HDFS磁盘写满问题分析
- 1. 问题说明
- 1.1 namenode常规分配datanode策略
- 1.2 DFS Used很大时是否能够继续写入数据
- 2 问题修复
- 2.1 集群均衡操作
- 2.2 配置系统预留参数
- 3. 疑问和思考
- 3.1. 是否需要配置`dfs.datanode.du.reserved`?
- 4. 参考文档
探讨hdfs的datanode节点磁盘被写满的原因分析和相关规避方案。关于常见分布式组件高可用设计原理的理解和思考
1. 问题说明
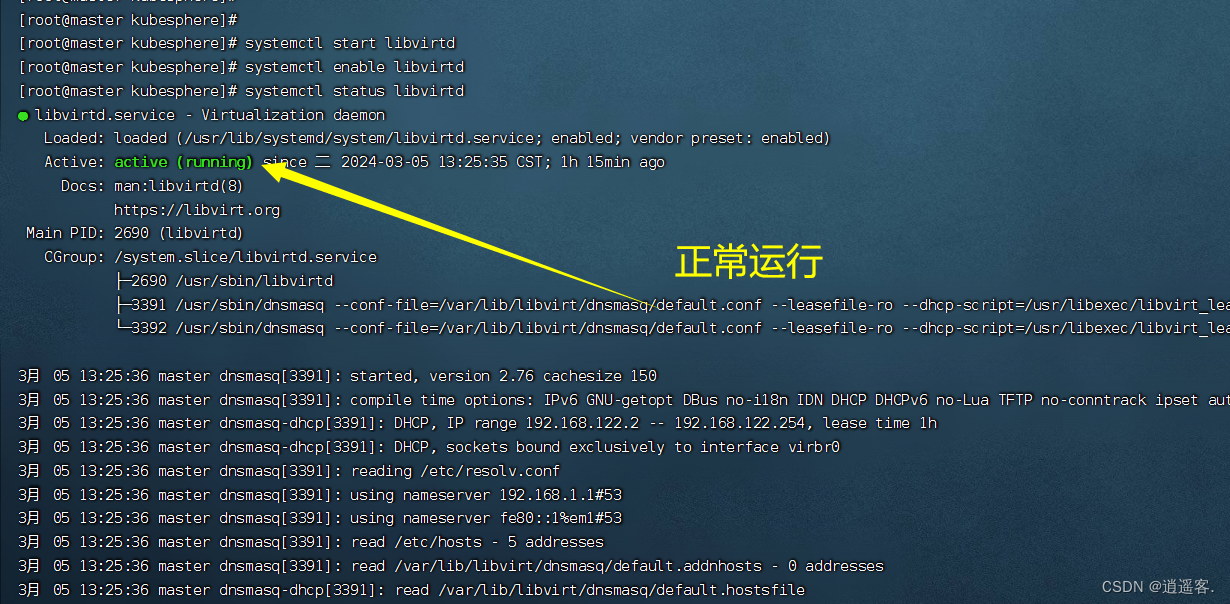
在生产上遇到了这样的一个问题,通过hdfs dfsadmin -report命令可以获取hdfs集群的磁盘使用情况统计信息。
Rack: /idc1
Decommission Status : Normal
Configured Capacity: 35722170777600 (32.49 TB)
DFS Used: 33921395016733 (30.85 TB)
Non DFS Used: 1800771816419 (1.64 TB)
DFS Remaining: 3944448 (3.76 MB)
DFS Used%: 94.96%
DFS Remaining%: 0.00%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 7
Last contact: Sat Mar 16 22:52:41 CST 2024
这里的几个关键信息
- Configured Capacity: 35722170777600 (32.49 TB),代表当前节点能够使用的最大磁盘容量,由当前节点所有磁盘加合获取
- DFS Used%: 94.96%,代表当前节点,在hdfs系统中的磁盘使用率,namenode会根据该参数判断该节点是否还能继续写入。由于使用率已经很高,namenode在分析新的数据写入时,通常不会继续给这个节点分配数据(不是绝对)
- Non DFS Used: 1800771816419 (1.64 TB),指的是DataNode上除了HDFS数据存储之外的其他用途所占用的空间。这可能包括操作系统、日志、临时文件、Hadoop数据缓存等。Non DFS Used很大通常是由于这些因素导致的,可能是由于数据缓存、日志文件或其他临时文件占用了大量空间。
- DFS Remaining: 3944448 (3.76 MB),指HDFS中尚未使用的剩余存储空间
其中 Configured Capacity = DFS Used + Non DFS Used + DFS Remaining
同时 Configured Capacity = (单个磁盘总量 - dfs.datanode.du.reserved) * 磁盘数量
DFS Used = DFS Used / Configured Capacity
再来看对应节点的磁盘使用情况

实际上磁盘已经写满,不能继续写入数据。
1.1 namenode常规分配datanode策略
在HDFS中,写入数据时排除不合适的DataNode通常是通过网络拓扑、数据节点状态和负载等信息来实现的。HDFS会根据这些信息选择最佳的DataNode来存储数据。具体细节需要参考HDFS源码中涉及块放置的部分,这里简要概述一下:
- 网络拓扑感知:HDFS会考虑数据节点和客户端的网络拓扑位置,尽可能选择靠近客户端的数据节点,以减少网络传输延迟。
- 数据节点状态:HDFS会检查数据节点的状态,比如存储容量、负载情况等,避免选择负载过重或不稳定的数据节点。
- 块复制因子:HDFS默认会将数据块复制到多个数据节点以实现容错性。在选择数据节点时,会考虑确保块的复制因子得到满足。
- 源码实现:具体逻辑涉及HDFS源码中的块放置相关部分,例如在
org.apache.hadoop.hdfs.server.blockmanagement包中的类。源码涉及块的选择逻辑,包括如何评估数据节点的可用性、负载和网络位置等。详细的源码实现需要在HDFS源代码中查找相关部分。
总的来说,HDFS使用一系列策略来选择最佳的数据节点进行数据写入,以优化性能和可靠性。
1.2 DFS Used很大时是否能够继续写入数据
在hdfs管理磁盘容量中, Non DFS Used占用了很大比例,从而导致DFS Used能够使用的磁盘很小,统计出来的实际 DFS Used使用率只有94.96%
- 即使DFS Used% 达到94.96%,NameNode仍然会写入数据,因为HDFS的设计并不会在存储接近满时停止写入操作。相反,NameNode会触发一系列措施来管理数据块的复制和移动,以确保系统的正常运行。
- 当DFS Used% 达到 100% 时,NameNode 将不再写入数据。当存储空间达到饱和时,HDFS 将拒绝新的写入请求,以保护数据的完整性。
通常情况下,不会分配数据到该datanode,但是如果集群压力大时,还是会将相关的数据写入到对应的datanode节点,但是datanode的实际的磁盘使用率已经满了,因此对应的数据写入就会失败。
这就是为什么客户端写入数据失败的原因。
2 问题修复
知道了客户端数据写入失败的原因,就能够知道相关的修复方案。根据hdfs dfsadmin -report获取的集群的datanode磁盘使用率情况,能够知道,hdfs集群不同节点的磁盘使用率差异很大,这是由于集群中不同的datanode的磁盘配置不一致导致的。因此修复的策略分 2个步骤
- 触发集群数据均衡,将磁盘使用率高的节点数据迁移到其他节点
- 配置系统预留参数,避免磁盘被写满
2.1 集群均衡操作
可以使用均衡器 hdfs balancer,阈值默认是10%
threshold参数表示每个DataNode的HDFS使用率于集群的平均DFS利用率的偏差百分比。以任意一方式(更高或更低)超过该阈值将意味着该节点会被重新均衡。如下面的案例所示,可以运行不带任何参数的balancer命令,则此均衡器明朗了使用10%的默认阈值,这意味着均衡器通过将块从过度使用的节点移动到未充分使用的节点来均衡数据,直到每个Datanode的磁盘使用率不超过集群中平均磁盘使用率的正负10%。
有时,可能希望将阈值设置为不同的级别,例如,当集群中的可用空间变小,并且你希望将单个DataNode上使用的存储量保持在比默认的10%阈值更小的范围内时,可以这样指定阈值"hdfs balancer -threshold 5"
当运行均衡器时,它会查看集群中的两个关键HDFS使用情况值:
- 平均DFS使用百分比: 可以通过计算得到集群中使用的平均DFS百分比:“Average DFS Used = (DFS Used * 100) / Present Capacity”
- 节点使用的DFS百分比: 此度量显示每个节点使用的DFS百分比。
nohup hdfs balancer -threshold 20 &> /data/balancer.log &
该命令需要执行均衡数据,通常需要执行很长时间,建议放到后台运行
Configured Capacity: 940550251233280 (855.43 TB)
Present Capacity: 893139195925042 (812.31 TB)
DFS Remaining: 424862122598400 (386.41 TB)
DFS Used: 468277073326642 (425.90 TB)
DFS Used%: 52.43%
Under replicated blocks: 122636
Blocks with corrupt replicas: 109
Missing blocks: 0
- 如果一个datanode节点的
DFS Used% > 集群的DFS Used% + threshold,就会触发均衡,将数据迁移到其他的节点 - 最终会均衡到
DFS Used% <= 集群的DFS Used% + threshold
说明
- 默认的DataNode策略是在DataNode级别均衡存储,但均衡器不会在DataNode的各个存储卷之间均衡数据。
- 仅当DataNode使用的DFS百分比和(由集群使用的)平均DFS之间的差大于(或小于)规定阈值时,均衡器才会均衡DataNode。否则,它不会重新均衡集群。
- 均衡器运行多长时间取决于集群的大小和数据的不平衡程度。第一次运行均衡器,或者不经常调度均衡器,以及在添加一组DataNode之后运行均衡器,它将运行很长时间(通常是几天,如果数据量达到PB或者接近EB级别,可能需要一个多月的时间来均衡哟~)
- 如果有一个数据写入和删除频繁的集群,集群可能永远不会达到完全均衡的状态,均衡器仅仅将数据从一个节点移动到另一个节点。
- 向集群添加新节点后最好立即运行均衡器。如果一次添加大量节点,则运行均衡器需要一段时间才能完成其工作。
- 如果确定阈值?这很容易,秩序选择整个集群中节点最低DFS使用百分比即可。不必花费大量的时间了解每个节点使用的DFS百分比,使用
hdfs dfsadmin -report命令即可找出正确的阈值。阈值越小,均衡器需要执行的工作越多,集群就越均衡。
配套的优化配置,如下配置不能热加载,需要重启相关的datanode进程才能生效
# 移动的线程数,默认值是1
<property>
<name>dfs.datanode.balance.moverThreads</name>
<value>4096</value>
</property>
# 移动的网络带宽限制,默认是10 MBytes/s,当前配置是100 MBytes/s
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>104857600</value>
</property>
# 指定数据节点之间进行数据平衡操作时允许的最大并发移动任务数, 默认值是5
<property>
<name>dfs.datanode.balance.max.concurrent.moves</name>
<value>50</value>
</property>
更多配置说明可以参考 HDFS高可用架构涉及常用功能整理
2.2 配置系统预留参数
通过调整对应的datanode节点的参数dfs.datanode.du.reserved,该参数是针对单个节点的每个磁盘都预留相关数据。
-
增加如下参数
vim /usr/local/services/hadoop-*/etc/hadoop/hdfs-site.xml 按照格式增加如下参数,每个磁盘预留1t空间 <property> <name>dfs.datanode.du.reserved</name> <value>1073741824000</value> </property> -
重启datanode
当datanode重启后,通过hdfs dfsadmin -report可以看到对应节点的Configured Capacity变小了,因此能够写入的总的数据量变小(能够写入的理论上限是Configured Capacity),从而能够避免磁盘打满。

3. 疑问和思考
3.1. 是否需要配置dfs.datanode.du.reserved?
有。
因为HDFS的设计并不会在存储接近满时停止写入操作,并且因为Non DFS Used存在,可能会导致DFS Used 比真实的磁盘使用率小,从而导致DFS Used 还没有100%,但是磁盘使用率100%,数据写入失败。
通常需要,设置dfs.datanode.du.reserved,至少预留200g(根据实际情况而定),并监控磁盘的使用率,及时清理数据或者进行数据均衡。
4. 参考文档
- HDFS高可用架构涉及常用功能整理