小T导读:胜软科技在石油石化行业中选择使用 TDengine 处理时序数据,不仅显著降低了运维数据库的成本,也大幅减少了存储空间的占用,实现了从原有的 40 多套 Oracle 数据库向仅 9 套 TDengine集群的精简替换。在迁移过程中,原有表结构几乎无需调整即可平滑移植至 TDengine。早在 TDengine 2.x 版本阶段,胜软科技便已开始部署使用,并在 TDengine 3.0 发布后完成升级,受益于 3.x 版本在功能和性能方面的诸多优化,尤其是数据订阅、企业版工具 taosX 等新功能,为实际应用带来了显著便利。本文将分享其在迁移与落地过程中的实践经验。
1. 背景概述
石油石化行业的时序数据广泛应用于能源生产、运输、加工和销售等环节,大量设备、传感器和监控系统持续生成时时序数据,用于支撑生产监控、调度优化和故障预警。早年时序数据库尚不成熟,我们曾采用 Oracle 存储某大型油田的时序数据,但随着业务数据量快速增长,各油田系统在数据处理和查询性能上逐渐暴露出瓶颈。
1.1 没有万能的数据库,只有合适的数据库
Oracle 作为传统关系型数据库的佼佼者,其稳定性和性能毋庸置疑。但用于存储海量时序数据并不合适,效率低、成本高的问题日益突出。要从根本上解决瓶颈,唯一的办法就是替换 Oracle。近年来,时序数据库快速发展,引起了我们的关注,针对时序数据的特性,选用专业的时序数据库已成为必然选择。
1.2 降低管理维护成本,简化运维
随着业务系统不断扩展,Oracle 数据库数量已增长至数十套,管理和维护成本居高不下,存储成本也持续攀升。而时序数据库在处理海量时序数据方面具备天然优势,超高压缩比大幅降低了存储开销。其分布式架构不仅支持灵活扩展计算资源以应对新增业务,还可便捷扩容节点存储空间,满足持续增长的数据需求。
1.3 软件国产化趋势下的重新选择
在石油石化行业,推进数据库软件国产化替代已成为信息化建设的重要趋势,旨在提升数据安全性、减少对国外厂商的依赖,并响应国家信创政策的要求。同时,数据库选型还需综合考虑其社区活跃度、发展前景,以及替换 Oracle 所需的改造成本等关键因素。
选型过程中,我们发现 TDengine 正是国产时序数据库中的重要一员:
-
将核心代码进行完全开源 https://github.com/taosdata/TDengine
-
支持集群、多副本等重要功能,集群环境下有更高的高可用性
-
TDengine 也已经支持众多的国产操作系统、CPU 平台
-
“一个设备一张表”与“超级表”的概念,设计了创新的存储引擎,让数据的写入、查询和存储效率都得到极大的提升,与我们当前业务匹配度很高
-
社区活跃度高,版本发布时间相对稳定,新功能在不断丰富
-
支持 SQL 语法,应用代码改动量小
经过前期充分的测试与验证,我们最终决定选用时序数据库 TDengine 来存储时序数据。
2. Oracle 切换至 TDengine
在我们的实时数据业务中,涉及实时类的设备和井等超过 70 种类型。过去在 Oracle 中,每类设备对应一张大表,所有同类设备的数据集中存储,字段类型多为 NUMBER、DATE、VARCHAR2 等。迁移至 TDengine 后,我们将字段类型调整为 TIMESTAMP、INT、DOUBLE、FLOAT、VARCHAR、NCHAR,并为每类设备建立一个超级表。
TDengine 要求超级表必须设置 tag 列,我们将设备编码作为首个 tag,用于标识每个具体设备或井。每个超级表下可创建多个子表,结构与超级表一致。这种设计方式与我们的业务场景高度契合,在后续的数据写入和查询性能上也带来了显著提升。
总体来看,从 Oracle 切换到 TDengine 比较顺利。

Oracle 库中的某表
TDengine 中的对应表
3. TDengine 大版本升级
早在 2022 年,我们就开始使用 TDengine 2.4 和 2.6 企业版。2023 年,在涛思数据企业版团队的支持下,我们顺利完成了向 3.0 的升级。由于 2.x 无法直接本地升级至 3.x,我们采用搭建临时集群的方式,制定了完整的升级与历史数据迁移方案,有效规避了业务中断风险。升级过程中,借助 taosX 工具,我们在不影响系统运行的前提下完成了历史数据迁移。以某单位为例,单副本 6T 数据在一周内全部迁移完成,最终成功切换至 3.0 版本。
TDengine 3.0 在使用方式上与 2.x 保持高度一致,写入、查询等核心功能无需大幅改动,仅需将 taos-jdbcdriver 升级至对应版本即可。
我们选择升级的另一个重要原因,是 3.0 提供了更强大、灵活的数据订阅能力。相比 2.x 中相对简单的订阅功能,3.0 支持按 SELECT、超级表、数据库等多级别进行订阅,既可将实时数据分发至其他系统,也能高效实现集群间数据同步,显著提升了业务集成与扩展能力。
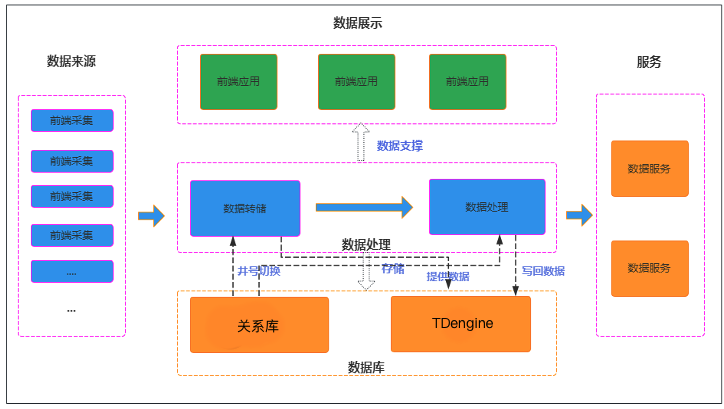
4. 落地效果
TDengine 上线后,系统运行始终保持稳定,在性能、存储效率和运维管理等方面都取得了显著成效。在使用与集成过程中,涛思数据的售后团队通过多种沟通渠道及时响应,持续提供专业支持,为项目的顺利推进提供了有力保障。
4.1 性能提升
应用 TDengine 后写入、查询方面都有很大提升,以下是早期的部分模拟测试场景:
| 测试内容 | 概要总结 |
|---|---|
| 数据写入 | 50000 井、2,000,000,000 条数据的写入 用时:2355.37 s 写入平均速度:849121.05 条/秒,140,954,094.3 点/秒 平均写入频率:208.25ms 最大写入间隔:3000.03ms 最小写入间隔:11.64ms |
| 单设备表 1 天数据查询 | 50000 设备、2,000,000,000 条数据 选择 1 个设备表,该设备 3 天数据中查询 1 天数据,输出到 CSV 文件 平均查询时间:2.64s |
| 全量表中 TAG 过滤单表查询 | 50000 设备、2,000,000,000 条数据中,在超级表中,有 5w 子表,使用 tag 过滤,在该子表增加 1 天时间限制,进行查询 平均用时:0.29s |
| 单设备表 1 条聚合查询 | 50000 设备、2,000,000,000 条数据中,在超级表中,有 5w 子表,使用 tag 过滤,进行 1 天时间段的聚合查询( count(*),max(wd), min(yy),avg(gl_sz))的查询 平均用时:1.41ms |
| 全量表按标签聚合 | 50000 设备、2,000,000,000 条数据中,在超级表中,有 5w 子表,查询所有测点在某个时间段内测点采集值的 count,max,min,avg 和 tag 分组查询 按照 tag 分组平均用时:2.29s |
| 全量表中按标签和时间段聚合 | 50000 设备、2,000,000,000 条数据中,在超级表中,有 5w 子表,按照 1 小时、1 天的时间窗口进行分组后的 count,max,min,avg 聚合结果。 1 小时聚合:9.76ms 1 天聚合:8.72ms |
| 全量数据时间最新数据查询 | 50000 设备、2,000,000,000 条数据中 全量数据中,查询该测点在所有数据中时间戳最大的一条记录。 平均用时:0.311s |
业务应用查询实时数据展示:
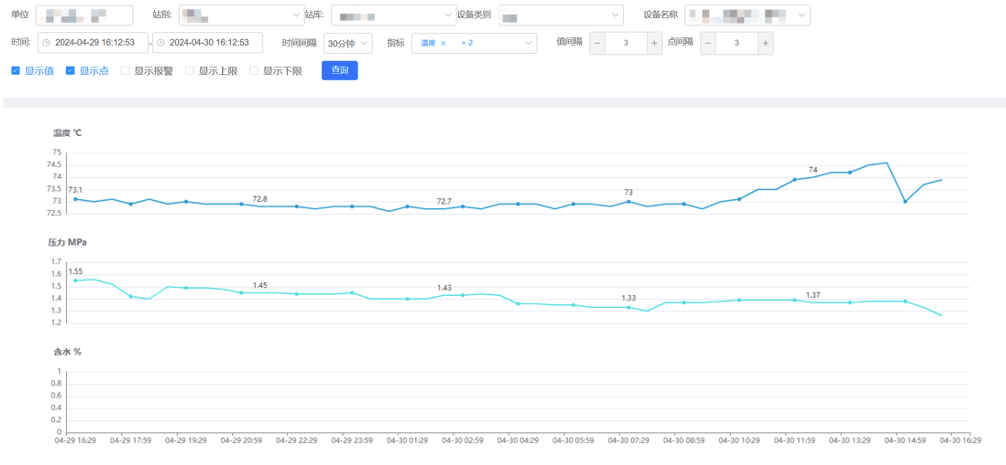
4.2 压缩比高,存储、运维成本降低
TDengine 具备出色的压缩能力,我们原先几张大表在迁移后,存储空间大幅减少,压缩率(见下图中的 Compression_Ratio)已降至个位数。
过去使用 40 多套 Oracle 数据库,如今各单位仅需部署 1 套 TDengine 集群即可满足业务需求,显著降低了运维成本。TDengine 支持多级存储,有效提升写入性能;我们目前采用 0 级挂载多个目录的方式,也提升了 I/O 吞吐能力。后续无论是为单台服务器扩容磁盘,还是增加节点扩展集群,操作都相对便捷。



4.3 数据订阅的使用
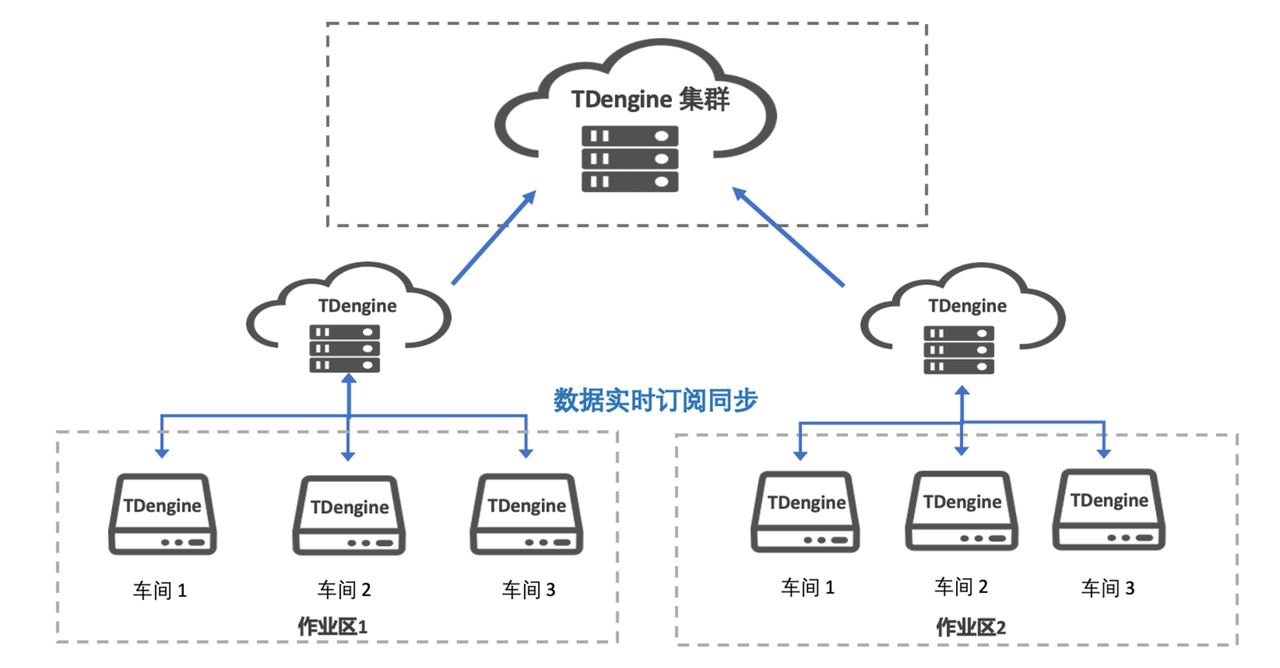
TDengine 提供了类似消息队列的数据订阅与消费接口,用户可在系统中定义 topic,与 Kafka 的使用方式相似。在许多场景下,借助 TDengine 构建时序大数据平台,我们无需再额外集成消息队列产品,极大简化了系统架构,也降低了运维成本。
在数据质量监测应用中,我们利用 TDengine 的订阅功能判断数据点的上报值是否处于合理范围,实现了实时的数据校验与告警。
我们不仅在业务系统中使用了数据订阅功能,在多个集群之间进行实时数据同步时,也同样依赖这一机制。通过 taosX 提供的 TMQ 数据订阅接口方式,我们实现了将数据实时同步至另一套集群,实现读写分离,进一步提升了生产环境的稳定性。
此外,数据订阅还有一个重要用途:辅助校验数据写入的准确性。通过订阅可以发现是否存在重复或乱序数据。由于 TDengine 默认以第一列为主键,同一子表中相同时间的数据仅保留一条,后写入的数据会覆盖先前的。借助这一机制,我们排查并解决了数据重复与乱序写入的问题,优化调整后,系统在读写性能与存储效率方面都实现了进一步提升。
5. 使用 TDengine 的心得
时序数据库与关系型数据库在数据存储量上存在显著差异,通常前者需要处理更大规模的数据。在查询时,需特别注意 SQL 的编写方式,重点聚焦时间范围内的数据,而非全表扫描,以避免不必要的资源消耗。
建议如下:
-
查询超级表时,务必添加第一列的时间戳范围过滤,精准限定查询时间段;
-
优先使用 tag 列进行过滤,而非普通列,可显著提升查询效率;
-
充分利用数据库的缓存机制,数据可直接从内存中获取,查询速度更快,比如获取每个设备的最新一条记录等场景。
6. 结语
石油石化是胜软科技重点服务的行业之一,而涛思数据也在该领域积累了丰富的实践经验。未来,我们将继续与涛思数据深入合作,持续探索更多业务场景的应用可能,充分发挥时序数据库在大规模时序数据管理方面的优势,并进一步推动与其他系统组件的集成,共同打造更高效、智能的数据平台。
关于胜软科技:
山东胜软科技股份有限公司成立于 2002 年,是国家高新技术企业,新三板挂牌企业,依托国家级双跨工业互联网平台“胜软云帆”构建一体化软件生产生态体系,打造以业务、技术为双擎的核心驱动力。面向智慧能源、智慧城市、智能制造三航道,提供战略规划、方案设计、软件开发实施、系统集成运维服务,目前已发展成为国内油气领域规模最大的民营软件服务商。采用北京+东营“双总部”运营模式,设有济南研发中心,在北京、成都、郑州、乌鲁木齐、青岛设有分公司,此外拥有 9 家子公司,1 家海外公司,客户遍布全国 24 个省市自治区和海外 8 个国家与地区。
作者:研发经理王强、孙东超