 | 0 | -2^31 到 2^31-1 |
| short | 16 | 2 | 0 | -32,768到32,767 |
| long | 64 | 8 | 0L | -2^63 到 2^63-1 |
| byte | 8 | 1 | 0 | -128到127 |
| char | 16 | 2 | ‘u0000’ | |
| float | 32 | 4 | 0f | -2^31 到 2^31-1 |
| double | 64 | 8 | 0d | -2^63 到 2^63-1 |
| boolean | 1 | false |
引用数据类型:
引用数据类型包括类、接口、数组。它们指向一个对象的引用(内存地址),而不是对象本身的值。引用数据类型的默认值是null。
- 类(Class): 如String、Integer等Java标准库中的类,以及用户自定义的类。
- 接口(Interface): 一种特殊的抽象类型,是方法声明的集合。
- 数组(Array): 存储固定大小的同类型元素序列。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
8、什么是Java自动类型转换、强制类型转换?
在Java中,类型转换分为**自动类型转换(隐式类型转换)和强制类型转换(显式类型转换)**两种。
自动类型转换(隐式类型转换):
当将一个类型的数据赋值给另一个类型时,如果满足从小到大的转换规则,Java会自动完成类型转换。
这种转换是安全的,因为它不会导致数据丢失。常见的自动类型转换规则为:
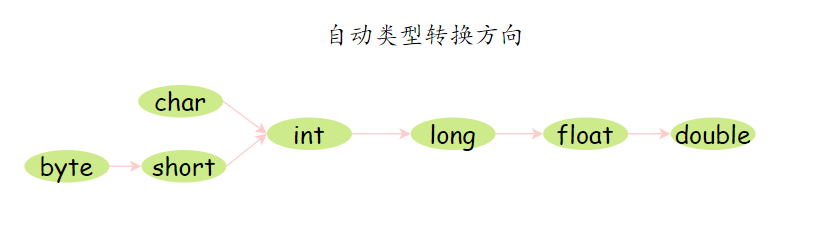
自动类型转换示例:
int i = 100;
long l = i; // 从 int 自动转换为 long
float f = l; // 从 long 自动转换为 float
System.out.println("Int value: " + i);
System.out.println("Long value: " + l);
System.out.println("Float value: " + f);
这就好像,小杯里的水倒进大杯没问题,但大杯的水倒进小杯就不行了,可能会溢出。
强制类型转换(显式类型转换):
当需要将一个数据类型强制转换为另一个类型时,可以使用强制类型转换。
这通常是从大到小的转换,可能会导致精度丢失或溢出。
进行强制类型转换时,需要在要转换的值前加上括号和目标类型。
强制类型转换示例:
double d = 100.04;
long l = (long)d; // 强制将 double 类型转换为 long 类型
int i = (int)l; // 强制将 long 类型转换为 int 类型
System.out.println("Double value: " + d);
System.out.println("Long value: " + l);
System.out.println("Int value: " + i);
在使用强制类型转换时,必须注意转换可能导致的数据丢失或精度降低。自动类型转换则不需要程序员显式进行操作,Java编译器会自动处理。
8、什么是自动装箱/拆箱?
自动拆箱和封箱是Java 5引入的特性,旨在自动处理基本类型和它们对应的包装类之间的转换,简化了基本类型与对象之间的转换过程。
**装箱(Autoboxing):**将基本类型用它们对应的引用类型包装起来。
Java 可以自动对基本数据类型和它们的包装类进行装箱和拆箱。
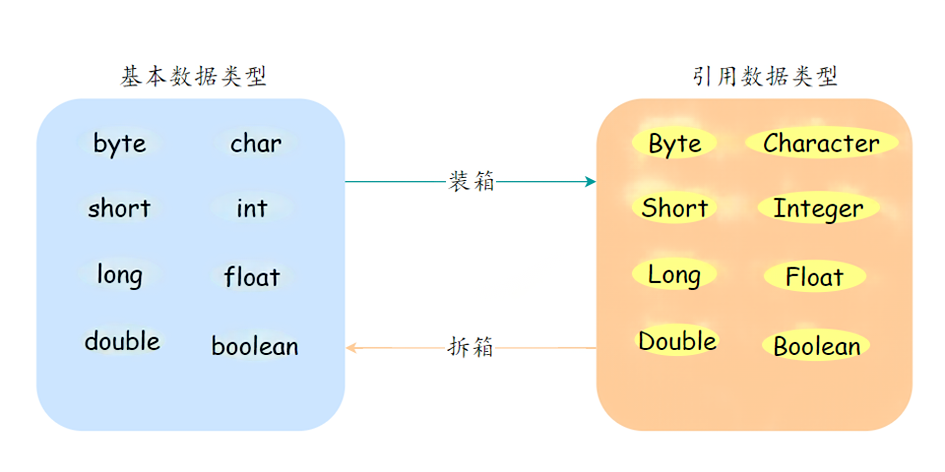
例如:
Integer i = 5; // 自动封箱,编译器将基本类型5转换为Integer对象
**拆箱(Unboxing):**将包装类型转换为基本数据类型;
例如:
int a = i; // 自动拆箱,编译器将Integer对象转换为基本类型int
在下面更复杂的示例中,**list.add(j);发生了自动封箱操作,而sum += k;**则发生了自动拆箱操作。
自动拆箱和封箱大大简化了集合与基本类型之间的操作,使得代码更加简洁易读。然而,它们也可能引起性能问题,尤其是在大量操作中,因此使用时需要谨慎。
List<Integer> list = new ArrayList<Integer>();
for (int j = 0; j < 10; j++) {
list.add(j); // 自动封箱,将int类型的j转换为Integer对象后添加到列表中
}
int sum = 0;
for (Integer k : list) {
sum += k; // 自动拆箱,将列表中的Integer对象转换为int类型后进行求和
}
System.out.println("Sum: " + sum);
9、java的&和&&有什么区别?
在Java中,**&和&&**都可以用作逻辑运算符,但它们之间有重要的区别:
1、&(逻辑与/位运算符):
- 作为逻辑运算符时,**&**对两边的布尔表达式进行逻辑与操作。不论左侧表达式的结果如何,都会执行右侧的表达式。
- 作为位运算符时,**&**对两边的整数进行按位与操作。
boolean a = true;
boolean b = false;
boolean result1 = a & b; // false,两侧表达式都会被执行
boolean result2 = a && b; // false,由于a为true,会继续判断b的值
2、&&(短路逻辑与):
- &&也是进行逻辑与操作,但它支持短路行为。即如果左侧的表达式结果为false,则不再执行右侧的表达式,因为无论右侧表达式结果如何,整个表达式的结果已经确定为false。
int x = 0;
boolean result3 = (x != 0) & (10 / x > 1); // 抛出除以零的ArithmeticException异常
boolean result4 = (x != 0) && (10 / x > 1); // 不会执行(10 / x > 1),因此不会抛出异常
在这个短路行为的示例中,使用**&&时,由于(x != 0)的结果为false**,所以后面的**(10 / x > 1)不会被执行,从而避免了可能的ArithmeticException异常。
总结来说,&可以作为逻辑与和位运算符使用,无短路行为;&&**是逻辑与操作符,具有短路特性,可以提高程序的效率并避免某些情况下的错误。
9、switch 是否能作用在 byte/long/String 上?
在Java中,switch语句的兼容性取决于Java的版本:
- byte:switch语句可以作用于byte类型。byte是Java的基本数据类型之一,switch对其提供原生支持。
byte b = 10;
switch(b) {
case 10:
System.out.println("Ten");
break;
default:
System.out.println("Not ten");
}
- long:switch语句不能作用于long类型。由于long类型的范围远大于int,为了保证效率和实现的简单性,Java的设计者没有让switch直接支持long。
// 此代码是错误的,只是为了说明`switch`不能用于`long`
long l = 10L;
switch(l) {
case 10L:
// 编译错误
break;
default:
// 编译错误
}
- String: 从Java SE 7开始,switch语句可以作用于String类型。这是一个比较晚近的改进,旨在提高Java在处理文本数据时的表达能力和方便性。
String str = "Hello";
switch(str) {
case "Hello":
System.out.println("Hello");
break;
case "World":
System.out.println("World");
break;
default:
System.out.println("Default case");
}
10、break ,continue ,return 的区别及作用?
break、continue和return都是Java中控制流程的关键字,它们在循环或者方法中起着不同的作用:
break:
- 在循环中使用时,break会中断循环,不论循环条件是否满足,都不再继续执行循环体中剩余的语句。
- 在switch语句中使用break可以避免执行下一个case。
//循环示例
for(int i = 0; i < 10; i++) {
if(i == 5) {
break; // 当i等于5时,退出循环
}
System.out.println(i);
}
//switch示例
int res=0;
switch (chineseNumber.length()){
case 1:
res=1;
break;
case 2:
res=2;
break;
default:
res=3;
}
continue:
- continue关键字用于跳过当前循环体的剩余部分,并开始下一次循环的迭代。与break不同,continue仅仅跳过循环体中剩余的语句,然后根据循环条件判断是否继续执行循环。
for(int i = 0; i < 10; i++) {
if(i % 2 == 0) {
continue; // 跳过偶数的打印
}
System.out.println(i);
}
return:
- return关键字用于从当前方法中退出,并返回值(如果方法声明返回类型不是void)。
public int testReturn(int value) {
if(value == 5) {
return 5; // 当value等于5时,方法返回5
}
return 0; // 其他情况返回0
}
总结来说,break用于完全结束循环,continue用于跳过当前循环中的剩余语句并继续下一次迭代,而return则用于从方法中退出并可选地返回一个值。
11、java如何用最有效率的方法计算 2 乘以 8?
在Java中,计算2乘以8最有效率的方法是使用位移操作。位移操作比乘法操作要快,因为它仅仅涉及到二进制位的移动。将一个数左移n位,就相当于将这个数乘以2的三次方。因此,可以通过将2左移3位来得到2乘以8的结果。
public class MultiplyByEight {
public static void main(String[] args) {
int result = 2 << 3; // 将2左移3位
System.out.println("2 乘以 8 等于: " + result);
}
}
12、说说Java中的自增自减运算?
Java中的自增(++)和自减(–)运算符用于对变量进行加一或减一的操作。这两个运算符都可以作为前缀使用(即在变量之前,如**++var或–var**),也可以作为后缀使用(即在变量之后,如var++或var–)。它们之间的区别主要体现在表达式求值时的行为上。
自增运算符(++):
- 前缀自增(++var): 首先将变量的值加1,然后返回变量加1后的值。
- 后缀自增(var++): 首先返回变量当前的值,然后将变量的值加1。
自减运算符(–):
- 前缀自减(–var): 首先将变量的值减1,然后返回变量减1后的值。
- 后缀自减(var–): 首先返回变量当前的值,然后将变量的值减1。
int a = 5;
int b = ++a; // 前缀自增:a现在是6,b也是6。
int c = 5;
int d = c++; // 后缀自增:c最终是6,但d是5,因为d赋值时c还没增加。
int e = 5;
int f = --e; // 前缀自减:e现在是4,f也是4。
int g = 5;
int h = g--; // 后缀自减:g最终是4,但h是5,因为h赋值时g还没减少。
13、Java面向对象和面向过程的区别?
Java是一种面向对象编程(OOP)语言,它与传统的面向过程编程(POP)有显著的不同。
面向对象编程和面向过程编程主要在程序的设计和组织方式上有区别:
面向过程编程(POP):
- 关注的是过程与步骤。程序被视为一系列函数的集合,数据被视为这些函数操作的对象。
- 主要通过编写函数或者过程来表示完成任务的具体步骤。
- 强调的是算法和数据的分离,算法被看作是首要的,而数据则是次要的。
- 适合于简单的、任务驱动型的问题,但在处理复杂的系统时,其代码可重用性和可维护性较差。
面向对象编程(OOP):
- 关注的是对象和类。程序被视为一系列相互作用的对象集合,每个对象都是类的实例,类定义了对象的属性和可以对这些属性进行操作的方法。
- 主要通过创建对象以及对象之间的交互来实现特定的功能。
- 强调数据和操作数据的算法(即方法)的统一,将数据封装于对象中,并通过对象的方法来操作数据,提高了数据的安全性。
- 适合于复杂的、多变的应用程序,因为它提高了代码的重用性、扩展性和维护性。
例如处理汽车加速。
面向过程处理汽车加速
void accelerateCar(int speed, int increment) {
speed += increment;
}
面向对象处理汽车加速
class Car {
private int speed;
public void accelerate(int increment) {
this.speed += increment;
}
}
在面向对象的示例中,Car是一个类,拥有属性speed和方法accelerate,不仅体现了数据(即属性)和方法的封装,还便于扩展(如通过继承创建特定类型的汽车)和维护。
大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
14、面向对象有哪些特性
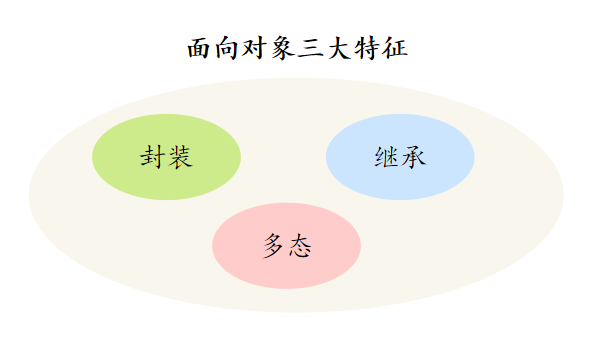
面向对象编程的核心特征包括:
- 封装:隐藏对象的属性和实现细节,仅对外提供公共访问方式。
- 继承:允许新创建的类继承现有类的属性和方法。
继承是使⽤已存在的类的定义作为基础创建新的类,新类的定义可以增加新的属性或新的方法,也可以继承父类的属性和方法。通过继承可以很方便地进行代码复用。
关于继承有以下三个要点:
- ⼦类拥有⽗类对象所有的属性和⽅法(包括私有属性和私有⽅法),但是⽗类中的私有属性和⽅法⼦类是⽆法访问,只是拥有。
- ⼦类可以拥有⾃⼰属性和⽅法,即⼦类可以对⽗类进⾏扩展。
- ⼦类可以⽤⾃⼰的⽅式实现⽗类的⽅法。
- 多态:允许不同类的对象对同一消息做出响应,实现方法的多样性。
在 Java 中有两种形式可以实现多态:继承(多个⼦类对同⼀⽅法的重写)和接⼝(实现接⼝并覆盖接⼝中同⼀⽅法)。
15、重载(overload)和重写(override)的区别?
在Java中,重载(Overloading)和重写(Overriding)是两种用来增强类的功能的机制,但它们在概念上和应用上有显著的区别:
重载(Overloading):
- 定义: 在同一个类中,允许存在一个以上的同名方法,只要它们的参数列表不同即可,这称为方法的重载。
- 目的: 重载使得一个类可以根据不同的参数列表执行不同的任务。
- 参数: 方法重载是通过改变参数的数量或类型来实现的。
- 返回类型: 可以不同或相同,但仅返回类型之间的差异不足以声明重载方法。
- 访问修饰符: 可以不同。
- 抛出的异常: 可以不同。
- 应用范围: 发生在同一个类中或者在一个类的子类和父类中。
class Demo {
public void display(String c) {
System.out.println(c);
}
public void display(String c, int num) {
System.out.println(c + " " + num);
}
}
重写(Overriding):
- 定义: 子类可以根据需要,对从父类继承来的方法进行重新编写。这称为方法的重写。
- 目的: 重写使得子类可以提供特定的实现细节,或者修改继承方法的行为。
- 参数: 必须和父类被重写的方法完全相同。
- 返回类型: 必须和父类被重写的方法的返回类型相同或是其子类型(协变返回类型)。
- 访问修饰符: 访问权限可以扩大,不能缩小。
- 抛出的异常: 可以减少或不抛出异常,但不能抛出新的或更广的检查异常。
- 应用范围: 仅发生在子类与父类之间。
class Animal {
public void move() {
System.out.println("Animals can move");
}
}
class Dog extends Animal {
@Override
public void move() {
System.out.println("Dogs can walk and run");
}
}
总结来说,重载是增加方法的新版本,而重写是替换从父类继承来的方法。
重载发生在同一类中或继承关系的类中,主要关注参数列表;
重写则发生在继承关系的类之间,关注方法的具体实现。
16、访问修饰符 public、private、protected、以及不写(默认)时的区别?
在Java中,访问修饰符用于定义Java类、变量、方法和构造器的访问范围。
Java提供了四种访问级别:public、protected、private以及默认(不写)。
下面是每种访问修饰符的访问权限和特点:
1、public:
- 访问权限: 类、接口、变量、方法可以被任何其他类访问。
- 使用范围: 从任何其他类、包、项目。
2、protected:
- 访问权限: 类、变量、方法可以被同一个包内的其他类以及其他包中的子类访问。
- 使用范围: 相同包内的类和任何子类。
3、默认(不指定,也称为包私有):
- 访问权限: 类、接口、变量、方法可以被同一个包内的其他类访问,但对于其他包中的类则是不可见的。
- 使用范围: 同一包内的其他类。
4、private:
- 访问权限: 类、变量、方法只能被定义它们的类访问。
- 使用范围: 同一类内部。

public class AccessExample {
public int publicVar = 1; // 公开访问
protected int protectedVar = 2; // 受保护访问
int defaultVar = 3; // 默认访问(包私有)
private int privateVar = 4; // 私有访问
}
- publicVar可以在任何地方被访问。
- protectedVar可以被相同包内的类或其他包中的子类访问。
- defaultVar只能在同一个包内的类中被访问。
- privateVar只能在AccessExample类内部被访问。
正确使用访问修饰符可以提高代码的封装性和安全性,避免了外部不必要的访问和修改,是面向对象设计的重要方面。
17、.this 关键字有什么作用?
在Java中,this关键字有多种用途,主要用于引用当前对象。
它可以在实例方法或构造器中使用,主要用于以下几个方面:
1、区分实例变量和局部变量:
当实例变量和局部变量(比如方法的参数)名称相同时,this可用于区分实例变量和局部变量。
public class Person {
private String name;
public void setName(String name) {
this.name = name; // 使用this来指明name是实例变量而非参数
}
}
2、在一个构造器中调用另一个构造器: 使用**this()**可以在一个构造器中调用类的另一个构造器,通常用于构造器重载。
public class Rectangle {
private int x, y;
private int width, height;
public Rectangle() {
this(0, 0, 1, 1); // 使用this调用另一个构造器
}
public Rectangle(int width, int height) {
this(0, 0, width, height); // 使用this调用另一个构造器
}
public Rectangle(int x, int y, int width, int height) {
this.x = x;
this.y = y;
this.width = width;
this.height = height;
}
}
3、返回当前对象:this可以用于返回当前类的实例。
public class ReturnCurrentClassInstance {
public ReturnCurrentClassInstance get() {
return this; // 返回当前类的实例
}
}
4、传递当前对象作为参数: 在方法中,this可以用来将当前对象传递给另一个方法。
public class PassThisAsArgument {
public void print(PassThisAsArgument obj) {
System.out.println("Printing...");
}
public void send() {
print(this); // 将当前对象作为参数传递
}
}
总结来说,this关键字在Java编程中是非常有用的,它可以提高代码的可读性和避免名称上的混淆,同时也支持在不同构造器间进行调用,实现代码的复用。
18、抽象类(abstract class)和接口(interface)有什么区别?
抽象类(Abstract Class)和接口(Interface)都是Java中实现抽象化的机制,但它们在设计和使用上有一些关键的区别:
抽象类(Abstract Class):
- 目的: 为其他类提供一个共有的类型,封装了一些抽象方法和具体方法(含实现),这些类继承了抽象类必须实现其中的抽象方法。
- 使用方式: 通过extends关键字被继承。
- 成员: 可以包含抽象方法(没有方法体的方法)和具体方法(有方法体的方法),还可以包含成员变量。
- 构造器: 可以有构造器。
- 继承: 一个类只能继承一个抽象类,支持单继承。
- 访问修饰符: 抽象方法可以有任何访问修饰符(public, protected, private)。
abstract class Animal {
public abstract void eat(); // 抽象方法
public void sleep() { // 具体方法
System.out.println("Sleep");
}
}
接口(Interface):
- 目的: 定义了一组方法规范,是一种契约,实现接口的类必须实现这些方法。
- 使用方式: 通过implements关键字被实现。
- 成员: Java 8之前,接口只能包含抽象方法(所有方法默认为public abstract),不能包含实现(具体方法)。Java 8引入了默认方法和静态方法,Java 9加入了私有方法。接口不能包含成员变量,但可以包含常量(public static final)。
- 构造器: 不能有构造器。
- 继承: 一个类可以实现多个接口,支持多重继承的特性。
- 访问修饰符: 接口中的方法默认是public的。
interface Animal {
void eat(); // 在Java 8之前,接口中的方法默认是抽象的
default void sleep() { // Java 8中引入的默认方法
System.out.println("Sleep");
}
}
抽象类适用于一些具有共同特征的类的情况,而接口更适用于为不同类提供公共功能的情况。
选择使用抽象类还是接口,取决于你要解决的问题以及软件设计的需求。
19、成员变量与局部变量的区别有哪些?
成员变量和局部变量在Java中扮演着不同的角色,它们之间的主要区别可以从以下几个方面来描述:
1、声明位置:
- 成员变量:声明在类中方法外,它们属于对象的一部分,也被称为实例变量。如果成员变量被static修饰,则被称为类变量或静态变量,它们属于类的一部分。
- 局部变量:声明在方法内、方法参数或者代码块中,其作用范围限定在声明它的块中。
2、生命周期:
- 成员变量:随对象的创建而初始化,随对象的消失而消失。对于静态变量,则是随类的加载而存在,随类的消失而消失。
- 局部变量:当进入方法或代码块时创建,退出这些区域时销毁。
3、初始化:
- 成员变量:如果不手动初始化,Java会为它们提供默认值(例如,数值型变量的默认值是0或0.0,布尔型变量的默认值是false,对象引用的默认值是null)。
- 局部变量:没有默认值,必须在使用前显式初始化,否则编译器会报错。
4、内存位置:
- 成员变量:存储在堆内存中,因为它们随对象一起存在。
- 局部变量:存储在栈内存中,因为它们的生命周期比较短。
5、访问修饰符:
- 成员变量:可以使用访问修饰符(如public, protected, private)来指定访问级别。
- 局部变量:不能使用访问修饰符,它们的访问范围仅限于声明它们的块内。
public class VariableDifference {
int memberVariable; // 成员变量
public void method() {
int localVariable = 0; // 局部变量,必须初始化
System.out.println(localVariable);
}
}
在这个示例中
memberVariable是一个成员变量,它在类中定义,并拥有默认值;
localVariable是一个局部变量,它在方法中定义,必须在使用前初始化。
20、final 关键字有什么作用?
在Java中,final关键字用于表示某些事物是不可改变的。
它可以用于修饰类、方法和变量,具有以下几种用途:
1、修饰变量:
- 当final修饰一个变量时,这个变量就成为了常量,意味着一旦给它赋了初值之后就不能再修改它的值了。final变量可以是成员变量、局部变量或者是参数变量。
- final成员变量必须在声明时或在构造器中初始化。
- final局部变量和参数变量必须在声明时或在使用之前初始化。
final int MAX_VALUE = 10;
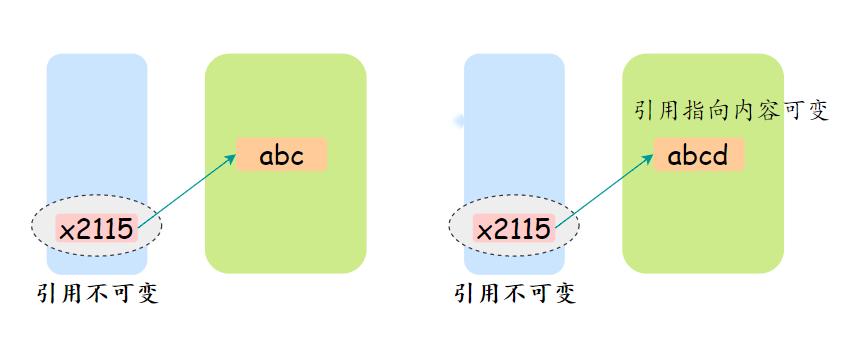
**值得注意的是:**这里的不可变指的是变量的引用不可变,不是引用指向的内容的不可变。
例如:
final StringBuilder sb = new StringBuilder("abc");
sb.append("d");
System.out.println(sb); //abcd
2、修饰方法:
- 当final修饰一个方法时,这个方法不能被子类覆盖(重写)。
- final方法可以加快方法调用,因为编译器在编译时可以将final方法转换为内联调用。
public final void display() {
System.out.println("This is a final method.");
}
3、修饰类:
- 当final修饰一个类时,这个类不能被继承。
- final类中的所有成员方法都会被隐式地指定为final方法,但是字段不受影响。
public final class MyFinalClass {
// 类的实现
}
使用final关键字的好处包括:
- 增强程序的安全性,防止不希望改变的代码被修改。
- 提高性能。对于final变量,编译器在编译期间可以将它们视为常量来处理,可能会做一些优化处理。
- 明确表达设计意图,使代码更易于理解。例如,final类明确表示它不打算被扩展。
21、final、finally、finalize 的区别?
在Java中,final、finally和finalize虽然听起来很相似,但它们的用途和作用完全不同。
final 关键字:
- final是一个访问修饰符,可以用来修饰类、方法和变量。
- 修饰类时,表明该类不能被继承。
- 修饰方法时,表示该方法不能被子类重写。
- 修饰变量时,表示该变量一旦初始化后其值就不能被改变(变成常量)。
final class MyClass {} // 不能被继承的类
public final void show() {} // 不能被重写的方法
final int LIMIT = 10; // 值不能改变的变量
finally 块:
- finally是与try语句一起使用的,无论是否捕获到异常,finally块中的代码都会被执行。
- 常用于关闭或释放资源,如输入/输出流、数据库连接等。
try {
// 可能产生异常的代码
} catch (Exception e) {
// 处理异常
} finally {
// 清理代码,总会执行
}
finalize() 方法:
- **finalize()**是Object类的一个方法,Java虚拟机(JVM)在垃圾回收对象之前调用该方法,给一个对象清理资源的机会。
- 它主要用于回收资源,但是由于其不确定性和效率低下,一般建议避免使用。Java 9开始已经被标记为不推荐使用(deprecated)。
protected void finalize() throws Throwable {
// 在对象被垃圾回收器回收之前执行清理操作
}
总结来说,final用于声明不可变的实体,finally用于处理异常后的清理工作,而**finalize()**用于对象被垃圾回收前的资源释放。这三者在Java编程中是3个完全不相干的三个关键字。
22、==和 equals 的区别?
在Java中,运算符和equals()**方法用于比较两个对象,但它们在比较方式和使用场景上存在显著的区别:
** 运算符:
- **==**用于基本数据类型变量时,比较的是它们的值是否相等。
- 当**==**用于对象时,比较的是两个对象的引用地址是否相同,即判断它们是否指向堆内存中的同一个对象实例。
- 因此,对于引用类型,**==**判断的是两个引用是否指向内存中的同一位置。
String str1 = new String("hello");
String str2 = new String("hello");
System.out.println(str1 == str2); // 输出 false,因为str1和str2引用不同的对象实例
int num1 = 5;
int num2 = 5;
System.out.println(num1 == num2); // 输出 true,因为num1和num2的值相等
equals() 方法:
- equals()方法用于比较两个对象的内容是否相等,它在Object类中被定义。默认情况下,Object类的**equals()方法和==**运算符的作用相同,比较对象的引用地址。
- 但是,许多类(如String、Integer等所有包装类)都重写了**equals()**方法,使其比较的是对象的内容而不是引用地址。
- 因此,如果你需要判断两个对象的内容是否相同,应该使用**equals()**方法。
String str1 = new String("hello");
String str2 = new String("hello");
System.out.println(str1.equals(str2)); // 输出 true,因为str1和str2的内容相同
总结来说,**用于基本类型数据的值比较或判断两个对象的引用是否相同,而equals()方法用于比较两个对象的内容是否相等。在使用时需要根据具体需求选择使用还是equals()**方法。
23、你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode 方法?
在Java中,确实有过重写hashCode()和equals()方法的经验。这两个方法在Object类中定义,大多数Java集合类(如HashSet、HashMap、Hashtable等)依赖这两个方法来判断对象的相等性以及确定对象的存储位置。
为什么需要重写equals()方法?
- 默认情况下,Object类的equals()方法是比较对象的引用地址,但在实际应用中,我们通常需要比较对象的内容是否相等。例如,两个Person对象,如果它们的name和age属性值相同,我们就认为这两个Person对象是相等的。
为什么重写equals()时必须重写hashCode()方法?
- 因为按照Java规范,如果两个对象通过equals()方法比较相等,则这两个对象的hashCode()方法必须返回相同的整数结果。这一规则确保了对象能够在使用基于哈希的集合(如HashSet、HashMap)时,正确地存储和检索。
- 如果你重写了equals()方法而没有重写hashCode()方法,会导致违反上述规约,进而可能导致基于哈希的集合行为不正确。例如,在HashMap中,如果两个键对象是“相等的”,但它们的哈希码不同,可能会导致无法正确地检索值对象。
public class Person {
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
if (age != person.age) return false;
return name != null ? name.equals(person.name) : person.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
在这个Person类的例子中,equals()方法被重写以比较对象的name和age属性,而hashCode()也被相应地重写以确保当两个Person对象通过**equals()**方法比较为相等时,它们的哈希码也相等。这种做法满足了使用基于哈希的集合时的正确性要求。
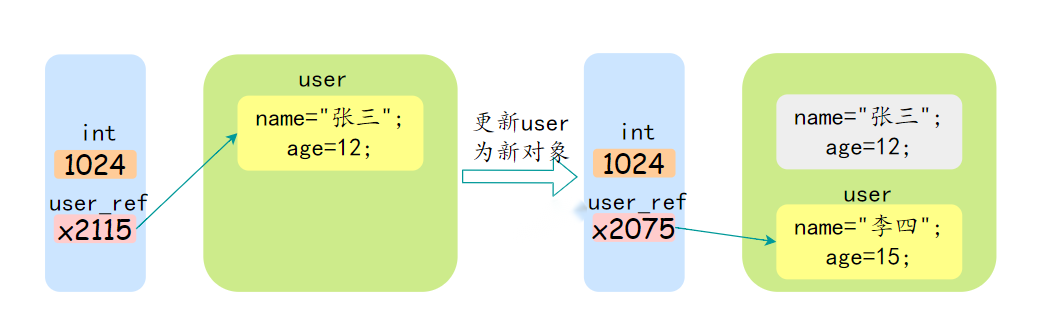
24、Java 是值传递,还是引用传递?
Java中的参数传递是值传递。
无论是基本数据类型还是对象,传递给方法的都是变量的副本,而不是变量本身。
这个概念对于理解Java中方法参数的行为至关重要。
- 对于基本类型:传递的是基本类型的值的副本。在方法内对这些副本的任何操作都不会影响原始值。
- 对于对象引用:传递的是对象引用的值的副本,而不是对象本身。这意味着你可以通过这个副本引用来访问和修改对象的属性。但是,如果你尝试在方法内部将这个副本引用指向另一个对象,原始引用不会改变,因为传递的只是引用的值的副本。
这里的关键是理解“对象引用的值的副本”这个概念。
这个副本指向同一个对象,所以可以改变对象的状态,但不能改变引用本身的指向。
JVM 的内存分为堆和栈,其中栈中存储了基本数据类型和引用数据类型实例的地址,也就是对象地址。
而对象所占的空间是在堆中开辟的,所以传递的时候可以理解为把变量存储的对象地址给传递过去,因此引用类型也是值传递。
public class Test {
public static void main(String[] args) {
Test test = new Test();
// 基本类型测试
int x = 1;
test.modify(x);
System.out.println(x); // 输出 1,x 的值不变
// 对象引用测试
MyObject myObject = new MyObject();
test.changeReference(myObject);
System.out.println(myObject.value); // 输出 "Modified",对象的状态被改变了
test.tryToChangeReference(myObject);
System.out.println(myObject.value); // 依然输出 "Modified",引用本身的指向没有改变
}
public void modify(int number) {
number = number + 1;
}
public void changeReference(MyObject obj) {
obj.value = "Modified";
}
public void tryToChangeReference(MyObject obj) {
obj = new MyObject();
obj.value = "Changed";
}
static class MyObject {
String value = "Original";
}
}
这个例子说明了Java的参数传递机制:
modify方法试图改变基本类型参数的值,但这个改变不会影响原始变量;
changeReference方法改变了对象引用参数指向对象的状态,这个改变反映到了方法外部;
而tryToChangeReference方法尝试改变引用参数本身的指向,但这个改变不会反映到方法外部。
25、深拷贝和浅拷贝?
在Java中,对象的拷贝可以分为深拷贝(Deep Copy)和浅拷贝(Shallow Copy)两种.
它们在拷贝对象时的行为上有本质的区别:
浅拷贝(Shallow Copy):
- 浅拷贝仅复制对象的引用,而不复制引用指向的对象本身。
- 在浅拷贝后,原始对象和拷贝对象会指向同一个实例,因此对一个对象的修改会影响到另一个。
- 在Java中,浅拷贝可以通过赋值操作或者使用Object类的**clone()方法实现(如果没有重写clone()**方法实现深拷贝)。
深拷贝(Deep Copy):
- 深拷贝不仅复制对象的引用,还复制引用指向的对象本身以及该对象内部所有引用的对象,形成完整的对象图拷贝。
- 在深拷贝后,原始对象和拷贝对象是完全独立的,对一个对象的修改不会影响到另一个。
- 实现深拷贝通常需要重写**clone()**方法,并手动复制对象及其内部所有引用的对象,或者通过序列化(Serializable)和反序列化实现。
例如现在有一个 order 对象,里面有一个 products 列表,它的浅拷贝和深拷贝的示意图:
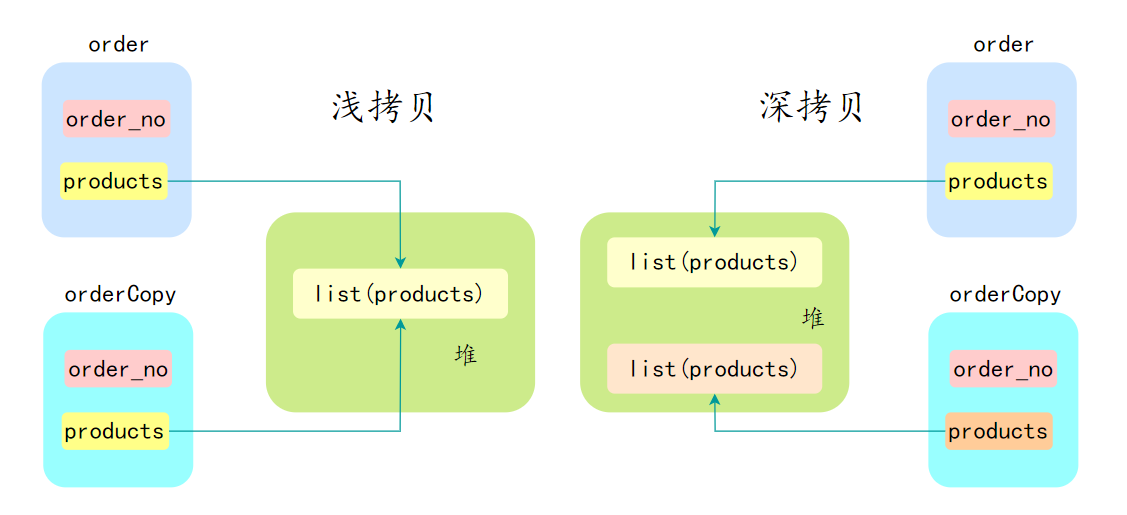 因此深拷贝是安全的,浅拷贝的话如果有引用类型,那么拷贝后对象,引用类型变量修改,会影响原对象。
因此深拷贝是安全的,浅拷贝的话如果有引用类型,那么拷贝后对象,引用类型变量修改,会影响原对象。
浅拷贝如何实现呢?
Object 类提供的 clone()方法可以非常简单地实现对象的浅拷贝。
// 浅拷贝示例
class ShallowCopyExample implements Cloneable {
int[] arr = {1, 2, 3};
public Object clone() throws CloneNotSupportedException {
return super.clone(); // 默认的clone()方法实现浅拷贝
}
}
深拷贝如何实现呢?
1、重写克隆方法:重写克隆方法,引用类型变量单独克隆,这里可能会涉及多层递归。
// 深拷贝示例
class DeepCopyExample implements Cloneable {
int[] arr = {1, 2, 3};
public Object clone() throws CloneNotSupportedException {
DeepCopyExample copy = (DeepCopyExample) super.clone();
copy.arr = arr.clone(); // 手动复制数组,实现深拷贝
return copy;
}
}
2、序列化:可以先将原对象序列化,再反序列化成拷贝对象
import java.io.*;
class Employee implements Serializable {
String name;
int age;
Department department;
public Employee(String name, int age, Department department) {
this.name = name;
this.age = age;
this.department = department;
}
// 深拷贝方法
public Employee deepCopy() throws IOException, ClassNotFoundException {
// 将对象写入到字节流中
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
// 从字节流中读取对象
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Employee) ois.readObject();
}
}
class Department implements Serializable {
String name;
public Department(String name) {
this.name = name;
}
}
public class DeepCopyExample {
public static void main(String[] args) {
Department dept = new Department("Engineering");
Employee original = new Employee("John Doe", 30, dept);
Employee copied = null;
try {
copied = original.deepCopy();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
// 修改原始对象的属性,以验证深拷贝
original.name = "Jane Doe";
original.department.name = "Human Resources";
System.out.println("Original Employee: " + original.name + ", Department: " + original.department.name);
System.out.println("Copied Employee: " + (copied != null ? copied.name : "null") + ", Department: " + (copied != null ? copied.department.name : "null"));
}
}
在这个示例中,Employee 类和 Department 类都实现了 Serializable 接口,这样它们的实例就可以被序列化和反序列化。Employee 类中的 deepCopy 方法通过序列化和反序列化实现了对象的深拷贝。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
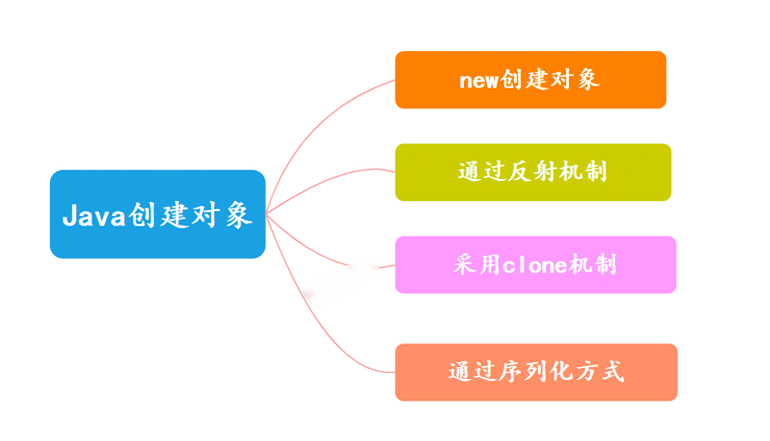
26、Java 创建对象有哪几种方式?
在Java中,创建对象的方式主要有4种:
- 使用new关键字
- 通过反射机制
- 使用clone()方法
- 使用反序列化
1、使用new关键字:
这是创建对象最常见的方式。通过调用类的构造器(构造方法)来创建类的实例。
MyClass obj = new MyClass();
2、使用Class类的newInstance方法:
通过反射机制,先获取到Class对象的引用,然后调用**newInstance()**方法创建对象。
这种方式要求类有一个无参数的构造方法。
MyClass obj = MyClass.class.newInstance();
// 或者
Class cls = Class.forName("MyClass");
MyClass obj = (MyClass) cls.newInstance();
3、使用Constructor类的newInstance方法:
同样是通过反射机制,但这种方式允许通过指定的构造器来创建对象,适用于无参和有参构造函数。
Constructor<MyClass> constructor = MyClass.class.getConstructor();
MyClass obj = constructor.newInstance();
4、使用clone()方法:
如果一个类实现了Cloneable接口,那么可以通过调用该类对象的**clone()**方法来创建一个新的对象副本。
MyClass original = new MyClass();
MyClass clone = (MyClass) original.clone();
5、使用反序列化:
通过从文件、数据库或网络等来源读取一个对象的序列化数据,然后反序列化成新的对象实例。
这种方式不会调用构造器。
ObjectInputStream in = new ObjectInputStream(new FileInputStream("data.obj"));
MyClass obj = (MyClass) in.readObject();
27、String 是 Java 基本数据类型吗?可以被继承吗?
在Java中,String不是基本数据类型,而是一个不可变的引用数据类型。
Java提供了八种基本数据类型,分别是:byte、short、int、long、float、double、char和boolean,它们用于存储简单的数值或字符类型的数据。
String类实际上是Java中的一个类,位于java.lang包下,用于表示字符串。String类内部使用字符数组存储字符数据,提供了丰富的方法来操作字符串。
关于String类是否可以被继承:
String类是被final修饰的,这意味着它不能被继承。在Java中,使用final修饰的类无法被其他类继承。这样设计的主要原因是为了保证String的不可变性(Immutable),不可变性带来了线程安全性、字符串池的可能以及保证了hashCode的不变,这些都是设计String时重要考虑的方面。
28、String 和 StringBuilder、StringBuffer 的区别?
在Java中,String、StringBuilder和StringBuffer都用于操作字符串,但它们之间存在一些关键的区别,主要体现在可变性和线程安全性上。
String:
- String是不可变的(Immutable),即一旦一个String对象被创建,它所包含的字符序列就不能改变。如果需要修改字符串,实际上是创建了一个新的String对象,然后将引用指向新对象。
- 不可变性使得String对象是线程安全的。
- 适合使用在字符串不经常改变的场景中。
StringBuilder:
- StringBuilder是可变的(Mutable),允许在原始字符串上进行修改,而不是每次修改都生成一个新的字符串。
- StringBuilder没有实现线程安全,它的方法没有被synchronized关键字修饰,因此在单线程环境下性能较好。
- 适用于字符串经常变化的场景,比如在使用循环或者频繁地对字符串进行操作时。
StringBuffer:
- StringBuffer也是可变的,和StringBuilder类似,但StringBuffer的所有公共方法都被synchronized关键字修饰,所以它是线程安全的。
- 由于线程安全,StringBuffer在多线程环境下使用更安全,但相比于StringBuilder有一定的性能损耗。
- 适用于多线程环境下需要对字符串内容进行操作的场景。
总结:
- 如果字符串内容不会改变,推荐使用String,因为其不可变性可以安全地在多个线程间共享。
- 如果字符串内容经常改变,并且操作仅限于单线程,推荐使用StringBuilder,因为它比StringBuffer更快。
- 如果字符串内容经常改变,并且需要在多线程环境中安全地操作字符串,应使用StringBuffer。
在实际开发中,选择哪种类型取决于具体的使用场景和性能要求。
String str = "Hello";
str += " World"; // 每次修改都会创建一个新的String对象
StringBuilder sb = new StringBuilder("Hello");
sb.append(" World"); // 直接在sb上追加字符串,不会创建新的对象
StringBuffer sbf = new StringBuffer("Hello");
sbf.append(" World"); // 线程安全地在sbf上追加字符串
29、String str1 = new String(“abc”)和 String str2 = “abc” 的区别?
String str1 = new String(“abc”) 和 String str2 = “abc” 在Java中表示创建字符串对象的两种不同方式,它们之间的主要区别体现在内存分配和字符串池的使用上。
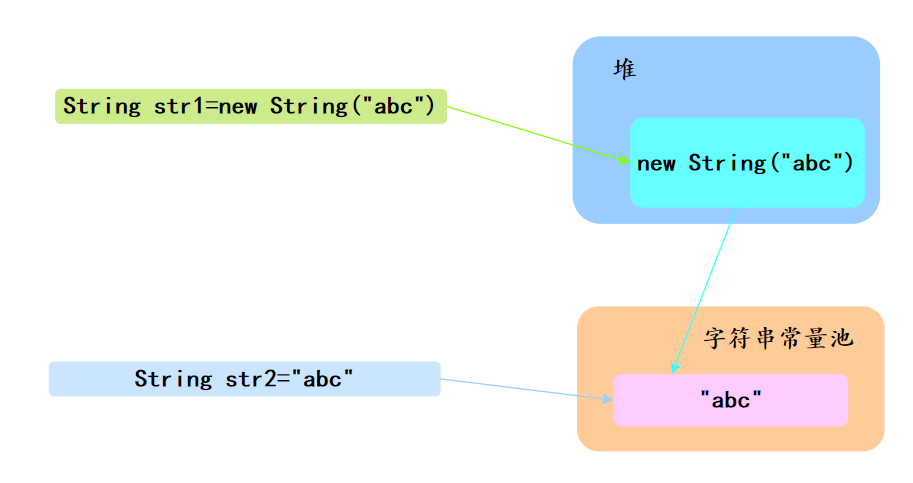
两个语句都会去字符串常量池中检查是否已经存在 “abc”,如果有则直接使用,如果没有则会在常量池中创建 “abc” 对象。
但是不同的是:
1、内存分配:
- 当执行 String str1 = new String(“abc”) 时,JVM会在堆(heap)内存中创建一个新的String对象。此外,“abc"字面量会被存放在字符串常量池中(如果常量池中尚未存在"abc”)。因此,这条语句实际上可能会创建两个对象:一个在堆中,另一个在字符串常量池中。
- 执行 String str2 = “abc” 时,JVM首先检查字符串常量池中是否已存在"abc"。如果存在,就不再创建新的对象,直接将str2引用指向常量池中的该对象。如果不存在,JVM会在字符串常量池中创建一个"abc"对象,并让str2引用它。这种方式不会在堆上创建对象。
2、字符串常量池的使用:
- 字符串常量池是Java为了减少相同字符串字面量的重复创建而专门设立的。它位于方法区。使用**String str2 = “abc”**方式创建的字符串会利用这个特性,节省内存,提高效率。
- 而通过**new String(“abc”)**显式创建的字符串对象,虽然内容相同,却不会共享常量池中的相同字面量对象,这样会消耗更多的内存。
3、字符串比较:
- 使用 == 运算符比较 str1 和 str2 时,结果为 false,因为 == 比较的是对象的引用地址,而 str1 和 str2 指向的是堆内存中不同的对象。
- 如果使用 str1.equals(str2) 进行比较,结果为 true,因为 equals() 方法比较的是字符串的内容。
public class StringCreationComparison {
public static void main(String[] args) {
String str1 = new String("abc");
String str2 = "abc";
System.out.println(str1 == str2); // 输出 false,因为引用不同
System.out.println(str1.equals(str2)); // 输出 true,因为内容相同
}
}
30、String 不是不可变类吗?字符串拼接是如何实现的?
String 的确是不可变的,“+”的拼接操作,其实是会生成新的对象。
例如:
String a = "hello ";
String b = "world!";
String ab = a + b;
在jdk1.8 之前,a 和 b 初始化时位于字符串常量池,ab 拼接后的对象位于堆中。经过拼接新生成了 String 对象。如果拼接多次,那么会生成多个中间对象。
内存如下:
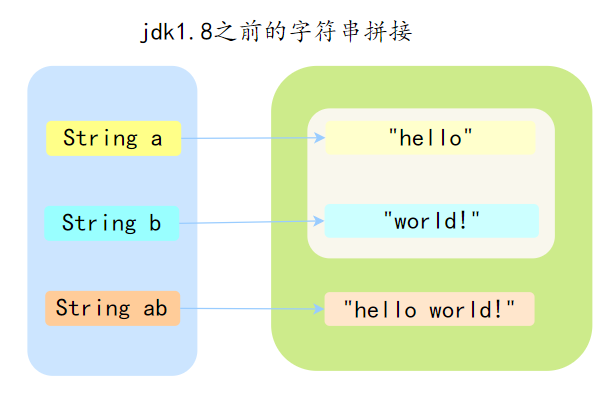
在Java8 时JDK 对“+”号拼接进行了优化,上面所写的拼接方式会被优化为基于 StringBuilder 的 append 方法进行处理。Java 会在编译期对“+”号进行处理。
下面是通过 javap -verbose 命令反编译字节码的结果,很显然可以看到 StringBuilder 的创建和 append 方法的调用。
stack=2, locals=4, args_size=1
0: ldc #2 // String hello
2: astore_1
3: ldc #3 // String world!
5: astore_2
6: new #4 // class java/lang/StringBuilder
9: dup
10: invokespecial #5 // Method java/lang/StringBuilder."<init>":()V
13: aload_1
14: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
17: aload_2
18: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
21: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
24: astore_3
25: return
也就是说其实上面的代码其实相当于:
String a = "hello ";
String b = "world!";
StringBuilder sb = new StringBuilder();
sb.append(a);
sb.append(b);
String ab = sb.toString();
此时,如果再笼统的回答:通过加号拼接字符串会创建多个 String 对象,因此性能比 StringBuilder 差,就是错误的了。因为本质上加号拼接的效果最终经过编译器处理之后和 StringBuilder 是一致的。
当然,循环里拼接还是建议用 StringBuilder,为什么,因为循环一次就会创建一个新的 StringBuilder 对象,大家可以自行实验。
31、intern方法有什么作用?
intern() 方法是 String 类的一个方法,它的作用是确保所有相同内容的字符串引用都指向字符串常量池中的同一个对象。
这个方法可以用来优化内存使用和提高性能,特别是在创建大量内容相同的字符串对象时。
intern方法的工作原理:
- 当调用一个字符串对象的 intern() 方法时,如果字符串常量池中已经包含一个等于此 String 对象的字符串,则返回常量池中这个字符串的字符串对象引用。
- 如果字符串常量池中不存在这个字符串,则将这个 String 对象包含的字符串添加到常量池中,并返回这个 String 对象的引用。
public class StringInternExample {
public static void main(String[] args) {
String s1 = new String("hello");
String s2 = "hello";
String s3 = s1.intern();
System.out.println(s1 == s2); // 输出 false,因为s1指向堆中的对象,而s2指向常量池中的对象
System.out.println(s2 == s3); // 输出 true,因为s3通过intern()方法得到了常量池中的对象引用
}
}
使用场景:
- intern() 方法非常适合在需要大量重复字符串的场景中使用,比如在读取大量文本数据并解析为字符串时,通过使用 intern() 可以显著减少内存占用。
- 在Java 7及更高版本中,字符串常量池被移至堆内存中,这意味着使用 intern() 方法不会像早期版本那样受到永久代(PermGen space)大小的限制。
32、Integer a= 127,Integer b = 127;Integer c= 128,Integer d = 128;相等吗?
在Java中,Integer类型的对象比较需要注意自动装箱和缓存机制的影响。
自动装箱与Integer缓存:
- 自动装箱:是Java提供的一个自动将基本数据类型转换为对应的包装类型的特性。
- 例如,将int类型自动转换为Integer类型。
- Integer缓存:Java为了优化性能和减少内存使用,在Integer类中实现了一个内部缓存。
- 根据Java规范,默认情况下,这个缓存范围是从**-128到127**。
根据这两个特性,我们来分析:
- Integer a = 127; Integer b = 127; 这里的a和b因为值在缓存范围内,所以它们会指向缓存中的同一个对象。
因此,a == b的结果是true。
- Integer c = 128; Integer d = 128; 这里的c和d因为值超出了默认的缓存范围,所以会创建新的Integer对象。
因此,c == d的结果是false。
public class IntegerEquality {
public static void main(String[] args) {
Integer a = 127;
Integer b = 127;
Integer c = 128;
Integer d = 128;
System.out.println(a == b); // 输出 true
System.out.println(c == d); // 输出 false
}
}
需要注意的是,使用**==操作符比较Integer对象时,实际上是比较它们的引用地址。如果需要比较两个Integer对象的数值是否相等,应该使用.equals()方法,例如a.equals(b),这样无论数值是否在缓存范围内,只要数值相等,都会返回true**。
33、String 怎么转成 Integer 的?原理是什么?
PS:这道题印象中在一些面经中出场过几次。
String 转成 Integer,主要有两个方法:
- Integer.parseInt(String s)
- Integer.valueOf(String s)
不管哪一种,最终还是会调用 Integer 类内中的parseInt(String s, int radix)方法。
抛去一些边界之类的看看核心代码:
public static int parseInt(String s, int radix)
throws NumberFormatException
{
int result = 0;
//是否是负数
boolean negative = false;
//char字符数组下标和长度
int i = 0, len = s.length();
……
int digit;
//判断字符长度是否大于0,否则抛出异常
if (len > 0) {
……
while (i < len) {
// Accumulating negatively avoids surprises near MAX_VALUE
//返回指定基数中字符表示的数值。(此处是十进制数值)
digit = Character.digit(s.charAt(i++),radix);
//进制位乘以数值
result *= radix;
result -= digit;
}
}
//根据上面得到的是否负数,返回相应的值
return negative ? result : -result;
}
原理解析:
- 解析过程: 在转换过程中,这两个方法实际上是通过遍历字符串中的每个字符,检查它是否是有效的数字字符(0-9),同时考虑符号位(正号**+和负号-**),然后将每个字符代表的数值乘以相应的十的幂次方累加起来,最终得到整数的值。
- 错误处理: 如果字符串包含非数字字符(不包括字符串开始处的正负号),则会抛出NumberFormatException。这是因为这些方法只能解析标准的数字表示形式。
- 性能考虑:Integer.valueOf(String s)相比Integer.parseInt(String s),valueOf方法还涉及到从缓存中返回实例的过程(对于**-128到127**之间的值),可能会有微小的性能差异。
public class StringToInteger {
public static void main(String[] args) {
String strNumber = "123";
// 使用 parseInt 方法
int number1 = Integer.parseInt(strNumber);
System.out.println("使用 parseInt 转换的结果:" + number1);
// 使用 valueOf 方法
Integer number2 = Integer.valueOf(strNumber);
System.out.println("使用 valueOf 转换的结果:" + number2);
}
}
34、Object 类的常见方法是什么?
Object类是Java中所有类的根类,每个类都使用Object作为超类。
所有对象(包括数组)都实现了这个类的方法。Object类提供了以下几个常见的方法:
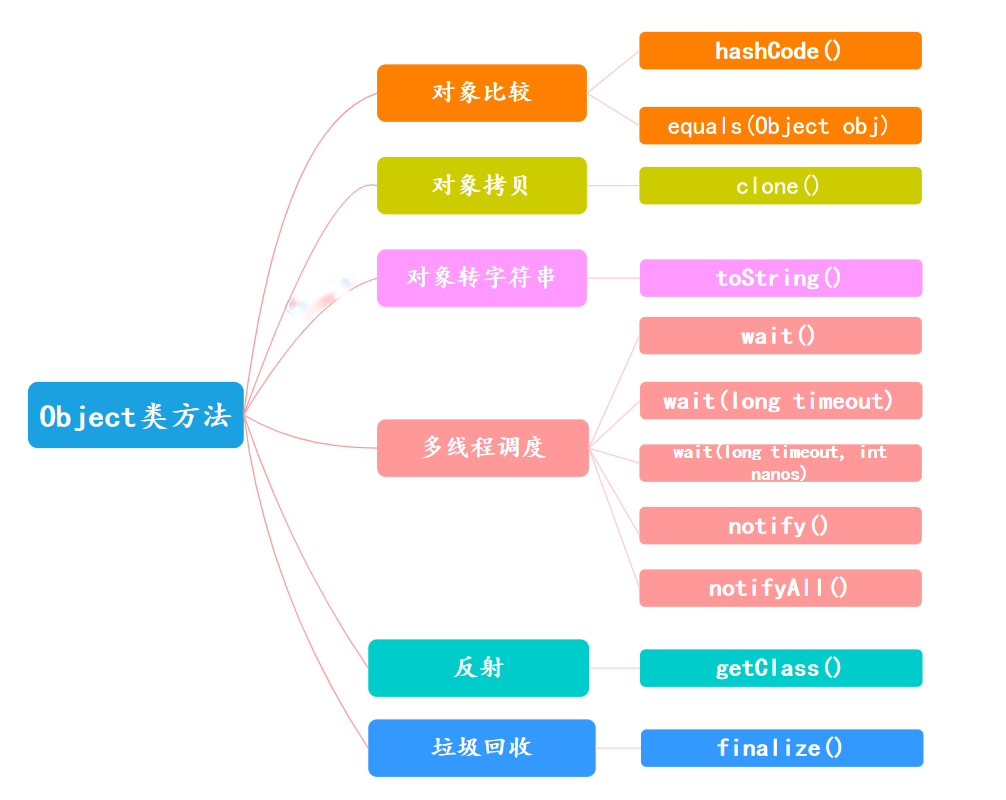
反射:
1、public final native Class<?> getClass():
返回此对象的运行时类。通过这个方法可以获得对象所属的类信息,如类的名称、方法信息、字段信息等。
对象比较:
2、public int hashCode():
返回对象的哈希码值。哈希码的使用主要在哈希表如HashMap、HashSet等数据结构中,用于确定对象的存储地址。
3、public boolean equals(Object obj):
指示某个其他对象是否与此对象“相等”。默认实现是比较两个对象的地址是否相同,即是否为同一个对象。
对象拷贝:
4、protected Object clone() throws CloneNotSupportedException:
创建并返回此对象的一个副本。默认情况下,clone()方法是浅复制。
但可以通过重写clone方法实现深复制。
对象转字符串:
5、public String toString():
返回对象的字符串表示。默认实现返回类名加上“@”符号后跟对象的哈希码的无符号十六进制表示。
多线程调度:
6、public final void wait(long timeout) throws InterruptedException:
导致当前线程等待,直到另一个线程调用此对象的**notify()方法或notifyAll()**方法,或者超过指定的时间量。
7、public final native void notify():
唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。
8、public final native void notifyAll():
唤醒在此对象监视器上等待的所有线程。
垃圾回收:
9、protected void finalize() throws Throwable:
由垃圾收集器在确定没有对该对象的更多引用时调用的方法。Java 9开始弃用此方法。
35、Java 中的异常处理体系是什么?
Java的异常处理体系是通过类的继承结构来组织的,旨在提供一种健壮的机制来处理运行时的错误。
Java中的异常(Exception)和错误(Error)都是从Throwable类继承而来,它们是Java异常体系的根。在这个体系中,主要可以分为两大类:Error和Exception。

1、Error:
- Error类表示编译时和系统错误(外部错误),通常是程序无法处理的。这些错误发生时,JVM通常会选择终止程序。
- 例如:OutOfMemoryError(内存溢出)、StackOverflowError(栈溢出)等。
2、Exception:
- Exception类表示程序本身可以处理的异常。它又细分为两类:检查型异常(checked exceptions)和非检查型异常(unchecked exceptions)。
- 2.1、检查型异常(Checked Exceptions):
- 必须在编写可能会抛出这些异常的方法时显示地进行捕获(try-catch)或声明(throws)。
- 检查型异常主要包括那些反映外部错误的异常,这些错误不受程序控制。例如:IOException、SQLException等。
- 2.2、非检查型异常(Unchecked Exceptions):
- 包括运行时异常(RuntimeException)及其子类。
- 程序错误导致的异常,如逻辑错误或API的错误使用。例如:NullPointerException、ArrayIndexOutOfBoundsException、IllegalArgumentException等。
- 非检查型异常是不需要强制进行捕获或声明的。
异常处理关键字: Java提供了try、catch、finally、throw、throws关键字来处理异常:
- try:定义一个代码块,用来捕获异常。
- catch:捕获和处理try块中抛出的异常。
- finally:定义一个代码块,无论是否发生异常,该代码块都会执行。
- throw:手动抛出一个异常实例。
- throws:用在方法签名中,声明该方法可能会抛出的异常。
public class ExceptionExample {
public static void main(String[] args) {
try {
int result = 10 / 0; // 这会导致ArithmeticException
} catch (ArithmeticException e) {
System.err.println("捕获到算术异常: " + e.getMessage());
} finally {
System.out.println("这里的代码总是会执行。");
}
}
}
36、Java中异常的处理方式有哪些?
Java中处理异常的方式主要通过以下几种关键字实现:try、catch、finally、throw、throws。
每种关键字都有其特定的使用场景和目的,使得Java程序能够更加健壮和可靠。
1、使用try-catch捕获异常:
- try块中包含可能会抛出异常的代码。如果在try块内的代码抛出了异常,那么该异常会被发送到一个或多个catch块处理。
- catch块跟随在try块后面,用来捕获并处理特定类型的异常。catch块可以有一个或多个,每个catch块针对一种类型的异常。
2、使用finally清理资源:
- finally块总是在try块执行完毕后执行,无论是否抛出异常。它通常用于清理资源,如关闭文件流或数据库连接等。
3、使用throw抛出异常:
- throw关键字用来手动抛出一个异常实例。使用throw可以抛出已检测到的异常或自定义异常,这些异常必须符合方法的异常声明。
4、使用throws声明异常:
- throws关键字用在方法签名中,用来声明该方法可能会抛出的异常类型。如果方法内部抛出的异常没有在方法内捕获,那么这些异常必须通过throws在方法声明中进行声明。
public class ExceptionHandlingExample {
public static void main(String[] args) {
try {
int result = divide(10, 0);
} catch (ArithmeticException e) {
System.err.println("发生算术异常: " + e.getMessage());
} finally {
System.out.println("这是finally块,总会被执行。");
}
}
public static int divide(int numerator, int denominator) throws ArithmeticException {
if (denominator == 0) {
throw new ArithmeticException("除数不能为0。");
}
return numerator / denominator;
}
}
在这个例子中,divide方法通过throw关键字抛出ArithmeticException异常。在main方法中,调用divide方法的代码被包裹在try-catch块中,以捕获并处理可能发生的ArithmeticException。无论是否发生异常,finally块都会被执行。
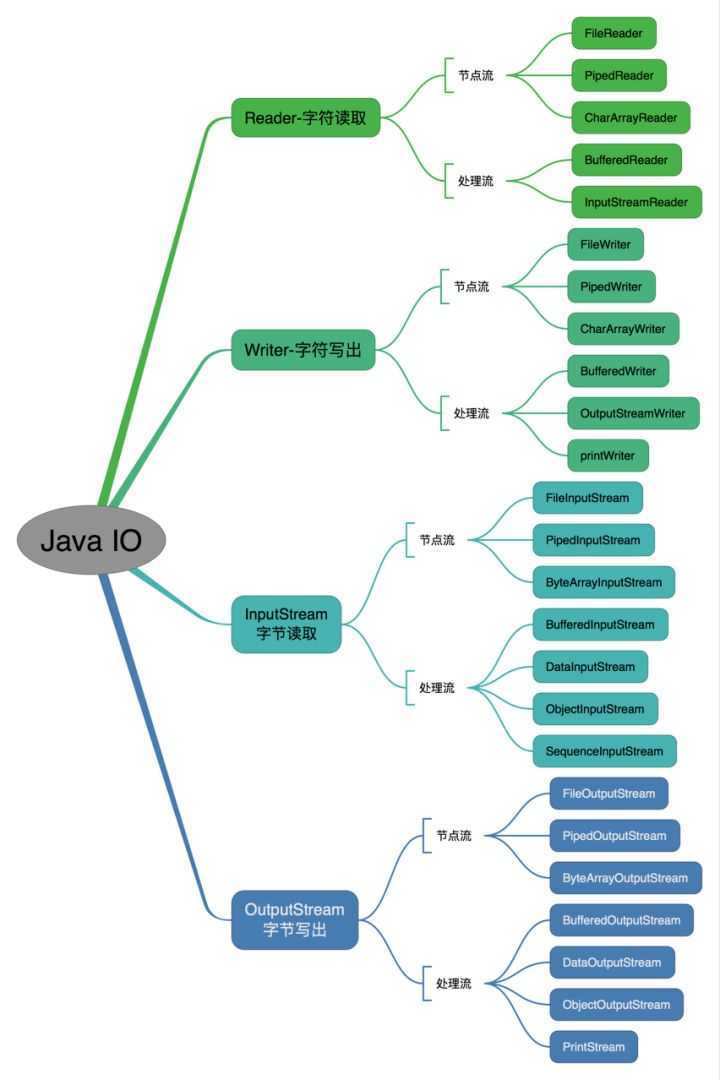
37、Java 中 IO 流分为几种?
流按照不同的特点,有很多种划分方式。
- 按照流的流向分,可以分为输入流和输出流;
- 按照操作单元划分,可以划分为字节流和字符流;
- 按照流的角色划分为节点流和处理流
Java Io 流共涉及 40 多个类,看上去杂乱,其实都存在一定的关联, Java I0 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
 IO > 流用到了什么设计模式?
IO > 流用到了什么设计模式?
其实,Java 的 IO 流体系还用到了一个设计模式——装饰器模式。
InputStream 相关的部分类图如下,篇幅有限,装饰器模式就不展开说了,感兴趣的同学可以阅读这篇教程:装饰者设计模,详细了解装饰着设计模式的精髓
38、Java中既然有了字节流,为什么还要有字符流?
Java中的字节流和字符流各自承担不同的数据处理任务,主要基于处理数据的类型(字节或字符)和编码的考量。
尽管字节流(Byte Streams)能够处理所有类型的数据,包括文本和二进制数据,但字符流(Character Streams)的引入主要是为了更方便、更有效地处理字符数据,尤其是考虑到不同的字符编码。
主要原因如下:
1、字符编码的抽象:
- 字符流提供了一个重要的层次,即对字符编码的抽象。字符流自动处理字符到字节的转换过程,并考虑到了不同的字符编码方式(如UTF-8、ISO-8859-1等),使得处理文本数据时不必关心底层的字节表示和编码问题。
2、国际化支持:
- 随着全球化的发展,软件需要支持多种语言,这就需要处理各种字符集。字节流在处理不同语言的文本数据时,开发者需要明确指定字符集来正确解码,处理起来较为繁琐。字符流通过封装这一过程,简化了国际化应用的开发。
3、文本文件的便捷处理:
- 字符流提供了直接读取和写入字符的方法,这使得读写文本文件更加直接和便捷。例如,BufferedReader和BufferedWriter提供的**readLine()和write()**方法,可以非常方便地按行处理文本数据。
4、性能优化和资源利用:
- 对于文本数据的处理,字符流通过提供缓冲等机制,能够有效地减少物理读写次数,优化性能。同时,字符流在处理字符时能够自动应对字符与字节之间的转换,减少了开发者在资源管理方面的负担。
对比:
使用字节流读取文本文件时,你需要手动处理字符编码和解码,可能会面临乱码问题。
而使用字符流(如FileReader和FileWriter),Java虚拟机会自动进行字符编码和解码,开发者可以更专注于业务逻辑的实现。
总结:
字符流的设计主要是为了提高处理文本数据的效率和便捷性,尤其是在多语言环境下的应用。它们补充了字节流在字符数据处理方面的不足,使得Java I/O库能够更全面地满足不同场景下的数据处理需求。
39、详细说BIO、NIO、AIO?
在Java中,BIO、NIO和AIO代表不同的IO模型,每个模型都有其特定的使用场景和性能特点。
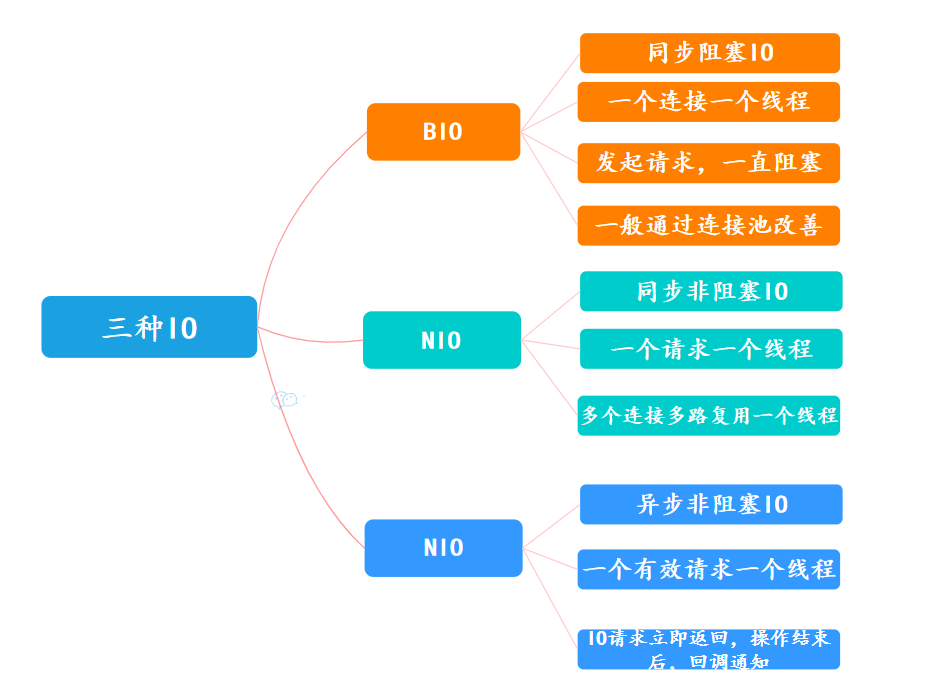
BIO(Blocking IO):
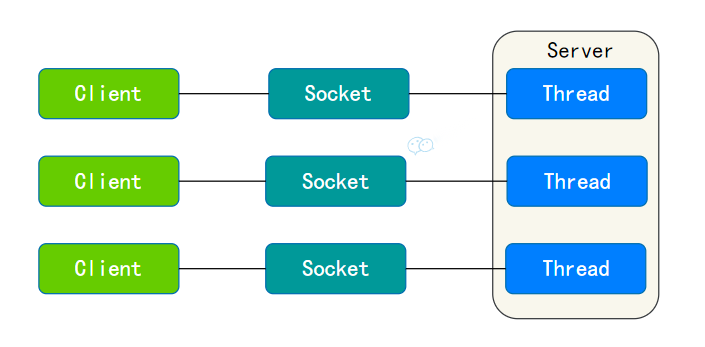
BIO即阻塞同步IO模型
在BIO模型中,当一个线程调用读取或写入操作时,线程会被阻塞,直到有数据可读,或数据完全写入。这意味着在操作完成之前,该线程不能做任何事情。
- BIO是一个简单的IO模型,易于理解和使用,但是它的缺点也非常明显:
当需要处理成千上万的客户端连接时,BIO模型需要创建与客户端数量相同的线程,这会导致巨大的线程开销,并且大量线程的上下文切换也会严重影响性能。
BIO更适用于连接数目比较小且固定的架构,这种模式可以让线程之间的调度更简单。
NIO(Non-blocking IO):
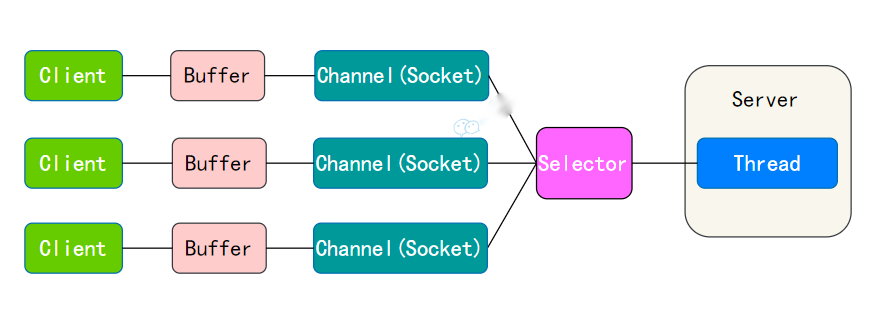
NIO是非阻塞同步IO模型
它引入了通道(Channel)、缓冲区(Buffer)和选择器(Selector)等概念。
在NIO模式下,可以让一个线程处理多个客户端连接,通过单个线程轮询所有请求,实现多客户端的接入。
- NIO支持面向缓冲的(Buffer-Oriented)IO操作,IO操作主要围绕缓冲区展开。数据的读取写入需要经过Buffer。
- Selector允许单个线程管理多个Channel的IO事件,如连接请求、读数据等。只有当Channel真正有读写事件发生时,才会进行读写,大大减少了系统的开销。
- NIO适用于连接数目多且连接比较短(轻操作)的架构,如聊天服务器、服务器间通信等。
AIO(Asynchronous IO):
- AIO即异步非阻塞IO模型,它是基于事件和回调机制实现的,可以实现真正的异步IO操作。在AIO模型中,IO操作不会导致线程阻塞,而是在操作完成时通过系统回调通知应用程序。
- AIO引入了异步通道的概念,提供了异步文件通道和异步套接字通道等。应用程序可以直接对这些通道执行异步读写操作,操作完成后会得到系统通知,应用程序可以继续进行其他任务。
- AIO适用于连接数目多且连接持续时间长(重操作)的架构,如高性能的服务器、大量并发的文件操作等。
总结:
- BIO:适合连接数少且固定的应用场景,模型简单,使用方便。
- NIO:通过单线程处理多个连接的方式,适合连接数目多但轻操作的场景,提高了性能和资源利用率。
- AIO:适合高性能、大并发的应用场景,实现了真正的异步非阻塞IO操作,提高了响应速度和系统的吞吐量。
40、什么是序列化?什么是反序列化?
什么是序列化,序列化就是把 Java 对象转为二进制流,方便存储和传输。
序列化主要用于远程通信(如,在网络中传输对象)和持久化数据(如,保存对象状态到文件)。
反序列化(Deserialization):是序列化过程的逆过程,它将序列化后的字节序列恢复为对象。
通过反序列化,可以从文件、数据库或网络中接收到的字节序列中重建对象的状态。
Java中的序列化和反序列化:
在Java中,可以通过实现java.io.Serializable接口来使对象可序列化,该接口是一个标记接口,不包含任何方法。
但是如果不实现这个接口,在有些序列化场景会报错,所以一般建议,创建的 JavaBean 类都实现 Serializable。
那么serialVersionUID 又有什么用?
serialVersionUID 就是起验证作用。
private static final long serialVersionUID = 1L;
我们经常会看到这样的代码,这个 ID 其实就是用来验证序列化的对象和反序列化对应的对象 ID 是否一致。
这个 ID 的数字其实不重要,无论是 1L 还是 IDE 自动生成的,只要序列化时候对象的 serialVersionUID 和反序列化时候对象的 serialVersionUID 一致的话就行。
如果没有显示指定 serialVersionUID ,则编译器会根据类的相关信息自动生成一个,可以认为是一个指纹。
所以如果你没有定义一个 serialVersionUID, 结果序列化一个对象之后,在反序列化之前把对象的类的结构改了,比如增加了一个成员变量,则此时的反序列化会失败。
因为类的结构变了,所以 serialVersionUID 就不一致。
Java 序列化包不包含静态变量?
序列化的时候是不包含静态变量的。
如果有些变量不想序列化,怎么办?
对于不想进行序列化的变量,使用transient关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
41、说说有几种序列化方式?
在Java中,存在多种序列化方式,每种方式都有其特定的使用场景和优缺点。
主要的序列化方式包括Java原生序列化、XML序列化、JSON序列化等。
1、Java原生序列化:
使用java.io.Serializable接口实现对象的序列化和反序列化。该方法主要用于Java对象的深度复制,以及通过网络或文件系统存储对象的状态。
但是,Java原生序列化的缺点是产生的序列化数据较大,序列化过程性能也不是最优的。
import java.io.*;
// 定义一个可序列化的类
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private transient int age; // 使用transient关键字标记的字段不会被序列化
public User(String name, int age) {
this.name = name;
this.age = age;
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
User user = new User("Tom", 25);
// 序列化
FileOutputStream fos = new FileOutputStream("user.ser");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(user);
oos.close();
// 反序列化
FileInputStream fis = new FileInputStream("user.ser");
ObjectInputStream ois = new ObjectInputStream(fis);
User deserializedUser = (User) ois.readObject();
ois.close();
System.out.println(deserializedUser.name); // 输出: Tom
System.out.println(deserializedUser.age); // 输出: 0,因为age是transient,不会被序列化
}
}
2、XML序列化:
XML(eXtensible Markup Language)是一种标记语言,用于表示分层数据和文档。
在Java中,可以使用JAXB(Java Architecture for XML Binding)实现对象到XML的序列化和反序列化。
import javax.xml.bind.JAXBContext;
import javax.xml.bind.Marshaller;
import javax.xml.bind.annotation.XmlRootElement;
@XmlRootElement
public class User {
private String name;
private int age;
// 必须有无参构造函数
public User() {}
// getter和setter省略
public static void main(String[] args) throws Exception {
User user = new User("Tom", 25);
// 序列化到XML
JAXBContext context = JAXBContext.newInstance(User.class);
Marshaller marshaller = context.createMarshaller();
marshaller.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, Boolean.TRUE);
marshaller.marshal(user, System.out);
}
}
3、JSON序列化:
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,也易于机器解析和生成。
Java中可以使用第三方库(如Google的Gson、FasterXML的Jackson等)进行JSON序列化和反序列化。
Gson示例:
import com.google.gson.Gson;
public class JsonExample {
public static void main(String[] args) {
User user = new User("Tom", 25);
// 使用Gson进行序列化
Gson gson = new Gson();
String json = gson.toJson(user);
System.out.println(json);
// 使用Gson进行反序列化
User userFromJson = gson.fromJson(json, User.class);
System.out.println(userFromJson.name);
}
}
42、Java 泛型了解么?什么是类型擦除?介绍一下常用的通配符?
什么是泛型?
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
List<Integer> list = new ArrayList<>();
list.add(12);
//这里直接添加会报错
list.add("a");
Class<? extends List> clazz = list.getClass();
Method add = clazz.getDeclaredMethod("add", Object.class);
//但是通过反射添加,是可以的
add.invoke(list, "kl");
System.out.println(list);
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
1、泛型类
//泛型类-通用的容器类
public class Box<T> {
private T t;
public void set(T t) {
this.t = t;
}
public T get() {
return t;
}
}
//泛型类-键值对
public class Pair<K, V> {
private K key;
private V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() { return key; }
public V getValue() { return value; }
}
//泛型类示例 - 数字容器,限定泛型为Number类或其子类
public class NumericBox<N extends Number> {
private N number;
public NumericBox(N number) {
this.number = number;
}
public N getNumber() {
return number;
}
}
2、泛型接口
//泛型接口示例 - 仓库接口
public interface Repository<T> {
void save(T item);
T find(int id);
}
//泛型接口示例 - 比较器
public interface Comparator<T> {
int compare(T o1, T o2);
}
//泛型接口示例 - 生成器
public interface Generator<T> {
T generate();
}
3、泛型方法示例
//泛型方法示例 - 交换数组中的两个元素
public class ArrayUtils {
public static <T> void swap(T[] array, int i, int j) {
T temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
//泛型方法示例 - 创建对应类型的集合
public class CollectionUtils {
public static <T> List<T> newList() {
return new ArrayList<T>();
}
}
43、说一下你对Java注解的理解?
Java 注解本质上是一个标记,可以理解成生活中的一个人的一些小装扮,比如戴什么什么帽子,戴什么眼镜。
注解可以被用来为编译器提供信息、编译时和部署时的处理,以及运行时的处理。
通过使用注解,开发者可以在不改变原有逻辑的情况下,增加一些额外信息或者功能。
注解可以标记在类上、方法上、属性上等,标记自身也可以设置一些值,比如帽子颜色是绿色。
有了标记之后,我们就可以在编译或者运行阶段去识别这些标记,然后搞一些事情,这就是注解的用处。
例如我们常见的 AOP,使用注解作为切点就是运行期注解的应用;
比如 lombok,就是注解在编译期的运行。
注解生命周期有三大类,分别是:
- RetentionPolicy.SOURCE:给编译器用的,不会写入 class 文件
- RetentionPolicy.CLASS:会写入 class 文件,在类加载阶段丢弃,也就是运行的时候就没这个信息了
- RetentionPolicy.RUNTIME:会写入 class 文件,永久保存,可以通过反射获取注解信息
所以我上文写的是解析的时候,没写具体是解析啥,因为不同的生命周期的解析动作是不同的。
像常见的:
就是给编译器用的,编译器编译的时候检查没问题就 over 了,class 文件里面不会有 Override 这个标记。
再比如 Spring 常见的 Autowired ,就是 RUNTIME 的,所以在运行的时候可以通过反射得到注解的信息,还能拿到标记的值 required 。

44、什么是反射?分别说下反射的原理和应用?
什么是反射?
我们通常都是利用new方式来创建对象实例,这可以说就是一种“正射”,这种方式在编译时候就确定了类型信息。
而如果,我们想在时候动态地获取类信息、创建类实例、调用类方法这时候就要用到反射。
通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
反射最核心的四个类:
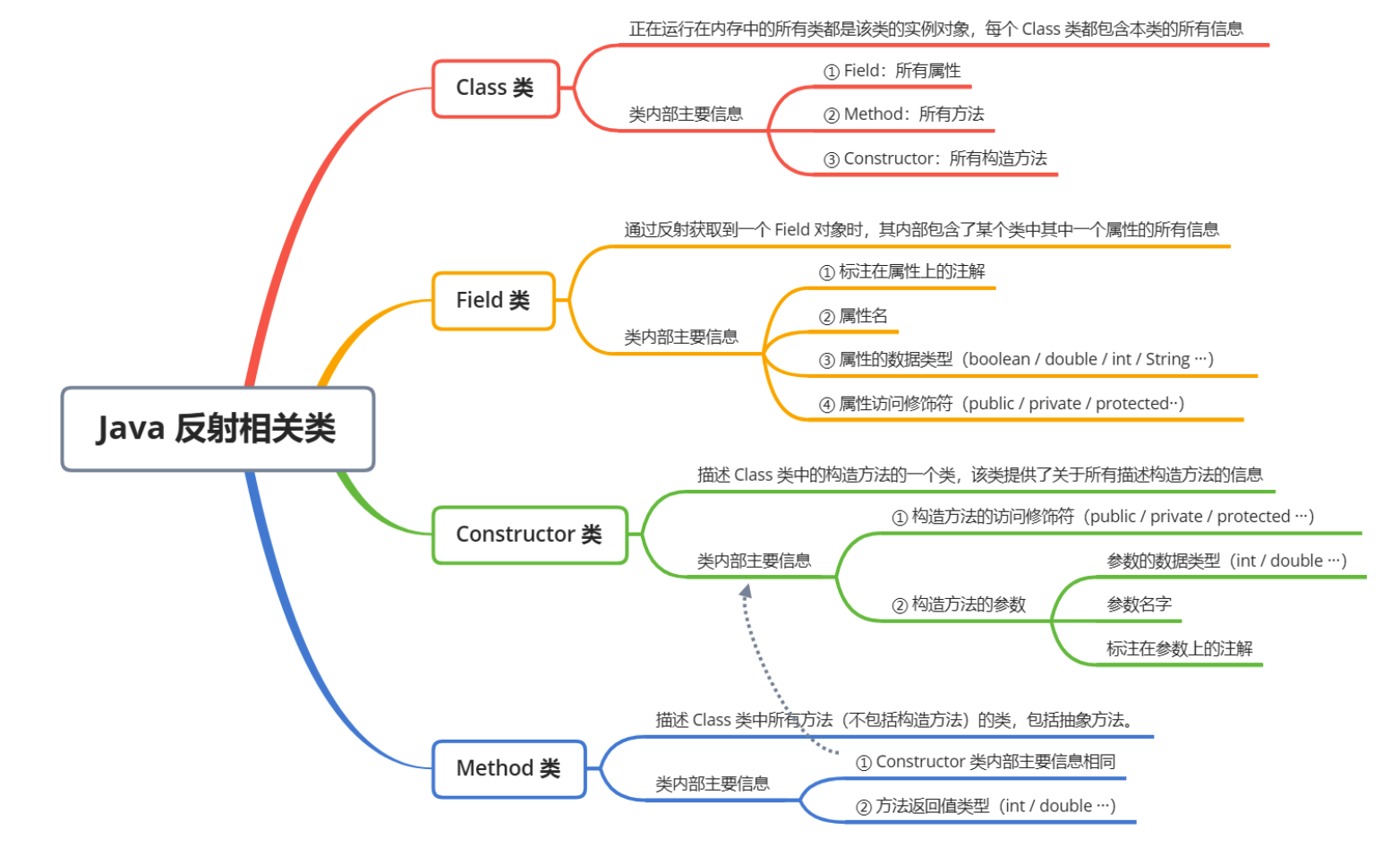
反射的原理:
- 类加载过程: 当程序使用到某个类时,Java虚拟机(JVM)会将该类加载到内存中,每个类被加载后,JVM会为其生成一个Class类型的对象(即类对象),类对象中包含了与类相关的元数据信息,如类的方法、字段、构造器、父类等。
- 通过类对象访问元数据: 反射机制通过这个Class对象访问类的元数据信息,然后利用Java语言中的接口来创建对象、调用方法或者访问字段等。因此,反射的核心就是Class类及其相关API。
反射的应用:
1、动态创建对象和调用方法:
反射可以在运行时动态创建对象和调用对象的方法,这使得Java能够实现动态脚本语言的一些特性。例如,可以通过类名字符串在运行时创建对应的对象实例。
2、依赖注入(DI)和控制反转(IoC):
许多现代Java框架,如Spring,都广泛使用反射来实现依赖注入。框架通过读取配置文件或注解,然后利用反射创建对象和设置对象间的依赖关系。
3、单元测试框架:
如JUnit,它使用反射来动态调用标记为测试方法的方法,无需手动一个个调用。
4、ORM(对象关系映射)框架:
如Hibernate和MyBatis,它们使用反射将数据库表映射为Java对象,从而简化了数据持久化的操作。
5、动态代理:
反射机制被用来实现动态代理,这在很多框架中都有应用,如Java的动态代理API、Spring AOP等。
45、JDK1.8 都有哪些新特性?
JDK 1.8(也称为Java 8)引入了许多重要的新特性,这些特性旨在提高Java语言的表现力、功能性和性能。
以下是Java 8的一些关键新特性:
1、Lambda表达式:
- Lambda表达式引入了一个清晰而简洁的方式来表示单方法接口(称为功能接口)的实例,使得编写匿名内部类变得更加简单。
Runnable r = () -> System.out.println("Hello Lambda!");
r.run();
2、方法引用(Method References):
- 方法引用提供了一种引用直接调用方法的方式,它的语法是使用两个冒号**:😗*将类或对象和方法名分隔开来。这一特性结合Lambda表达式能使代码更简洁易读。
List<String> list = Arrays.asList("a", "b", "c");
list.forEach(System.out::println);
3、接口的默认方法和静态方法:
- Java 8允许在接口中包含具有实现的方法,这些方法被称为默认方法。接口中也可以定义静态方法。
interface MyInterface {
default void defaultMethod() {
System.out.println("This is a default method");
}
static void staticMethod() {
System.out.println("This is a static method");
}
}
4、Stream API:
- Java 8引入了流(Stream)API,这是对集合(Collection)对象进行操作的一种高级工具,支持顺序和并行处理。
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
List<String> filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());
5、Optional类:
- Optional类是一个容器类,代表一个值存在或不存在。它提供了一种更好的方法来处理null值,避免NullPointerException。
Optional<String> optional = Optional.ofNullable(null);
System.out.println(optional.isPresent()); // false
System.out.println(optional.orElse("fallback")); // "fallback"
6、新的日期时间API:
- 引入了一个全新的日期和时间API,在java.time包下,这个新的API解决了旧版日期时间API存在的线程安全问题,同时也提供了更为简洁的方法来处理日期和时间。
LocalDateTime now = LocalDateTime.now();
System.out.println("Now: " + now);
7、Nashorn JavaScript引擎:
- Nashorn,一个新的轻量级JavaScript引擎,允许在JVM上运行JavaScript应用。
// 需要通过JShell或将JavaScript代码作为字符串传递给Nashorn引擎执行,此处仅为示意。
String javaScriptCode = "print('Hello Nashorn');";
8、并行数组(Parallel Arrays):
- 通过Arrays类中的**parallelSort()**方法,可以并行地对数组进行排序,利用多核处理器的计算能力,提高排序性能。
int[] array = {4, 1, 3, 2, 5};
Arrays.parallelSort(array);
System.out.println(Arrays.toString(array)); // 输出排序后的数组
9、集合类的改进:
- 在Collections类中加入了removeIf方法,允许根据某个条件来删除满足该条件的所有元素。
List<String> myList = new ArrayList<>();
myList.add("One");
myList.add("Two");
myList.add("Three");
myList.removeIf(item -> item.startsWith("O")); // 删除以"O"开头的字符串
10、CompletableFuture:
- CompletableFuture提供了一个更加强大的Future API,它允许你以异步的方式计算结果,编写非阻塞的代码,并且可以手动完成计算。
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "Hello");
completableFuture.thenAccept(System.out::println); // 异步执行后的处理
46、Java中处理空指针的方式有哪几种?
有一次在面试过程中,被面试官突然问到这道题,瞬间大脑一片空白,主要日常我们处理空指针主要是做好检查,其他的方式没有思考过。
但是面试官就是想看你日常有没有思考过其他的处理方案。
在Java中,处理空指针异常(NullPointerException)的方式可以有以下几种方式:
1、检查变量是否为null:
在对对象进行操作之前,先检查该对象是否为null,从而避免空指针异常的发生。
这也是我们日常最常用的方式
public class NullCheckExample {
public static void main(String[] args) {
String str = null;
if (str != null) {
System.out.println(str.length());
} else {
System.out.println("String is null");
}
}
}
2、使用Optional类:
Java 8引入了Optional类,它是一个容器对象,可以包含也可以不包含非null值。
通过使用Optional,你可以避免显式的null检查。
import java.util.Optional;
public class OptionalExample {
public static void main(String[] args) {
String str = null;
Optional<String> optionalStr = Optional.ofNullable(str);
System.out.println(optionalStr.orElse("String is null"));
}
}
3、使用try-catch捕获异常:
如果无法避免空指针异常的发生,可以使用try-catch语句捕获异常,从而防止程序崩溃。
public class TryCatchExample {
public static void main(String[] args) {
String str = null;
try {
System.out.println(str.length());
} catch (NullPointerException e) {
System.out.println("Caught NullPointerException: " + e.getMessage());
}
}
}
4、使用Objects类中的静态方法:
Java 7引入了Objects类,它提供了一些静态方法来处理对象,例如**Objects.requireNonNull()**可以用来检查对象是否为null,并在对象为null时抛出异常。
import java.util.Objects;
public class ObjectsExample {
public static void main(String[] args) {
String str = null;
try {
Objects.requireNonNull(str, "String cannot be null");
} catch (NullPointerException e) {
System.out.println(e.getMessage());
}
}
}
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
项目文档&视频:
开源:项目文档 & 视频 Github-Doc
本文,已收录于,我的技术网站 aijiangsir.com,有大厂完整面经,工作技术,架构师成长之路,等经验分享
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!