运动想象迁移学习系列:数据对齐(EA)
- 0. 引言
- 1. 迁移学习算法流程
- 2. 欧式对齐算法流程
- 3. 与RA算法进行对比
- 4. 实验结果对比
- 5. 总结
- 欢迎来稿
论文地址:https://ieeexplore.ieee.org/abstract/document/8701679
论文题目:Transfer Learning for Brain–Computer Interfaces: A Euclidean Space Data Alignment Approach
论文代码:https://github.com/hehe03/EA/blob/master/main_MI.m
0. 引言
本篇博客重点考虑数据对齐部分,因为其对后续迁移学习的效果影响非常大。
数据对齐有多种方法,如黎曼对齐(Riemannian Alignment, RA)、欧式对齐(Euclidean Alignment, EA)、标签对齐(Label Alignment, LA)、重心对齐(Centroid Alignment, CA) 等。下面重点介绍EA。
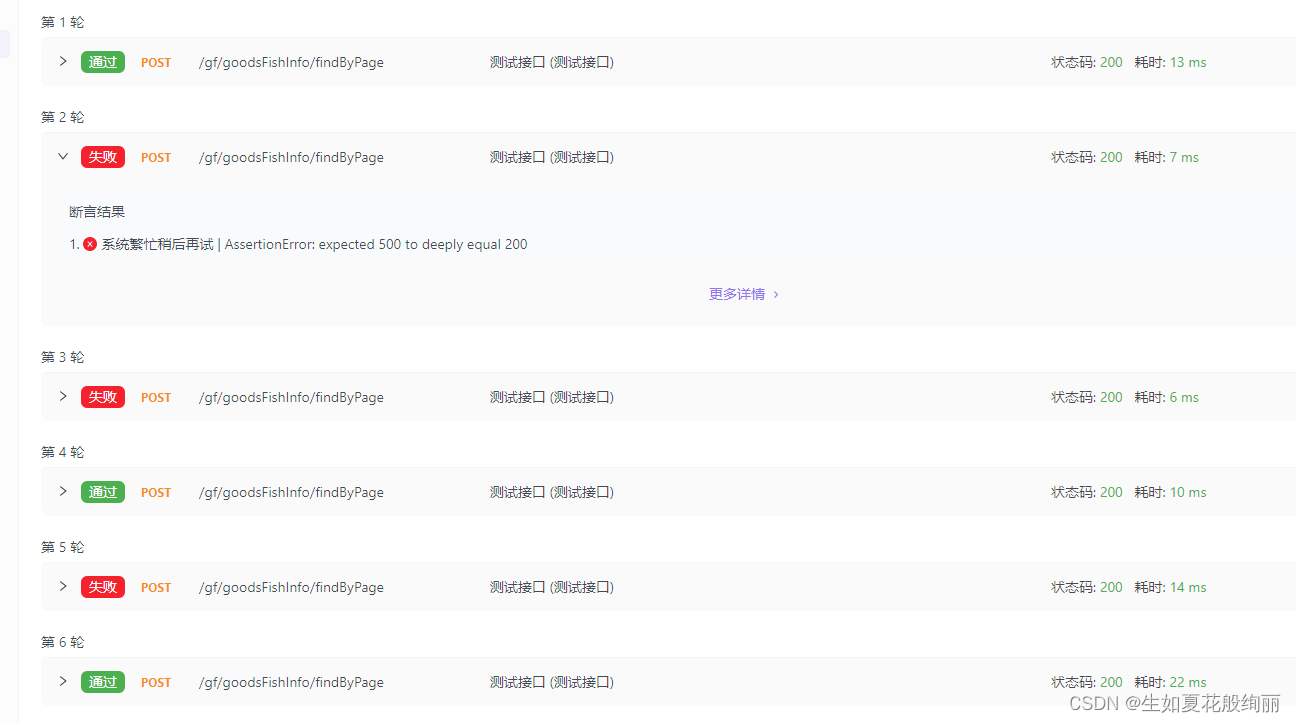
1. 迁移学习算法流程
迁移学习算法流程如图11所示。可以看到数据对齐的位置所在!!!

2. 欧式对齐算法流程
欧式对齐算法流程如图12所示。其处理源域用户和目标域用户的方式是一样的,所以下面描述中不区分源域用户和目标域用户。假定一个用户有n段EEG样本。EA先计算每段EEG样本的协方差矩阵,再计算这n个协方差矩阵的均值,记为
R
‾
\overline{R}
R。对齐矩阵即为
R
‾
−
1
/
2
\overline{R}^{-1/2}
R−1/2。对每段EEG样本,左乘
R
‾
−
1
/
2
\overline{R}^{-1/2}
R−1/2,得到一个跟原始EEG样本维度相同的样本,用于取代进行所有后续计算,如空域滤波、特征提取、分类等。EA简单有效,主要原因是对齐之后任意用户的EEG样本协方差矩阵的均值都为单位矩阵,整体分布更加一致。这有点类似迁移学习中经常考虑的最大均值差异(Maximum Mean Discrepancy, MMD)度量。

3. 与RA算法进行对比
RA与EA对比如图13所示。EA计算更快,无需任何标签信息,并且之后可以搭配任意欧式空间滤波器、特征提取、分类器等,使用更加灵活。实验证明,EA的效果提升也比RA更加明显。

4. 实验结果对比
我们在两个运动想象数据集(MI1、MI2)和一个事件相关电位数据集(ERP)上验证了EA的效果。MI2上的t-SNE可视化如图14所示。第一行中蓝色的点代表来自8个源域用户的数据分布,红色的点是目标域用户(用户1)的数据分布。显然,EA对齐之前,源域和目标域数据分布差异很大。EA对齐之后,二者分布非常一致,有利于之后的迁移学习。第二行是用户2作为目标域时的结果,跟第一行结果类似。

5. 总结
到此,使用 数据对齐(EA) 已经介绍完毕了!!! 如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。
如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
欢迎来稿
欢迎投稿合作,投稿请遵循科学严谨、内容清晰明了的原则!!!! 有意者可以后台私信!!