文章来源:互联网博客文章,后续有时间再来细化整理。
在数据库查询中,合理的使用索引,可以极大提升数据库查询效率,充分利用系统资源。这个随着数据量的增加得到提升,越大越明显,也和业务线有关,越是读多写少的业务体现越明显。
索引优点:
- 唯一索引保证唯一性
- 加快数据的检索速度(单表查询、联合查询及分组排序等等)
索引缺点:
- 创建索引和维护索引要耗费时间(创建、更新、删除都需要维护)
- 索引需要占物理空间(物理空间包含内存和磁盘,这个看索引大小)
1 BTREE索引
CREATE INDEX默认使用BTREE索引,适合按照顺序存储的数据进行比较查询和范围查询。
查询优化器会优先考虑使用BTREE索引:
- <,<=,=,>,>=
- 以及这些操作的组合,比如between and,也可以使用BTREE。
- 在索引列上的IS NULL 或者IS NOT NULL也可以使用BTREE。
- BTREE索引也可以用于模糊查询,但是仅限字符串开头是常量的情况下,比如 name LIKE ‘Jason%’,或者name ~ ’^Jason’。但是name LIKE ‘%Jason’是不能用的。
- Min/Max聚集操作也可使用BTREE索引。
- 其实在merge join以及order by中,可以通过使用BTREE索引的有序性来减少sort带来的代价
create index on t1(id);2 Hash索引
Hash索引是通过比较hash值来查找定位,如果hash索引列的数据重复度比较高,容易产生严重的hash冲突,从而降低查询效率,因此这种情况下,不适合hash索引。
CREATE INDEX idx_name ON table_name USING HASH (column_name);3 GiST索引
不是独立的索引类型,是一种架构或者索引模板,是一棵平衡二叉树。适用于多维数据类型和集合数据类型。
适合业务:
- 几何类型,支持位置搜索(包含、相交、在上下左右等),按距离排序。
- 范围类型,支持位置搜索(包含、相交、在左右等)。
- IP类型,支持位置搜索(包含、相交、在左右等)。
- 空间类型(PostGIS),支持位置搜索(包含、相交、在上下左右等),按距离排序。
- 标量类型,支持按距离排序。
相比Btree缺点:
- GiST跟Btree索引相比,索引创建耗时较长,占用空间也比较大。
相比Btree有点:
- BTREE组合索引(a, b),如果where条件中只有b,则无法使用索引。此时,GiST可以解决这种情况。
create index idx_t3_gist on t3 using gist(a,b);条件分析:
root=# explain select * from t3 where b = '2022-11-18 17:50:29.245683';
QUERY PLAN
-------------------------------------------------------------------------------
Index Scan using idx_t3_gist on t3 (cost=0.28..8.30 rows=1 width=49)
Index Cond: (b = '2022-11-18 17:50:29.245683'::timestamp without time zone)
(2 rows)4 SP-GiST索引
和GiST类似,但是是一棵不平衡树,支持多维和海量数据,把空间分割成互不相交的部分。SP-GiST适用于空间可以递归分割成不相交区域的结构,包括四叉树、k-D树和基数树。
create index on sites using spgist(url);5 GIN索引
gin是倒排索引(es中字段默认会创建一个倒排索引),是一个存储对(key,list[])集合的索引结构,其中key是一个键值,而list[]是一组出现过key的位置。如(‘hello’,’14:2 23:4’)中,表示hello在14:2和23:4这两个位置出现过。
gin使用:
- 单值稀疏数据搜索
- 多列任意搜索,当用户的需求是按照任意列进行搜索时,gin支持多列展开单独建立索引域。从这边可以看出gin和btree都适用联合索引,两者的区分就是,看索引是否是任意的,如果第一个索引列是必有的可以选择btree,相反选择gin。
5.1 前后模糊索引- pg_trgm
对于前后都需要模糊的字段需要用到pg_trgm索引,需要注意的是,数据库的lc_type不能为‘C’,可以通过命令 \l+ database_name 来查看。需要提前创建扩展:
CREATE EXTENSION btree_gin;
CREATE EXTENSION pg_trgm索引创建:
CREATE INDEX idx_vehiclestructured_plateno_like ON viid_vehicle.vehiclestructured USING GIN (plateno GIN_TRGM_OPS)5.2 pg_trgm原理
pg_trgm使用时将字符串的前端添加2个空格,末端添加一个空格,之后每三个连续的字符串作为一个TOKEN进行拆分,对TOKEN建立GIN倒排索引。
查看字符串的原理:
SELECT SHOW_TRGM('viid');
结果:
show_trgm
-----------------------------
{" v"," vi","id ",iid,vii}5.3 物理结构
逻辑结构
GIN索引在逻辑上可以看成一个relation,该relation有两种结构:
- 只索引基表的一列
| key | value |
|---|---|
| Key1 | Posting list( or posting tree) |
| Key2 | Posting list( or posting tree) |
| … | … |
- 索引基表的多列(复合、多列索引)
| column_id | key | value |
|---|---|---|
| Column1 num | Key1 | Posting list( or posting tree) |
| Column2 num | Key1 | Posting list( or posting tree) |
| Column3 num | Key1 | Posting list( or posting tree) |
| ... | ... | ... |
这种结构,对于基表中不同列的相同的key,在GIN索引中也会当作不同的key来处理。
GIN索引在物理存储上包含如下内容:
-
Entry:GIN索引中的一个元素,可以认为是一个词位,也可以理解为一个key
-
Entry tree:在Entry上构建的B树
-
posting list:一个Entry出现的物理位置(heap ctid, 堆表行号)的链表
-
posting tree:在一个Entry出现的物理位置链表(heap ctid, 堆表行号)上构建的B树,所以posting tree的KEY是ctid,而entry tree的KEY是被索引的列的值
-
pending list:索引元组的临时存储链表,用于fastupdate模式的插入操作
从上面可以看出GIN索引主要由Entry tree和posting tree(or posting list)组成,其中Entry tree是GIN索引的主结构树,posting tree是辅助树。
entry tree类似于b+tree,而posting tree则类似于b-tree(平衡树)。
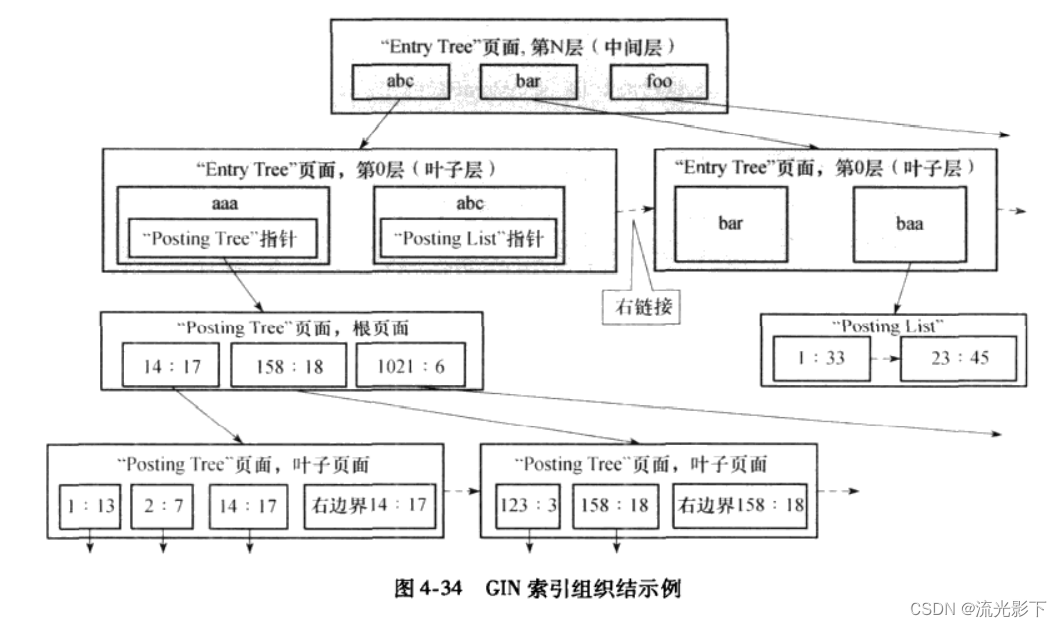
另外,不管entry tree还是posting tree,它们都是按KEY有序组织的。
总结:组合索引是为每一个字段创建一个entry tree,当key对应的value数据较少则用链表形式,当达到一定数量则采用B树(平衡树)的模式,这个倒是像极了Java8 HashMap的内部数据部分结构
5.4 pg_trgm适用场景
-
有前缀的模糊查询,例如a%,至少需要提供1个字符。
-
有后缀的模糊查询,例如%ab,至少需要提供2个字符。
-
前后模糊查询,例如%abc%,至少需要提供3个字符。
5.5 查询流程
这个我没有找到相关博客文章的说明,但是根据上面对gin索引结构的说明,人工智能的回答可信度应该是有的。注意:下面是AI回答,作为思考考虑就行,下面介绍不保证正确。

6 brin
Brin索引是块级索引,它不是以行号为单位记录索引明细,而是记录每个数据块或者每段连续的数据块的统计信息。因此brin索引空间占用特别小,对数据写入、更新、删除的影响很小。
Brin索引适合时序数据(timestamp类型),在时间或序列字段创建索引,进行等值、范围查询时效果好;
以及对存储空间比较严格的场景。
CREATE INDEX idx_vehiclestructured_plateno_like ON viid_vehicle.vehiclestructured USING BRIN(plateno);Brin的优点
- 顺序扫描会很快,它是索引顺序扫描的一种改进,如果键值的顺序和存储中块的组织顺序相同,则针对大表的统计型SQL性能会大幅提升。
- 创建索引的速度非常快。
- 索引占用的空间很小。
Brin的缺点:
- Brin在很大程度上依赖于数据相邻性(在磁盘上附近发现相似的数据)。如果我们的数据非常的混乱,则Brin索引查询重叠的条目可能性就非常高。一旦我们的Brin索引开始重叠,就将匹配更多的记录,并且导致需要从源表中读取多个块范围,以找到我们要查找的记录。
适合:
- 主要适用于类似时序数据之类的,有着天然的顺序,而且都是添加写的场景。比如有序时间这类的。
推荐文章:
PgSQL · 应用案例 · GIN索引在任意组合查询中的应用-阿里云开发者社区 (aliyun.com)
GIN索引 - foreast - 博客园 (cnblogs.com)
PostgreSQL GIN索引实现原理-阿里云开发者社区 (aliyun.com)





![[Linux] 进程间通信基础](https://img-blog.csdnimg.cn/img_convert/7b0d6ba5dcce6ce6b2e732fdffde6496.gif#pic_center)