如果想实现一个计算机视觉应用,而不想从零开始训练权重,比方从随机初始化开始训练,更快的方式是下载已经训练好权重的网络结构,把这个作为预训练,迁移到你感兴趣的新任务上。ImageNet、PASCAL等等数据库已经公开在线。许多计算机视觉的研究者已经在上面训练了自己的算法,训练要耗费很长时间,很多GPU,有人已经经历过这种痛苦,可以下载这种开源的权重,为你自己的神经网络做好的初始化开端,而且可以用迁移学习来迁移知识,从这些大型公共数据库迁移知识到自己的问题上。
举例
比如有两只猫的名字是Tiggar和Misty,下载了框架,前面的可以都不用改,可以修改一下后面的softmax,根据自己的需要替换一下框架中的softmax即可。前面的参数不需要训练了,可以只训练softmax层的权重,同时冻结前面所有层
如果你的训练集比较小,用前面固定函数(该神经网络的前半部分)接受任一输入图像X,然后计算其特征向量,然后一句这个特征向量训练一个浅层softmax模型去预测,因此,预计算之前层的激活结果是有利于你计算的操作,(预计算)训练集所有样本(激活结果)并存到硬盘上,然后训练右边的softmax类别。这样做的好处是你不需要在训练集上每次迭代,重新计算这些激活结果。
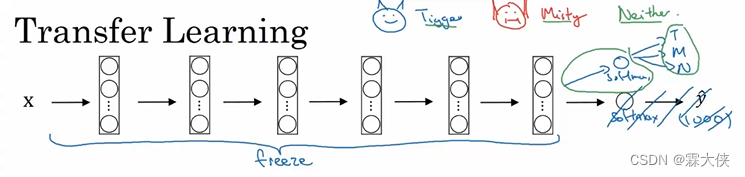
如果你的训练集比较大,你可以冻结更少的层数,训练后面这些层,尽管输出层的类别与你需要的不同,你可以用最后几层权重作为初始化开始做梯度下降(训练),或者也可以去掉最后几层,用自己的神经元和最终的softmax输出(训练)。即你的数据越多,所冻结的层数可以越少,自己训练的层数可以越多

如果有很多数据,可以用开源网络和权重初始化整个网络然后训练。可以用下载的权重初始化,因为这些权重可以代替随机初始化,然后做梯度下降,训练更新所有的权重和网络层

常见的迁移训练的方式:
1、载入权重后训练所有参数
2、载入权重后只训练最后几层参数
3、载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层