文章目录
- 文件操作
- 文件编码
- 什么是编码
- 为什么要使用编码
- 文件的读取
- open
- model常用的三种基础访问模式
- 读操作相关方法
- 文件的写入
- 注意
- 代码示例
文件操作
文件编码
什么是编码
-
编码就是一种规则集合,记录了内容和二进制间进行互相转换的规则
-
最常用的是UTF-8编码
为什么要使用编码
-
计算机内部保存的都是0和1,所以需要将内容全部转换为0和1才能识别
-
读取时需要将计算机中保存的0和1转为内容
文件的读取
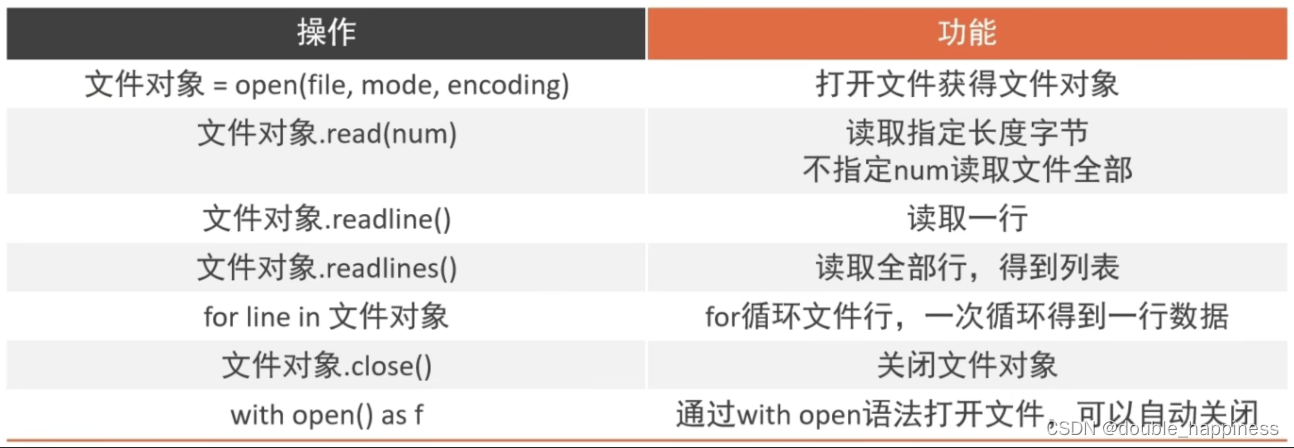
open
- 语法
open(name, mode, encoding)
name 要打开的目标文件名的字符串
mode 打开文件的模式:只读、写入、追加
encoding 编码格式,推荐使用UTF8
model常用的三种基础访问模式

读操作相关方法
- read方法
文件对象.read(num)
num 表示要从文件中读取的数据长度,单位是字节,如果没有传,读取文件中所有的数据
-
readlines():可以按照行的方式把整个文件的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
-
readline()读取文件的一行
-
for循环读取文件行
-
close()关闭文件对象
-
with open语法:用于打开文件并在使用完毕后自动关闭文件
- 代码示例
# *_*coding:utf-8 *_*
# 打开文件
f = open("./read_file.py", 'r', encoding="UTF-8")
# 读取文件
print(f'读取50个字节的结果{f.read(50)}')
# 在程序中多次调用read,下一次会从上一次读的偏移结尾继续读
print(f'读取全部字节的结果{f.read()}')
# readlines读取文件的全部行,封装到列表中
print(f'读取文件的全部行{f.readlines()}')
# readline一次读取文件一行
line1 = f.readline()
line2 = f.readline()
line3 = f.readline()
print(f'第一行数据是:{line1}')
print(f'第二行数据是:{line2}')
print(f'第三行数据是:{line3}')
# 关闭文件
f.close()
# for循环读取文件行
for line in open("./read_file.py", "r"):
print(line)
# with open语法
with open("./read_file.py", "r", encoding="UTF-8") as f:
print(f'{f.readlines()}')
文件的写入
注意
-
直接调用write方法,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
-
当调用flush的时候,内容会真正写入文件
-
目的:避免频繁磁盘操作,导致效率下降
-
close方法内置了flush功能
-
w模式
-
文件不存在则创建
-
文件存在则清空
-
-
a模式
-
文件不存在则创建
-
文件存在则追加尾部写
-
代码示例
# *_*coding:utf-8 *_*
# open打开文件,使用覆盖写操作
f = open("test.txt", "w", encoding="UTF-8")
# write写入
f.write("123456789")
# flush刷新
f.flush()
# 关闭文件
f.close()
# open打开文件,使用追加写操作
f = open("test1.txt", "a", encoding="UTF-8")
# write写入
f.write("123456789")
# flush刷新
f.flush()
# 关闭文件
f.close()