PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。
第46讲:POC-TPCH测试
内容1:TPC-H介绍
内容2:TPC-H测试部署
内容3:TPC-H报告
TPC背景介绍
TPC组织:
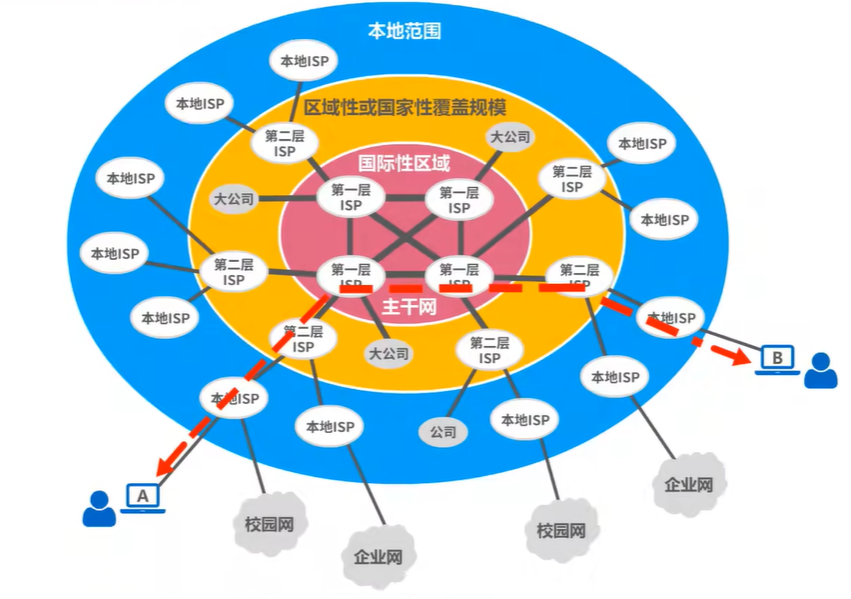
事务处理性能测试委员会TPC(Transaction process performance Council)是一个专门负责制定计算机事务处理能力测试标准并监督其执行的组织,其总部位于美国,针对数据库不同的使用场景TPC组织发布了多项测试标准,其中被业界广泛使用的有TPC-C 、TPC-E,TPC-H和TPC-DS,前两者应用到OLTP,后两者应用到OLAP场景。
OLTP与OLAP区别
联机事务处理OLTP(on-line transaction processing) 主要是执行基本日常的事务处理,比如数据库记录的增删查改。比如在银行的一笔交易记录,就是一个典型的事务。高并发,高性能,且满足事务的ACID特性。
联机分析处理OLAP(On-Line Analytical Processing) 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态的报表系统。对实时性要求不高,数据量大

测试标准-OLAP
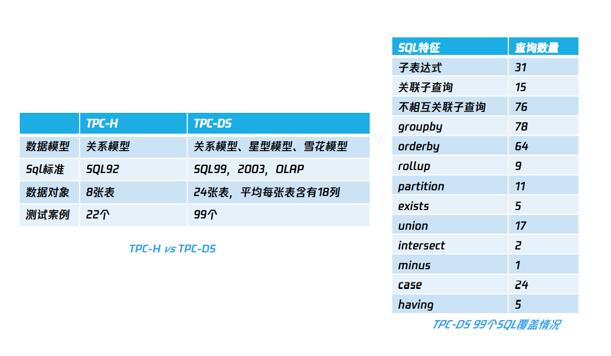
随着开源Hapdoop、Spark、HDFS、HBASE等技术的商用化,大数据管理技术得到了突飞猛进的发展,为了更客观地比较不同数据管理系统,TPC组织牵头制定了大数据测试基准TPC-H,TPC-DS,后者是TPC组织在TPC-H基础上的升级版本,下面介绍一下两者差异以及TPC-DS的SQL覆盖
TPC-H测试简介
TPC-H是事务处理性能委员会( Transaction ProcessingPerformance Council )制定的基准程序之一。
TPC- H 主要目的是评测数据库系统在统计分析、数据挖掘、分析处理等决策支持方面的能力。
该基准模拟了决策支持系统中的数据库操作,测试数据库系统复杂查询的响应时间,以每小时执行的查询数(TPC-H QphH@Siz)作为度量指标。
TPC-H基准模型中定义了一个数据库模型,容量可以在1GB~10000GB的8个级别中进行选择。数据库模型包括CUSTOMER、LINEITEM、NATION、ORDERS、PART、PARTSUPP、REGION和SUPPLIER 8张数据表。
模拟商品零售业决策支持系统的 22 个查询,涉及22条复杂的select查询流语句和2条带有insert和delete程序段的更新流语句。SQL涵盖了统计分组、排序、聚集操作、子查询、多表关联等复杂操作,可以测试各个查询的响应时间。
TPC-H查询语句简介
Q1语句是查询lineItems的一个定价总结报告
在单个表lineitem上查询某个时间段内,对已经付款的、已经运送的等各类商品进行统计,包括业务量的计费、发货、折扣、税、平均价格等信息。
Q1语句的特点是:带有分组、排序、聚集操作并存的单表查询操作。这个查询会导致表上的数据有95%到97%行被读取到。
Q2语句是查询最小代价供货商查询
Q2语句查询获得最小代价的供货商。得到给定的区域内,对于指定的零件(某一类型和大小的零件),哪个供应者能以最低的价格供应它,就可以选择哪个供应者来订货。
Q2语句的特点是:带有排序、聚集操作、子查询并存的多表查询操作。查询语句没有从语法上限制返回多少条元组,但是TPC-H标准规定,查询结果只返回前100行(通常依赖于应用程序实现)。
Q3语句是查询运送优先级
Q3语句查询得到收入在前10位的尚未运送的订单。在指定的日期之前还没有运送的订单中具有最大收入的订单的运送优先级(订单按照收入的降序排序)和潜在的收入(潜在的收入为l_extendedprice * (1-l_discount)的和)。
Q3语句的特点是:带有分组、排序、聚集操作并存的三表查询操作。查询语句没有从语法上限制返回多少条元组,但是TPC-H标准规定,查询结果只返回前10行(通常依赖于应用程序实现)。
TPC-H测试部署
1、软件安装
$ unzip tpc-h-tools-2.17.3.zip
$ cd 2.17.3/
$ cd dbgen/
$ cp makefile.suite makefile
#编辑makefile (修改如下内容 (第 109行左右),下面内容区别大小写)
CC=gcc
DATABASE=ORACLE
MACHINE=LINUX
WORKLOAD=TPCH
#编译
$ make
2、产生数据模板
让我们使用dbgen工具生成数据-有一个重要的参数“scale”影响数据量。它大致相当于原始数据的GB数,所以要生成5GB的数据,注意当前是否有足够的空间。
./dbgen -s 5
它以类似于Oracle的CSV格式创建一堆.tbl文件,ls *.tbl查看。
3、要将它们转换为与PostgreSQL兼容的CSV格式,请执行以下操作
for i in `ls *.tbl`; do sed 's/|$//' $i > ${i/tbl/csv}; echo $i; done;
执行完成后可以把.tbl文件删除,否则占用空间,现在我们有八个CSV文件可以加载到数据库中。但我们必须先创造它。
4、安装pg_tpch_master软件,提供测试脚本:
unzip pg_tpch-master.zip
cd pg_tpch-master
cp -rf dss /soft/2.17.3/dbgen/ #/soft是存放tpch软件的目录,后面需要dss目录下的文件
5、创建数据库并加载数据
尽管TPC-H规范描述了数据库结构,但create脚本不是包的一部分。PG准备了一个创建所有表的创建脚本和一个创建外键的alter脚本(在填充数据库之后),需要先创建一个数据库tpch然后再创建表。
$ cd /soft/2.17.3/dbgen/dss
$ psql tpch < tpch-create.sql
把前面由八个.tbl 转化为CSV文件mv到当前路径的data目录下,data目录需要自己创建。
$ mkdir data
$ mv /soft/2.17.3/dbgen/*.csv data/
6、用生成的数据填充数据库
在/soft/2.17.3/dbgen/dss目录下创建脚本load.sql,加入如下内容:
dir=`pwd`/data
opts="-h localhost tpch"
psql $opts -c "COPY part FROM '$dir/part.csv' WITH (FORMAT csv, DELIMITER '|')"
psql $opts -c "COPY region FROM '$dir/region.csv' WITH (FORMAT csv, DELIMITER '|')"
psql $opts -c "COPY nation FROM '$dir/nation.csv' WITH (FORMAT csv, DELIMITER '|')"
psql $opts -c "COPY supplier FROM '$dir/supplier.csv' WITH (FORMAT csv, DELIMITER '|')"
psql $opts -c "COPY customer FROM '$dir/customer.csv' WITH (FORMAT csv, DELIMITER '|')"
psql $opts -c "COPY partsupp FROM '$dir/partsupp.csv' WITH (FORMAT csv, DELIMITER '|')"
psql $opts -c "COPY orders FROM '$dir/orders.csv' WITH (FORMAT csv, DELIMITER '|')"
psql $opts -c "COPY lineitem FROM '$dir/lineitem.csv' WITH (FORMAT csv, DELIMITER '|') "
#执行该脚本,导入数据:
sh load.sql
7、最后创建约束
psql tpch < tpch-pkeys.sql --先创建主键
psql tpch < tpch-alter.sql --创建外键
8、产生sql语句:
现在我们必须从TPC-H基准中指定的模板生成查询。在tpch.org上提供的模板不适合PostgreSQL。因此,在“dss/templates”目录中提供了稍加修改的查询,应该将这些查询放在“dss/querys”目录中。进入到dbgen目录下,(必须要在此目录中)
$ cd /soft/2.17.3/dbgen
--创建存放sql语句的目录:
$ mkdir dss/queries
--产生sql语句:
for q in `seq 1 22`
do
DSS_QUERY=dss/templates ./qgen $q >> dss/queries/$q.sql
sed 's/^select/explain select/' dss/queries/$q.sql > dss/queries/$q.explain.sql
cat dss/queries/$q.sql >> dss/queries/$q.explain.sql;
done
8、产生sql语句(续):
现在,dss/querys目录中应该有44个文件。其中22个将实际运行查询,另外22个将生成查询的解释计划(不实际运行)。
自此,数据加载完成,同时产生sql语句,可以调用里面的sql语句执行。
9、产生工作负载集
--从查询模板中把22个查询集中产生一个压力测试的sql脚本:
DSS_QUERY=dss/queries ./qgen > dss/workload.sql
--指定某些查询模板产生工作负载集:
DSS_QUERY=dss/queries ./qgen 1 2 3 > dss/1_2_3_workload.sql
9、产生工作负载集
--指定1-10的查询模板产生工作负载集:
for r in `seq 1 10`
do
rn=$((`cat /dev/urandom|od -N3 -An -i` % 10000))
DSS_QUERY=dss/queries ./qgen -r $rn >> dss/1_to_10_workload.sql
done
10、执行压力测试脚本
前面我们以及生成了数据集,产生了压力测试的脚本,接下来需要去执行它,执行的方式有很多种,根据实际测试的要求去运行。
--简单的执行测试脚本,可以执行如下命令:
psql tpch < workload.sql
这个查询只是产生工作量,没有产生有关统计分析后的信息。
10、执行压力测试脚本
--生成一组结果日志,其中包含每个工作负载的秒数。从各种工具(iostat、vmstat等等)收集数据。
先准备workload-1.sql-workload-4.sql 4个脚本,然后再写一个脚本,调用该脚本:
DSS_QUERY=dss/queries ./qgen 1 > dss/workload-1.sql #根据这个命令产生1-4的压力脚本
#start the processes
for c in `seq 1 4`
do
/usr/bin/time -f "total=%e" -o result-$c.log \
psql tpch < workload-$c.sql > /dev/null 2>&1 &
done;
# wait for the processes
for p in `jobs -p`
do
wait $p;
done;
结合JeMeter产生测试报告

CUUG PostgreSQL技术大讲堂系列公开课第46讲-POC-TPCH测试的内容,往期视频及文档,请联系CUUG。