在GPT-1之前,传统的 NLP 模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点:预训练语言模型之GPT
- 需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,标签并不是唯一的或者实例标签并不存在明确的边界;
- 根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了 NLP。
1 GPT-1
生成式预训练 Transfomer 模型(Generative Pre-Trained Transformer,GPT),将无监督学习应用到有监督模型的预训练目标。参考GPT的前世今生
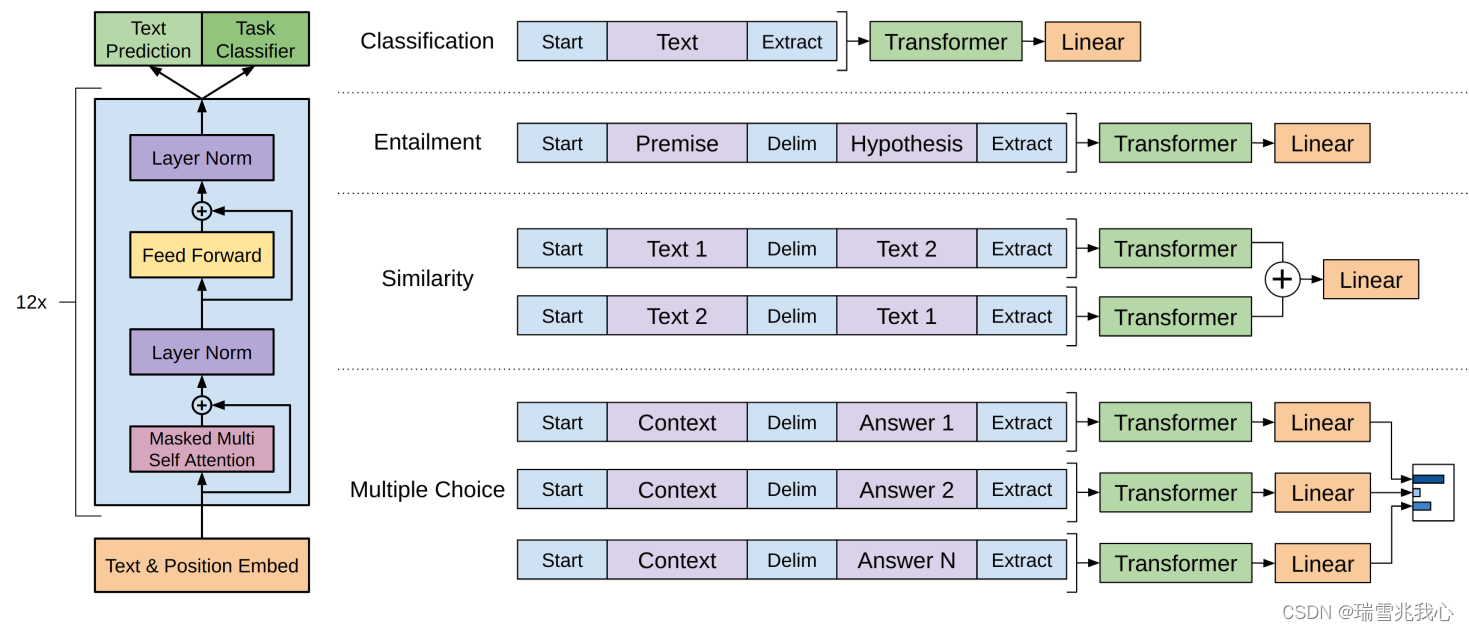
GPT-1 语言模型结构上对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention。
GPT-1 语言模型通过大量的无监督预训练(Unsupervised Pre-Training)(无监督是指不需要人工介入,不需要标注数据集的预训练),再通过少量有监督微调(Supervised Fine-Tuning)来修正其理解能力。监督训练和无监督训练是什么参考2.1部分
- 在预训练阶段,GPT-1 使用无标注文本数据集(数据量约 5 GB 大小,模型自身参数 1.17 亿,Transfomer Layer 堆叠 12 层),通过最大化预训练数据集上的似然函数 log-likelihood 来训练模型参数。
- 在微调阶段,GPT-1 将预训练模型的参数用于特定的自然语言处理任务。
2 GPT-2
GPT-2 的目标旨在训练一个泛化能力更强的词向量模型,它并没有对 GPT-1 的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集。GPT语言模型详细介绍
GPT-2 模型主推零样本学习(Zero Shot Learning),使用了更多的数据(数据集增加 40 GB大小,模型自身参数高达15亿,Transfomer Layer 堆叠 48 层)进行预训练 Pre_Training,将有监督 Fine-Tuning 微调阶段变成了一个无监督的模型,同时增加了预训练多任务 MultiTask 模式(即主张不通过专门的标注数据集训练专用的AI,而是喂取了海量数据后,任意任务都可以完成)。
3 GPT-3
从理论上讲 GPT-3 也是支持 Fine-Tuning 的,但是 Fine-Tuning 需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以 GPT-3 并没有尝试 Fine-Tuning。
零样本学习(Zero-Shot Learning)是一种能够在没有任何样本的情况下学习新类别的方法。通常情况下,模型只能识别它在训练集中见过的类别。但通过零样本学习,模型能够利用一些辅助信息来进行推理,并推广到从未见过的类别上。这些辅助信息可以是关于类别的语义描述、属性或其他先验知识。 Zero-Shot, One-Shot 和 Few-Shot Learning概念介绍
一次样本学习(One-Shot Learning)是一种只需要一个样本就能学习新类别的方法。这种方法试图通过学习样本之间的相似性来进行分类。例如,当我们只有一张狮子的照片时,一次样本学习可以帮助我们将新的狮子图像正确分类。
少样本学习(Few-Shot Learning)是介于零样本学习和一次样本学习之间的方法。它允许模型在有限数量的示例下学习新的类别。相比于零样本学习,少样本学习提供了更多的训练数据,但仍然相对较少。这使得模型能够从少量示例中学习新的类别,并在面对新的输入时进行准确分类。
元学习(Meta Learning)的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果(对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解)。
GPT-3 模型使用更多的高质量的数据(数据集增加 45 TB大小,模型自身参数高达 1750 亿,Transformer Layer 也从48层提升到 96 层),使用 MAML(Model Agnostic Meta Learning)算法学习一组 Meta-Initialization,能够快速应用到其它任务中。
4 ChatGPT
ChatGPT 基于 GPT-3.5 架构的有监督精调 (Supervised Fine-Tuning, SFT),训练一个奖励模型(Reward Model,RM),使用来自人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)进行优化训练,通过近端策略优化(Proximal Policy Optimization)算法进行微调。参考ChatGPT原理详解
该方法包括以下三个步骤: 一文读懂ChatGPT中的强化学习
- 第一步:带监督的微调,预训练语言模型对由标注人员管理的相对较少的演示数据进行微调,以学习监督策略(SFT模型),根据选定的提示列表生成输出,这表示基线模型;
- 第二步:“模仿人类偏好” ,要求标注人员对相对较多的 SFT 模型输出进行投票,创建一个由对比数据组成的新数据集。在该数据集上训练一个新的奖励模型(RM);
- 第三步:近端策略优化(PPO),对奖励模型进一步微调以改进 SFT 模型。这一步的结果就是所谓的策略模型。
- 步骤 1 只进行一次,而步骤 2 和步骤 3 可以连续迭代,在当前的最佳策略模型上收集更多的比较数据,训练出一个新的奖励模型,然后在此基础上再训练出一个新的策略。