ELK日志管理实现的3种常见方法
1. 日志收集方法
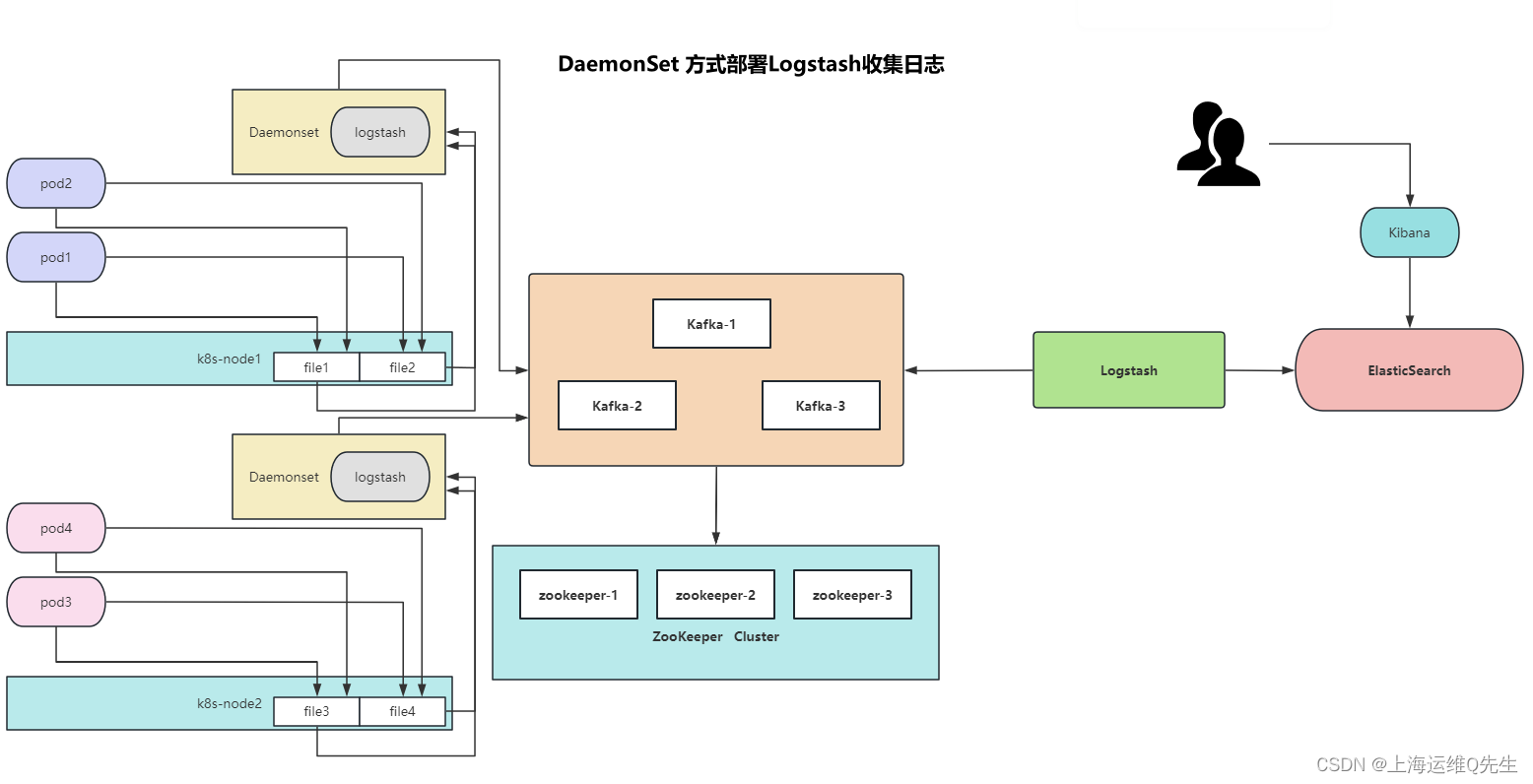
1.1 使用DaemonSet方式日志收集
通过将node节点的/var/log/pods目录挂载给以DaemonSet方式部署的logstash来读取容器日志,并将日志吐给kafka并分布写入Zookeeper数据库.再使用logstash将Zookeeper中的数据写入ES,并通过kibana将数据进行展示.
标准日志和错误日志:
标准日志 -->/dev/stdout
错误日志 ----> /dev/stderr
1.2 使用Logstash SideCar日志收集
pod中两个容器,1个是业务容器,另一个是日志收集容器,通过emptydir实现文件共享
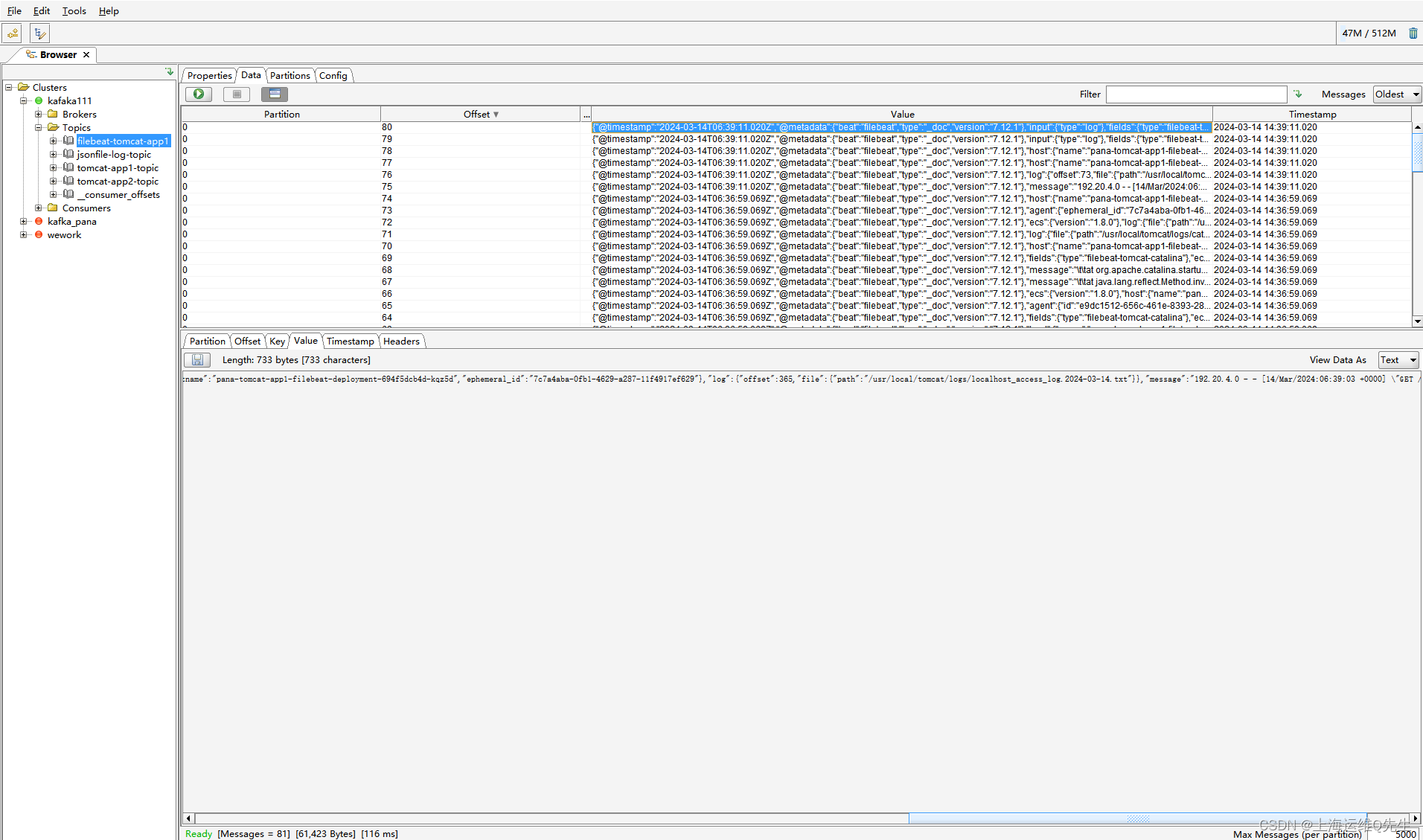
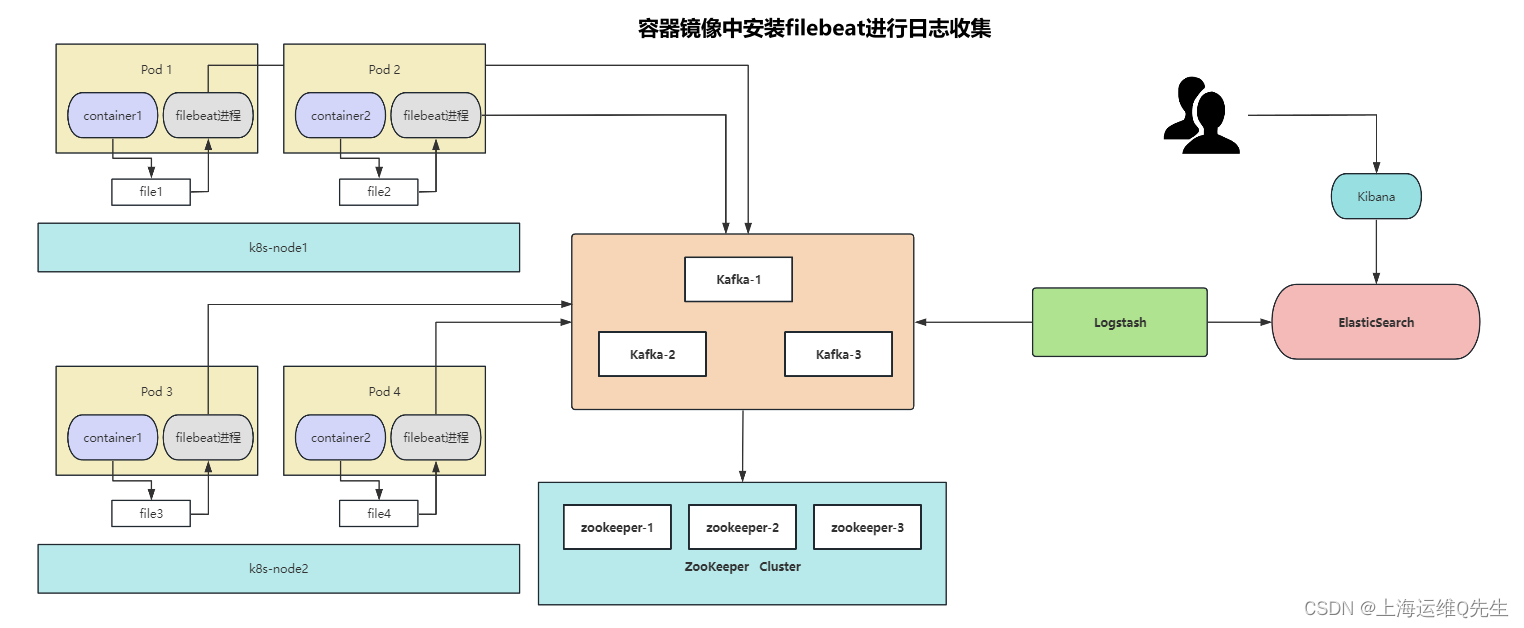
1.3 容器镜像中filebeat进程日志收集
对业务容器镜像修改,容器中启动filebeat
3种方式的对比:
- daemonset资源占用更少
- sidecar和filebeat可以更多的定制,但sidecar资源占用会更多
2. ElasticSearch集群部署
2.1 ElasticSearch器安装
- 下载deb包
清华源下载elasticsearch-7.12.1-amd64.deb
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/e/elasticsearch/elasticsearch-7.12.1-amd64.deb
- 3台ES服务器安装
dpkg -i elasticsearch-7.12.1-amd64.deb
- 修改配置文件
vi /etc/elasticsearch/elasticsearch.yml
cluster.name: k8s-els # 保证一样
node.name: es-01 # 3台保证不同
#bootstrap.memory_lock: true # 启动占用内存,如果打开需要修改/etc/elasticsearch/jvm.options
# 在/etc/elasticsearch/jvm.options中打开以下选项确保内存占用是连续的
## -Xms4g
## -Xmx4g
# 监听地址和端口
network.host: 192.168.31.101 # 也可以写成0.0.0.0
http.port: 9200
# 集群中有哪些服务器
discovery.seed_hosts: ["192.168.31.101", "192.168.31.102","192.168.31.103"]
# 哪些服务器可以作为master
cluster.initial_master_nodes: ["192.168.31.101", "192.168.31.102","192.168.31.103"]
# 删除数据不允许模糊匹配
action.destructive_requires_name: true
- 启动elasticsearch
systemctl enable --now elasticsearch.service
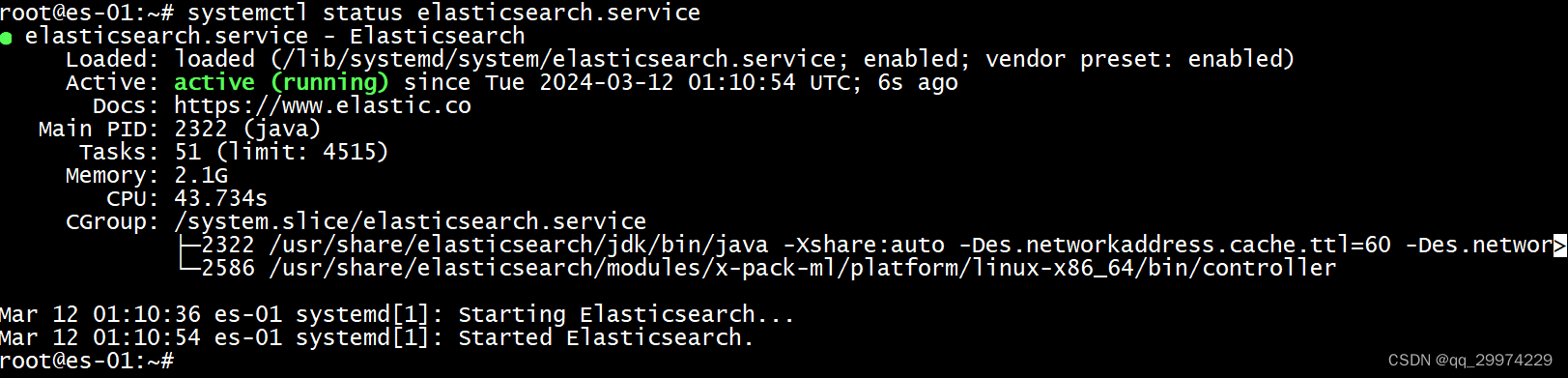
- 确认服务启动完成
systemctl status elasticsearch.service
2.2 Kibana安装
- 下载
清华源下载kibana-7.12.1-amd64.deb
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/k/kibana/kibana-7.12.1-amd64.deb
- 安装
dpkg -i kibana-7.12.1-amd64.deb
- 修改配置
vi /etc/kibana/kibana.yml
修改内容
server.port: 5601
server.host: "192.168.31.101" # 也可以写成0.0.0.0
elasticsearch.hosts: ["http://192.168.31.101:9200"] # 任意一个节点即可
i18n.locale: "zh-CN"
- 启动服务
systemctl enable --now kibana
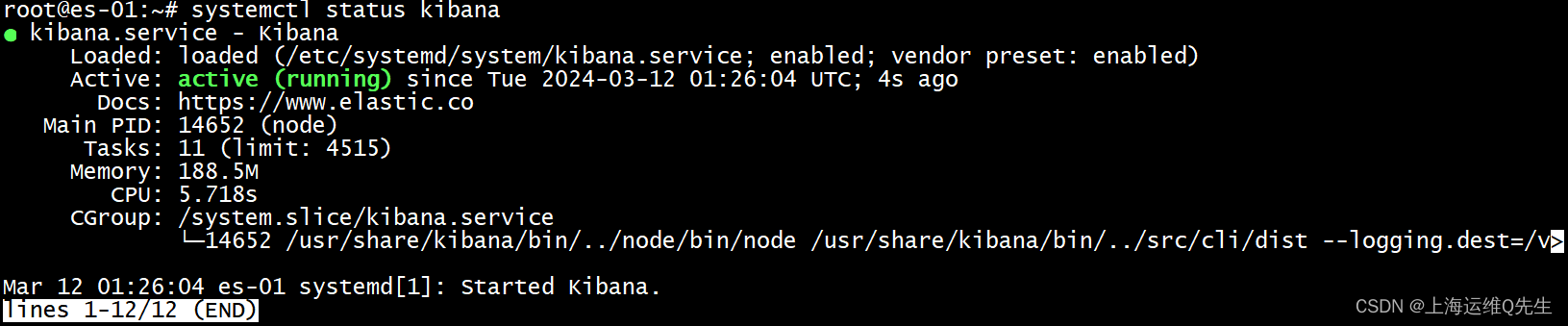
- 确认服务
systemctl status kibana
3. Zookeeper集群部署
3.1 Zookeeper安装
- 下载
官网下载zookeeper3.6.4(https://zookeeper.apache.org/)
https://archive.apache.org/dist/zookeeper/zookeeper-3.6.4/apache-zookeeper-3.6.4-bin.tar.gz
- 安装
zookeeper依赖jdk8,先安装jdk8
apt install openjdk-8-jdk -y
解压缩zookeeper
mkdir /apps
cd /apps
tar xf apache-zookeeper-3.6.4-bin.tar.gz
ln -sf /apps/apache-zookeeper-3.6.4-bin /apps/zookeeper
- 配置修改
cd /apps/zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
修改配置文件
vi /apps/zookeeper/conf/zoo.cfg
# 检查时间间隔
tickTime=2000
# 初始化次数
initLimit=10
# 存活检查次数
syncLimit=5
# 数据目录
dataDir=/data/zookeeper
# 客户端端口
clientPort=2181
# 集群配置 2888数据同步,3888集群选举
server.1=192.168.31.111:2888:3888
server.2=192.168.31.112:2888:3888
server.3=192.168.31.113:2888:3888
创建数据id
mkdir -p /data/zookeeper
echo 1 > /data/zookeeper/myid # 其他节点依次为2和3
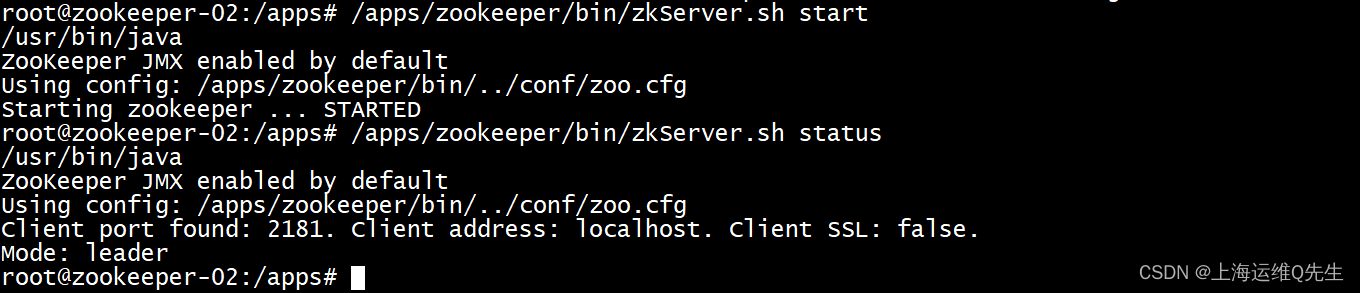
- 启动服务
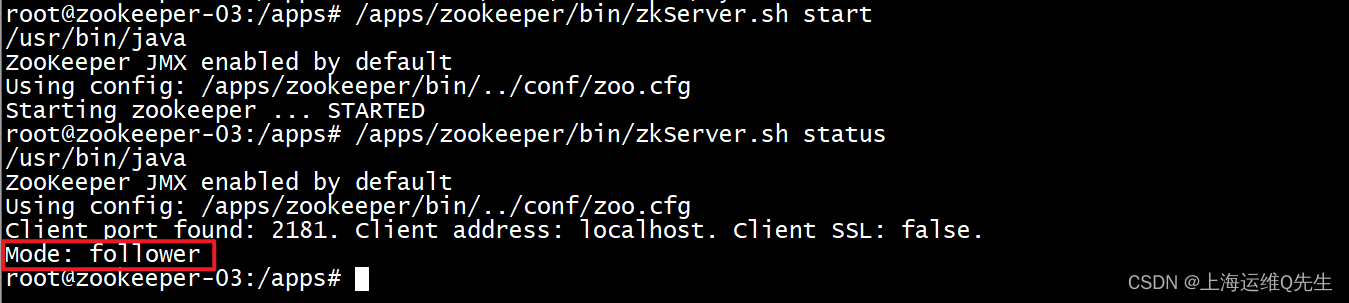
/apps/zookeeper/bin/zkServer.sh start
5.确认
/apps/zookeeper/bin/zkServer.sh status
确认状态是leader或者是follower
3.2 Kafka安装
1.下载
官网下载kafka(https://zookeeper.apache.org/)
https://dlcdn.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgz
- 安装
解压kafka包
tar xf kafka_2.13-3.7.0.tgz
ln -sf /apps/kafka_2.13-3.7.0 /apps/kafka
- 配置修改
cd /apps/kafka/config/
vi server.properties
修改内容
# 节点id保证不重复
broker.id=111
# 本机ip
listeners=PLAINTEXT://192.168.31.111:9092 # 确保每台服务器定义自己的ip
# 日志目录
log.dirs=/data/kafka-logs
# 数据保留时间 默认7天
log.retention.hours=168
# zookeeper集群连接配置
zookeeper.connect=192.168.31.111:2181,192.168.31.112:2181,192.168.31.113:2181
-
启动服务
3台服务器上,以daemon方式启动服务
/apps/kafka/bin/kafka-server-start.sh -daemon /apps/kafka/config/server.properties
- 确认
启动后会监听在9092端口
ss -ntlp|grep 9092

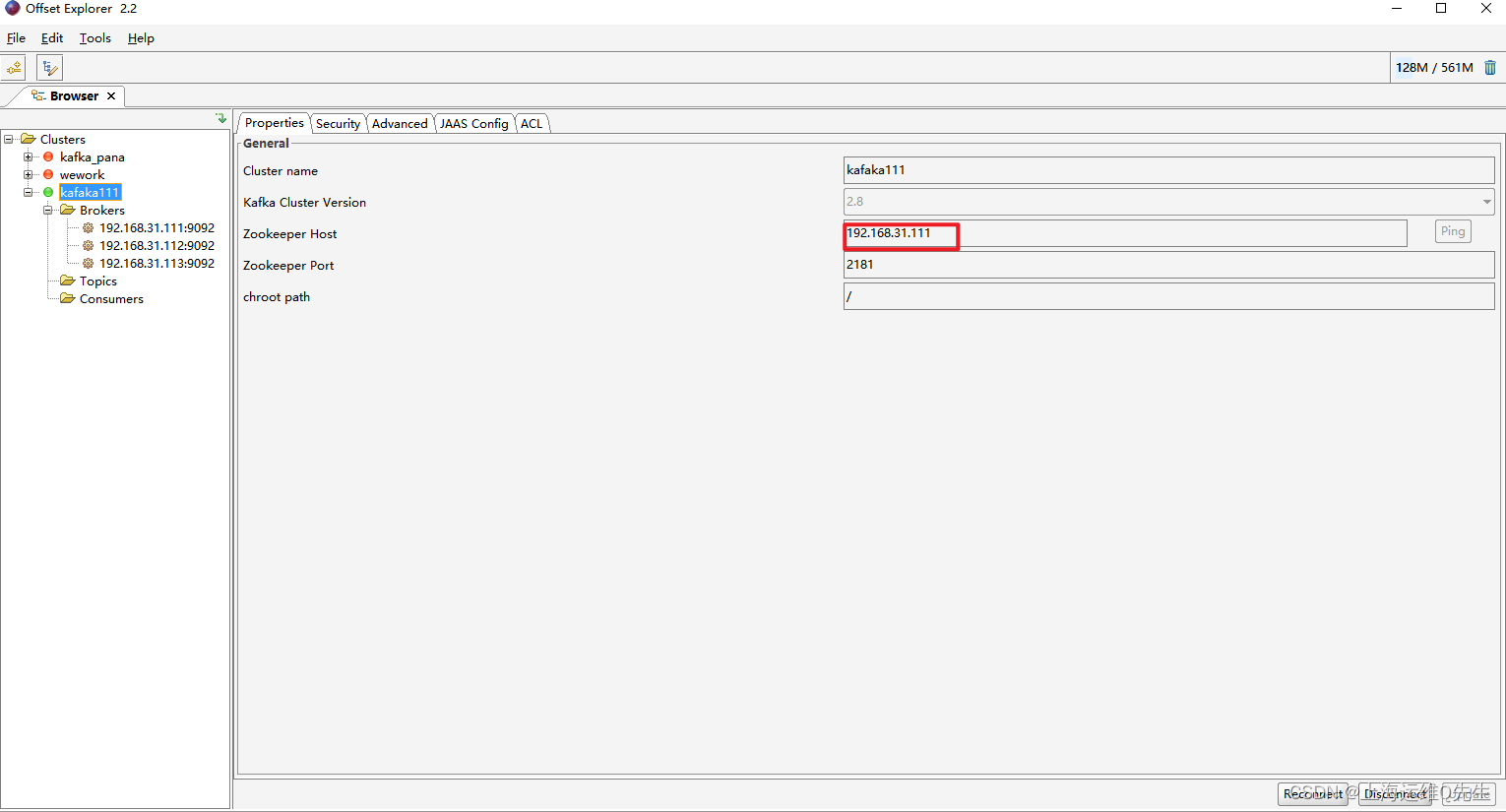
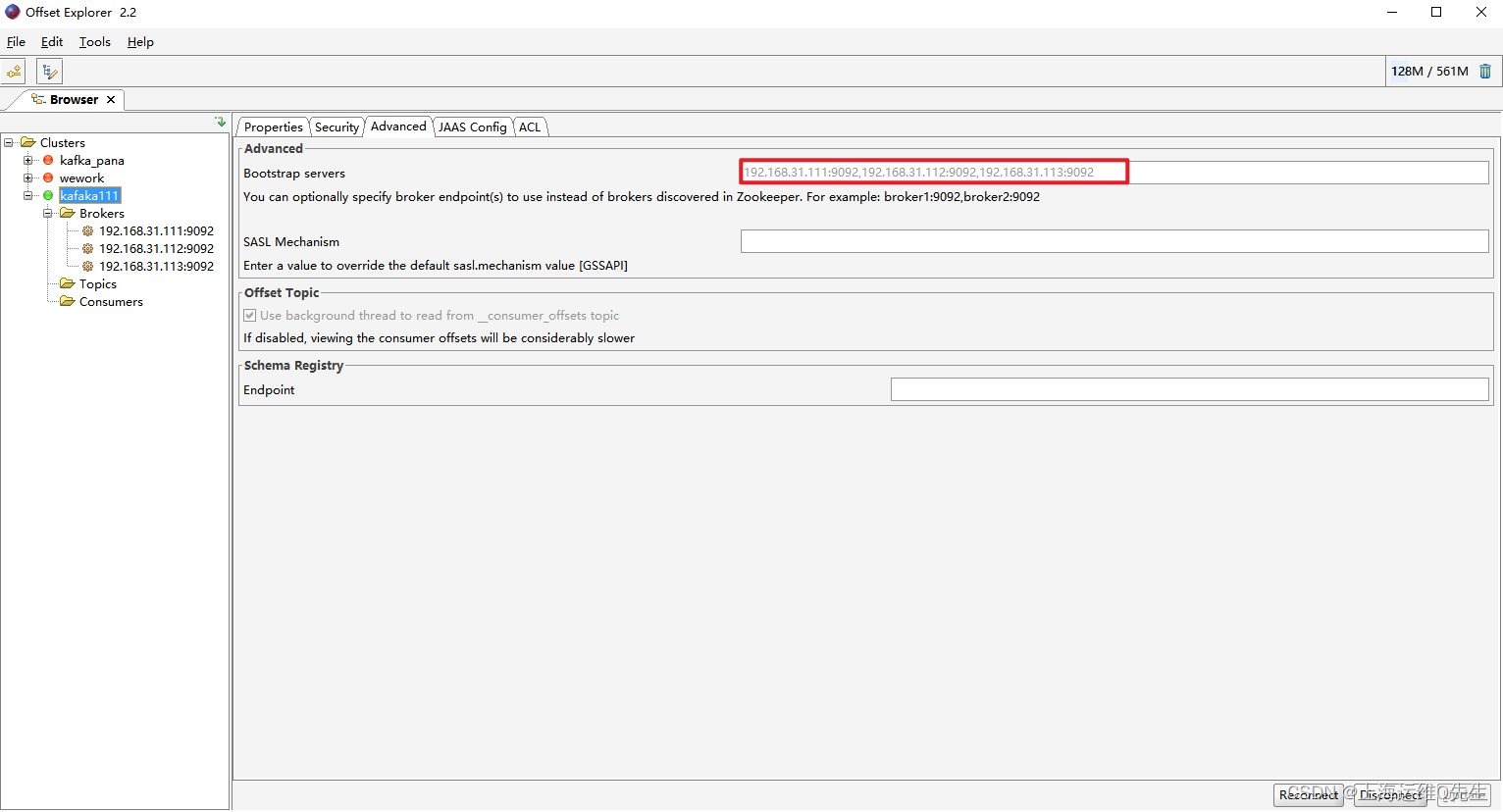
通过offset Explorer
4. Logstash安装
- 下载
logstash-7.12.1-amd64.deb
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/l/logstash/logstash-7.12.1-amd64.deb
- 安装
apt install openjdk-8-jdk -y
dpkg -i logstash-7.12.1-amd64.deb
- 配置修改
vi /etc/logstash/conf.d/daemonset-log-to-es.conf
input {
kafka {
bootstrap_servers => "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"
topics => ["jsonfile-log-topic"]
codec => "json"
}
}
output {
#if [fields][type] == "app1-access-log" {
if [type] == "jsonfile-daemonset-applog" {
elasticsearch {
hosts => ["192.168.31.101:9200","192.168.31.102:9200"]
index => "jsonfile-daemonset-applog-%{+YYYY.MM.dd}"
}}
if [type] == "jsonfile-daemonset-syslog" {
elasticsearch {
hosts => ["192.168.31.101:9200","192.168.31.102:9200"]
index => "jsonfile-daemonset-syslog-%{+YYYY.MM.dd}"
}}
}
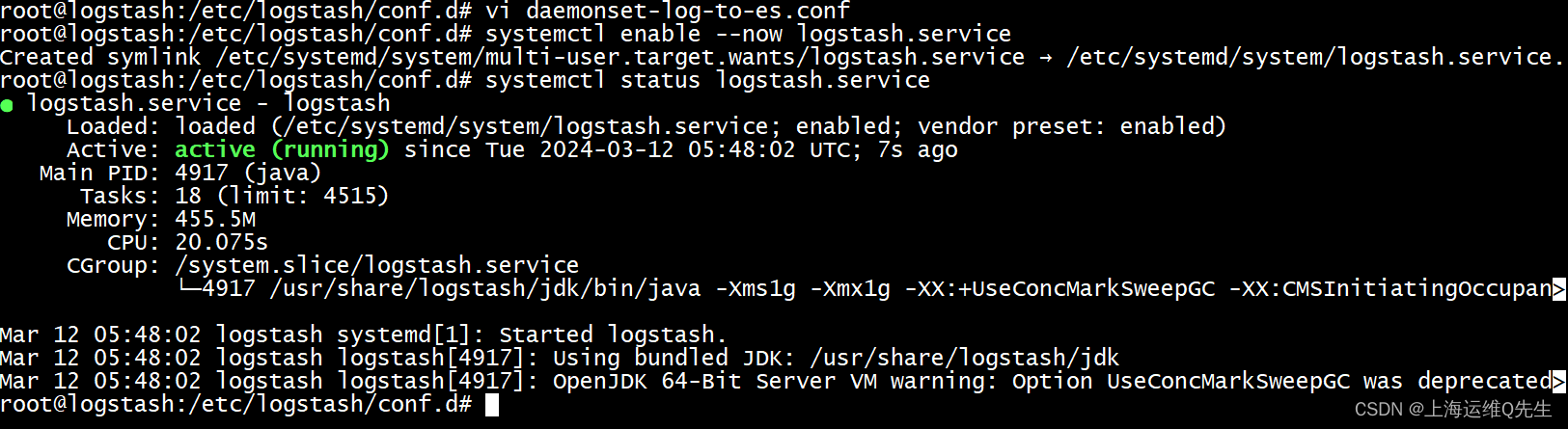
- 启动
systemctl enable --now logstash.service
- 测试
systemctl status logstash.service
5. DaemonSet
5.1 构建镜像
Dockerfile
FROM logstash:7.12.1
USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
logstash.conf
input {
file {
#path => "/var/lib/docker/containers/*/*-json.log" #docker
path => "/var/log/pods/*/*/*.log"
start_position => "beginning"
type => "jsonfile-daemonset-applog"
}
file {
path => "/var/log/*.log"
start_position => "beginning"
type => "jsonfile-daemonset-syslog"
}
}
output {
if [type] == "jsonfile-daemonset-applog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节
codec => "${CODEC}"
} }
if [type] == "jsonfile-daemonset-syslog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}" #系统日志不是json格式
}}
}
logstash.yml
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ]
构建镜像
nerdctl build -t harbor.panasonic.cn/baseimages/logstash:v7.12.1-json-file-log-v2 .
nerdctl push harbor.panasonic.cn/baseimages/logstash:v7.12.1-json-file-log-v2
5.2 DaemonSet
DaemonSet yaml文件
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: logstash-elasticsearch
namespace: kube-system
labels:
k8s-app: logstash-logging
spec:
selector:
matchLabels:
name: logstash-elasticsearch
template:
metadata:
labels:
name: logstash-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: logstash-elasticsearch
image: harbor.panasonic.cn/baseimages/logstash:v7.12.1-json-file-log-v1
env:
- name: "KAFKA_SERVER"
value: "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"
- name: "TOPIC_ID"
value: "jsonfile-log-topic"
- name: "CODEC"
value: "json"
# resources:
# limits:
# cpu: 1000m
# memory: 1024Mi
# requests:
# cpu: 500m
# memory: 1024Mi
volumeMounts:
- name: varlog #定义宿主机系统日志挂载路径
mountPath: /var/log #宿主机系统日志挂载点
- name: varlibdockercontainers #定义容器日志挂载路径,和logstash配置文件中的收集路径保持一直
#mountPath: /var/lib/docker/containers #docker挂载路径
mountPath: /var/log/pods #containerd挂载路径,此路径与logstash的日志收集路径必须一致
readOnly: false
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log #宿主机系统日志
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers #docker的宿主机日志路径
path: /var/log/pods #containerd的宿主机日志路径
部署
kubectl apply daemonset.yaml
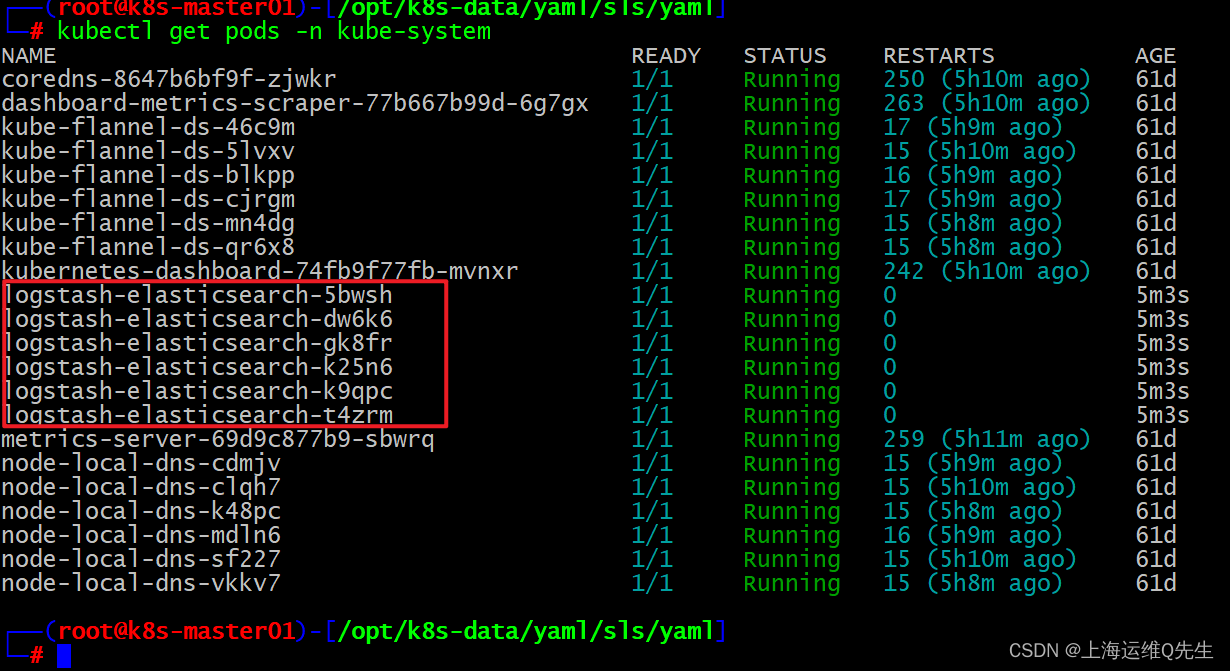
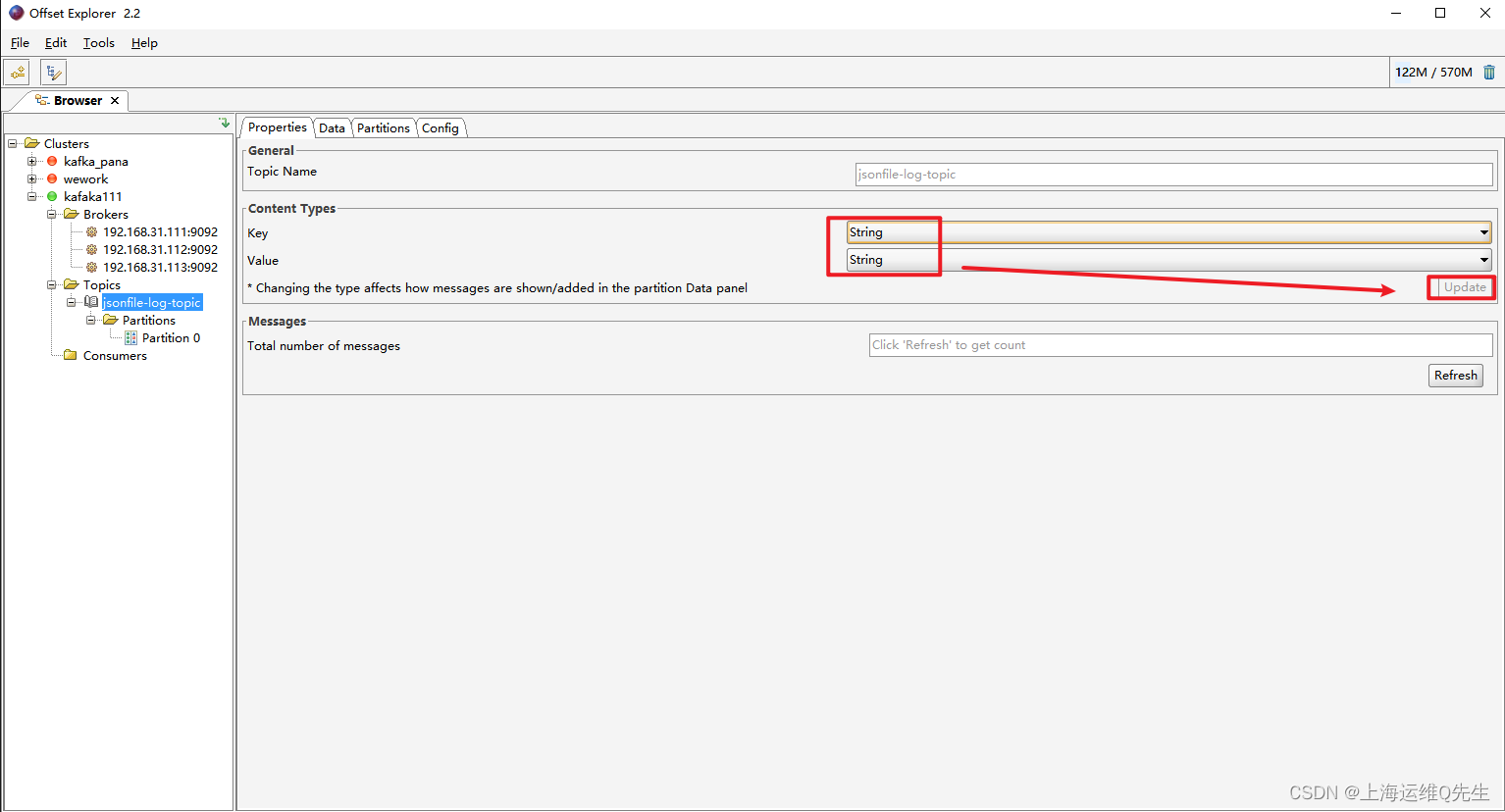
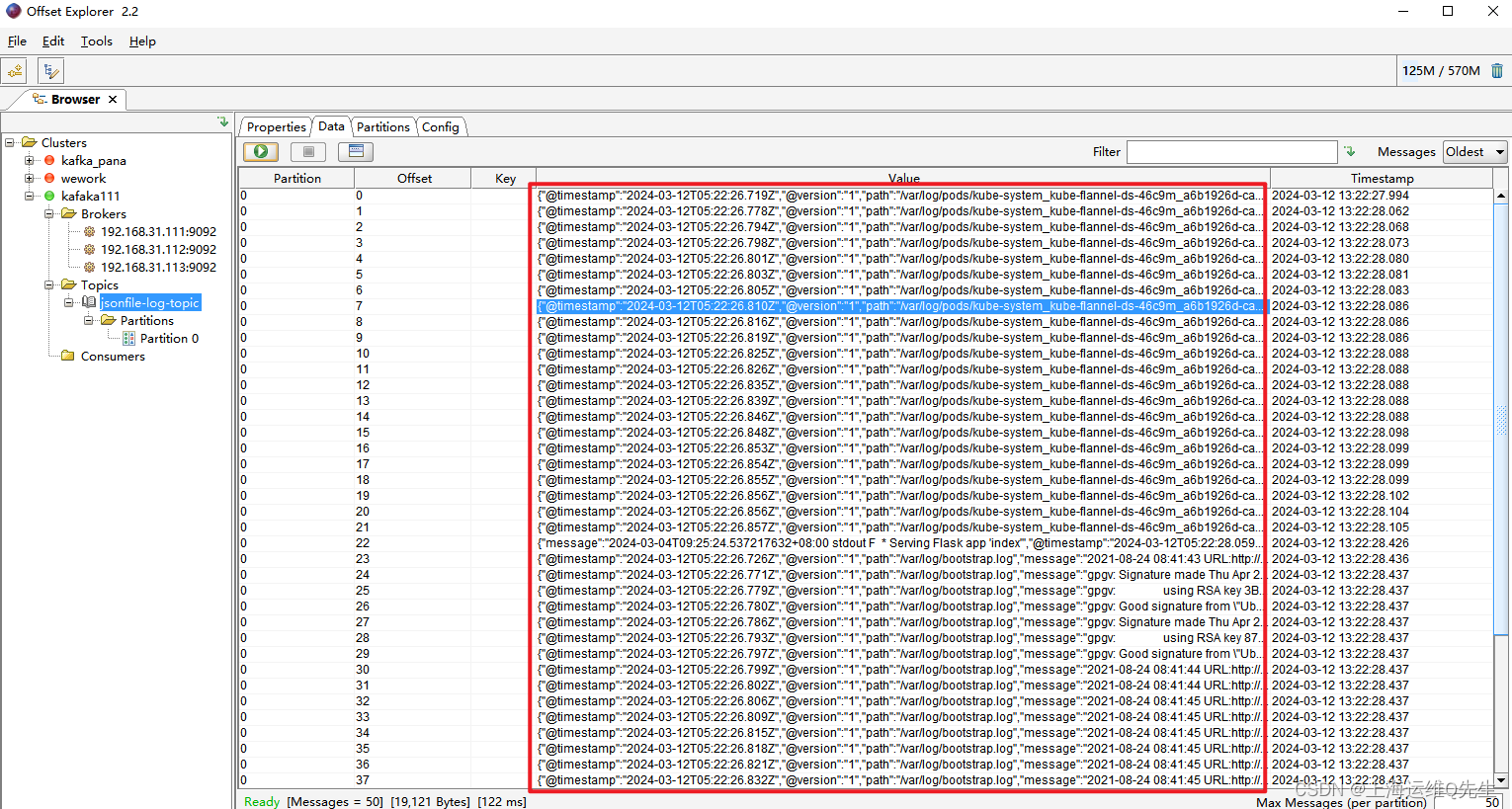
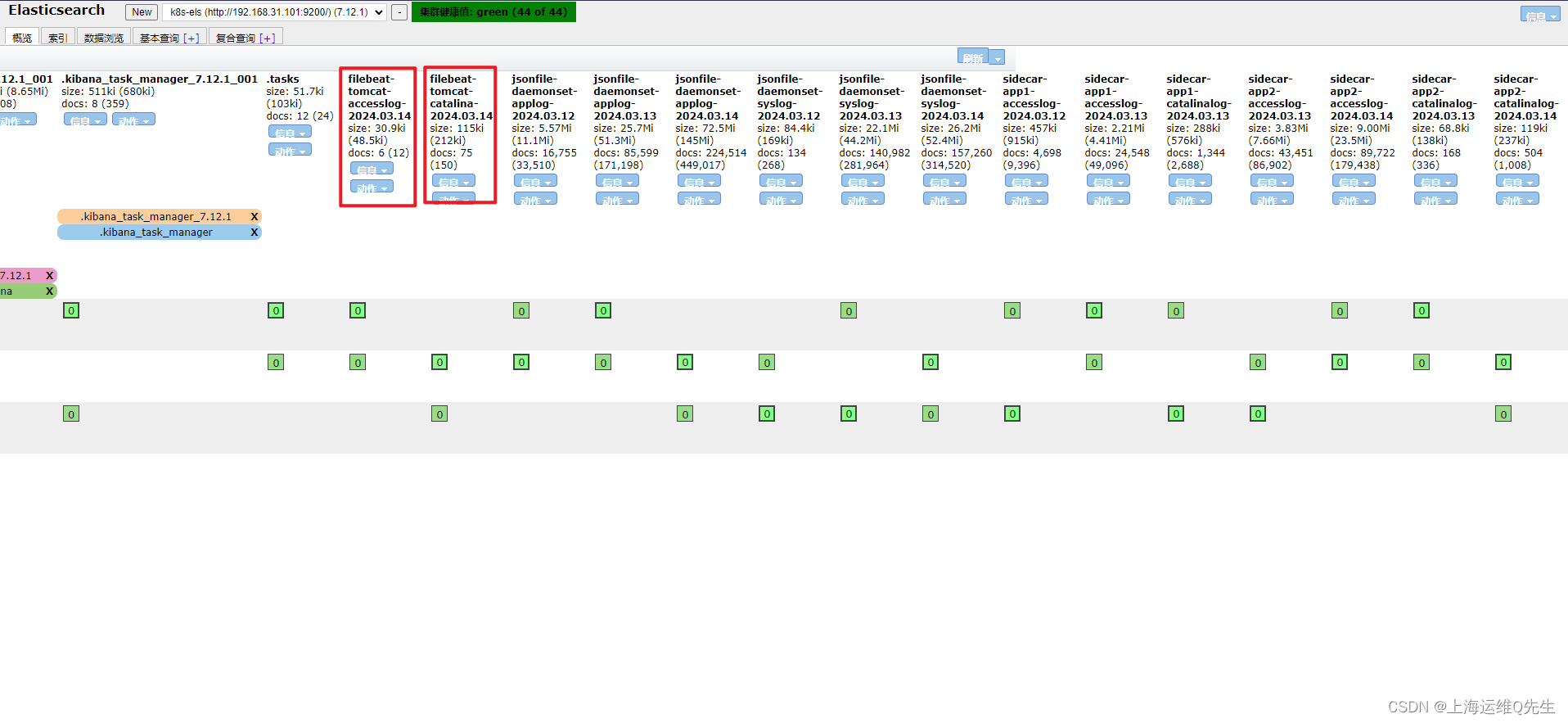
此时在Elasticsearch的dashboard上已经可以看到applog和syslog
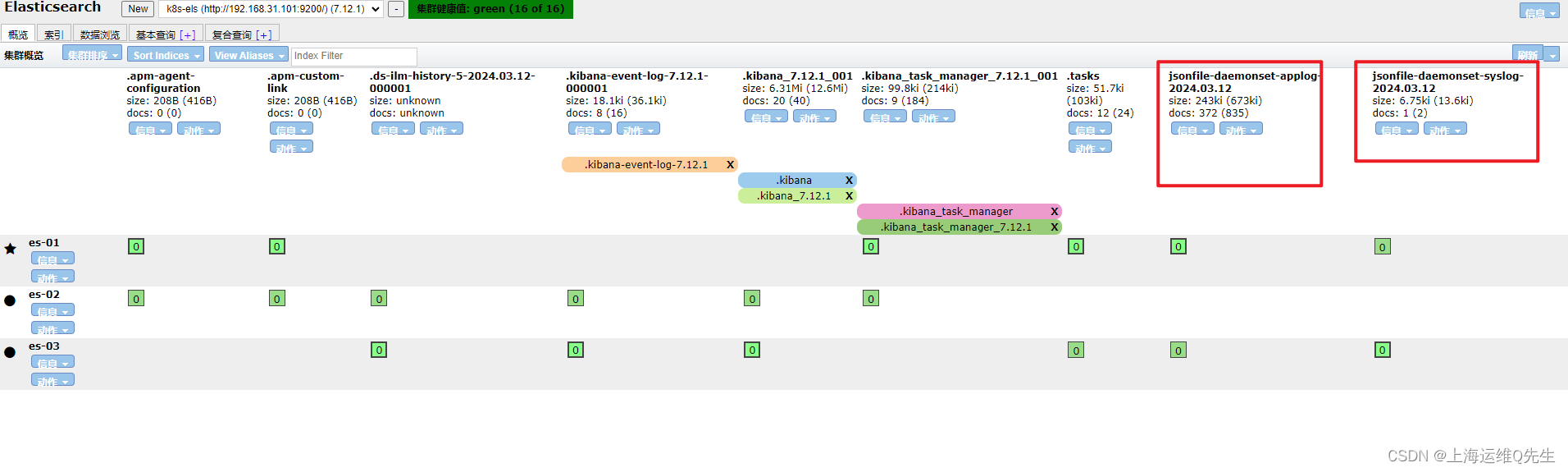
配置logstash服务器将日志从kafka抽到es上
vi /etc/logstash/conf.d/daemonset-log-to-es.conf
配置kafka地址和es地址
input {
kafka {
bootstrap_servers => "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"
topics => ["jsonfile-log-topic"]
codec => "json"
}
}
output {
#if [fields][type] == "app1-access-log" {
if [type] == "jsonfile-daemonset-applog" {
elasticsearch {
hosts => ["192.168.31.101:9200","192.168.31.102:9200"]
index => "jsonfile-daemonset-applog-%{+YYYY.MM.dd}"
}}
if [type] == "jsonfile-daemonset-syslog" {
elasticsearch {
hosts => ["192.168.31.101:9200","192.168.31.102:9200"]
index => "jsonfile-daemonset-syslog-%{+YYYY.MM.dd}"
}}
}
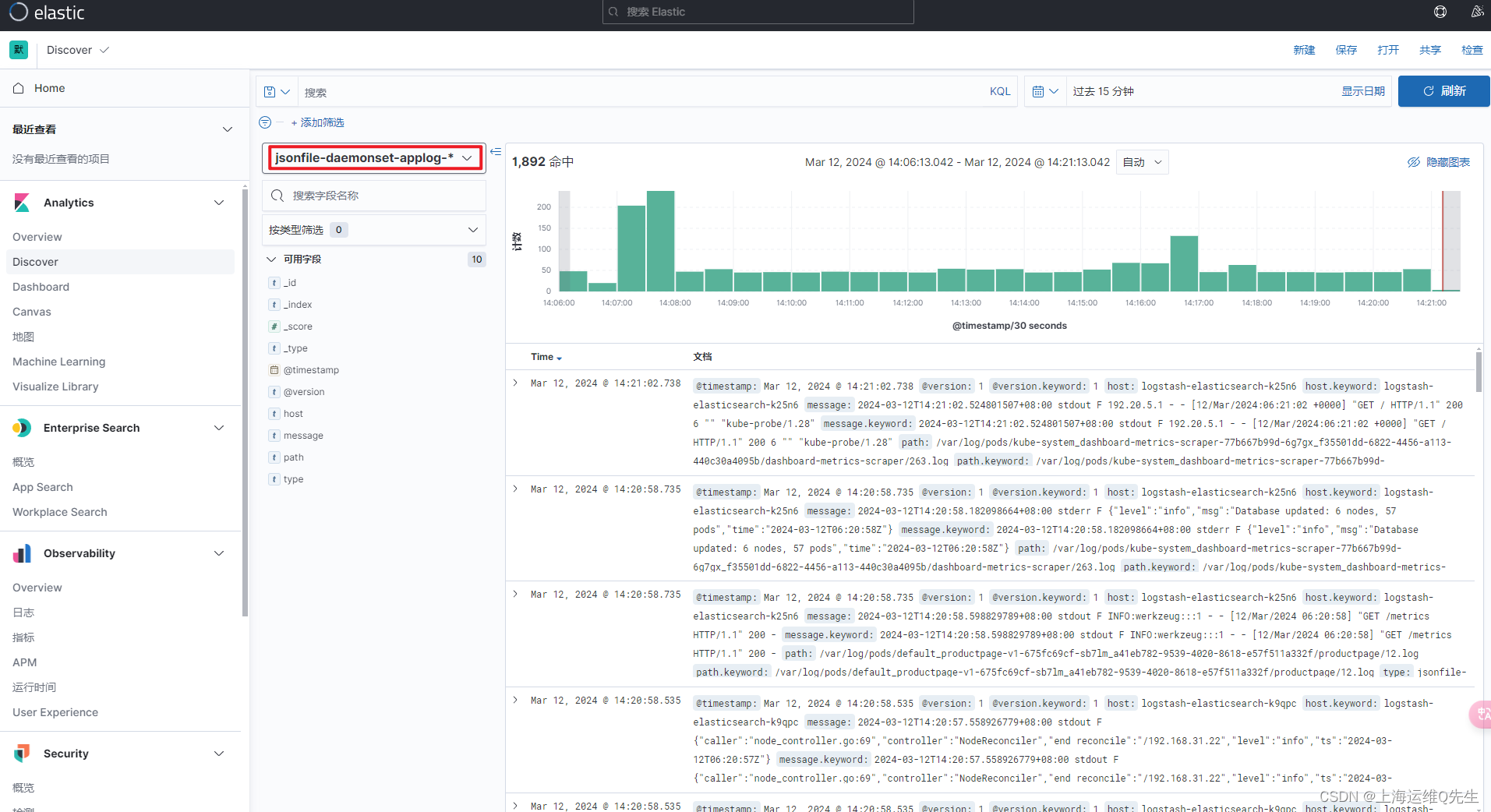
重启服务后可以在es服务器上看到相关数据
相关内容也符合我们的预期
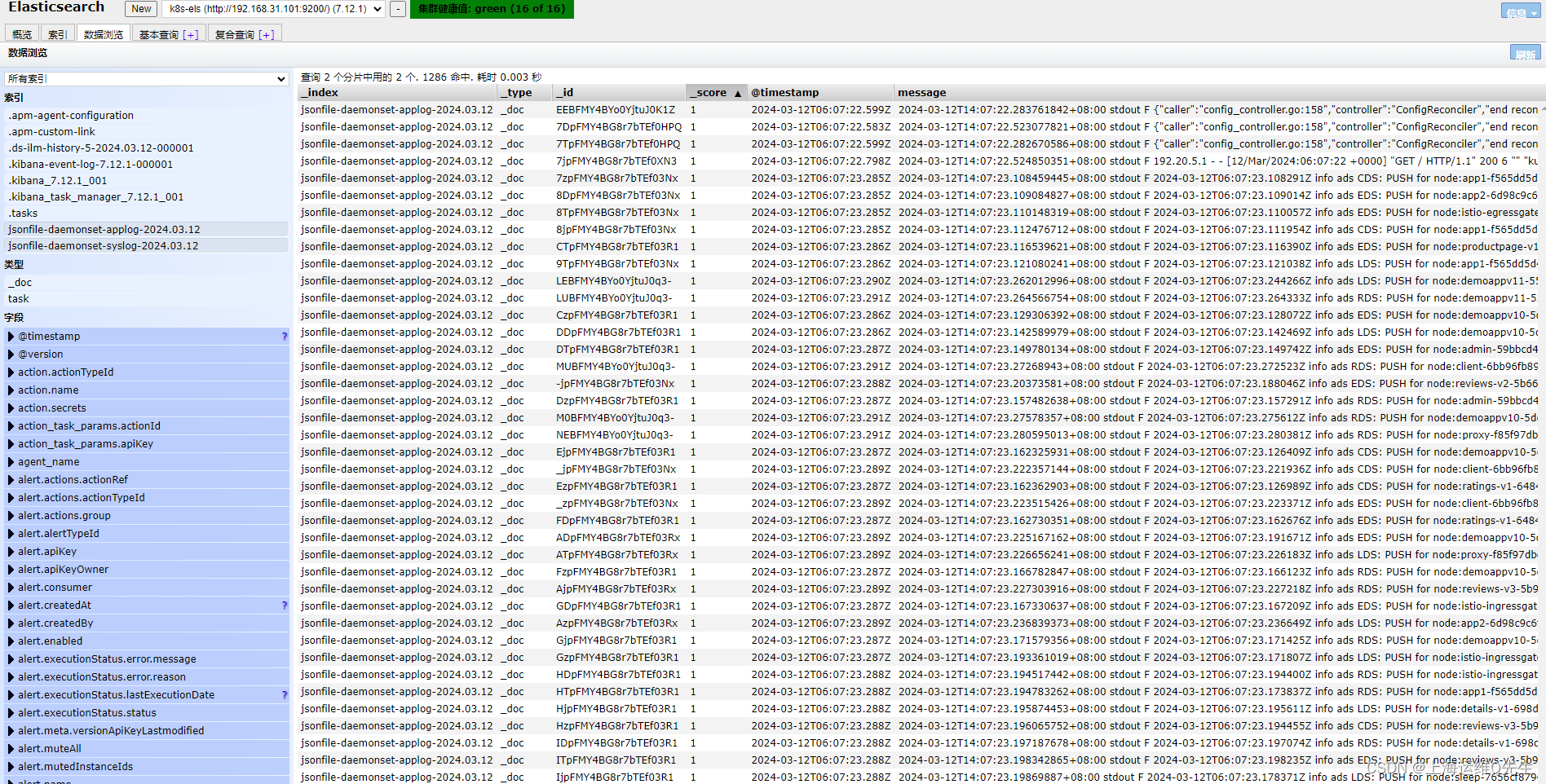
手动加入一段日志
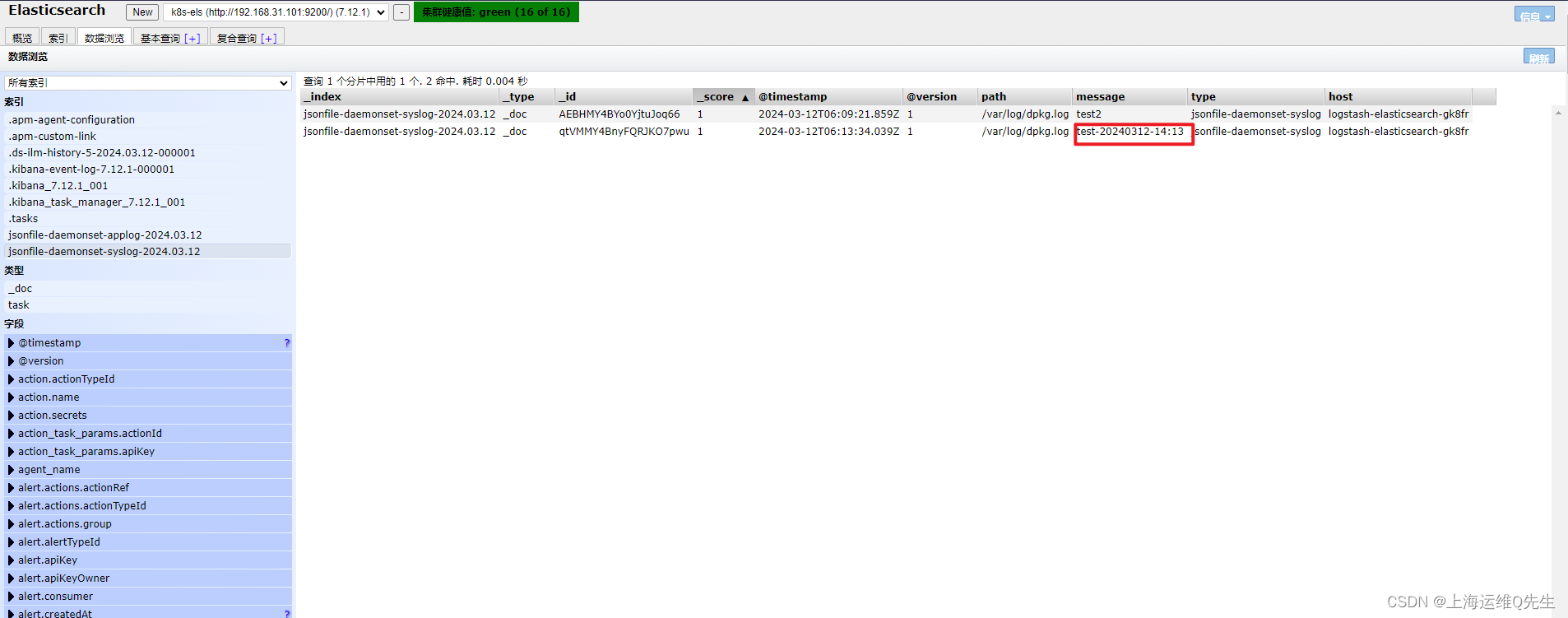
root@k8s-master01# echo 'test-20240312-14:13' >> /var/log/dpkg.log
日志也出现在els中
es服务器上创建syslog索引
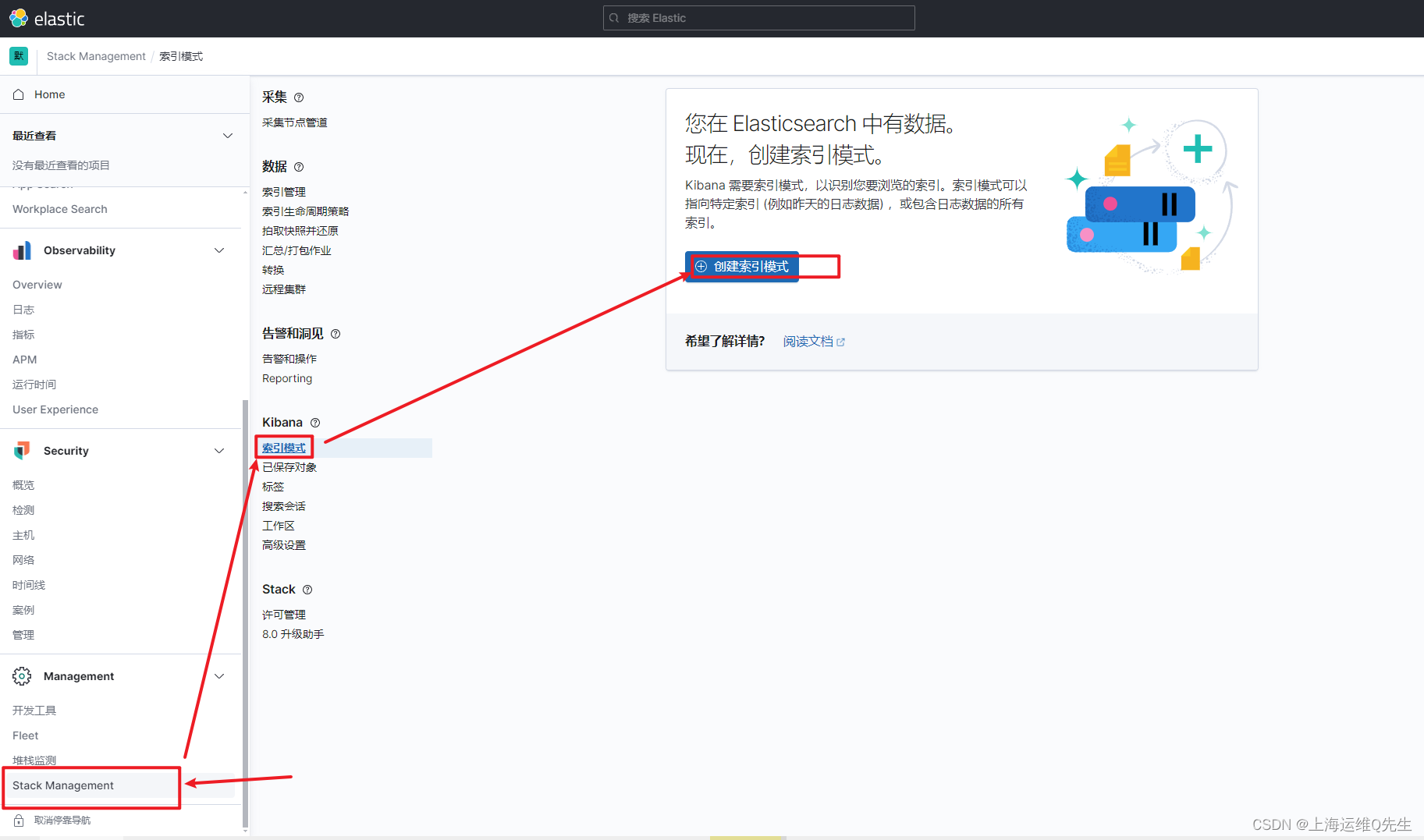
日志前缀加*匹配日志
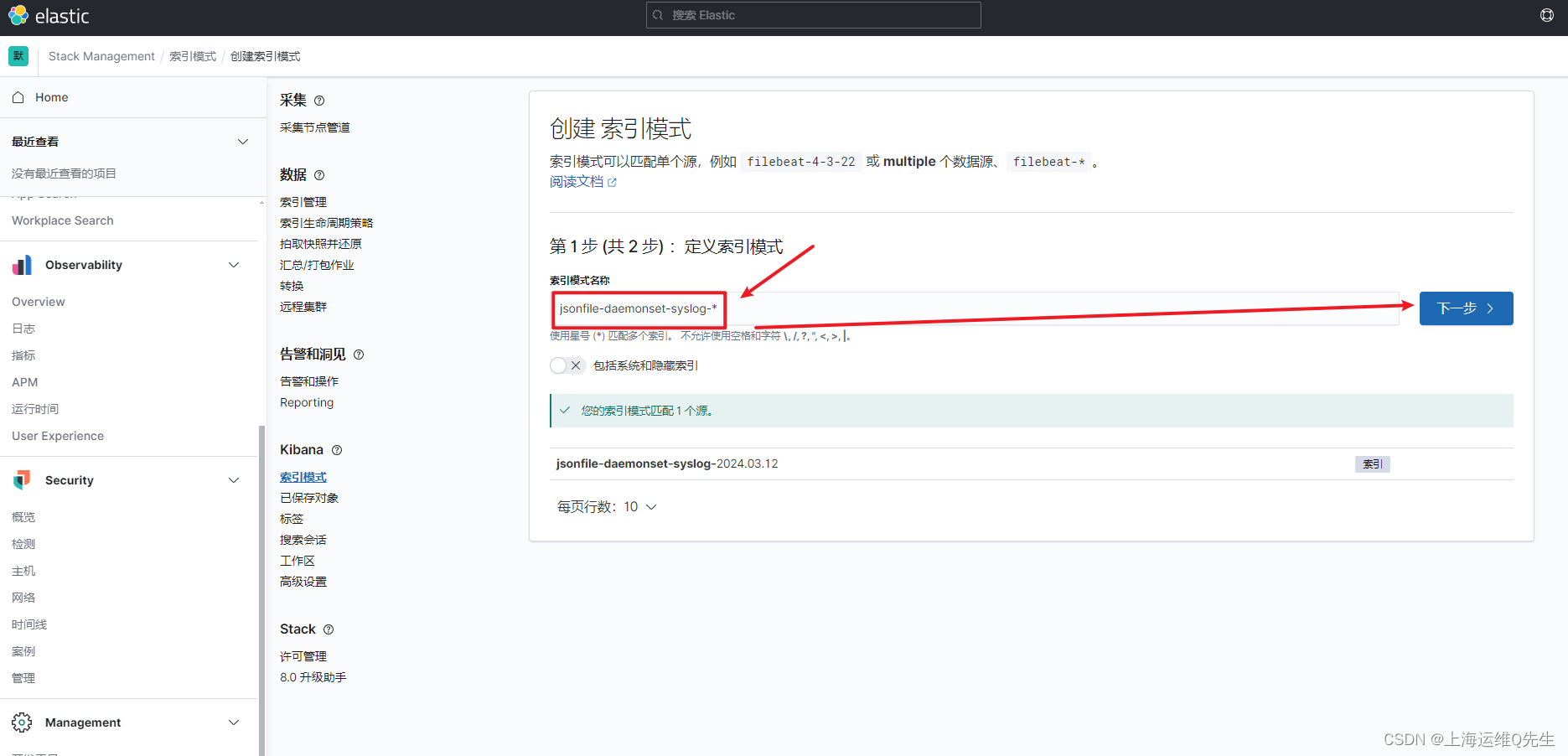
选择timestramp
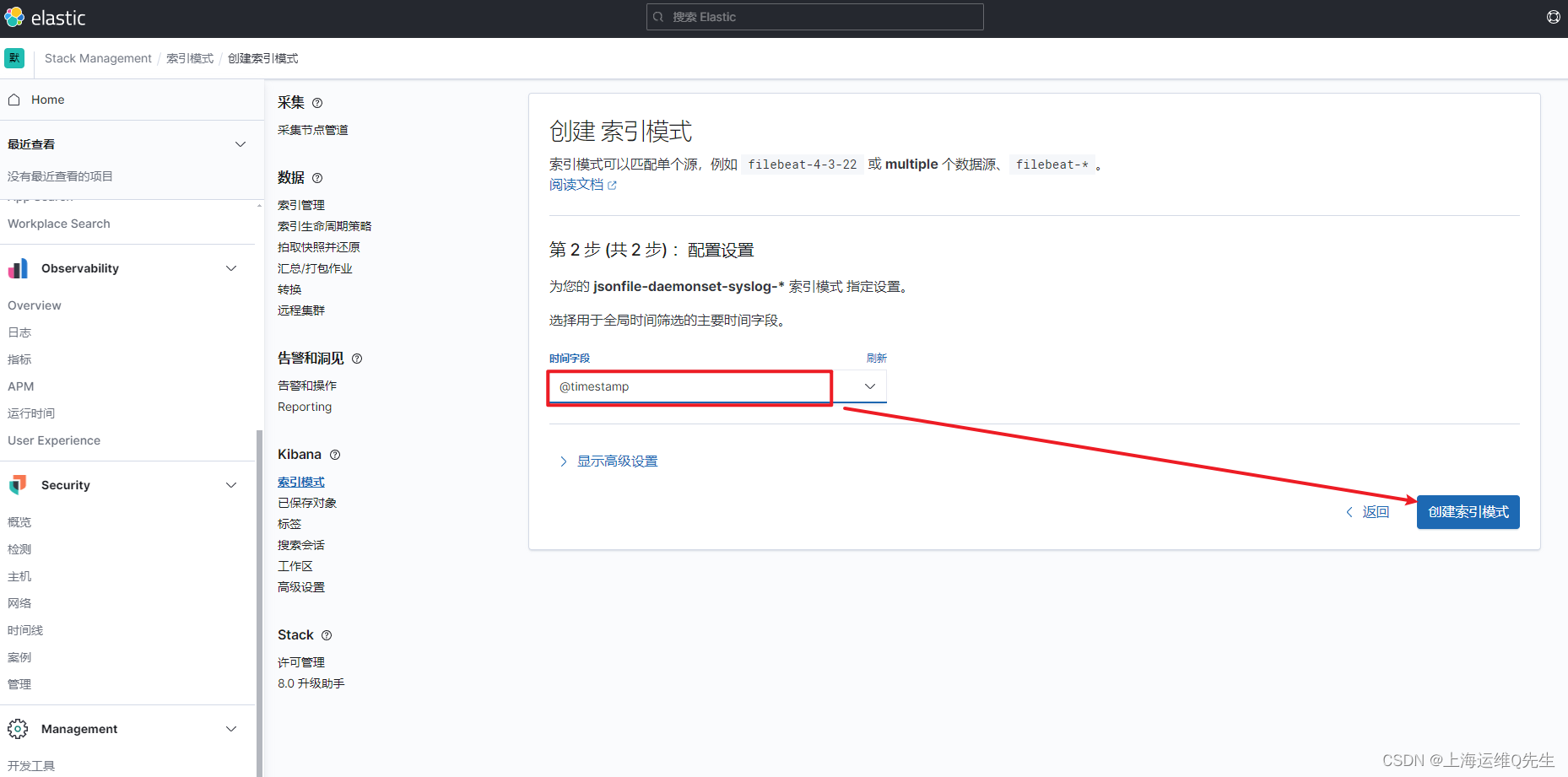
同样,再次创建applog
6. SideCar
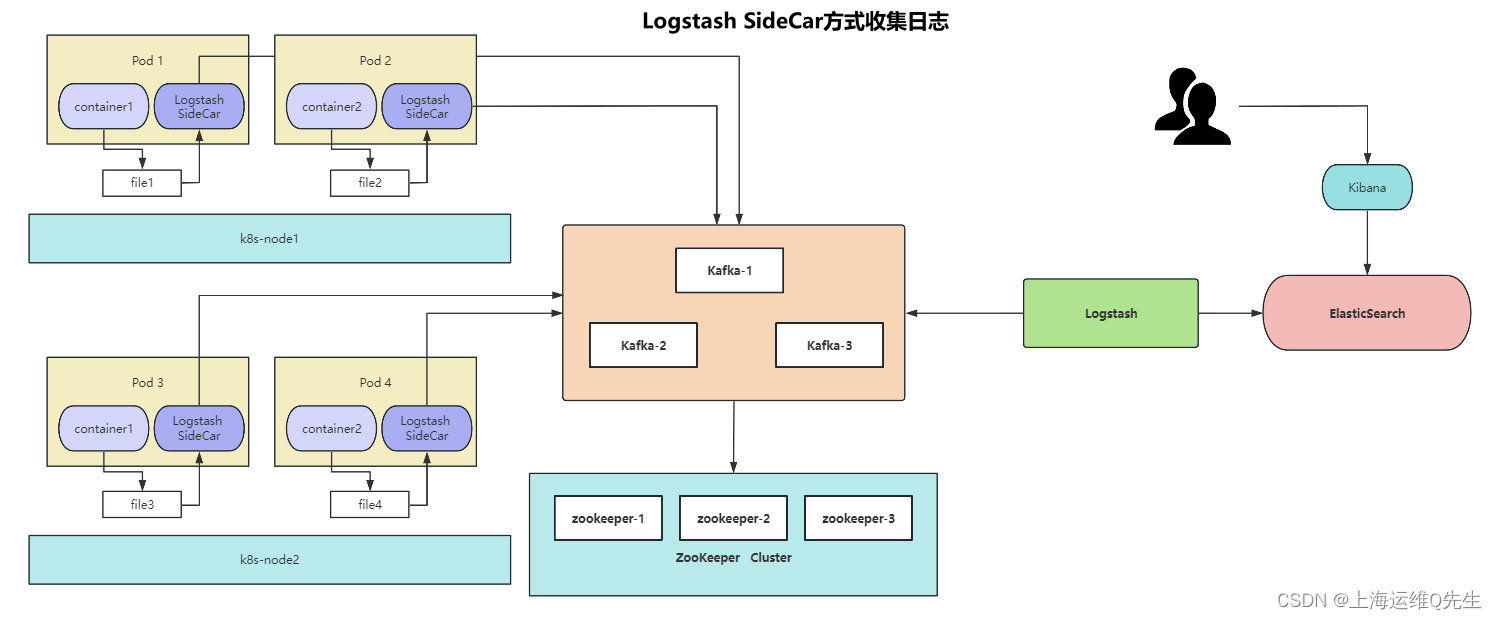
6.1 构建镜像
dockerfile
FROM logstash:7.12.1
USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
logstash.conf
input {
file {
path => "/var/log/applog/catalina.out"
start_position => "beginning"
type => "app1-sidecar-catalina-log"
}
file {
path => "/var/log/applog/localhost_access_log.*.txt"
start_position => "beginning"
type => "app1-sidecar-access-log"
}
}
output {
if [type] == "app1-sidecar-catalina-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节
codec => "${CODEC}"
} }
if [type] == "app1-sidecar-access-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}"
} }
}
logstash.yml
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200"
build-commond.sh
#!/bin/bash
#docker build -t harbor.magedu.local/baseimages/logstash:v7.12.1-sidecar .
#docker push harbor.magedu.local/baseimages/logstash:v7.12.1-sidecar
nerdctl build -t harbor.panasonic.cn/baseimages/logstash:v7.12.1-sidecar .
nerdctl push harbor.panasonic.cn/baseimages/logstash:v7.12.1-sidecar
6.2 SideCar
tomcat-app1.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: pana-tomcat-app1-deployment-label
name: pana-tomcat-app1-deployment #当前版本的deployment 名称
namespace: pana
spec:
replicas: 3
selector:
matchLabels:
app: pana-tomcat-app1-selector
template:
metadata:
labels:
app: pana-tomcat-app1-selector
spec:
containers:
- name: sidecar-container
image: harbor.panasonic.cn/baseimages/logstash:v7.12.1-sidecar
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
env:
- name: "KAFKA_SERVER"
value: "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"
- name: "TOPIC_ID"
value: "tomcat-app1-topic"
- name: "CODEC"
value: "json"
volumeMounts:
- name: applogs
mountPath: /var/log/applog
- name: pana-tomcat-app1-container
image: registry.cn-hangzhou.aliyuncs.com/zhangshijie/tomcat-app1:v1
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
volumeMounts:
- name: applogs
mountPath: /apps/tomcat/logs
startupProbe:
httpGet:
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5 #首次检测延迟5s
failureThreshold: 3 #从成功转为失败的次数
periodSeconds: 3 #探测间隔周期
readinessProbe:
httpGet:
#path: /monitor/monitor.html
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
livenessProbe:
httpGet:
#path: /monitor/monitor.html
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
volumes:
- name: applogs #定义通过emptyDir实现业务容器与sidecar容器的日志共享,以让sidecar收集业务容器中的日志
emptyDir: {}
tomcat-service.yaml
---
kind: Service
apiVersion: v1
metadata:
labels:
app: pana-tomcat-app1-service-label
name: pana-tomcat-app1-service
namespace: pana
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 40080
selector:
app: pana-tomcat-app1-selector
sidecar.conf
input {
kafka {
bootstrap_servers => "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"
topics => ["tomcat-app1-topic"]
codec => "json"
}
}
output {
#if [fields][type] == "app1-access-log" {
if [type] == "app1-sidecar-access-log" {
elasticsearch {
hosts => ["192.168.31.101:9200","192.168.31.102:9200"]
index => "sidecar-app1-accesslog-%{+YYYY.MM.dd}"
}
}
#if [fields][type] == "app1-catalina-log" {
if [type] == "app1-sidecar-catalina-log" {
elasticsearch {
hosts => ["192.168.31.101:9200","192.168.31.102:9200"]
index => "sidecar-app1-catalinalog-%{+YYYY.MM.dd}"
}
}
# stdout {
# codec => rubydebug
# }
}
7. 容器镜像中安装filebeat
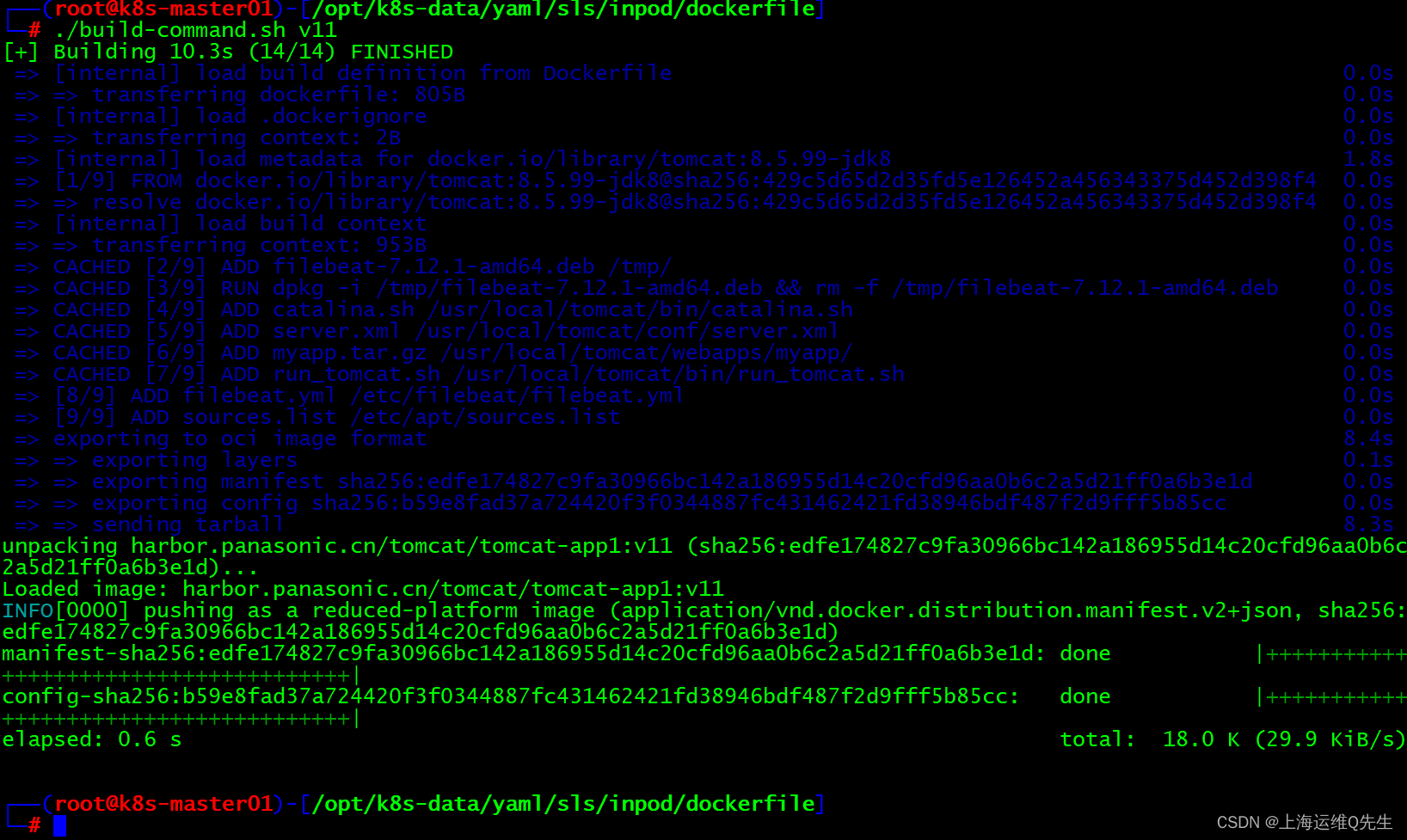
7.1 镜像制作
1.Dockerfile
filebeat-7.12.1-amd64.deb 从清华镜像源获取 https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/f/filebeat/
#tomcat web1
FROM tomcat:8.5.99-jdk8
ADD filebeat-7.12.1-amd64.deb /tmp/
RUN dpkg -i /tmp/filebeat-7.12.1-amd64.deb && rm -f /tmp/filebeat-7.12.1-amd64.deb
ADD catalina.sh /usr/local/tomcat/bin/catalina.sh
ADD server.xml /usr/local/tomcat/conf/server.xml
ADD myapp.tar.gz /usr/local/tomcat/webapps/myapp/
ADD run_tomcat.sh /usr/local/tomcat/bin/run_tomcat.sh
ADD filebeat.yml /etc/filebeat/filebeat.yml
ADD sources.list /etc/apt/sources.list
EXPOSE 8080 8443
CMD ["/usr/local/tomcat/bin/run_tomcat.sh"]
run_tomcat.sh
#!/bin/bash
/usr/share/filebeat/bin/filebeat -e -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat &
/usr/local/tomcat/bin/catalina.sh start
tail -f /etc/hosts
server.xml
<Host name="localhost" appBase="/usr/local/tomcat/webapps" unpackWARs="false" autoDeploy="false">
镜像制作
7.2 服务创建
- serviceaccount
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat-serviceaccount-clusterrole
labels:
k8s-app: filebeat-serviceaccount-clusterrole
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat-serviceaccount-clusterrolebinding
subjects:
- kind: ServiceAccount
name: default
namespace: pana
roleRef:
kind: ClusterRole
name: filebeat-serviceaccount-clusterrole
apiGroup: rbac.authorization.k8s.io
- deployment
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: pana-tomcat-app1-filebeat-deployment-label
name: pana-tomcat-app1-filebeat-deployment
namespace: pana
spec:
replicas: 2
selector:
matchLabels:
app: pana-tomcat-app1-filebeat-selector
template:
metadata:
labels:
app: pana-tomcat-app1-filebeat-selector
spec:
containers:
- name: pana-tomcat-app1-filebeat-container
image: harbor.panasonic.cn/tomcat/tomcat-app1:v11
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
- service
---
kind: Service
apiVersion: v1
metadata:
labels:
app: pana-tomcat-app1-filebeat-service-label
name: pana-tomcat-app1-filebeat-service
namespace: pana
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 30092
selector:
app: pana-tomcat-app1-filebeat-selector
kubectl apply -f *.yaml
7.3 logstash配置
input {
kafka {
bootstrap_servers => "192.168.31.111:9092,192.168.31.112:9092,192.168.31.113:9092"
topics => ["filebeat-tomcat-app1"]
codec => "json"
}
}
output {
if [fields][type] == "filebeat-tomcat-catalina" {
elasticsearch {
hosts => ["192.168.31.101:9200","192.168.31.102:9200"]
index => "filebeat-tomcat-catalina-%{+YYYY.MM.dd}"
}}
if [fields][type] == "filebeat-tomcat-accesslog" {
elasticsearch {
hosts => ["192.168.31.101:9200","192.168.31.102:9200"]
index => "filebeat-tomcat-accesslog-%{+YYYY.MM.dd}"
}}
}
重启logstash服务
systemctl restart logstash
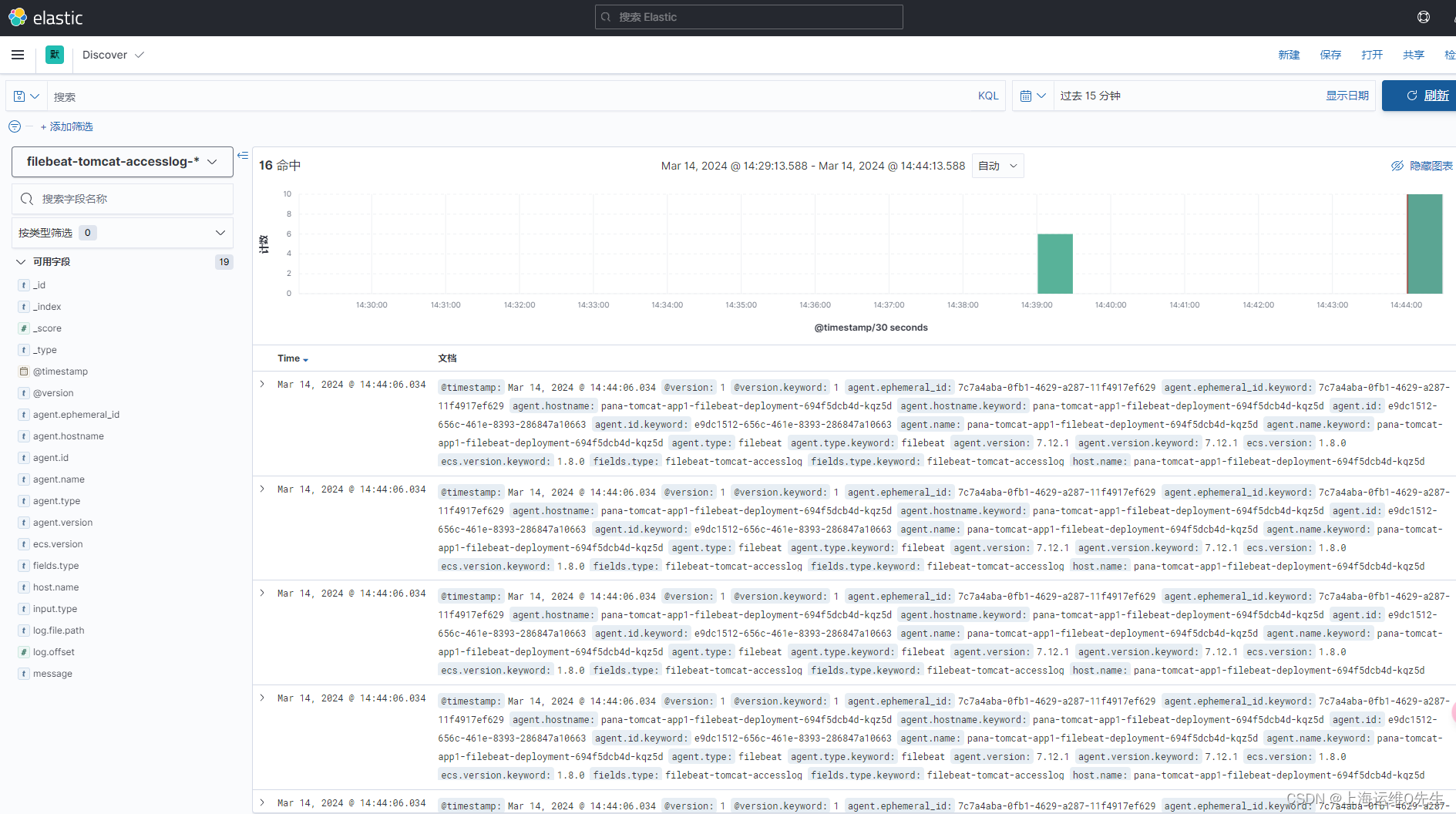
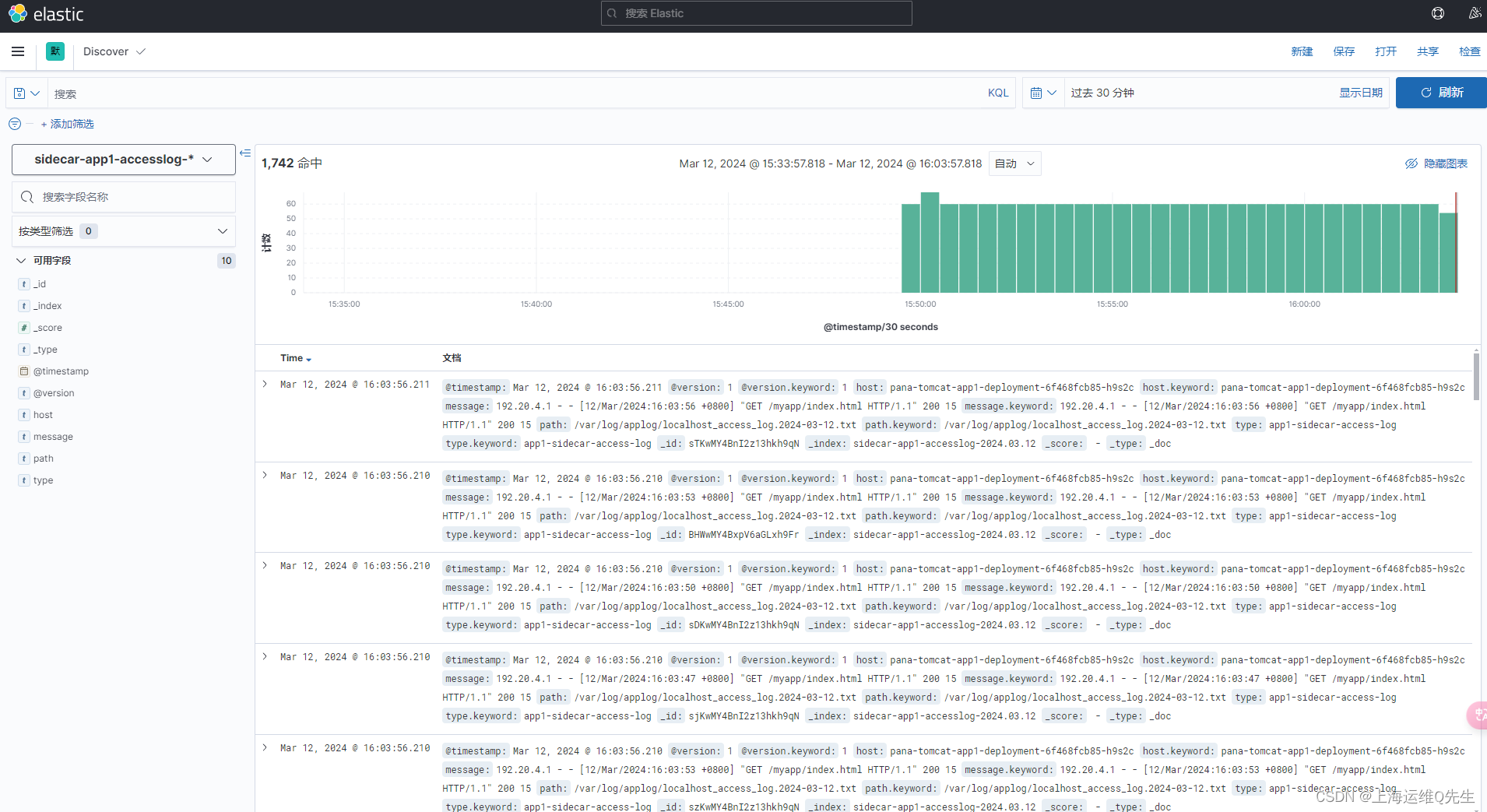
7.4 sls日志查询