程序员之间交流时,会经常使用非程序员无法理解的行话,或者使用令操不同编程语言的程序员理解起来比较模糊的行话。
但是,那些操相同编程语言的程序员理解起来不会产生什么问题。
这有时也取决于程序员所掌握知识的渊博程度。
一个新手或许不理解有经验的程序员说的是什么意思,而与此同时,久经沙场的同事会点头赞同并做出回应。
本文向大家介绍一些Java编程行话,即Java惯用语,用以描述某些特性、功能、设计解决方案等。
我们还将学习设计和编写应用程序代码中最流行和最有用的实践。
读完本文,大家会彻底弄明白:其他Java程序员在讨论设计决策和所使用的功能时,讨论的内容到底是什么意思。
本文涉及以下主题:
- Java行业惯用语、实现及用法
- 最佳设计实践
- 代码为人而写
- 测试——通向高质量代码的捷径
01、Java行业惯用语、实现及用法
除了作为专业人员之间交流手段外,编程惯用语也是久经考验的编程解决方案和常见实践。
这些都不是直接产生于语言规范,而是来自编程经验。我们将讨论最常用的惯用语。
至于惯用语的完整列表,可以在Java官方文档中查找和学习。
1●equals()方法和hashCode()方法
java.lang.Object类中,equals()方法和hashCode()方法的默认实现,如下所示。
public boolean equals(Object obj) {
return (this == obj);
}
/**
* Whenever it is invoked on the same object more than once during
* an execution of a Java application, the hashCode method
* must consistently return the same integer...
* As far as is reasonably practical, the hashCode method defined
* by class Object returns distinct integers for distinct objects.
*/
@HotSpotIntrinsicCandidate
public native int hashCode();可以看到,equals()方法的默认实现仅比较指向对象存储地址的内存引用。
类似地,从注释(引自源代码)中可以看出,hashCode()方法为相同的对象返回相同的整数,为不同的对象返回不同的整数。
下面用Person类来演示,具体如下。
public class Person {
private int age;
private String firstName, lastName;
public Person(int age, String firstName, String lastName) {
this.age = age;
this.lastName = lastName;
this.firstName = firstName;
}
public int getAge() { return age; }
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
}对于equals()方法和hashCode()方法的默认行为,举例如下:
Person person1 = new Person(42, "Nick", "Samoylov");
Person person2 = person1;
Person person3 = new Person(42, "Nick", "Samoylov");
System.out.println(person1.equals(person2)); //prints: true
System.out.println(person1.equals(person3)); //prints: false
System.out.println(person1.hashCode()); //prints: 777874839
System.out.println(person2.hashCode()); //prints: 777874839
System.out.println(person3.hashCode()); //prints: 596512129person1引用和person2引用及其散列码都是相等的,因为这两个引用指向相同的对象(相同的内存区域,以及相同的地址),而person3引用指向另一个对象。
在实践中,经常希望对象相等是基于对象的全部或部分属性值。
下面是equals()和hashCode()方法的一个典型实现。
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null) return false;
if(!(o instanceof Person)) return false;
Person person = (Person)o;
return getAge() == person.getAge() &&
Objects.equals(getFirstName(), person.getFirstName()) &&
Objects.equals(getLastName(), person.getLastName());
}
@Override
public int hashCode() {
return Objects.hash(getAge(), getFirstName(), getLastName());
}这样的实现在以前是比较复杂的,现在使用java.util.Objects实用程序令这样的实现简单多了。
特别值得注意的是,Objects.equals()方法还能处理null值。
将上述equals()和hashCode()方法的实现添加到Person1类中,执行同样的比较操作。
具体如下:
Person1 person1 = new Person1(42, "Nick", "Samoylov");
Person1 person2 = person1;
Person1 person3 = new Person1(42, "Nick", "Samoylov");
System.out.println(person1.equals(person2)); //prints: true
System.out.println(person1.equals(person3)); //prints: true
System.out.println(person1.hashCode()); //prints: 2115012528
System.out.println(person2.hashCode()); //prints: 2115012528
System.out.println(person3.hashCode()); //prints: 2115012528
可见,所做的更改不仅使相同的对象相等,而且使两个具有相同属性值的不同对象相等。
此外,散列码值现在也基于了相同属性的值。
在这些方法上使用@Override注解,可以确保这些方法确实覆盖了Object类中的默认实现。
否则,方法名中的一个拼写错误可能会造成这样的错觉:使用了新的实现,但实际上并没有使用。
事实证明,对这种情况的调试要比添加@Override注解困难得多,而且代价也要高得多。
如果方法没有覆盖任何内容,就会产生错误。
2●compareTo()方法
基于此方法所建立的顺序(通过集合的元素实现的)被称为自然顺序(natural order)。
下面创建了Person2类来演示该方法。具体如下:
public class Person2 implements Comparable<Person2> {
private int age;
private String firstName, lastName;
public Person2(int age, String firstName, String lastName) {
this.age = age;
this.lastName = lastName;
this.firstName = firstName;
}
public int getAge() { return age; }
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
@Override
public int compareTo(Person2 p) {
int result = Objects.compare(getFirstName(),
p.getFirstName(), Comparator.naturalOrder());
if (result != 0) {
return result;
}
result = Objects.compare(getLastName(),
p.getLastName(), Comparator.naturalOrder());
if (result != 0) {
return result;
}
return Objects.compare(age, p.getAge(),
Comparator.naturalOrder());
}
@Override
public String toString() {
return firstName + " " + lastName + ", " + age;
}
}
然后创建一个Person2对象的列表并进行排序:
Person2 p1 = new Person2(15, "Zoe", "Adams");
Person2 p2 = new Person2(25, "Nick", "Brook");
Person2 p3 = new Person2(42, "Nick", "Samoylov");
Person2 p4 = new Person2(50, "Ada", "Valentino");
Person2 p6 = new Person2(50, "Bob", "Avalon");
Person2 p5 = new Person2(10, "Zoe", "Adams");
List<Person2> list = new ArrayList<>(List.of(p5, p2, p6, p1, p4, p3));
Collections.sort(list);
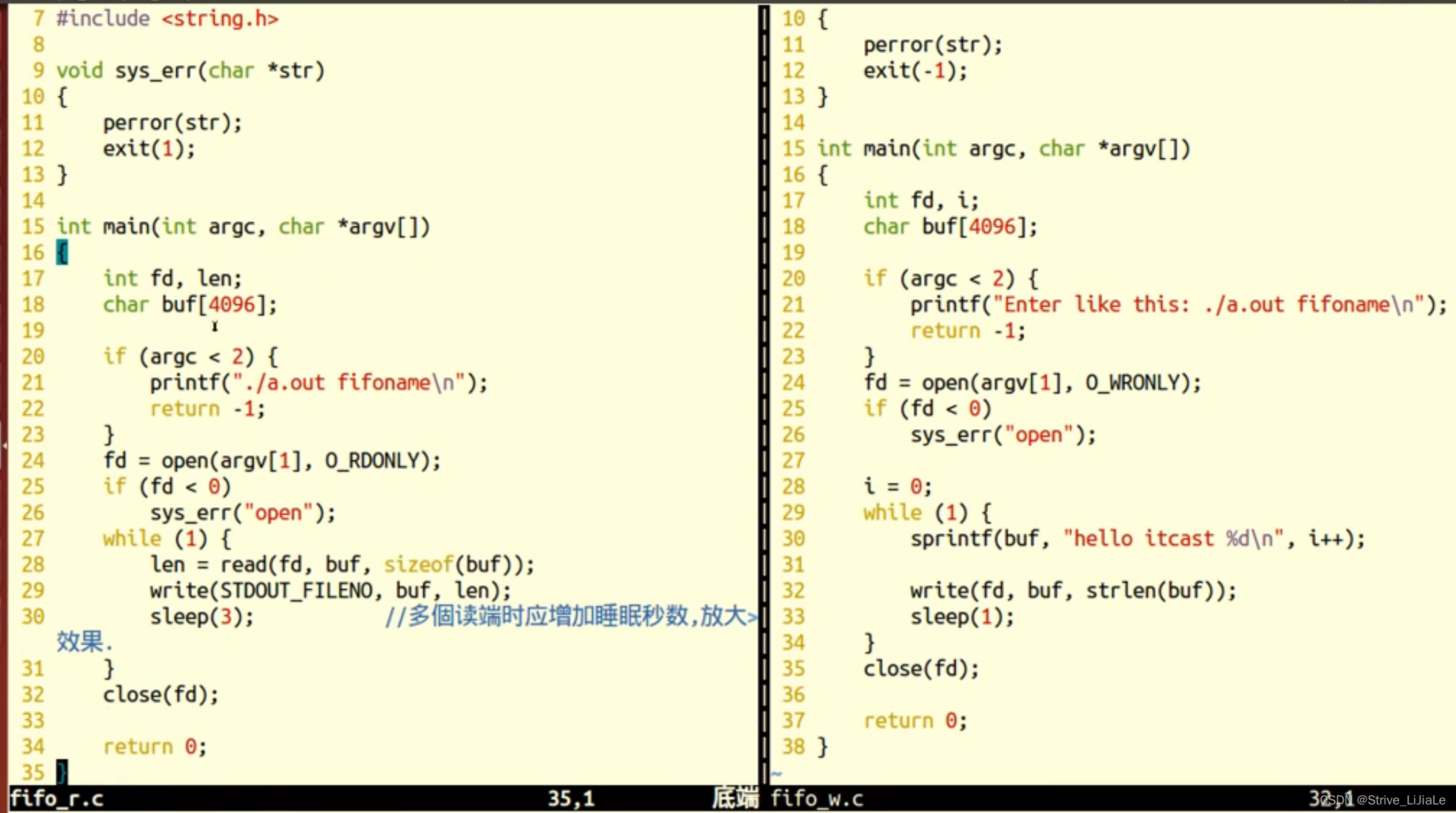
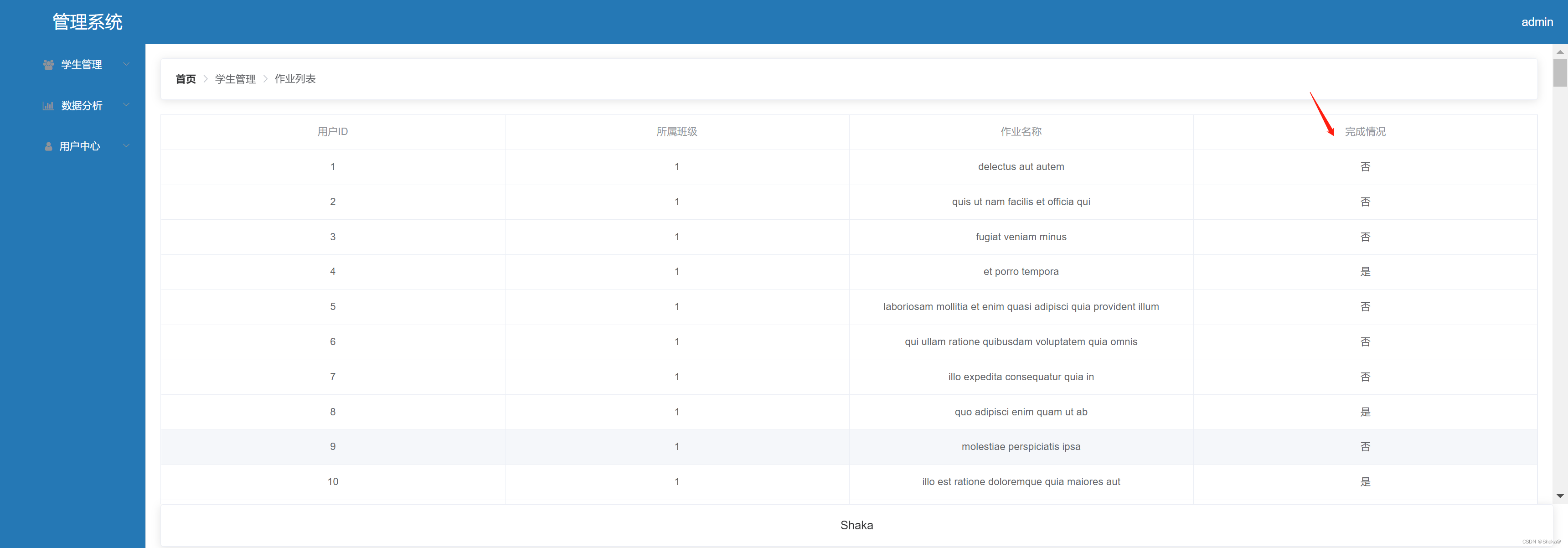
list.stream().forEach(System.out::println);输出结果如图18-1所示。

图 18-1 代码运行结果
有三点值得注意:
- 根据Comparable接口的定义,当对象小于、等于或大于另一个对象时,compareTo()方法必须返回一个负整数、零或正整数。在上述实现中,如果两个对象的相同属性值不同,则立即返回结果。因为不管其他属性如何,都已经知道这个Object是“更大的”还是“更小的”了。但是,对两个对象的属性加以比较,顺序对最终结果是有影响的。此方法定义了属性值影响顺序的优先级。
- 这里把List.of()的结果存入new ArrayList()对象中。这样做是因为用of()工厂方法创建的集合是不可更改的。即不能添加或删除任何元素,也不能更改元素的顺序,然而这里需要对所创建的集合进行排序。这里之所以使用of()方法是因为这个方法更便捷,并提供了更短的表示。
- 最后一点,使用java.util.Objects进行属性比较,令实现比自制编码更容易、更可靠。
在实现compareTo()方法时,重要的一点是:务必确保不要违反规则。规则如下:
- 只有当返回值为0时,obj1.compareTo(obj2)才会返回与obj2.compareTo(obj1)相同的值。
- 如果返回值不是0,则obj1.compareTo(obj2)的符号与obj2.compareTo(obj1)的符号相反。
- 如果obj1.compareTo(obj2) > 0,以及obj2.compareTo(obj3) >0,则obj1.compareTo(obj3) > 0。
- 如果obj1.compareTo(obj2) < 0,以及obj2. compareto (obj3) < 0,则obj1.compareTo(obj3) < 0。
- 如果obj1.compareTo(obj2) == 0,那么obj2. compareto (obj3)和obj1.compareTo(obj3)具有相同的符号。
- obj1.compareto (obj2)和obj2.compareto (obj1)都抛出相同的异常(如果有的话)。
如果obj1.equals(obj2),那么obj1.compareTo(obj2) == 0;同时,如果obj1.compareTo(obj2) == 0,那么obj1.equals(obj2)。
建议你这样做,但不总是有这样做的需要。
3●clone()方法
在java.lang.Object中,clone()方法的实现,如下所示。
@HotSpotIntrinsicCandidate
protected native Object clone() throws CloneNotSupportedException;注释如下所示。
/**
* Creates and returns a copy of this object. The precise meaning
* of "copy" may depend on the class of the object.
***此方法的默认结果是按原样返回对象字段的副本。
如果值是基本类型的,这样做是可以的。但是,如果对象属性是另一个对象的引用,则只复制引用,而不复制引用的对象。
这就是为什么这样的复制被称为浅复制(shallow copy)。
要实现深复制(deep copy),必须覆盖clone()方法并克隆引用对象的每个对象属性。
在任何情况下,为了能够克隆对象,类必须实现Cloneable接口,并确保沿着继承树的所有对象(以及对象的属性)也实现Cloneable接口(java.lang.Object除外)。
Cloneable接口是一个标记接口,用以告诉编译器:程序员有意决定允许克隆这个对象(不管是因为浅复制足够好,还是因为clone()方法被覆盖了)。
在未实现Cloneable接口的对象上尝试调用clone(),将引发CloneNotSupportedException异常。
这看起来就够复杂了,但实践中甚至有更多陷阱存在。例如,假设Person类具有Address类型的address属性。
Person对象p1的浅复制p2会引用相同的Address对象,从而导致p1.address == p2.address。
举例说明,Address类如下所示。
class Address {
private String street, city;
public Address(String street, String city) {
this.street = street;
this.city = city;
}
public void setStreet(String street) { this.street = street; }
public String getStreet() { return street; }
public String getCity() { return city; }
}Person3类是这样使用Address类的:
class Person3 implements Cloneable{
private int age;
private Address address;
private String firstName, lastName;
public Person3(int age, String firstName,
String lastName, Address address) {
this.age = age;
this.address = address;
this.lastName = lastName;
this.firstName = firstName;
}
public int getAge() { return age; }
public Address getAddress() { return address; }
public String getLastName() { return lastName; }
public String getFirstName() { return firstName; }
@Override
public Person3 clone() throws CloneNotSupportedException{
return (Person3) super.clone();
}
}注意,clone()方法完成的是浅复制,因为这个方法没有克隆address属性。
使用这种clone()方法实现的结果如下。
Person3 p1 = new Person3(42, "Nick", "Samoylov",
new Address("25 Main Street", "Denver"));
Person3 p2 = p1.clone();
System.out.println(p1.getAge() == p2.getAge()); // true
System.out.println(p1.getLastName() == p2.getLastName()); // true
System.out.println(p1.getLastName().equals(p2.getLastName())); // true
System.out.println(p1.getAddress() == p2.getAddress()); // true
System.out.println(p2.getAddress().getStreet()); //prints: 25 Main Street
p1.getAddress().setStreet("42 Dead End");
System.out.println(p2.getAddress().getStreet()); //prints: 42 Dead End可以看到,在克隆完成之后,对源对象的address属性所做的更改反映在副本的相同属性中。
这不是很直观,对吧?克隆的时候,所期望的是独立的复制,没错吧?
为了避免共享Address对象,还需要对此对象进行显式的克隆。
要进行显式的克隆,就必须使Address对象具有可克隆的性质,具体操作如下。
public class Address implements Cloneable{
private String street, city;
public Address(String street, String city) {
this.street = street;
this.city = city;
}
public void setStreet(String street) { this.street = street; }
public String getStreet() { return street; }
public String getCity() { return city; }
@Override
public Address clone() throws CloneNotSupportedException {
return (Address)super.clone();
}
}有了这个实现,现在就可以添加address的克隆属性了:
class Person4 implements Cloneable{
private int age;
private Address address;
private String firstName, lastName;
public Person4(int age, String firstName,
String lastName, Address address) {
this.age = age;
this.address = address;
this.lastName = lastName;
this.firstName = firstName;
}
public int getAge() { return age; }
public Address getAddress() { return address; }
public String getLastName() { return lastName; }
public String getFirstName() { return firstName; }
@Override
public Person4 clone() throws CloneNotSupportedException{
Person4 cl = (Person4) super.clone();
cl.address = this.address.clone();
return cl;
}
}现在,如果运行相同的测试,结果将与最初预期的一样。
Person4 p1 = new Person4(42, "Nick", "Samoylov",
new Address("25 Main Street", "Denver"));
Person4 p2 = p1.clone();
System.out.println(p1.getAge() == p2.getAge()); // true
System.out.println(p1.getLastName() == p2.getLastName()); // true
System.out.println(p1.getLastName().equals(p2.getLastName())); // true
System.out.println(p1.getAddress() == p2.getAddress()); // false
System.out.println(p2.getAddress().getStreet()); //prints: 25 Main Street
p1.getAddress().setStreet("42 Dead End");
System.out.println(p2.getAddress().getStreet()); //prints: 25 Main Street
因此,如果应用程序希望所有属性都做深复制,那么所涉及的所有对象都必须是可克隆的。
这样做是可以的,但有个前提:只要相关的对象——当前对象中的属性也好,父类(及其属性和父类)中的属性也罢——没有一个不需要新的对象属性,没有一个不需要属性是可克隆的,并且没有一个在容器对象的clone()方法中是可以显式克隆的。
这话说得有些复杂。其复杂性的根源在于克隆过程潜在的复杂性。
程序员经常避开,不让对象变成可克隆的,这就是原因所在。
取而代之,如果需要,程序员更喜欢手动克隆对象。例如:
Person4 p1 = new Person4(42, "Nick", "Samoylov",
new Address("25 Main Street", "Denver"));
Address address = new Address(p1.getAddress().getStreet(),
p1.getAddress().getCity());
Person4 p2 = new Person4(p1.getAge(), p1.getFirstName(),
p1.getLastName(), address);
System.out.println(p1.getAge() == p2.getAge()); // true
System.out.println(p1.getLastName() == p2.getLastName()); // true
System.out.println(p1.getLastName().equals(p2.getLastName())); // true
System.out.println(p1.getAddress() == p2.getAddress()); // false
System.out.println(p2.getAddress().getStreet()); //prints: 25 Main Street
p1.getAddress().setStreet("42 Dead End");
System.out.println(p2.getAddress().getStreet()); //prints: 25 Main Street如果将另一个属性添加到任何相关对象,采用这种途径仍然需要更改代码。
但是,这种途径提供了对结果的更多控制,并减少了产生意想不到后果的机会。
幸运的是,clone()方法并不经常使用。
事实上,可能永远不会遇到需要使用此方法的情况。
4●StringBuffer类和StringBuilder类
在单线程情况下(这是绝大多数情况),应该首选StringBuilder类,因为其速度更快。
5●try子句、catch子句和finally子句
使用try-with-resources语句是释放资源的首选方法(传统上是在finally块中完成)。
遵循各种库的原则编码,会使代码更简单、更可靠。
02、最佳设计实践
“最佳”这个词带有主观性,依赖于上下文。正因如此,下面所推荐的,是以主流编程中大多数案例为基础的。但是,盲目地和无条件地照搬照抄不可取。因为在某些上下文中,这些案例有些在实践中是没有用的,甚至是错误的。采纳某些案例前,尽力去理解其背后的动机,并把动机作为决策的指南。例如,规模大小就至关重要。如果应用程序代码不超过几千行,那么一种简单的单体式程序就足够好了,其代码具有细目清单式风格。但是,如果代码中有复杂的代码区块,并且由多人共同来编写,那么将代码分解成特定的区段将有利于代码的理解、维护和扩展(如果某个特定的代码区域比其他区域需要更多的资源)。
下面就开始进行高级设计决策,这里没有固定的顺序。
1●松耦合功能区的识别
这样的设计决策可尽早做出,依靠的仅仅是对未来系统的主体部分、这些部分的功能,以及这些部分产生和交换的数据的一般性理解。
这样做有以下几点好处:
- 鉴别未来系统的结构,这影响到进一步的设计步骤和具体实施。
- 各部分的专业化和更深层次的分析。
- 各部分的并行开发。
- 对数据流更好的理解。
2●功能区的传统层划分
每个功能区准备妥当后,就可以根据技术特性和所使用的技术进行专门化划分。
从传统意义上看,技术的专门化划分如下:
- 前端(用户图形界面或Web界面)。
- 具有广泛业务逻辑的中间层。
- 后端(数据存储或数据源)。
这样做的好处包括:
- 按层部署和扩展。
- 基于经验知识的程序员专门化划分。
- 各部分的并行开发。
3●接口代码的编写
以上面两个小节描述的决策为基础,专门化的部分必须通过接口中加以描述,而这个接口则隐藏实现的细节。
这种设计的好处是为面向对象编程奠定了基础。
4●工厂方法的使用
从定义上看,接口没有描述也不能描述实现接口的类的构造方法。使用工厂方法允许将这个差距缩小,只向客户端公开一个接口。
5●宁组合勿继承
最初,面向对象编程关注的是继承,将继承视作对象间分享共同功能的方式。
继承甚至是前面文章中描述的四个面向对象编程原则之一。
但在实践中,这种功能共享的方法在同一继承链中所包含的类之间创建了太多的依赖关系。
应用程序功能的演变通常是不可预测的,继承链中的一些类开始获得与类链的原始用途无关的功能。
这里的主张是,有些设计解决方案允许不用继承,而是保持原始的类不被改变。
然而,在实践中,经常发生这样的事情,子类可能会突然改变行为,只是因为它们通过继承获得了新的功能。
父母是不能选择的,对吧?另外,继承以这种方式打破了封装,而封装则是OOP的另一个基本原则。
另一方面,组合允许对使用类的哪个功能以及忽略类的哪个功能进行选择和控制。
组合还允许对象保持轻量级别,而免受继承带来的负担。
这样的设计更灵活,更具可扩展性和可预测性。
6●库的使用
使用Java类库(JCL)和外部(JDK之外的)库使编程更容易,还能编出更高质量的代码。
库的创建者投入了大量的时间和精力,所以应该尽力在任何时候都利用好这样的库。
这是利用好一个库的另一种方式——使用知名的共享接口集,而不是自己另起炉灶来定义接口。
关于编写让他人容易理解的代码,上面最后一句话起到了一个很好的切换作用,切换到本文下一个主题。
03、代码为人而写
最初几十年时间里,编程是需要编写机器命令,以供电子设备执行。这不仅是一项乏味且容易出错的工作,而且还要求编写的指令尽可能获得最佳的性能。因为计算机运行缓慢,也不会作太多的代码优化。即使作了优化,也不多。
从那时起,在硬件和编程方面都取得了很大的进步。在使所提交的代码尽可能快地运行方面,现代编译器功不可没,即便程序员没有认识到这一点。这就允许我们在无需过多考虑优化的情况下编写更多的代码行。但是传统的做法和许多关于编程的书籍继续要求作优化处理。有时我们仍然担心自己编写代码的性能,甚至担心的程度胜于代码产生的结果。遵循传统比背离传统更为容易。这就是为什么程序员更倾注于编写代码的方式,而不是使业务自动化,尽管实现了错误的业务逻辑的好代码也是无用的。
还是文归正传。有了现代JVM来助力,程序员对代码优化的需求已经不像以前那么迫切了。时至今日,程序员主要是关注全局,以避免产生导致不良代码性能的结构性错误,也关注多次被使用的代码。后者的紧迫性也越来越小,因为JVM变得越来越复杂,可以实时地查看代码,且在使用相同的输入多次调用相同的代码块时,只是返回结果(不执行)。
这就给我们留下了唯一可能的结论:编写代码时,必须确保代码让人而不是让计算机容易阅读、容易理解。在这个行业工作了一段时间的那些人,会对自己几年前编写的代码感到困惑不解。要是对编写的意图明确了然、透明清晰,就能改进代码编写的风格。对于注释的必要性,讨论多久都情有可原。
十分明确的是,对于代码的用意作鹦鹉学舌式的注释是没有必要的。例如:
//Initialize variable
int i = 0;对代码的用意予以解释的注释,更有价值:
// In case of x > 0, we are looking for a matching group
// because we would like to reuse the data from the account.
// If we find the matching group, we either cancel it and clone,
// or add the x value to the group, or bail out.
// If we do not find the matching group,
// we create a new group using data of the matched group.加了注释后,代码可能会变得很复杂。良好的注释用以说明意图,并帮助读者理解代码。问题是,程序员常常嫌麻烦而不去加注释。反对添加注释的人有两个典型的理由:
- 注释必须与代码一起维护和演变。否则,注释可能会产生误导。但是,没有什么工具可以用来提示程序员在修改代码的同时调整注释。因此,加注释很危险。
- 编写的代码本身(包括变量和方法的名称选择)自明,无需要额外的解释。
这两种说法都没错,但同样没错的是:注释也可能大有裨益,特别是那些紧扣意图的注释。
此外,这样的注释需要调整的地方不多,因为代码用意就算有变化,也不会经常变。
04、测试——通向高质量代码的捷径
最后讨论的一个最佳实践是:“测试不是开销或负担,而是程序员的成功指南。”唯一的问题是,何时编写测试代码。
一个有说服力的观点认为,要在编写程序代码行之前编写测试代码。如果能做到这一点,那再好不过了。这里也不会劝阻读者那样做。但如果不那样做,也应在编写一行或全部代码行之后就尽力开始编写测试代码。
实践中,许多有经验的程序员发现,在实现了一些新功能之后才开始编写测试代码很有益处,因为到了那时程序员才能更好地理解新代码如何能融进现有的上下文环境。程序员甚至可能试着对一些值实施硬编码,以查看新代码与调用新方法的代码的融合度好到什么程度。在确保新代码很好地得以融合之后,程序员可以继续实现和调优新代码,同时在调用代码的上下文中根据需求测试新的实现。
必须添加一个重要的限定条件:在编写测试代码时,输入数据和测试标准最好不是由你来设置,而是由分配给你任务的人或测试员来设置。根据代码生成的结果来设置测试程序是一个众所周知的程序员陷阱。客观的自我评估不易做到,但如有可能要尽力做到。