参考资料:python统计分析【托马斯】
也可查看:python统计分析——单变量描述统计-CSDN博客
当我们有一个来自分布的数据样本时,我们可以用不同的参数来描述分布中心。因此,数据可以用两种方式来评估:
(1)用它们的值;
(2)用他们的秩(即按大小排序时的列表编号)。
1、均值
默认来说,当我们讲到均值的时候,我们指的是算术均值
我们可以使用命令np.mean来找到数组x的均值。
现实生活中的数据通常包含缺失值,在许多情况下,缺失值用nan来代替(nan代表“非数字”,即not a number)。对于包括nan的数组的统计,numpy具有许多处理nan的函数。
import numpy as np
x=np.arange(10)
# 计算均值
np.mean(x)
# 在x数组中添加一个nan
xWithNan=np.hstack((x,np.nan))
xWithNan
当数组中有nan时,用np.nanmean()函数来计算数据均值。

2、中位数
中位数是当数据按顺序排序时中间的值。与均值不同,中位数不受离群数据点的影响。计算中位数的函数为np.median(),代码效果如下:
np.median(x)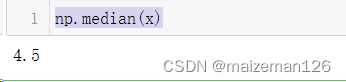
注意,如果像我们这个例子中一样,一个分布是对称的,那么它的均值和中位数会重合。
3、众数
众数是一个分布中出现最频繁的值。
找到众数最简单的方法是scipy.stats中对应的函数,它能够提供众数值和频数。函数为:scipy.stats.mode()。代码展示如下:
# 导入库
from scipy import stats
# 模拟数据
data=[1,3,4,4,7]
# 求众数
stats.mode(data)![]()
4、几何均值
在某些情况下,几何平均可以用来描述分布的位置。它可以通过计算每个值对数的算术平均数来得到。python中计算几何均值的函数为:scipy.stats.gmean()。代码展示如下:
# 模拟数据
x=np.arange(1,101)
# 计算几何均值
stats.gmean(x)
注意,计算几何均值的输入数字必须是正的。