文章目录
- 一、论文关键信息
- 二、基础概念
- 三、主要内容
- 1. Motivations
- 2. Insights
- 3. 解决方案的关键
- 4. 实验
- 四、总结与讨论
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、论文关键信息
论文标题:Retrieval-augmented GPT-3.5-based Text-to-SQL Framework with Sample-aware Prompting and Dynamic Revision Chain
会议信息:2023 ICONIP(CCF C)
论文地址:https://arxiv.org/abs/2307.05074
作者团队:Chunxi Guo, Zhiliang Tian, Jintao Tang, Shasha Li, Zhihua Wen, Kaixuan Wang and Ting Wang.
作者单位:国防科技大学计算机学院
👨💻 代码地址:暂无
关键词:大语言模型、Text-to-SQL、提示工程
🚀 一段话总结:基于检索增强 GPT-3.5 的 Text-to-SQL 框架,该方法结合了样本感知提示、动态修订链和检索增强技术来处理 SQL 语法要求的挑战。
Text-to-SQL 旨在针对给定的自然语言问题生成 SQL 查询,从而帮助用户查询数据库。使用大语言模型(LLMs)进行提示学习是最近出现的一种方法,它设计提示来引导 LLMs 理解输入问题并生成相应的 SQL。然而,它面临着严格的 SQL 语法要求的挑战。现有的工作用一系列演示示例(即 question-SQL 对)提示 LLMs 生成 SQL,但静态提示很难泛化到检索到的演示与输入问题之间语义差距较大的情况。这项研究提出了一种基于 LLM 的文本到 SQL 框架的检索增强提示方法,涉及样本感知提示和动态修订链。该方法结合了样本感知演示,其中包括 SQL 运算符的组成以及与给定问题相关的细粒度信息。为了检索与输入问题意图相似的问题,作者提出了两种辅助检索策略。首先,他们利用 LLM 来简化原始问题,统一语法,从而明确用户的意图。为了在无需人工干预的情况下生成可执行且准确的 SQL,设计了一个动态修订链,它迭代地适应先前生成的 SQL 的细粒度反馈。在三个文本到 SQL 基准测试上的实验结果表明,提出的方法优于强基线模型。

二、基础概念
Text-to-SQL:
Text-to-SQL(文本到 SQL)是一种自然语言处理(NLP)任务,旨在将自然语言查询转换为结构化查询语言(SQL)语句。这种技术使得非技术用户能够通过使用他们日常的自然语言来查询和操作数据库,而无需了解复杂的 SQL 语法。
在 Text-to-SQL 任务中,人工智能系统需要理解输入的自然语言文本,并将其映射到相应的 SQL 语句。这个过程通常包括以下几个步骤:
- 语义解析:首先,AI 系统需要对输入的自然语言文本进行语义解析,以识别关键词、实体、属性和关系。这有助于系统理解用户的查询意图。
- 数据库架构匹配:接下来,AI 系统需要将解析出的实体和属性与数据库架构中的表和列进行匹配。这一步骤确保生成的SQL语句与目标数据库的结构相符。
- SQL 生成:最后,AI 系统需要根据解析出的信息和数据库架构生成相应的SQL语句。这可能涉及到选择合适的SQL操作(如 SELECT、INSERT、UPDATE 或 DELETE),以及构建正确的条件子句和连接子句。
Text-to-SQL 任务的挑战之一是处理多种多样的自然语言表达方式。用户可能会用不同的词汇和语法结构来表达相同的查询意图。此外,处理模糊或不完整的查询也是一个关键问题,因为用户可能没有提供足够的信息来生成准确的 SQL 语句。为了解决这些挑战,研究人员通常采用深度学习方法,如循环神经网络(RNN)、长短时记忆网络(LSTM)和 Transformer 架构。这些模型可以在大量的自然语言查询和对应的 SQL 语句上进行训练,从而学会理解和生成复杂的语言结构。
大语言模型的检索增强生成:
检索增强生成(Retrieval Augmented Generation,RAG)是一种结合了信息检索和生成模型的混合框架,用于生成文本回复。RAG 的核心思想是在大语言模型(Large Language Model,LLM)的基础上,添加一个信息检索系统,以提供生成回复所需的数据。这种框架的引入使得我们能够在生成回复时对使用的数据进行控制。RAG 的应用在自然语言处理(Natural Language Processing,NLP)领域具有重要意义。它能够生成既具有上下文准确性又富含信息的文本。通过将信息检索模型和生成模型结合起来,RAG 在 NLP 中具有革命性的作用。RAG 的架构通常使用大型的自回归语言模型(Autoregressive Language Model),并且采用 Decoder-only 的架构。这是因为自回归模型对生成任务更加友好,能够利用上文信息。此外,大型语言模型的参数规模需要超过 13B 才能具备较强的生成能力。
在大语言模型(ChatGPT、GPT-4、LLaMA 等)应用落地中,利用【外挂】知识库进行上下文检索增强(In-Context Retrieval-Augmented )来进一步提升 LLMs 的效果,这一策略被越来越多的研究人员认可。该策略带来的好处有:
- 让大模型获取更多的知识,尤其最新的信息,而大模型是无法记住所有的知识;
- 缓解大模型存在的幻觉问题(类似一本正经的胡说八道),提供外挂信息,可让大模型的输出更有据可循;例如在利用 LLMs 做事件点评时,嵌入事件之间的因果逻辑,能让大模型输出的结果合理性更强;
- 很多开源的大模型都是通用型的,结合领域专门的外挂知识库,能让这类大模型在领域问题表现的更好,这也是低成本应用大模型的一种好策略。
RAG 的目标是提高生成模型的上下文准确性和信息丰富性。通过引入信息检索系统,RAG 可以从外部知识库中检索事实,以确保生成的文本基于最准确和最新的信息。这种结合了检索模型和生成模型的方法在 NLP 领域具有重要意义。RAG 的应用场景包括开放域问答、对话系统、摘要生成等任务。通过使用 RAG,研究人员和工程师可以快速开发和部署适用于知识密集型任务的解决方案。
三、主要内容
1. Motivations
解决什么问题?做这个事儿的意义、挑战?
- 解决什么问题? → \rightarrow → 针对给定的自然语言问题生成 SQL 查询
- 做这个事儿的意义? → \rightarrow → 就 Text-to-SQL 这个任务而言,其目的是将自然语言问题转换为可执行的 SQL 查询,用于为关系数据库提供用户友好界面,并使数据管理的各个环节受益,如数据库的可访问性、网站设计的灵活性等。
- 做这个事儿的挑战? → \rightarrow → 严格的 SQL 语法、检索到的演示与输入问题之间语义差距较大
已有的方法不足:
- 端到端训练的 encoder-decoder 架构的神经网络需要多样化和广泛的训练数据来训练模型,这是非常昂贵的。这样的方法还容易过拟合,泛化性能不佳。
- 使用特定的提示或指令来驱动 LLMs 生成所需的回应(提示学习),Rajkumar 等人和 Liu 等人评估了文本到 SQL 任务的几个提示学习基线。他们的研究结果表明,尽管 LLMs 生成文本序列是很自然的,但由于 SQL 的严格语法要求,生成 SQL 仍然是一个挑战。
- 受少样本学习的启发,现有工作采用一系列演示示例(即 question-SQL 对)来提示 LLMs 生成 SQL 查询。然而,他们通常依靠体力劳动来创建针对特定任务的静态演示示例。DIN-SQL 从每个类别中选择预定义的样本,Self-Debugging 向 LLM 解释代码,但没有解释演示。这些方法采用静态演示,这意味着提供给 LLMs 的演示示例是固定的,不会在不同的示例中进行调整或更改。这些静态演示示例很难适应检索到的演示与输入问题之间的语义差距较大的场景,这被称为检索偏差,通常出现在检索增强生成中。
2. Insights
为了解决前面提到的问题,作者提出了基于检索增强的 GPT-3.5 的文本到 SQL 框架,具有样本感知提示和动态修订链。
🔎 洞察在于,受 Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? 的启发,作者认为提供动态演示可以适应 SQL 生成的特定样本和模式。动态示例使 SQL 生成能够适应各种场景。通过根据特定实例进行调整,可以对演示进行定制,以包含必要的查询结构、逻辑操作和问题语义。这种适应性有助于生成适用于不同情况的相关 SQL。
3. 解决方案的关键
为基于 LLM 的文本到 SQL 模型提出了检索增强提示,该模型包含样本感知提示和动态修订链。具体来说:
- 建议检索类似的 SQL 查询,以使用示例感知的演示示例构建提示。请注意,用户经常用不同的表达式提问,即使他们有相同的意图和 SQL 查询。这使得模型很难检索到有用的示例。为了解决这个问题,通过两种策略提取问题的真实意图:首先,通过 LLM 简化原始问题,以明晰用户的意图并统一检索语法。其次,提取问题骨架来检索具有相似问题意图的项目。
- 为了生成可执行且准确的 SQL,设计了一个动态修订链,通过根据先前版本生成的 SQL 迭代适应细粒度反馈来生成 SQL 查询。反馈包括 SQL 执行结果、SQL 解释以及相关的数据库内容。这个动态链通过语言模型和数据库之间的自动交互,在没有人为干预的情况下,能够生成可执行且准确的 SQL。
提出的框架由两个模块组成,如下图所示:
-
检索库:构建了一个添加了简化问题的检索存储库,然后使用问题骨架来检索样本感知的 SQL 演示示例。
-
动态修订链:通过添加细粒度反馈来进一步修订生成的 SQL 查询。
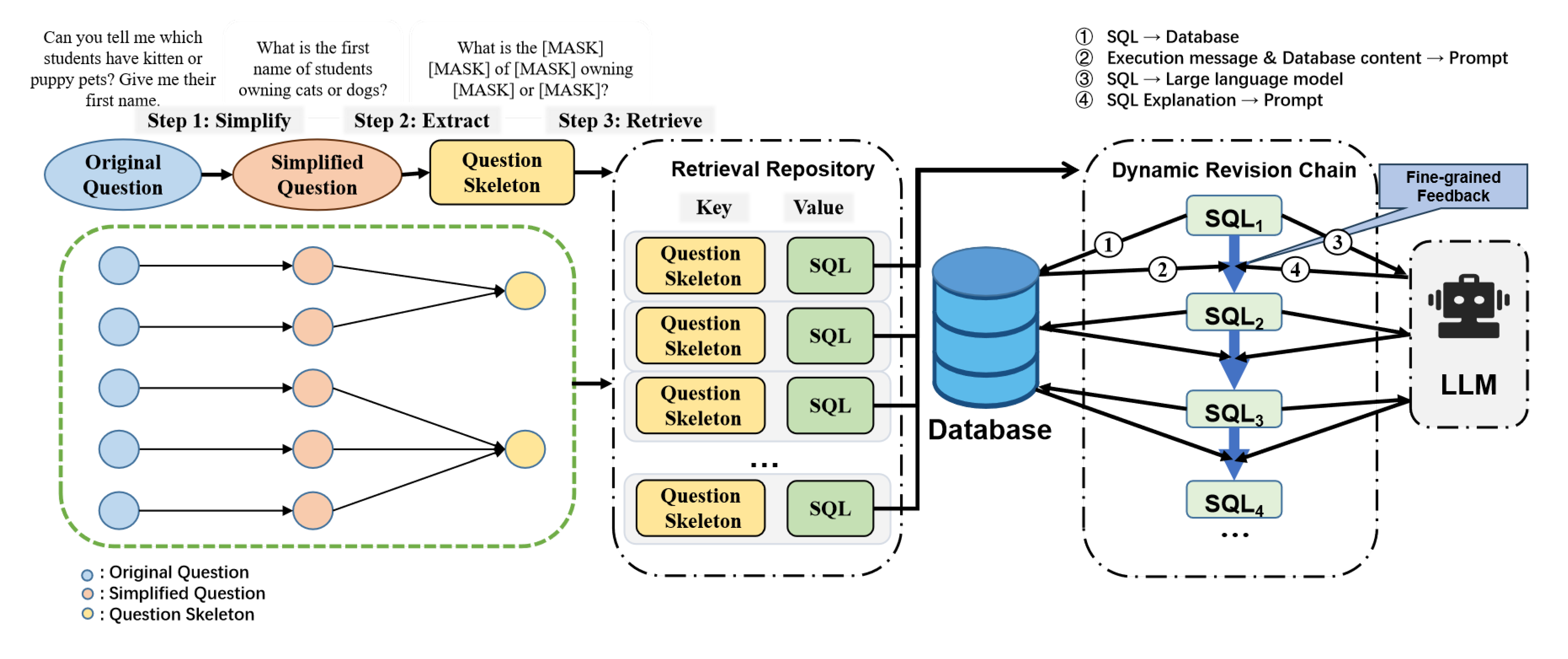
框架概述:左半部分显示了分三个步骤构建检索库。前三句分别是三个具体的例子。绿色虚线框显示训练集。右半部分是一个动态修订链,将 LLM 迭代生成的 SQL 查询作为节点(绿色框)。步骤 2 和 4 的输出统称为细粒度反馈。
为基于 LLM 的文本到 SQL 模型提出了检索增强提示。通过使用示例感知提示和动态修订链,解决了检索有用示例和基于细粒度反馈调整生成的 SQL 的挑战。在三个文本到 SQL 基准测试上的实验结果证明了方法的有效性。
4. 实验
论文中使用了三个 Text-to-SQL 基准测试数据集进行定量评估,分别是 Spider、Spider-Syn 和 Spider-DK。其中,Spider 是一个跨领域的大规模基准测试,包含 138 个不同领域的数据库,而 Spider-Syn 和 Spider-DK 是基于 Spider 的变体数据集。
使用 FAISS 进行问题骨架的存储和高效检索,然后应用 Retrieval-augmented GPT-3.5-based Text-to-SQL 框架进行 SQL 查询生成。在生成 SQL 样本时,设置温度 τ = 0.5 \tau=0.5 τ=0.5。对于检索样本的数量,分别设置 k 1 = 4 k_{1}=4 k1=4 和 k 2 = 4 k_{2}=4 k2=4。在三个 Text-to-SQL 基准测试中,实验结果表明,该方法优于强基线模型。
四、总结与讨论
生成 SQL 查询是一个长期存在的问题,因为 SQL 查询需要遵循严格的语法规则,而自然语言问题通常不遵循这些规则。因此,这个问题一直存在,并且一直在研究中得到关注。这篇论文提出了一种新的方法来解决这个问题。
这项研究深入探索了 Text-to-SQL 任务,即将自然语言问题转换为 SQL 查询。传统方法使用固定提示和示例对大语言模型进行提示,但存在一些挑战。因此,这篇论文提出了一种检索增强的提示方法,包括样本感知提示和动态修订链,以提高生成 SQL 的准确性和可执行性。实验证明,该方法在三个基准数据集上优于现有模型。文章还讨论了该方法的普适性、问题简化的合理性、检索库的覆盖性、匹配准确性和扩展性。
论文中提出的解决方案的关键是结合了样本感知提示和检索增强技术的 Retrieval-augmented GPT-3.5-based Text-to-SQL 框架,以及动态修订链。其中,样本感知提示和检索增强技术用于处理 SQL 语法要求的挑战,动态修订链用于生成可执行和准确的 SQL 查询。
论文中的实验及结果很好地支持了需要验证的科学假设,即结合样本感知提示和检索增强技术的 Retrieval-augmented GPT-3.5-based Text-to-SQL 框架以及动态修订链可以生成可执行和准确的 SQL 查询。具体来说,论文中的实验结果表明,该方法在三个 Text-to-SQL 基准测试中优于强基线模型,证明了该方法的有效性。此外,论文还对该方法进行了详细的分析和讨论,进一步支持了该科学假设的正确性。
📚️ 相关工作:
- 基于编码器-解码器架构的 SQL 生成;
- 基于 LLMs 的 SQL 生成;
🚀 论文的主要贡献总结如下:
- 通过提示 LLMs 进行样本感知演示,开发了一个用于文本到 SQL 任务的检索增强框架。
- 提出了一个动态修订链,它可以通过细粒度的反馈来适应之前生成的 SQL。
- 三个 Text-to-SQL 基准测试的实验结果表明,论文提出的方法超越了强基线模型。
👀 可能的改进和进一步工作:
- 使用更先进的语言模型,如 GPT-4、Claude 3 Opus、Gemini Ultra 等,以进一步提高生成的 SQL 查询的准确性。
- 可以探索使用更有效的检索技术,如语义搜索或基于知识图谱的检索,以提高检索到的示例的质量。
- 结合强化学习,根据数据库的反馈进一步优化生成的 SQL 查询。
- 探索将该框架应用于其他相关任务,如自然语言数据库接口(NLIDB)或自然语言编程(NLP),以评估其在其他领域的泛化能力和有效性。
📚️ 参考链接:
- 也看大模型与数据库查询分析的落地结合:C3 Text2SQL 方案及 Data-Copilot 数据自动化编排机制的实现思想阅读
- 知乎 | 大模型(LLM) + 上下文检索增强
- 检索增强生成(RAG)
- RAG:使用检索增强生成构建特定行业的大型语言模型
- 论文领读 | 别再第四范式:看看新热点检索增强怎么做文本生成!
- Google 机器学习术语表