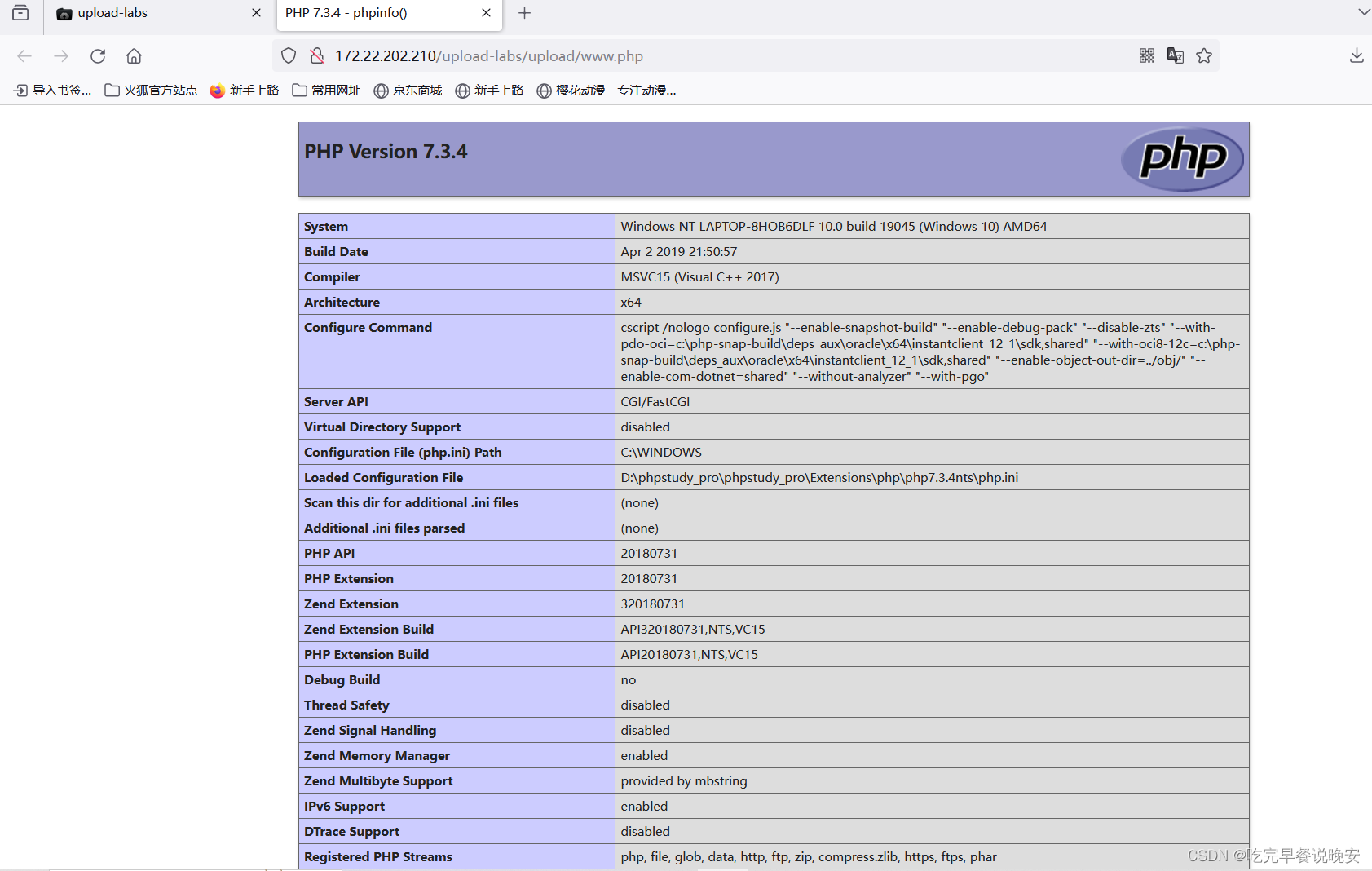
使用前面清洗好的数据来建立模型。使用自变量数据来预测是否存活(因变量)?
(根据问题特征,选择合适的算法)算法选择路径:

1.切割训练集与测试集
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Image
# 读取原数据数集
train = pd.read_csv('train.csv')
train.shape
#读取清洗过的数据集
# 删除了姓名列(对因变量无关),文本数据改为数值型数据
data = pd.read_csv('clear_data.csv')在作图时会使用中文标签,若要中文标签正常显示需要在前面加上下面的代码(应该放到我上一篇文章可视化部分):
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.figsize'] = (10, 6) # 设置输出图片大小在机器学习中有了数据集,需要按照一定比例把数据分为训练集与数据集(看我之前发的机器学习相关笔记),这里可以使用train_test_split() 函数:
在jupyter notebook中查看函数文档,了解用法和相关参数:
# 使用?来查看文档
train_test_split?from sklearn.model_selection import train_test_split
# 定义自变量和因变量
# 一般先取出X和y后再切割,有些情况会使用到未切割的,这时候X和y就可以用,x是清洗好的数据,y是我们要预测的存活数据'Survived'
X = data
y = train['Survived']
# 对数据集进行切割
# 随机种子:random_state=
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
# 查看数据形状
X_train.shape, X_test.shape
X_test.head()- 将数据集分为自变量和因变量
- 按比例切割训练集和测试集(一般测试集的比例有30%、25%、20%、15%和10%)
- 使用分层抽样
- 设置随机种子以便结果能复现
2.模型创建
- 创建基于线性模型的分类模型(逻辑回归)
- 创建基于树的分类模型(决策树、随机森林)
- 分别使用这些模型进行训练,分别的到训练集和测试集的得分
- 查看模型的参数,并更改参数值,观察模型变化
- 逻辑回归不是回归模型而是分类模型,不要与
LinearRegression混淆 - 随机森林其实是决策树集成为了降低决策树过拟合的情况
- 线性模型所在的模块为
sklearn.linear_model - 树模型所在的模块为
sklearn.ensemble
(模型的原理可查看我之前的笔记)
1逻辑回归模型:
导入包—使用模型—查看准确度—调整参数
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
# 默认参数逻辑回归模型
lr = LogisticRegression()
# fit使用给定的训练数据去拟合模型
# sample_weight=None样本权重参数,用于在训练时调整损失函数(仅用于训练)
# 某一种类的数据数量特别多,其他种类的数量特别少,样本不平衡,导致样本不是总体样本的无偏估计,从而可能导致我们的模型预测能力下降
# 查看数据是否失衡(结果:没有)
train['Survived'].value_counts()
lr.fit(X_train, y_train)
# lr = LogisticRegression().fit(X_train,y_train)
# 查看数据是否失衡
train['Survived'].value_counts()
# 查看训练集和测试集score值
# 返回平均准确度(把已知标签与预测标签对比)
# :.2f(表示浮点数小数点后两位)
print("Training set score: {:.2f}".format(lr.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr.score(X_test, y_test)))
# format另一种使用法
print(f"Testing set score: {lr.score(X_test, y_test):.2f}")
# 调整参数后的逻辑回归模型
# C,默认为1,越小越能限制模型的复杂度,模型就会越简单
# 因此需要找到合适的C值使得模型准确度升高,参数种类很多可以自己选择
# 模型简单就欠拟合,过于复杂就过拟合
lr2 = LogisticRegression(C=100)
lr2.fit(X_train, y_train)
# score()返回平均准确度(把已知标签与预测标签对比)
print("Training set score: {:.2f}".format(lr2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(lr2.score(X_test, y_test)))2随机森林模型:
# 默认参数的随机森林分类模型
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
print("Training set score: {:.2f}".format(rfc.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(rfc.score(X_test, y_test)))
# 调整参数后的随机森林分类模型
# n_estimators=100决策树的个数(默认100default)
# max_depth决策树的最大深度(没有默认值)
rfc2 = RandomForestClassifier(n_estimators=100, max_depth=5)
rfc2.fit(X_train, y_train)
print("Training set score: {:.2f}".format(rfc2.score(X_train, y_train)))
print("Testing set score: {:.2f}".format(rfc2.score(X_test, y_test)))3.输出模型预测结果
- 输出模型预测分类标签(predict() 函数)
- 输出不同分类标签的预测概率(predict_proba() 函数)
# 预测每个测试标签的结果
pred = lr.predict(X_train)
# 输出为每个测试集样本的预测结果(list)
# 打印前五个[0,5):01234 (左闭右开)
pred[:5]
# 预测标签概率
# 返回每个样本标签的概率
pred_proba = lr.predict_proba(X_train)
pred_proba[:10]
# 标签为0死亡的概率与1存活的概率