1.零钱兑换(322题)
题目描述:
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
你可以认为每种硬币的数量是无限的。
示例 1:
- 输入:coins = [1, 2, 5], amount = 11
- 输出:3
- 解释:11 = 5 + 5 + 1
dp[j]:凑足总额为j所需钱币的最少个数为dp[j]
凑足总额为j - coins[i]的最少个数为dp[j - coins[i]],那么只需要加上一个钱币coins[i]即dp[j - coins[i]] + 1就是dp[j](考虑coins[i])
所以dp[j] 要取所有 dp[j - coins[i]] + 1 中最小的。
递推公式:dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
dp[0] = 0;
考虑到递推公式的特性,dp[j]必须初始化为一个最大的数,否则就会在min(dp[j - coins[i]] + 1, dp[j])比较的过程中被初始值覆盖。
所以下标非0的元素都是应该是最大值。
本题求钱币最小个数,那么钱币有顺序和没有顺序都可以,都不影响钱币的最小个数。
所以本题并不强调集合是组合还是排列。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
本题的两个for循环的关系是:外层for循环遍历物品,内层for遍历背包或者外层for遍历背包,内层for循环遍历物品都是可以的
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int>dp(amount + 1,INT_MAX);
dp[0] = 0;
for(int i = 0;i < coins.size();i++){ // 遍历物品
for(int j = coins[i];j <= amount;j++){// 遍历背包
if (dp[j - coins[i]] != INT_MAX) { // 如果dp[j - coins[i]]是初始值则跳过
dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
}
}
}
if (dp[amount] == INT_MAX) return -1;
return dp[amount];
}
};- 时间复杂度: O(n * amount),其中 n 为 coins 的长度
- 空间复杂度: O(amount)
遍历背包放在外循环,遍历物品放在内循环也是可以的
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int>dp(amount + 1,INT_MAX);
dp[0] = 0;
for(int i = 1;i <= amount;i++){ // 遍历背包
for(int j = 0;j < coins.size();j++){// 遍历物品
if (i-coins[j] >= 0 && dp[i - coins[j]] != INT_MAX) { // 如果dp[j - coins[i]]是初始值则跳过
dp[i] = min(dp[i - coins[j]] + 1, dp[i]);
}
}
}
if (dp[amount] == INT_MAX) return -1;
return dp[amount];
}
};2.完全平方数(279题)
题目描述:
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
给你一个整数 n ,返回和为 n 的完全平方数的 最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
- 输入:n = 12
- 输出:3
- 解释:12 = 4 + 4 + 4
dp[j]:和为j的完全平方数的最少数量为dp[j]
dp[j] 可以由dp[j - i * i]推出, dp[j - i * i] + 1 便可以凑成dp[j]。
此时我们要选择最小的dp[j],所以递推公式:dp[j] = min(dp[j - i * i] + 1, dp[j]);
dp[0]表示 和为0的完全平方数的最小数量,那么dp[0]一定是0,非0下标的dp[j]一定要初始为最大值,这样dp[j]在递推的时候才不会被初始值覆盖。
本题外层for遍历背包,内层for遍历物品,还是外层for遍历物品,内层for遍历背包,都是可以的
先遍历物品,在遍历背包
class Solution {
public:
int numSquares(int n) {
vector<int>dp(n + 1,INT_MAX);
dp[0] = 0;
for(int i = 1;i * i <= n;i++){// 遍历物品
for(int j = i * i;j <= n;j++){// 遍历背包
dp[j] = min(dp[j],dp[j - i * i]+1);
}
}
return dp[n];
}
};遍历背包,遍历物品
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i <= n; i++) { // 遍历背包
for (int j = 1; j * j <= i; j++) { // 遍历物品
dp[i] = min(dp[i - j * j] + 1, dp[i]);
}
}
return dp[n];
}
};- 时间复杂度: O(n * √n)
- 空间复杂度: O(n)
3.单词拆分(139题)
题目描述:
给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
拆分时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
示例 1:
- 输入: s = "leetcode", wordDict = ["leet", "code"]
- 输出: true
- 解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
回溯算法:本道是枚举分割所有字符串,判断是否在字典里出现过
class Solution {
private:
bool backtracking (const string& s, const unordered_set<string>& wordSet, int startIndex) {
if (startIndex >= s.size()) {
return true;
}
for (int i = startIndex; i < s.size(); i++) {
string word = s.substr(startIndex, i - startIndex + 1);
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, i + 1)) {
return true;
}
}
return false;
}
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
return backtracking(s, wordSet, 0);
}
};- 时间复杂度:O(2^n),因为每一个单词都有两个状态,切割和不切割
- 空间复杂度:O(n),算法递归系统调用栈的空间
改进版回溯算法:
class Solution {
private:
bool backtracking (const string& s,
const unordered_set<string>& wordSet,
vector<bool>& memory,
int startIndex) {
if (startIndex >= s.size()) {
return true;
}
// 如果memory[startIndex]不是初始值了,直接使用memory[startIndex]的结果
if (!memory[startIndex]) return memory[startIndex];
for (int i = startIndex; i < s.size(); i++) {
string word = s.substr(startIndex, i - startIndex + 1);
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, memory, i + 1)) {
return true;
}
}
memory[startIndex] = false; // 记录以startIndex开始的子串是不可以被拆分的
return false;
}
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> memory(s.size(), 1); // -1 表示初始化状态
return backtracking(s, wordSet, memory, 0);
}
};这个时间复杂度其实也是:O(2^n)
背包问题:
dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词。
如果确定dp[j] 是true,且 [j, i] 这个区间的子串出现在字典里,那么dp[i]一定是true。(j < i )。
所以递推公式是 if([j, i] 这个区间的子串出现在字典里 && dp[j]是true) 那么 dp[i] = true。
从递推公式中可以看出,dp[i] 的状态依靠 dp[j]是否为true,那么dp[0]就是递推的根基,dp[0]一定要为true,否则递推下去后面都都是false了。
拆分为一个或多个在字典中出现的单词,所以这是完全背包。
还要讨论两层for循环的前后顺序。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
本题一定是 先遍历 背包,再遍历物品
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> dp(s.size() + 1, false);
dp[0] = true;
for (int i = 1; i <= s.size(); i++) { // 遍历背包
for (int j = 0; j < i; j++) { // 遍历物品
string word = s.substr(j, i - j); //substr(起始位置,截取的个数)
if (wordSet.find(word) != wordSet.end() && dp[j]) {
dp[i] = true;
}
}
}
return dp[s.size()];
}
};- 时间复杂度:O(n^3),因为substr返回子串的副本是O(n)的复杂度(这里的n是substring的长度)
- 空间复杂度:O(n)
4.多重背包理论基础(卡玛网56题)
有N种物品和一个容量为V 的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 。求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大。
#include<iostream>
#include<vector>
using namespace std;
int main(){
int bagWeight,n;
cin >> bagWeight >> n;
vector<int> weight(n, 0);
vector<int> value(n, 0);
vector<int> nums(n, 0);
for (int i = 0; i < n; i++) cin >> weight[i];
for (int i = 0; i < n; i++) cin >> value[i];
for (int i = 0; i < n; i++) cin >> nums[i];
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < n; i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
// 以上为01背包,然后加一个遍历个数
for (int k = 1; k <= nums[i] && (j - k * weight[i]) >= 0; k++) { // 遍历个数
dp[j] = max(dp[j], dp[j - k * weight[i]] + k * value[i]);
}
}
}
cout << dp[bagWeight] << endl;
}时间复杂度:O(m × n × k),m:物品种类个数,n背包容量,k单类物品数量
5.打家劫舍( 198题)
题目描述:
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
- 示例 1:
- 输入:[1,2,3,1]
- 输出:4
解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。 偷窃到的最高金额 = 1 + 3 = 4 。
dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。
dp[i]取最大值,即dp[i] = max(dp[i - 2] + nums[i], dp[i - 1])
dp[0] 一定是 nums[0],dp[1]就是nums[0]和nums[1]的最大值即:dp[1] = max(nums[0], nums[1]);
dp[i] 是根据dp[i - 2] 和 dp[i - 1] 推导出来的,那么一定是从前到后遍历!
class Solution {
public:
int rob(vector<int>& nums) {
//当前数组大小为0时返回0
if (nums.size() == 0)
return 0;
//当前数组大小1时返回1
if (nums.size() == 1)
return nums[0];
vector<int> dp(nums.size());//定义dp数组
dp[0] = nums[0];//初始化0
dp[1] = max(nums[0], nums[1]);//初始化dp[1]
//遍历,从后向前遍历
for (int i = 2; i < nums.size(); i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);//递推公式
}
return dp[nums.size() - 1];//返回值
}
};- 时间复杂度: O(n)
- 空间复杂度: O(n)
6. 打家劫舍II(213题)
题目描述:
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,能够偷窃到的最高金额。
示例 1:
-
输入:nums = [2,3,2]
-
输出:3
-
解释:你不能先偷窃 1 号房屋(金额 = 2),然后偷窃 3 号房屋(金额 = 2), 因为他们是相邻的。
- 情况一:考虑不包含首尾元素
- 情况二:考虑包含首元素,不包含尾元素
- 情况三:考虑包含尾元素,不包含首元素
虽然是考虑包含尾元素,但不一定要选尾部元素,情况二 和 情况三 都包含了情况一了,所以只考虑情况二和情况三就可以了。
class Solution {
public:
int rob(vector<int>& nums) {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
int result1 = robRange(nums, 0, nums.size() - 2); // 情况二
int result2 = robRange(nums, 1, nums.size() - 1); // 情况三
return max(result1, result2);
}
int robRange(vector<int>& nums,int start,int end){
if (end == start) return nums[start];
vector<int>dp(nums.size());
dp[start] = nums[start];
dp[start + 1] = max(nums[start],nums[start + 1]);
for(int i = start + 2;i <= end;i++){
dp[i] = max(dp[i - 1],dp[i - 2] + nums[i]);
}
return dp[end];
}
};- 时间复杂度: O(n)
- 空间复杂度: O(n)
7.打家劫舍 III(337题)
题目描述:
在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
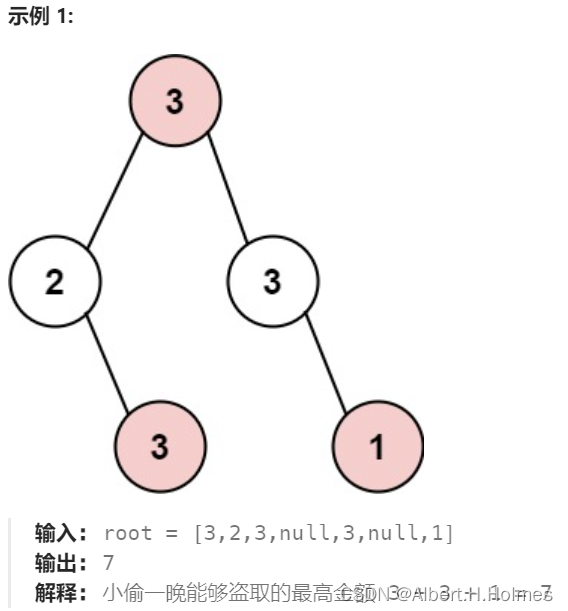
本题一定是要后序遍历,如果抢了当前节点,两个孩子就不能动,如果没抢当前节点,就可以考虑抢左右孩子
暴力递归
class Solution {
public:
int rob(TreeNode* root) {
if(root == NULL)return NULL;
if(root->left == NULL && root->right == NULL)return root->val;
// 偷父节点
int val1 = root->val;
if(root->left)val1 += rob(root->left->left) + rob(root->left->right);// 跳过root->left,相当于不考虑左孩子
if(root->right)val1 += rob(root->right->left) + rob(root->right->right);// 跳过root->right,相当于不考虑右孩子了
// 不偷父节点
int val2 = rob(root->left) + rob(root->right);
return max(val1, val2);
}
};- 时间复杂度:O(n^2),这个时间复杂度不太标准,也不容易准确化,例如越往下的节点重复计算次数就越多
- 空间复杂度:O(log n),算上递推系统栈的空间
记忆化递推:可以使用一个map把计算过的结果保存一下,这样如果计算过孙子了,那么计算孩子的时候可以复用孙子节点的结果。
class Solution {
public:
unordered_map<TreeNode* , int> umap; // 记录计算过的结果
int rob(TreeNode* root) {
if (root == NULL) return 0;
if (root->left == NULL && root->right == NULL) return root->val;
if (umap[root]) return umap[root]; // 如果umap里已经有记录则直接返回
// 偷父节点
int val1 = root->val;
if (root->left) val1 += rob(root->left->left) + rob(root->left->right); // 跳过root->left
if (root->right) val1 += rob(root->right->left) + rob(root->right->right); // 跳过root->right
// 不偷父节点
int val2 = rob(root->left) + rob(root->right); // 考虑root的左右孩子
umap[root] = max(val1, val2); // umap记录一下结果
return max(val1, val2);
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(log n),算上递推系统栈的空间
动态规划
这道题目算是树形dp的入门题目,因为是在树上进行状态转移
这里的返回数组就是dp数组
dp数组(dp table)以及下标的含义:下标为0记录不偷该节点所得到的的最大金钱,下标为1记录偷该节点所得到的的最大金钱。
dp数组就是一个长度为2的数组
在递归的过程中,系统栈会保存每一层递归的参数
在遍历的过程中,如果遇到空节点的话,很明显,无论偷还是不偷都是0,所以就返回,相当于dp数组的初始化,明确的是使用后序遍历。
通过递归左节点,得到左节点偷与不偷的金钱。
通过递归右节点,得到右节点偷与不偷的金钱。
如果是偷当前节点,那么左右孩子就不能偷,val1 = cur->val + left[0] + right[0]; (如果对下标含义不理解就再回顾一下dp数组的含义)
如果不偷当前节点,那么左右孩子就可以偷,至于到底偷不偷一定是选一个最大的,所以:val2 = max(left[0], left[1]) + max(right[0], right[1]);
最后当前节点的状态就是{val2, val1}; 即:{不偷当前节点得到的最大金钱,偷当前节点得到的最大金钱}
class Solution {
public:
int rob(TreeNode* root) {
vector<int> result = robTree(root);
return max(result[0], result[1]);
}
// 长度为2的数组,0:不偷,1:偷
vector<int> robTree(TreeNode* cur) {
if (cur == NULL) return vector<int>{0, 0};
vector<int> left = robTree(cur->left);
vector<int> right = robTree(cur->right);
// 偷cur,那么就不能偷左右节点。
int val1 = cur->val + left[0] + right[0];
// 不偷cur,那么可以偷也可以不偷左右节点,则取较大的情况
int val2 = max(left[0], left[1]) + max(right[0], right[1]);
return {val2, val1};
}
};- 时间复杂度:O(n),每个节点只遍历了一次
- 空间复杂度:O(log n),算上递推系统栈的空间
总结:
零钱兑换:不同面额的硬币 coins 和一个总金额 amount,凑成总金额所需的最少的硬币个数,dp[j]:凑足总额为j所需钱币的最少个数为dp[j] ,递推公式:dp[j] = min(dp[j - coins[i]] + 1, dp[j]);dp[0] = 0;dp[j]必须初始化为一个最大的数,否则就会在min(dp[j - coins[i]] + 1, dp[j])比较的过程中被初始值覆盖,下标非0的元素都是应该是最大值,本题的两个for循环的关系是:外层for循环遍历物品,内层for遍历背包或者外层for遍历背包,内层for循环遍历物品都是可以的,我们最后返回dp[amount]即可,如果dp[j - coins[i]]是初始值则跳过判断条件,
完全平方数:给定一个整数,使用完全平方数来实现和为这个整数,dp[j]:和为j的完全平方数的最少数量为dp[j],最小的dp[j],所以递推公式:dp[j] = min(dp[j - i * i] + 1, dp[j]),dp[0]一定是0,非0下标的dp[j]一定要初始为最大值,本题外层for遍历背包,内层for遍历物品,还是外层for遍历物品,内层for遍历背包,都是可以的。
for(int i = 1;i * i <= n;i++){// 遍历物品
for(int j = i * i;j <= n;j++){// 遍历背包
dp[j] = min(dp[j],dp[j - i * i]+1);
}
}
单词拆分:给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。回溯算法:本道是枚举分割所有字符串,判断是否在字典里出现过,组合问题,我们首先对字符串进行取哈希表的方法,unordered_set<string> wordSet,然后是组合问题,startindex,终止条件if(startindex > s.size())return true;for(int i = startindex;i<s.size();i++)之后我们需要对这个进行取字符串操作,s.substr操作,然后我们进行下面的操作,判断是否出现过且进行递归,然后返回True,否则返回false,使用背包来解决问题,dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词。递推公式是 if([j, i] 这个区间的子串出现在字典里 && dp[j]是true) 那么 dp[i] = true,dp[i] 的状态依靠 dp[j]是否为true,那么dp[0]就是递推的根基,dp[0]一定要为true,否则递推下去后面都都是false,本题一定是 先遍历 背包,再遍历物品,
多重背包理论基础:有N种物品和一个容量为V 的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 。求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大。
for(int i = 0; i < n; i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
// 以上为01背包,然后加一个遍历个数
for (int k = 1; k <= nums[i] && (j - k * weight[i]) >= 0; k++) { // 遍历个数
dp[j] = max(dp[j], dp[j - k * weight[i]] + k * value[i]);
}
}
}
打家劫舍: 给定一个数组,然后限制条件是相邻的有警报系统,可以偷取的最大价值是多少,dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]dp[i]取最大值,即dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]),dp[0] 一定是 nums[0],dp[1]就是nums[0]和nums[1]的最大值即:dp[1] = max(nums[0], nums[1]);从前到后遍历,这里我们定义dp数组大小为数组大小即可,初始化和上述介绍,遍历从前向后遍历,从2开始到nums.size(),最后递推公式即可,最后返回dp[nums.size() - 1]
打家劫舍II:该题与上一个题不同于整个数组是连成一个圈首尾呼应,三种情况第一个不考虑首尾,第二种考虑首不考虑尾,第三种情况考虑尾不考虑首,第二三种情况包括了第一种情况,所以我们直接考虑设计一个函数根据首尾位置的一个打家劫舍的函数即可实现,这里采用两个首尾位置下标的方法,首先递推公式和上一个一样,这里初始化需要根据下标进行初始化,初始化也就是把初始化的下标换成start即可,最后返回dp[end]即可,
打家劫舍III:和二叉树联系起来的一个打家劫舍问题,这里一定需要后序遍历,抢了当前节点,两个孩子就不能动,如果没抢当前节点,就可以考虑抢左右孩子,分两种情况取考虑,这里需要知道一个是取父节点(之后我们需要左节点的左右孩子,还要右节点的左右孩子),另一个是不取父节点(递归左和右)记忆化递推:可以使用一个map把计算过的结果保存一下,这样如果计算过孙子了,那么计算孩子的时候可以复用孙子节点的结果,树形dp是在树上进行状态转移,dp数组下标为0记录不偷该节点所得到的的最大金钱,下标为1记录偷该节点所得到的的最大金钱。dp数组就是一个长度为2的数组,如果是偷当前节点,那么左右孩子就不能偷,val1 = cur->val + left[0] + right[0]; (如果对下标含义不理解就再回顾一下dp数组的含义)如果不偷当前节点,那么左右孩子就可以偷,至于到底偷不偷一定是选一个最大的,所以:val2 = max(left[0], left[1]) + max(right[0], right[1]);最后当前节点的状态就是{val2, val1}; 即:{不偷当前节点得到的最大金钱,偷当前节点得到的最大金钱}其实这里就是将其分开讨论了,最后取最大值即可。