目录
一、项目背景
二、代码
三、总结
一、项目背景
(1)利用requests库采集豆瓣网分类排行榜 (“https://movie.douban.com/chart”)中各分类类别前100部电影的相关信息并存储为csv文件。

(2)利用获取的13个分类类别共1300部电影数据,获取电影所有上映国家并保存至csv文件。要求:其中index属性为国家或地区,columns属性为该国家发行电影的电影类型,值标识了各国家发行不同类型电影的数量信息。在表格的行尾和列尾分别加上属性“总计”,值为对应行、列的值加和;然后分别根据表格的index和columns“总计”进行从小到大排序。
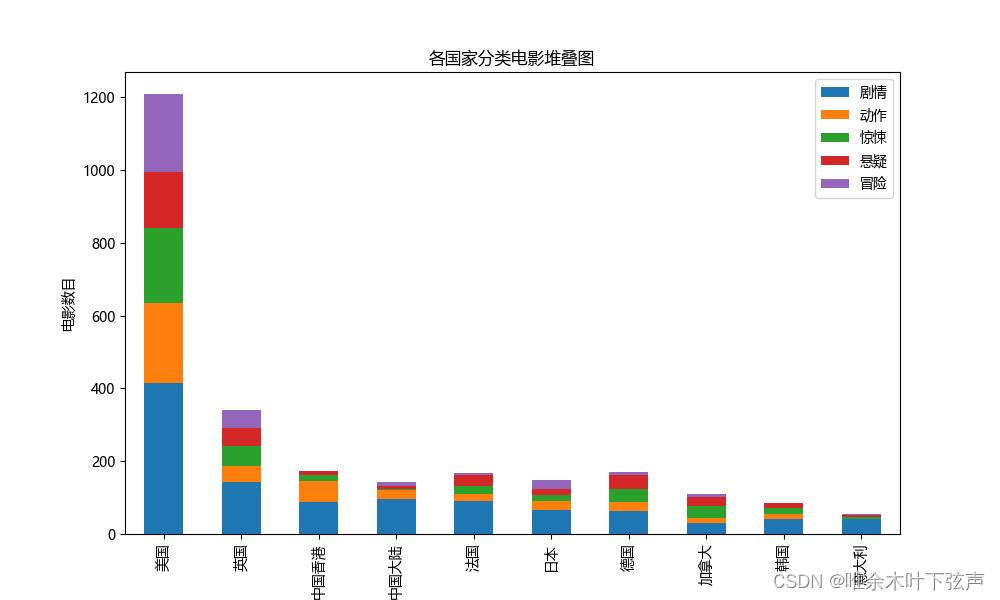
(3)基于上述排序后的数据,选取发行电影数量最多的10个国家,选取电影类型最多的5个类型,使用matplotlib方法制作柱状堆叠图。其中横轴显示的国家,纵轴显示的电影数量,图例是各电影类别。
(4)分别获取13个分类类别对应的电影数量前7个国家,其他的用“其他”代替,计算每个分类类别对应的7个国家及“其他”部分的占比。使用matplotlib.pyplot.pie方法直观的显示这13个分类类别对应的国家发行电影数量占比,使用subplot方法进行多子图展示。
(5)计算获得所有电影的相似度(用欧式距离来定义),其中,DataFrame对象的index和columns均为所有的电影名称,值为两个电影的相似度。向每部电影推荐相似都最高的前5部电影。利用循环结构,循环提取每一部电影与其他所有电影的相似度数据,并进行排序,选择相似度最大(距离最近)的5部电影,同时将这5部电影的相似度记录下来。
二、代码
1、导入所需的Python包
#导包
import pandas as pd
import requests as rq
from bs4 import BeautifulSoup
import re
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore", category=pd.errors.PerformanceWarning)
warnings.filterwarnings("ignore", category=pd.errors.SettingWithCopyWarning)
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体:解决plot不能显示中文问题
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题各模块功能如下:
pandas:用于数据处理和存储。
requests:用于发送HTTP请求。
BeautifulSoup:用于解析HTML内容。
re:用于正则表达式操作。
numpy:用于数值计算。
matplotlib.pyplot:用于绘图。
warnings:用于过滤警告信息。
pylab:用于设置图形显示的默认配置。
2、爬取豆瓣电影信息
通过requests读取包含电影信息的json,并将其转换为DataFrame。
#电影分类
movie_types = ['剧情','喜剧','动作','爱情','科幻','悬疑','惊悚','恐怖','历史','战争','犯罪','奇幻','冒险']
#设置requests headers,应对反爬机制
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'}
def get_douban_movies():
'''
项目内容:
利用 requests 库采集豆瓣网分类排行榜(“https://movie.douban.com/chart”)
中各分类类别前 100 部电影的相关信息
'''
#豆瓣电影主页
homepage = 'https://movie.douban.com/chart'
#爬取主页
web = rq.get(homepage,headers=headers)
#设置中文编码
web.encoding = 'utf-8'
#解析HTML
soup = BeautifulSoup(web.text,'lxml')
#获取分类列表
urls = [span.a['href'] for span in soup.select('div.types span')]
require_urls = ['https://movie.douban.com'+u for movie_type in movie_types for u in urls if movie_type in u]
#获取每个分类的数字编号
numbers = [re.search(r'type=(\d+)', url).group(1) for url in require_urls]
#数据存储到data列表
data = []
#遍历爬取13个分类
counts = 0
for number in numbers:
url = 'https://movie.douban.com/j/chart/top_list?type={}&interval_id=100%3A90&action=&start=0&limit=100'.format(number)
response = rq.get(url,headers=headers)
#获取JSON数据
data_json = response.json()
#遍历100个电影
for i in data_json:
data.append([i['title'],i['release_date'],i['regions'],
i['types'],i['url'],i['actors'],
i['actor_count'],i['score'],
i['vote_count'],i['types']])
counts += 1
print("成功爬取第{}个电影分类".format(counts))
#将列表data转换为表格,配置列名
df = pd.DataFrame(data,columns=['title','release_date','regions','types','film_url','actors','actor_count','score','vote_count','fenlei'])
return df3、统计各国家地区发行电影数量
def get_df_counties(df):
#打散国家地区
df = df.explode('regions')
#创建空表格,后面再填充数据
df_counties = pd.DataFrame()
#遍历每一个电影分类
for t in movie_types:
df_counties[t] = df['types'].apply(lambda x:1 if t in x else 0)
df_counties['regions'] = df['regions']
#汇总
df_counties = df_counties.groupby('regions').sum()
df_counties['总计'] = df_counties.sum(axis=1)
#计算行方向的统计
count_list = []
for t in movie_types+['总计']:
count_list.append(df_counties[t].sum())
df_counties.loc['总计'] = count_list
print('统计完成')
return df_counties4、绘制各国家地区分类电影堆叠图
def draw_bar_diagram(select_data):
# 创建堆叠柱状图
ax = select_data.plot.bar(stacked=True, figsize=(10, 6))
# 添加标题和标签
plt.title('各国家地区分类电影堆叠图')
plt.xlabel('国家地区')
plt.ylabel('电影数目')
# 显示图形
plt.savefig('各国家地区分类电影堆叠图.jpg')
plt.show()绘制图像如下:
5、绘制各国家地区发行电影数量占比图
def draw_pie_diagram(df_counties):
df_counties = df_counties.drop('总计')
#处理数据
df_list = []
for t in movie_types:
df_sub = df_counties[t].nlargest(7)
df_sub.loc['其他'] = df_counties.drop(df_sub.index)[t].sum()
df_list.append(df_sub)
# 设置子图布局
fig, axes = plt.subplots(nrows=4, ncols=4, figsize=(10, 10))
# 遍历每个电影类型的DataFrame
for i, df in enumerate(df_list):
# 将索引转换为整数类型
#df.index = range(len(df))
# 计算电影数量占比
proportions = df / df.sum()
# 绘制饼图
ax = axes[i // 4, i % 4]
ax.pie(proportions, labels=df.index, autopct='%1.1f%%', startangle=90)
ax.set_title(df.name,fontdict={'fontsize': 20, 'color': 'black'}) # 使用电影类型作为子图标题
#调整间距
plt.subplots_adjust(wspace=0.5, hspace=2)
#隐藏空白子图
for i in range(len(df_list), 16):
axes.flatten()[i].axis('off')
plt.tight_layout()
plt.savefig('各国家地区发行电影数量占比.jpg')
# 显示图形
plt.show()绘制图像如下:
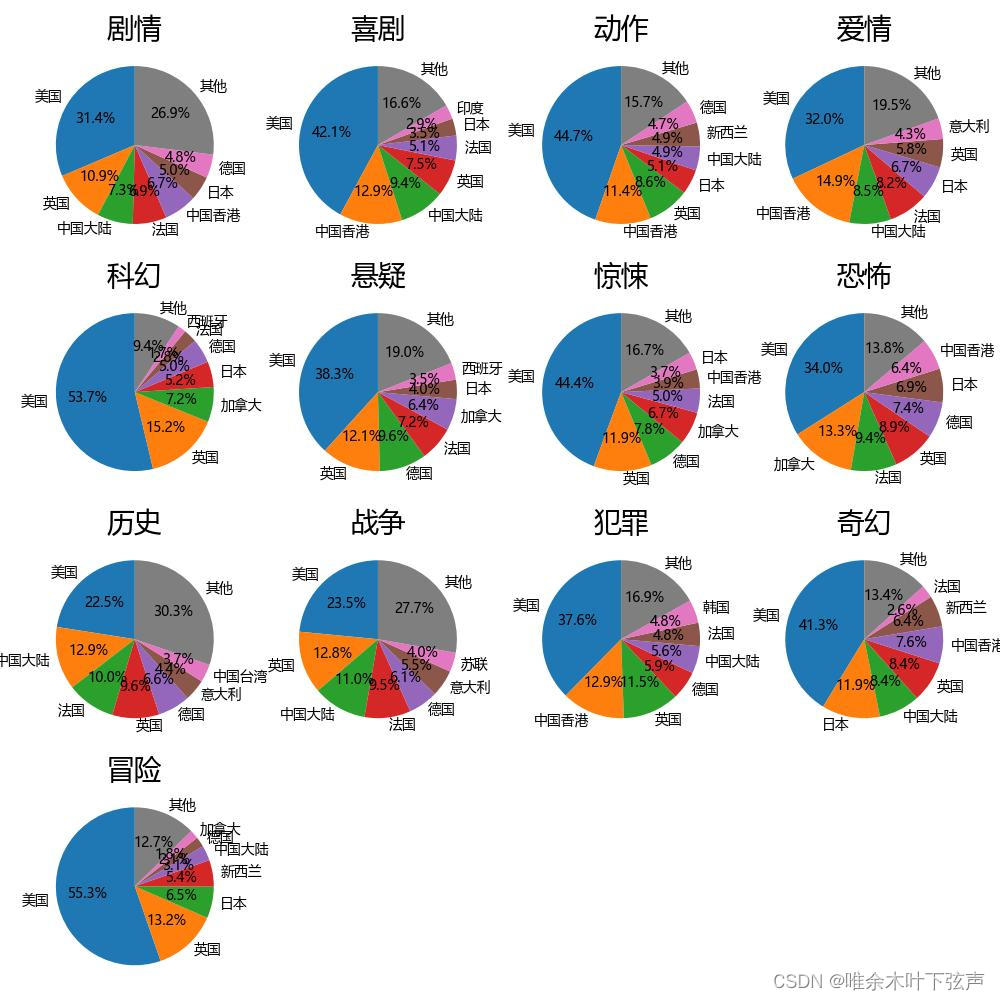
6、基于近邻规则生成推荐电影信息
def get_data_tuijian(df):
df = df.drop_duplicates(subset='title', keep='first')
#归一化
df['score'] = (df['score'] - df['score'].min()) / (df['score'].max() - df['score'].min())
df['vote_count'] = (df['vote_count'] - df['vote_count'].min()) / (df['vote_count'].max() - df['vote_count'].min())
data = df[['title','score', 'vote_count']]
#遍历每部电影,计算与其他电影的相似度
for t in data.title.unique():
col = data[data.title==t].iloc[0]
sim_values = []
for _ ,row in data.iterrows():
sim_values.append(np.sqrt((row['score']-col['score'])**2+(row['vote_count']-col['vote_count'])**2))
data[t] = sim_values
#data[t] = (data[t] - data[t].min()) / (data[t].max() - data[t].min())
#设置索引
data.index=data.title
data = data.drop(columns=['title', 'score', 'vote_count'])
data_tuijian = pd.DataFrame()
data_tuijian['电影名称'] = data.index
data_tuijian[['推荐电影1', '推荐电影2', '推荐电影3', '推荐电影4', '推荐电影5',
'与电影1相似度', '与电影2相似度', '与电影3相似度', '与电影4相似度', '与电影5相似度']
] = None
#遍历每一部电影,提取每一部电影的前5最相似电影
for c in data.columns:
top5 = data[c].sort_values().iloc[1:6].reset_index().values
for i in range(5):
data_tuijian.loc[data_tuijian['电影名称']==c,'推荐电影'+str(i+1)] = top5[i][0]
data_tuijian.loc[data_tuijian['电影名称']==c,'与电影{}相似度'.format(i+1)] = top5[i][1]
print('推荐信息获取完成')
return data_tuijian7、主程序
if __name__ == '__main__':
print('===========项目1、豆瓣电影信息爬取与存储==========')
df = get_douban_movies()
df.to_csv('film_info.csv',index=False,encoding='utf-8-sig')
print('===========项目2、国家地区发行各类别电影的可视化分析==========')
df_counties = get_df_counties(df)
df_counties.to_csv('df_counties.csv',encoding='utf-8-sig')
#绘制图表
select_data = df_counties.sort_values(by='总计',ascending=False).iloc[:11]
columns = select_data.iloc[0].sort_values(ascending=False).iloc[1:6].index.to_list()
select_data = select_data[columns].iloc[1:]
draw_bar_diagram(select_data)
draw_pie_diagram(df_counties)
print('===========项目3、基于近邻的电影推荐研究==========')
df = pd.read_csv('film_info.csv')
data_tuijian = get_data_tuijian(df)
data_tuijian.to_csv('data_tuijian.csv',index=False,encoding='utf-8-sig')三、总结
本项目主要考察的是对requests爬虫、pandas数据处理、matplotlib绘图等Python模块的使用,难度不大。