咱们接着这个系列的上一篇文章继续:
政安晨:【深度学习处理实践】(七)—— 文本数据预处理![]() https://blog.csdn.net/snowdenkeke/article/details/136697057
https://blog.csdn.net/snowdenkeke/article/details/136697057
机器学习模型如何表示单个单词,这是一个相对没有争议的问题:
它是分类特征(来自预定义集合的值),我们知道如何处理。它应该被编码为特征空间中的维度,或者类别向量(本例中为词向量)。然而,一个更难回答的问题是,如何对单词组成句子的方式进行编码,即如何对词序进行编码。
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
自然语言中的顺序问题很有趣:
与时间序列的时间步不同,句子中的单词没有一个自然、标准的顺序。不同语言对单词的排列方式非常不同,比如英语的句子结构与日语就有很大不同。即使在同一门语言中,通常也可以略微重新排列单词来表达同样的含义。更进一步,如果将一个短句中的单词完全随机打乱,你仍然可以大致读懂它的含义——尽管在许多情况下可能会出现明显的歧义。顺序当然很重要,但它与意义之间的关系并不简单。
如何表示词序是一个关键问题,不同类型的NLP架构正是源自于此。最简单的做法是舍弃顺序,将文本看作一组无序的单词,这就是词袋模型(bag-of-words model)。你也可以严格按照单词出现顺序进行处理,一次处理一个,就像处理时间序列的时间步一样,这样你就可以利用咱们以前介绍的循环模型。
最后,你也可以采用混合方法:Transformer架构在技术上是不考虑顺序的,但它将单词位置信息注入数据表示中,从而能够同时查看一个句子的不同部分(这与RNN不同),并且仍然是顺序感知的。RNN和Transformer都考虑了词序,所以它们都被称为序列模型(sequence model)。
从历史上看,机器学习在NLP领域的早期应用大多只涉及词袋模型。随着RNN的重生,人们对序列模型的兴趣从2015年开始才逐渐增加。今天,这两种方法仍然都是有价值的。我们来看看二者的工作原理,以及何时使用哪种方法。
我们将在一个著名的文本分类基准上介绍两种方法,这个基准就是IMDB影评情感分类数据集。咱们以前使用了IMDB数据集的预向量化版本,现在我们来处理IMDB的原始文本数据,就如同在现实世界中处理一个新的文本分类问题。
准备IMDB影评数据
首先,我们从斯坦福大学Andrew Maas的页面下载数据集并解压。
你会得到一个名为aclImdb的目录,其结构如下:
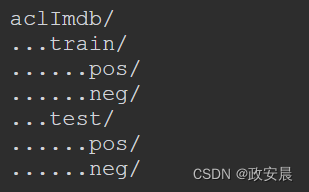
例如,train/pos/目录包含12 500个文本文件,每个文件都包含一个正面情绪的影评文本,用作训练数据。负面情绪的影评在neg目录下。共有25 000个文本文件用于训练,另有25 000个用于测试。
还有一个train/unsup子目录,我们不需要它,将其删除。
我们来查看其中几个文本文件的内容。请记住,无论是处理文本数据还是图像数据,在开始建模之前,一定都要查看数据是什么样子。这会让你建立直觉,了解模型在做什么。
!cat aclImdb/train/pos/4077_10.txt接下来,我们准备一个验证集,将20%的训练文本文件放入一个新目录中,即aclImdb/val目录。
import os, pathlib, shutil, random
base_dir = pathlib.Path("aclImdb")
val_dir = base_dir / "val"
train_dir = base_dir / "train"
for category in ("neg", "pos"):
os.makedirs(val_dir / category)
files = os.listdir(train_dir / category)
# 使用种子随机打乱训练文件列表,以确保每次运行代码都会得到相同的验证集
random.Random(1337).shuffle(files)
# (本行及以下1行)将20%的训练文件用于验证
num_val_samples = int(0.2 * len(files))
val_files = files[-num_val_samples:]
for fname in val_files:
# (本行及以下1行)将文件移动到aclImdb/val/neg目录和aclImdb/val/pos目录
shutil.move(train_dir / category / fname,
val_dir / category / fname)咱们以前讲过:
我们使用image_dataset_from_directory()函数根据目录结构创建一个由图像及其标签组成的批量Dataset。你可以使用text_dataset_from_directory()函数对文本文件做相同的操作。我们为训练、验证和测试创建3个Dataset对象。
from tensorflow import keras
batch_size = 32
# 运行这行代码的输出应该是“Found 20000 files belonging to 2 classes.”(找到属于2个类别的20 000个文件);如果你的输出是“Found 70000 files belonging to 3 classes.”(找到属于3个类别的70 000个文件),那么这说明你忘记删除aclImdb/train/unsup目录
train_ds = keras.utils.text_dataset_from_directory(
"aclImdb/train", batch_size=batch_size
)
val_ds = keras.utils.text_dataset_from_directory(
"aclImdb/val", batch_size=batch_size
)
test_ds = keras.utils.text_dataset_from_directory(
"aclImdb/test", batch_size=batch_size
)这些数据集生成的输入是TensorFlow tf.string张量,生成的目标是int32格式的张量,取值为0或1,如下代码所示:
(显示第一个批量的形状和数据类型)
for inputs, targets in train_ds:
print("inputs.shape:", inputs.shape)
print("inputs.dtype:", inputs.dtype)
print("targets.shape:", targets.shape)
print("targets.dtype:", targets.dtype)
print("inputs[0]:", inputs[0])
print("targets[0]:", targets[0])
break显示如下:
inputs.shape: (32,)
inputs.dtype: <dtype: "string">
targets.shape: (32,)
targets.dtype: <dtype: "int32">
inputs[0]: tf.Tensor(b"This string contains the movie review.", shape=(),
dtype=string)
targets[0]: tf.Tensor(1, shape=(), dtype=int32)
一切准备就绪,下面我们开始从这些数据中进行学习。
将单词作为集合处理:词袋方法
要对一段文本进行编码,使其可以被机器学习模型所处理,最简单的方法是舍弃顺序,将文本看作一组(一袋)词元。你既可以查看单个单词(一元语法),也可以通过查看连续的一组词元(N元语法)来尝试恢复一些局部顺序信息。
单个单词(一元语法)的二进制编码
如果使用单个单词的词袋,那么“the cat sat on the mat”(猫坐在垫子上)这个句子就会变成{"cat", "mat", "on", "sat", "the"}。
这种编码方式的主要优点是,你可以将整个文本表示为单一向量,其中每个元素表示某个单词是否存在。
举个例子,利用二进制编码(multi-hot),你可以将一个文本编码为一个向量,向量维数等于词表中的单词个数。这个向量的几乎所有元素都是0,只有文本中的单词所对应的元素为1。这就是咱们以前处理文本数据时所采用的方法。我们在本项任务中试试这种方法。
首先,我们用TextVectorization层来处理原始文本数据集,生成multi-hot编码的二进制词向量,如下代码所示:该层只会查看单个单词,即一元语法(unigram)。
(用TextVectorization层预处理数据集)
text_vectorization = TextVectorization(
# 将词表限制为前20 000个最常出现的单词。否则,我们需要对训练数据中的每一个单词建立索引——可能会有上万个单词只出现一两次,因此没有信息量。一般来说,20 000是用于文本分类的合适的词表大小
max_tokens=20000,
# 将输出词元编码为multi-hot二进制向量
output_mode="multi_hot",
)
# 准备一个数据集,只包含原始文本输入(不包含标签)
text_only_train_ds = train_ds.map(lambda x, y: x)
# 利用adapt()方法对数据集词表建立索引
text_vectorization.adapt(text_only_train_ds)
# (本行及以下8行)分别对训练、验证和测试数据集进行处理。一定要指定num_parallel_calls,以便利用多个CPU内核
binary_1gram_train_ds = train_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
binary_1gram_val_ds = val_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
binary_1gram_test_ds = test_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)你可以查看其中一个数据集的输出,如下代码所示:
(查看一元语法二进制数据集的输出)
for inputs, targets in binary_1gram_train_ds:
print("inputs.shape:", inputs.shape)
print("inputs.dtype:", inputs.dtype)
print("targets.shape:", targets.shape)
print("targets.dtype:", targets.dtype)
print("inputs[0]:", inputs[0])
print("targets[0]:", targets[0])
break
输出如下:
inputs.shape: (32, 20000) ←----输入是由20 000维向量组成的批量
inputs.dtype: <dtype: "float32">
targets.shape: (32,)
targets.dtype: <dtype: "int32">
inputs[0]: tf.Tensor([1. 1. 1. ... 0. 0. 0.], shape=(20000,), dtype=float32) ←----这些向量由0和1组成
targets[0]: tf.Tensor(1, shape=(), dtype=int32)
接下来,我们编写一个可复用的模型构建函数,如下代码所示:本节的所有实验都会用到它。
(模型构建函数)
from tensorflow import keras
from tensorflow.keras import layers
def get_model(max_tokens=20000, hidden_dim=16):
inputs = keras.Input(shape=(max_tokens,))
x = layers.Dense(hidden_dim, activation="relu")(inputs)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
return model最后,我们对模型进行训练和测试,如下代码所示:
(对一元语法二进制模型进行训练和测试)
model = get_model()
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("binary_1gram.keras",
save_best_only=True)
]
# (本行及以下1行)对数据集调用cache(),将其缓存在内存中:利用这种方法,我们只需在第一轮做一次预处理,在后续轮次可以复用预处理的文本。只有在数据足够小、可以装入内存的情况下,才可以这样做
model.fit(binary_1gram_train_ds.cache(),
validation_data=binary_1gram_val_ds.cache(),
epochs=10,
callbacks=callbacks)
model = keras.models.load_model("binary_1gram.keras")
print(f"Test acc: {model.evaluate(binary_1gram_test_ds)[1]:.3f}")模型的测试精度为89.2%,还不错!
请注意,本例的数据集是一个平衡的二分类数据集(正面样本和负面样本数量相同),所以无须训练模型就能实现的“简单基准”的精度只有50%。与此相对,在不使用外部数据的情况下,在这个数据集上能达到的最佳测试精度为95%左右。
二元语法的二进制编码
利用二元语法,前面的句子变成如下所示:
{"the", "the cat", "cat", "cat sat", "sat", "sat on", "on", "on the", "the mat", "mat"}
你可以设置TextVectorization层返回任意N元语法,如二元语法、三元语法等。只需传入参数ngrams=N,代码如下所示:
(设置TextVectorization层返回二元语法)
text_vectorization = TextVectorization(
ngrams=2,
max_tokens=20000,
output_mode="multi_hot",
)我们在这个二进制编码的二元语法袋上训练模型,并测试模型性能,代码如下所示:
(对二元语法二进制模型进行训练和测试)
text_vectorization.adapt(text_only_train_ds)
binary_2gram_train_ds = train_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
binary_2gram_val_ds = val_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
binary_2gram_test_ds = test_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
model = get_model()
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("binary_2gram.keras",
save_best_only=True)
]
model.fit(binary_2gram_train_ds.cache(),
validation_data=binary_2gram_val_ds.cache(),
epochs=10,
callbacks=callbacks)
model = keras.models.load_model("binary_2gram.keras")
print(f"Test acc: {model.evaluate(binary_2gram_test_ds)[1]:.3f}")现在测试精度达到了90.4%,有很大改进!事实证明,局部顺序非常重要。
二元语法的TF-IDF编码
你还可以为这种表示添加更多的信息,方法就是计算每个单词或每个N元语法的出现次数,也就是说,统计文本的词频直方图,如下所示:
{"the": 2, "the cat": 1, "cat": 1, "cat sat": 1, "sat": 1, "sat on": 1, "on": 1, "on the": 1, "the mat: 1", "mat": 1}
如果你做的是文本分类,那么知道一个单词在某个样本中的出现次数是很重要的:任何足够长的影评,不管是哪种情绪,都可能包含“可怕”这个词,但如果一篇影评包含许多个“可怕”,那么它很可能是负面的。
你可以用TextVectorization层来计算二元语法的出现次数,如下代码所示:
(设置TextVectorization层返回词元出现次数)
text_vectorization = TextVectorization(
ngrams=2,
max_tokens=20000,
output_mode="count"
)当然,无论文本的内容是什么,有些单词一定比其他单词出现得更频繁。“the”“a”“is”“are”等单词总是会在词频直方图中占据主导地位,远超其他单词,尽管它们对分类而言是没有用处的特征。我们怎么解决这个问题呢?
你可能已经猜到了:利用规范化。我们可以将单词计数减去均值并除以方差,对其进行规范化(均值和方差是对整个训练数据集进行计算得到的)。这样做是有道理的。但是,大多数向量化句子几乎完全由0组成(前面的例子包含12个非零元素和19 988个零元素),这种性质叫作稀疏性。这是一种很好的性质,因为它极大降低了计算负荷,还降低了过拟合的风险。如果我们将每个特征都减去均值,那么就会破坏稀疏性。因此,无论使用哪种规范化方法,都应该只用除法。那用什么作分母呢?最佳实践是一种叫作TF-IDF规范化(TF-IDF normalization)的方法。TF-IDF的含义是“词频–逆文档频次”。
TF-IDF非常常用,它内置于TextVectorization层中。要使用TF-IDF,只需将output_mode参数的值切换为"tf_idf",如下代码所示:
(设置TextVectorization层返回TF-IDF加权输出)
text_vectorization = TextVectorization(
ngrams=2,
max_tokens=20000,
output_mode="tf_idf",
)理解TF-IDF规范化
某个词在一个文档中出现的次数越多,它对理解文档的内容就越重要。
同时,某个词在数据集所有文档中的出现频次也很重要:如果一个词几乎出现在每个文档中(比如“the”或“a”),那么这个词就不是特别有信息量,而仅在一小部分文本中出现的词(比如“Herzog”)则是非常独特的,因此也非常重要。
TF-IDF指标融合了这两种思想。它将某个词的“词频”除以“文档频次”,前者是该词在当前文档中的出现次数,后者是该词在整个数据集中的出现频次。TF-IDF的计算方法如下。
def tfidf(term, document, dataset):
term_freq = document.count(term)
doc_freq = math.log(sum(doc.count(term) for doc in dataset) + 1)
return term_freq / doc_freq我们用这种设置训练一个新模型,如下代码所示:
(对TF-IDF二元语法模型进行训练和测试)
text_vectorization.adapt(text_only_train_ds)
tfidf_2gram_train_ds = train_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
tfidf_2gram_val_ds = val_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
tfidf_2gram_test_ds = test_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
model = get_model()
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("tfidf_2gram.keras",
save_best_only=True)
]
model.fit(tfidf_2gram_train_ds.cache(),
validation_data=tfidf_2gram_val_ds.cache(),
epochs=10,
callbacks=callbacks)
model = keras.models.load_model("tfidf_2gram.keras")
print(f"Test acc: {model.evaluate(tfidf_2gram_test_ds)[1]:.3f}")在IMDB分类任务上的测试精度达到了89.8%,这种方法对本例似乎不是特别有用。然而,对于许多文本分类数据集而言,与普通二进制编码相比,使用TF-IDF通常可以将精度提高一个百分点。
导出能够处理原始字符串的模型
在前面的例子中,我们将文本标准化、拆分和建立索引都作为tf.data管道的一部分。但如果想导出一个独立于这个管道的模型,我们应该确保模型包含文本预处理(否则需要在生产环境中重新实现,这可能很困难,或者可能导致训练数据与生产数据之间的微妙差异)。
幸运的是,这很简单。
我们只需创建一个新的模型,复用TextVectorization层,并将其添加到刚刚训练好的模型中。
# 每个输入样本都是一个字符串
inputs = keras.Input(shape=(1,), dtype="string")
# 应用文本预处理
processed_inputs = text_vectorization(inputs)
# 应用前面训练好的模型
outputs = model(processed_inputs)
# 将端到端的模型实例化
inference_model = keras.Model(inputs, outputs) 我们得到的模型可以处理原始字符串组成的批量,如下所示:
import tensorflow as tf
raw_text_data = tf.convert_to_tensor([
["That was an excellent movie, I loved it."],
])
predictions = inference_model(raw_text_data)
print(f"{float(predictions[0] * 100):.2f} percent positive")将单词作为序列处理:序列模型方法
前面几个例子清楚地表明,词序很重要。
基于顺序的手动特征工程(比如二元语法)可以很好地提高精度。现在请记住:深度学习的历史就是逐渐摆脱手动特征工程,让模型仅通过观察数据来自己学习特征。
如果不手动寻找基于顺序的特征,而是让模型直接观察原始单词序列并自己找出这样的特征,那会怎么样呢?这就是序列模型(sequence model)的意义所在。
要实现序列模型,首先需要将输入样本表示为整数索引序列(每个整数代表一个单词)。然后,将每个整数映射为一个向量,得到向量序列。最后,将这些向量序列输入层的堆叠,这些层可以将相邻向量的特征交叉关联,它可以是一维卷积神经网络、RNN或Transformer。
2016年~2017年,双向RNN(特别是双向LSTM)被认为是最先进的序列模型。你已经熟悉了这种架构,所以第一个序列模型示例将用到它。然而,如今的序列模型几乎都是用Transformer实现的,我们稍后会介绍。奇怪的是,一维卷积神经网络在NLP中一直没有很流行,尽管根据我自己的经验,一维深度可分离卷积的残差堆叠通常可以实现与双向LSTM相当的性能,而且计算成本大大降低。
第一个实例
我们来看一下第一个序列模型实例。首先,准备可以返回整数序列的数据集,如下代码所示:
(准备整数序列数据集)
from tensorflow.keras import layers
max_length = 600
max_tokens = 20000
text_vectorization = layers.TextVectorization(
max_tokens=max_tokens,
output_mode="int",
# 为保持输入大小可控,我们在前600个单词处截断输入。这是一个合理的选择,因为评论的平均长度是233个单词,只有5%的评论超过600个单词
output_sequence_length=max_length,
)
text_vectorization.adapt(text_only_train_ds)
int_train_ds = train_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
int_val_ds = val_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
int_test_ds = test_ds.map(
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)下面来创建模型。要将整数序列转换为向量序列,最简单的方法是对整数进行one-hot编码(每个维度代表词表中的一个单词)。在这些one-hot向量之上,我们再添加一个简单的双向LSTM,如下代码所示:
(构建于one-hot编码的向量序列之上的序列模型)
import tensorflow as tf
# 每个输入是一个整数序列
inputs = keras.Input(shape=(None,), dtype="int64")
# 将整数编码为20 000维的二进制向量
embedded = tf.one_hot(inputs, depth=max_tokens)
# 添加一个双向LSTM
x = layers.Bidirectional(layers.LSTM(32))(embedded)
x = layers.Dropout(0.5)(x)
# 最后添加一个分类层
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()下面我们来训练模型,如下代码所示:
(训练第一个简单的序列模型)
callbacks = [
keras.callbacks.ModelCheckpoint("one_hot_bidir_lstm.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=10,
callbacks=callbacks)
model = keras.models.load_model("one_hot_bidir_lstm.keras")
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")我们得到两个观察结果。
第一,这个模型的训练速度非常慢,尤其是与刚才的轻量级模型相比。
这是因为输入很大:每个输入样本被编码成尺寸为(600,20000)的矩阵(每个样本包含600个单词,共有20 000个可能的单词)。一条影评就有12 000 000个浮点数。双向LSTM需要做很多工作。
第二,这个模型的测试精度只有87%,性能还不如一元语法二进制模型,后者的速度还很快。
显然,使用one-hot编码将单词转换为向量,这是我们能做的最简单的事情,但这并不是一个好主意。
有一种更好的方法:词嵌入(word embedding)。
理解词嵌入
重要的是,进行one-hot编码时,你做了一个与特征工程有关的决策。你向模型中注入了有关特征空间结构的基本假设。
这个假设是:你所编码的不同词元之间是相互独立的。
事实上,one-hot向量之间都是相互正交的。对于单词而言,这个假设显然是错误的。单词构成了一个结构化的空间,单词之间共享信息。在大多数句子中,“movie”和“film”这两个词是可以互换的,所以表示“movie”的向量与表示“film”的向量不应该正交,它们应该是同一个向量,或者非常相似。
说得更抽象一点,两个词向量之间的几何关系应该反映这两个单词之间的语义关系。
例如,在一个合理的词向量空间中,同义词应该被嵌入到相似的词向量中,一般来说,任意两个词向量之间的几何距离(比如余弦距离或L2距离)应该与这两个单词之间的“语义距离”有关。含义不同的单词之间应该相距很远,而相关的单词应该相距更近。
词嵌入是实现这一想法的词向量表示,它将人类语言映射到结构化几何空间中。
one-hot编码得到的向量是二进制的、稀疏的(大部分元素是0)、高维的(维度大小等于词表中的单词个数),而词嵌入是低维的浮点向量(密集向量,与稀疏向量相对),如下图所示:
(one-hot编码或one-hot哈希得到的词表示是稀疏、高维、硬编码的,而词嵌入是密集、相对低维的,而且是从数据中学习得到的)
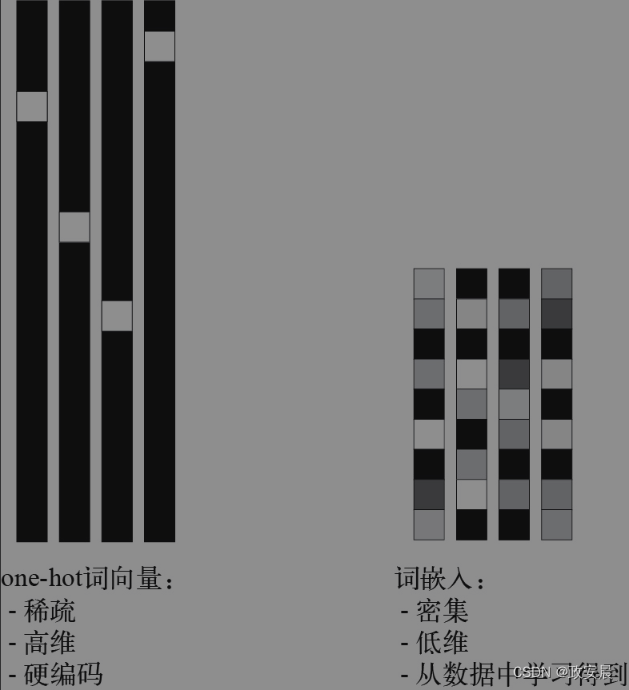
常见的词嵌入是256维、512维或1024维(处理非常大的词表时)。与此相对,one-hot编码的词向量通常是20 000维(词表中包含20000个词元)或更高。因此,词嵌入可以将更多的信息塞入更少的维度中。
词嵌入是密集的表示,也是结构化的表示,其结构是从数据中学习得到的。相似的单词会被嵌入到相邻的位置,而且嵌入空间中的特定方向也是有意义的。为了更清楚地说明这一点,我们来看一个具体示例。
在下图中,4个词被嵌入到二维平面中:这4个词分别是Cat(猫)、Dog(狗)、Wolf(狼)和Tiger(虎)。
(词嵌入空间的简单示例)

利用我们这里选择的向量表示,这些词之间的某些语义关系可以被编码为几何变换。例如,从Cat到Tiger的向量与从Dog到Wolf的向量相同,这个向量可以被解释为“从宠物到野生动物”向量。同样,从Dog到Cat的向量与从Wolf到Tiger的向量也相同,这个向量可以被解释为“从犬科到猫科”向量。
在现实世界的词嵌入空间中,常见的有意义的几何变换示例包括“性别”向量和“复数”向量。例如,将“king”(国王)向量加上“female”(女性)向量,得到的是“queen”(女王)向量。将“king”(国王)向量加上“plural”(复数)向量,得到的是“kings”向量。词嵌入空间通常包含上千个这种可解释的向量,它们可能都很有用。
我们来看一下在实践中如何使用这样的嵌入空间。有以下两种方法可以得到词嵌入。
在完成主任务(比如文档分类或情感预测)的同时学习词嵌入。在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,学习方式与学习神经网络权重相同。
在不同于待解决问题的机器学习任务上预计算词嵌入,然后将其加载到模型中。这些词嵌入叫作预训练词嵌入(pretrained word embedding)。
我们来分别看一下这两种方法:
利用Embedding层学习词嵌入
是否存在一个理想的词嵌入空间,它可以完美地映射人类语言,并可用于所有自然语言处理任务?这样的词嵌入空间可能存在,但我们尚未发现。此外,并不存在人类语言这种东西。世界上有许多种语言,它们之间并不是同构的,因为语言反映的是特定文化和特定背景。但从更实际的角度来说,一个好的词嵌入空间在很大程度上取决于你的任务,英语影评情感分析模型的完美词嵌入空间,可能不同于英语法律文件分类模型的完美词嵌入空间,因为某些语义关系的重要性因任务而异。
因此,合理的做法是对每个新任务都学习一个新的嵌入空间。幸运的是,反向传播让这种学习变得简单,Keras则使其变得更简单。我们只需学习Embedding层的权重,如下代码所示:
(将Embedding层实例化)
# Embedding层至少需要两个参数:词元个数和嵌入维度(这里是256)
embedding_layer = layers.Embedding(input_dim=max_tokens, output_dim=256)你可以将Embedding层理解为一个字典,它将整数索引(表示某个单词)映射为密集向量。它接收整数作为输入,在内部字典中查找这些整数,然后返回对应的向量。
Embedding层的作用实际上就是字典查询,如下图所示(Embedding层):
![]()
Embedding层的输入是形状为(batch_size, sequence_length)的2阶整数张量,其中每个元素都是一个整数序列。
该层返回的是一个形状为(batch_size,sequence_length, embedding_dimensionality)的3阶浮点数张量。
将Embedding层实例化时,它的权重(内部的词向量字典)是随机初始化的,就像其他层一样。
在训练过程中,利用反向传播来逐渐调节这些词向量,改变空间结构,使其可以被下游模型利用。训练完成之后,嵌入空间会充分地显示结构。这种结构专门针对模型训练所要解决的问题。
我们来构建一个包含Embedding层的模型,为我们的任务建立基准,如下代码所示:
(从头开始训练一个使用Embedding层的模型)
inputs = keras.Input(shape=(None,), dtype="int64")
embedded = layers.Embedding(input_dim=max_tokens, output_dim=256)(inputs)
x = layers.Bidirectional(layers.LSTM(32))(embedded)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("embeddings_bidir_gru.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=10,
callbacks=callbacks)
model = keras.models.load_model("embeddings_bidir_gru.keras")
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")模型训练速度比one-hot模型快得多(因为LSTM只需处理256维向量,而不是20000维),测试精度也差不多(87%)。然而,这个模型与简单的二元语法模型相比仍有一定差距。
部分原因在于,这个模型所查看的数据略少:二元语法模型处理的是完整的评论,而这个序列模型在600个单词之后截断序列。
理解填充和掩码
这里还有一件事会略微降低模型性能,那就是输入序列中包含许多0。
这是因为我们在TextVectorization层中使用了output_sequence_length=max_length选项(max_length为600),也就是说,多于600个词元的句子将被截断为600个词元,而少于600个词元的句子则会在末尾用0填充,使其能够与其他序列连接在一起,形成连续的批量。
我们使用的是双向RNN,即两个RNN层并行运行,一个正序处理词元,另一个逆序处理相同的词元。按正序处理词元的RNN,在最后的迭代中只会看到表示填充的向量。如果原始句子很短,那么这可能包含几百次迭代。
在读取这些无意义的输入时,存储在RNN内部状态中的信息将逐渐消失。
我们需要用某种方式来告诉RNN,它应该跳过这些迭代。有一个API可以实现此功能:掩码(masking)。
Embedding层能够生成与输入数据相对应的掩码。
这个掩码是由1和0(或布尔值True/False)组成的张量,形状为(batch_size, sequence_length),其元素mask[i, t]表示第i个样本的第t个时间步是否应该被跳过(如果mask[i, t]为0或False,则跳过该时间步,反之则处理该时间步)。
默认情况下没有启用这个选项,你可以向Embedding层传入mask_zero=True来启用它。你可以用compute_mask()方法来获取掩码,如下所示:
embedding_layer = layers.Embedding(input_dim=10, output_dim=256, mask_zero=True)
some_input = [
... [4, 3, 2, 1, 0, 0, 0],
... [5, 4, 3, 2, 1, 0, 0],
... [2, 1, 0, 0, 0, 0, 0]]
mask = embedding_layer.compute_mask(some_input)
<tf.Tensor: shape=(3, 7), dtype=bool, numpy=
array([[ True, True, True, True, False, False, False],
[ True, True, True, True, True, False, False],
[ True, True, False, False, False, False, False]])>在实践中,你几乎不需要手动管理掩码。
相反,Keras会将掩码自动传递给能够处理掩码的每一层(作为元数据附加到所对应的序列中)。RNN层会利用掩码来跳过被掩码的时间步。如果模型返回的是整个序列,那么损失函数也会利用掩码来跳过输出序列中被掩码的时间步。
我们使用掩码重新训练模型,如下代码所示:
(使用带有掩码的Embedding层)
inputs = keras.Input(shape=(None,), dtype="int64")
embedded = layers.Embedding(
input_dim=max_tokens, output_dim=256, mask_zero=True)(inputs)
x = layers.Bidirectional(layers.LSTM(32))(embedded)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("embeddings_bidir_gru_with_masking.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=10,
callbacks=callbacks)
model = keras.models.load_model("embeddings_bidir_gru_with_masking.keras")
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")这次模型的测试精度达到了88%,这是一个很小但仍可观的改进。
使用预训练词嵌入
有时可用的训练数据太少,只用手头数据无法学习特定任务的词嵌入。
在这种情况下,你可以从预计算嵌入空间中加载词嵌入向量(这个嵌入空间是高度结构化的,并且具有有用的性质,捕捉到了语言结构的通用特征),而不是在解决问题的同时学习词嵌入。
在自然语言处理中使用预训练词嵌入,其背后的原理与在图像分类中使用预训练卷积神经网络是一样的:没有足够的数据来自己学习强大的特征,但你需要的特征是非常通用的,即常见的视觉特征或语义特征。在这种情况下,复用在其他问题上学到的特征,这种做法是有意义的。
这种词嵌入通常是利用词频统计计算得到的(观察哪些单词在句子或文档中同时出现),它用到了很多种技术,有些涉及神经网络,有些则不涉及。
Yoshua Bengio等人在21世纪初首先研究了一种思路,就是用无监督的方法来计算一个密集、低维的词嵌入空间3,但直到成功的著名词嵌入方案Word2Vec算法发布之后,这一思路才开始在研究领域和工业应用中受到青睐。Word2Vec算法由谷歌公司的Tomas Mikolov于2013年开发,其维度捕捉到了特定的语义属性,比如性别。
有许多预计算的词嵌入数据库,你都可以下载并在Keras的Embedding层中使用,Word2Vec是其中之一。
另一个常用的叫作词表示全局向量(Global Vectors for Word Representation,GloVe),由斯坦福大学的研究人员于2014年开发。这种嵌入方法基于对词共现统计矩阵进行因式分解。它的开发者已经公开了数百万个英文词元的预计算嵌入,它们都是从维基百科数据和Common Crawl数据得到的。
我们来看一下如何在Keras模型中使用GloVe嵌入。同样的方法也适用于Word2Vec嵌入或其他词嵌入数据库。我们首先下载GloVe文件并解析。然后,我们将词向量加载到Keras Embedding层中,并利用它来构建一个新模型。
首先,我们下载在2014年英文维基百科数据集上预计算的GloVe词嵌入。它是一个822 MB的压缩文件,里面包含400 000个单词(或非词词元)的100维嵌入向量。
我们对解压后的文件(一个.txt文件)进行解析,构建一个索引将单词(字符串)映射为其向量表示,如下代码所示。
(解析GloVe词嵌入文件)
import numpy as np
path_to_glove_file = "glove.6B.100d.txt"
embeddings_index = {}
with open(path_to_glove_file) as f:
for line in f:
word, coefs = line.split(maxsplit=1)
coefs = np.fromstring(coefs, "f", sep=" ")
embeddings_index[word] = coefs
print(f"Found {len(embeddings_index)} word vectors.")接下来,我们构建一个可以加载到Embedding层中的嵌入矩阵,如下代码所示。
(准备GloVe词嵌入矩阵)
embedding_dim = 100
# 获取前面TextVectorization层索引的词表
vocabulary = text_vectorization.get_vocabulary()
# 利用这个词表创建一个从单词到其词表索引的映射
word_index = dict(zip(vocabulary, range(len(vocabulary))))
# 准备一个矩阵,后续将用GloVe向量填充
embedding_matrix = np.zeros((max_tokens, embedding_dim))
for word, i in word_index.items():
if i < max_tokens:
embedding_vector = embeddings_index.get(word)
# (本行及以下2行)用索引为i的单词的词向量填充矩阵中的第i个元素。对于嵌入索引中找不到的单词,其嵌入向量全为0
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector它必须是一个形状为(max_words, embedding_dim)的矩阵,对于索引为i的单词(在词元化时建立索引),该矩阵的元素i包含这个单词对应的embedding_dim维向量。
最后,我们使用Constant初始化方法在Embedding层中加载预训练词嵌入。为避免在训练过程中破坏预训练表示,我们使用trainable=False冻结该层,如下所示。
embedding_layer = layers.Embedding(
max_tokens,
embedding_dim,
embeddings_initializer=keras.initializers.Constant(embedding_matrix),
trainable=False,
mask_zero=True,
)现在我们可以训练一个新模型,如下代码所示。新模型与之前的模型相同,但使用的是100维的预训练GloVe嵌入,而不是128维学到的嵌入。
(使用预训练Embedding层的模型)
inputs = keras.Input(shape=(None,), dtype="int64")
embedded = embedding_layer(inputs)
x = layers.Bidirectional(layers.LSTM(32))(embedded)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("glove_embeddings_sequence_model.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=10,
callbacks=callbacks)
model = keras.models.load_model("glove_embeddings_sequence_model.keras")
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")可以看到,对于这项特定的任务,预训练词嵌入不是很有帮助,因为数据集中已经包含足够多的样本,足以从头开始学习一个足够专业的嵌入空间。
但是在处理较小的数据集时,预训练词嵌入会非常有用。
基于深度学习处理文本,咱们就告一段落了。