Apache Paimon系列之:主键表
- 一、主键表
- 1.Bucket
- 2.LSM Trees
- 3.Compaction
- 二、数据分布
- 1.固定Bucket
- 2.动态Bucket
- 3.正常动态Bucket模式
- 4.跨分区更新插入动态存储桶模式
- 三、Merge Engine
- 1.Deduplicate
- 2.部分更新
- 3.序列组
- 4.聚合部分更新
- 5.聚合
- 6.Retract
- 7.First Row
- 四、Changelog Producer
- 1.None
- 2.Input
- 3.Lookup
- 4.Full Compaction
- 五、Sequence and Rowkind
- 1.Sequence Field
- 2.Row Kind Field
一、主键表
主键表是创建表时默认的表类型。用户可以插入、更新或删除表中的记录。
主键由一组包含每个记录的唯一值的列组成。 Paimon 通过对每个存储桶内的主键进行排序来强制数据排序,允许用户通过对主键应用过滤条件来实现高性能。
1.Bucket
未分区表或分区表中的分区被细分为存储桶,以便为可用于更有效查询的数据提供额外的结构。
每个存储桶目录都包含一个 LSM 树及其变更日志文件。
桶的范围由记录中的一列或多列的哈希值确定。用户可以通过提供bucket-key选项来指定分桶列。如果未指定bucket-key选项,则主键(如果已定义)或完整记录将用作存储桶键。
桶是读写的最小存储单元,因此桶的数量限制了最大处理并行度。不过这个数字不应该太大,因为它会导致大量小文件和低读取性能。一般来说,每个桶中建议的数据大小约为200MB - 1GB。
另外,如果您想在创建表后调整存储桶的数量,请参阅重新缩放存储桶。
2.LSM Trees
Paimon 采用 LSM 树(日志结构合并树)作为文件存储的数据结构。本文档简要介绍了LSM树的概念。
排序运行
LSM 树将文件组织成多个排序的运行。排序运行由一个或多个数据文件组成,并且每个数据文件恰好属于一个排序运行。
数据文件中的记录按其主键排序。在排序运行中,数据文件的主键范围永远不会重叠。
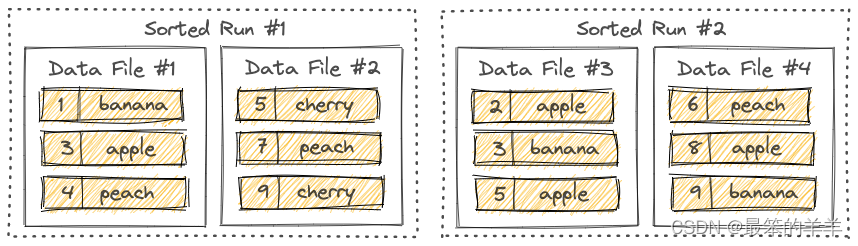
正如您所看到的,不同的排序运行可能具有重叠的主键范围,甚至可能包含相同的主键。查询LSM树时,必须合并所有排序的运行,并且必须根据用户指定的合并引擎和每条记录的时间戳来合并具有相同主键的所有记录。
写入LSM树的新记录将首先缓存在内存中。当内存缓冲区满时,内存中的所有记录将被排序并刷新到磁盘。现在已创建新的排序运行。
3.Compaction
当越来越多的记录写入LSM树时,排序游程的数量将会增加。由于查询LSM树需要将所有排序运行合并起来,太多排序运行将导致查询性能较差,甚至内存不足。
为了限制排序运行的数量,我们必须偶尔将多个排序运行合并为一个大的排序运行。这个过程称为压缩。
然而,压缩是一个资源密集型过程,会消耗一定的CPU时间和磁盘IO,因此过于频繁的压缩可能会导致写入速度变慢。这是查询和写入性能之间的权衡。 Paimon 目前采用了类似于 Rocksdb 通用压缩的压缩策略。
默认情况下,当Paimon将记录追加到LSM树时,它也会根据需要执行压缩。用户还可以选择在专用压缩作业中执行所有压缩。
二、数据分布
Bucket是读写的最小存储单元,每个Bucket目录中包含一棵LSM树。
1.固定Bucket
配置大于0的桶,采用Fixed Bucket模式,根据Math.abs(key_hashcode % numBuckets)计算记录的桶。
重新缩放存储桶只能通过离线流程完成。桶数过多会导致小文件过多,桶数过少会导致写入性能较差。
2.动态Bucket
配置“桶”=“-1”。先到达的key会落入旧的bucket,新的key会落入新的bucket,bucket和key的分布取决于数据到达的顺序。 Paimon 维护一个索引来确定哪个键对应哪个桶。
Paimon会自动扩大桶的数量。
- Option1: ‘dynamic-bucket.target-row-num’:控制一个桶的目标行数。
- 选项2:‘dynamic-bucket.initial-buckets’:控制初始化bucket的数量。
动态Bucket仅支持单个写入作业。请不要启动多个作业来写入同一分区(这可能会导致重复数据)。即使您启用“只写”并启动专用的压缩作业,它也不会起作用。
3.正常动态Bucket模式
当您的更新不跨分区(没有分区,或者主键包含所有分区字段)时,动态桶模式使用 HASH 索引来维护从键到桶的映射,它比固定桶模式需要更多的内存。
表现:
- 一般来说,没有性能损失,但会有一些额外的内存消耗,一个分区中的 1 亿个条目多占用 1 GB 内存,不再活动的分区不占用内存。
- 对于更新率较低的表,建议使用此模式,以显着提高性能。
普通动态桶模式支持排序压缩以加快查询速度。
4.跨分区更新插入动态存储桶模式
当需要跨分区upsert(主键不包含所有分区字段)时,Dynamic Bucket模式直接维护键到分区和桶的映射,使用本地磁盘,并在启动流写作业时通过读取表中所有现有键来初始化索引。不同的合并引擎有不同的行为:
- 重复数据删除:删除旧分区中的数据,并将新数据插入到新分区中。
- PartialUpdate & Aggregation:将新数据插入旧分区。
- FirstRow:如果有旧值,则忽略新数据。
性能:对于数据量较大的表,性能会有明显的损失。而且,初始化需要很长时间。
如果你的upsert不依赖太旧的数据,可以考虑配置索引TTL来减少索引和初始化时间:
- ‘cross-partition-upsert.index-ttl’:rocksdb索引和初始化中的TTL,这样可以避免维护太多索引而导致性能越来越差。
但请注意,这也可能会导致数据重复。
三、Merge Engine
当Paimon接收器收到两条或更多具有相同主键的记录时,它会将它们合并为一条记录以保持主键唯一。通过指定 merge-engine 表属性,用户可以选择如何将记录合并在一起。
始终在 Flink SQL TableConfig 中将 table.exec.sink.upsert-materialize 设置为 NONE,sink upsert-materialize 可能会导致奇怪的行为。当输入乱序时,我们建议您使用序列字段来纠正乱序。
1.Deduplicate
去重合并引擎是默认的合并引擎。 Paimon 只会保留最新的记录,并丢弃其他具有相同主键的记录。
具体来说,如果最新的记录是DELETE记录,则所有具有相同主键的记录都将被删除。
2.部分更新
通过指定 ‘merge-engine’ = ‘partial-update’,用户可以通过多次更新来更新记录的列,直到记录完成。这是通过使用同一主键下的最新数据逐一更新值字段来实现的。但是,在此过程中不会覆盖空值。
例如,假设 Paimon 收到三个记录:
<1, 23.0, 10, NULL>-
<1, NULL, NULL, ‘This is a book’>
<1, 25.2, NULL, NULL>
假设第一列是主键,则最终结果将是 <1, 25.2, 10, ‘This is a book’>。
对于流式查询,部分更新合并引擎必须与查找或完全压缩变更日志生成器一起使用。 (还支持“输入”变更日志生成器,但仅返回输入记录。)
默认情况下,部分更新不接受删除记录,您可以选择以下解决方案之一:
- 配置“partial-update.ignore-delete”以忽略删除记录。
- 配置“sequence-group”以收回部分列。
3.序列组
序列字段并不能解决多流更新的部分更新表的乱序问题,因为多流更新时序列字段可能会被另一个流的最新数据覆盖。
因此我们引入了部分更新表的序列组机制。它可以解决:
- 多流更新时出现混乱。每个流定义其自己的序列组。
- 真正的部分更新,而不仅仅是非空更新。
CREATE TABLE t (
k INT,
a INT,
b INT,
g_1 INT,
c INT,
d INT,
g_2 INT,
PRIMARY KEY (k) NOT ENFORCED
) WITH (
'merge-engine'='partial-update',
'fields.g_1.sequence-group'='a,b',
'fields.g_2.sequence-group'='c,d'
);
INSERT INTO t VALUES (1, 1, 1, 1, 1, 1, 1);
-- g_2 is null, c, d should not be updated
INSERT INTO t VALUES (1, 2, 2, 2, 2, 2, CAST(NULL AS INT));
SELECT * FROM t; -- output 1, 2, 2, 2, 1, 1, 1
-- g_1 is smaller, a, b should not be updated
INSERT INTO t VALUES (1, 3, 3, 1, 3, 3, 3);
SELECT * FROM t; -- output 1, 2, 2, 2, 3, 3, 3
对于 fields..sequence-group,有效的比较数据类型包括:DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP 和 TIMESTAMP_LTZ。
4.聚合部分更新
您可以为输入字段指定聚合函数,支持聚合中的所有函数。
CREATE TABLE t (
k INT,
a INT,
b INT,
c INT,
d INT,
PRIMARY KEY (k) NOT ENFORCED
) WITH (
'merge-engine'='partial-update',
'fields.a.sequence-group' = 'b',
'fields.b.aggregate-function' = 'first_value',
'fields.c.sequence-group' = 'd',
'fields.d.aggregate-function' = 'sum'
);
INSERT INTO t VALUES (1, 1, 1, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO t VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 1, 1);
INSERT INTO t VALUES (1, 2, 2, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO t VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 2, 2);
SELECT * FROM t; -- output 1, 2, 1, 2, 3
5.聚合
注意:始终在 Flink SQL TableConfig 中将 table.exec.sink.upsert-materialize 设置为 NONE。
有时用户只关心聚合结果。聚合合并引擎根据聚合函数将同一主键下的各个值字段与最新数据一一聚合。
每个不属于主键的字段都可以被赋予一个聚合函数,由 fields..aggregate-function 表属性指定,否则它将使用 last_non_null_value 聚合作为默认值。例如,请考虑下表定义。
CREATE TABLE my_table (
product_id BIGINT,
price DOUBLE,
sales BIGINT,
PRIMARY KEY (product_id) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation',
'fields.price.aggregate-function' = 'max',
'fields.sales.aggregate-function' = 'sum'
);
现场价格将通过 max 函数聚合,现场销售额将通过 sum 函数聚合。给定两个输入记录 <1, 23.0, 15> 和 <1, 30.2, 20>,最终结果将是 <1, 30.2, 35>。
当前支持的聚合函数和数据类型有:
- sum:sum 函数聚合多行中的值。它支持 DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT 和 DOUBLE 数据类型。
- product:产品功能可以跨多行计算产品值。它支持 DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT 和 DOUBLE 数据类型。
- count:count 函数对多行中的值进行计数。它支持 INTEGER、BIGINT 数据类型。
- max:max函数识别并保留最大值。它支持 CHAR、VARCHAR、DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP 和 TIMESTAMP_LTZ 数据类型。
- min:min 函数识别并保留最小值。它支持 CHAR、VARCHAR、DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP 和 TIMESTAMP_LTZ 数据类型。
- last_value:last_value 函数用最近导入的值替换以前的值。它支持所有数据类型。
- last_non_null_value:last_non_null_value 函数用最新的非空值替换先前的值。它支持所有数据类型。
- listagg:listagg 函数将多个字符串值连接成一个字符串。它支持 STRING 数据类型。
- bool_and:bool_and 函数评估布尔集中的所有值是否都为 true。它支持 BOOLEAN 数据类型。
- bool_or:bool_or 函数检查布尔集中是否至少有一个值为 true。它支持 BOOLEAN 数据类型。
- first_value:first_value 函数从数据集中检索第一个空值。它支持所有数据类型。
- first_non_null_value:first_non_null_value 函数选择数据集中的第一个非空值。它支持所有数据类型。
- nested_update:nested_update 函数将多行收集到一个数组中(所谓的“嵌套表”)。它支持 ARRAY 数据类型。
- 使用 fields..nested-key=pk0,pk1,… 指定嵌套表的主键。如果没有键,行将被追加到数组中。
-- orders table
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY NOT ENFORCED,
user_name STRING,
address STRING
);
-- sub orders that have the same order_id
-- belongs to the same order
CREATE TABLE sub_orders (
order_id BIGINT,
sub_order_id INT,
product_name STRING,
price BIGINT,
PRIMARY KEY (order_id, sub_order_id) NOT ENFORCED
);
-- wide table
CREATE TABLE order_wide (
order_id BIGINT PRIMARY KEY NOT ENFORCED,
user_name STRING,
address STRING,
sub_orders ARRAY<ROW<sub_order_id BIGINT, product_name STRING, price BIGINT>>
) WITH (
'merge-engine' = 'aggregation',
'fields.sub_orders.aggregate-function' = 'nested_update',
'fields.sub_orders.nested-key' = 'sub_order_id'
);
-- widen
INSERT INTO order_wide
SELECT
order_id,
user_name,
address,
CAST (NULL AS ARRAY<ROW<sub_order_id BIGINT, product_name STRING, price BIGINT>>)
FROM orders
UNION ALL
SELECT
order_id,
CAST (NULL AS STRING),
CAST (NULL AS STRING),
ARRAY[ROW(sub_order_id, product_name, price)]
FROM sub_orders;
-- query using UNNEST
SELECT order_id, user_name, address, sub_order_id, product_name, price
FROM order_wide, UNNEST(sub_orders) AS so(sub_order_id, product_name, price)
collect: 收集函数将元素收集到数组中。您可以设置 fields..distinct=true 来删除重复元素。它仅支持 ARRAY 类型。
merge_map: merge_map函数合并输入映射。它仅支持 MAP 类型。
对于流式查询,聚合合并引擎必须与查找或完全压缩变更日志生成器一起使用。 (还支持“输入”变更日志生成器,但仅返回输入记录。)
6.Retract
仅 sum、product、count、collect、merge_map、nested_update、last_value 和 last_non_null_value 支持撤回(UPDATE_BEFORE 和 DELETE),其他聚合函数不支持撤回。如果允许某些函数忽略撤回消息,可以配置:‘fields.${field_name}.ignore-retract’=‘true’。
当接受撤回消息时,last_value和last_non_null_value只是将字段设置为null。
collect 和 merge_map 尽最大努力尝试处理撤回消息,但不保证结果准确。处理撤回消息时可能会出现以下行为:
- 如果记录混乱,它可能无法处理撤回消息。例如表使用collect,上游分别发送+I[‘A’, ‘B’]和-U[‘A’]。如果表首先收到-U[‘A’],则它什么也不做;然后它收到+I[‘A’, ‘B’],合并结果将是+I[‘A’, ‘B’]而不是+I[‘B’]。
- 来自一个上游的撤回消息将撤回多个上游合并的结果。例如表使用merge_map,一个上游发送+I[1->A],另一个上游发送+I[1->B],稍后发送-D[1->B]。表会先将两个插入值合并到+I[1->B],然后-D[1->B]会收回整个结果,所以最终结果是一个空映射而不是+I[1- >A]
7.First Row
通过指定 ‘merge-engine’ = ‘first-row’,用户可以保留同一主键的第一行。它与去重合并引擎不同,在第一行合并引擎中,它将生成仅插入更改日志。
- 第一行合并引擎必须与查找变更日志生成器一起使用。
- 您不能指定sequence.field。
- 不接受 DELETE 和 UPDATE_BEFORE 消息。您可以配置first-row.ignore-delete来忽略这两种记录。
这对于替代流计算中的日志去重有很大的帮助。
四、Changelog Producer
流式查询会不断产生最新的变化。
通过在创建表时指定更改日志生成器表属性,用户可以选择从表文件生成的更改模式。
变更日志生成器表属性仅影响表文件中的变更日志。它不影响外部日志系统。
1.None
默认情况下,不会将额外的变更日志生成器应用于表的写入器。 Paimon 源只能看到跨快照的合并更改,例如删除了哪些键以及某些键的新值是什么。
但是,这些合并的更改无法形成完整的更改日志,因为我们无法直接从中读取键的旧值。合并的更改要求消费者“记住”每个键的值并重写这些值而不看到旧的值。然而,一些消费者需要旧的价值观来确保正确性或效率。
考虑一个消费者计算某些分组键的总和(可能不等于主键)。如果消费者只看到一个新值5,它无法确定应该将哪些值添加到求和结果中。例如,如果旧值为 4,则应在结果中加 1。但如果旧值是 6,则应依次从结果中减去 1。旧的价值观对于这些类型的消费者来说很重要。
总而言之,没有一个变更日志生成器最适合数据库系统等使用者。 Flink 还有一个内置的“规范化”运算符,可以将每个键的值保留在状态中。很容易看出,这种操作符的成本非常高,应该避免使用。 (您可以通过“scan.remove-normalize”强制删除“标准化”运算符。)
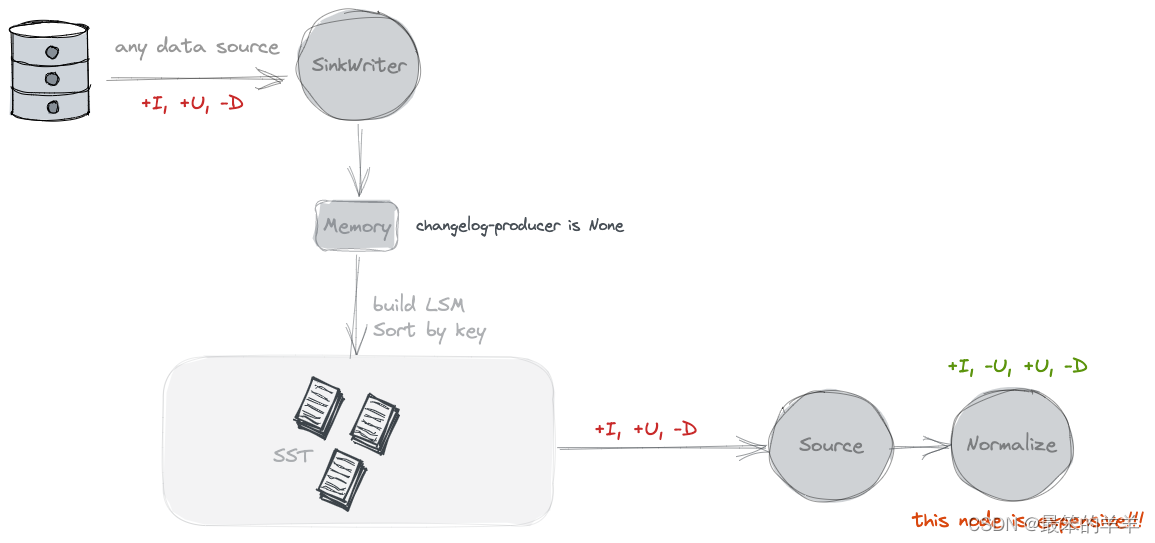
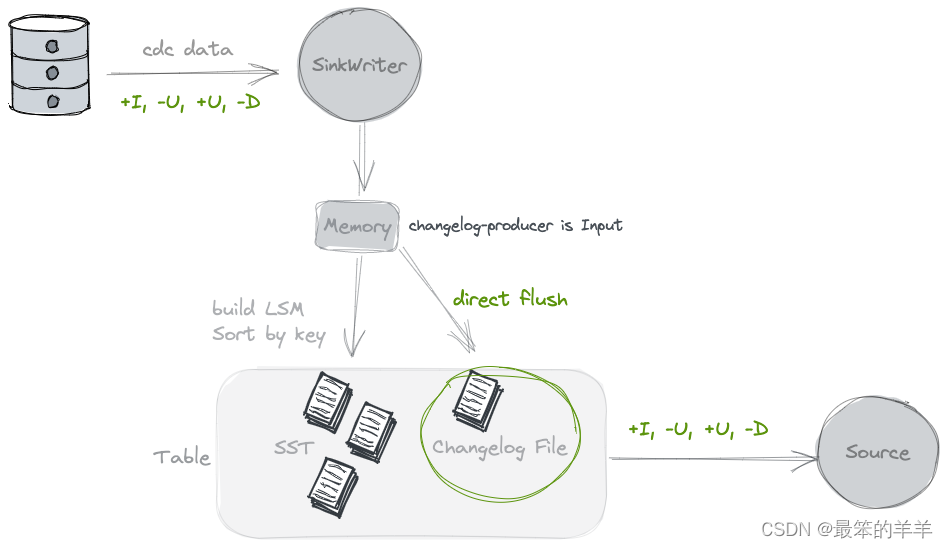
2.Input
通过指定 ‘changelog- Producer’ = ‘input’,Paimon 编写者依赖他们的输入作为完整变更日志的来源。所有输入记录将保存在单独的变更日志文件中,并由 Paimon 来源提供给消费者。
当 Paimon 编写者的输入是完整的变更日志(例如来自数据库 CDC)或由 Flink 状态计算生成时,可以使用输入变更日志生成器。
3.Lookup
如果您的输入无法生成完整的变更日志,但您仍然想摆脱昂贵的标准化运算符,则可以考虑使用“查找”变更日志生成器。
通过指定’changelog- Producer’ = ‘lookup’,Paimon将在提交数据写入之前通过’lookup’生成changelog。
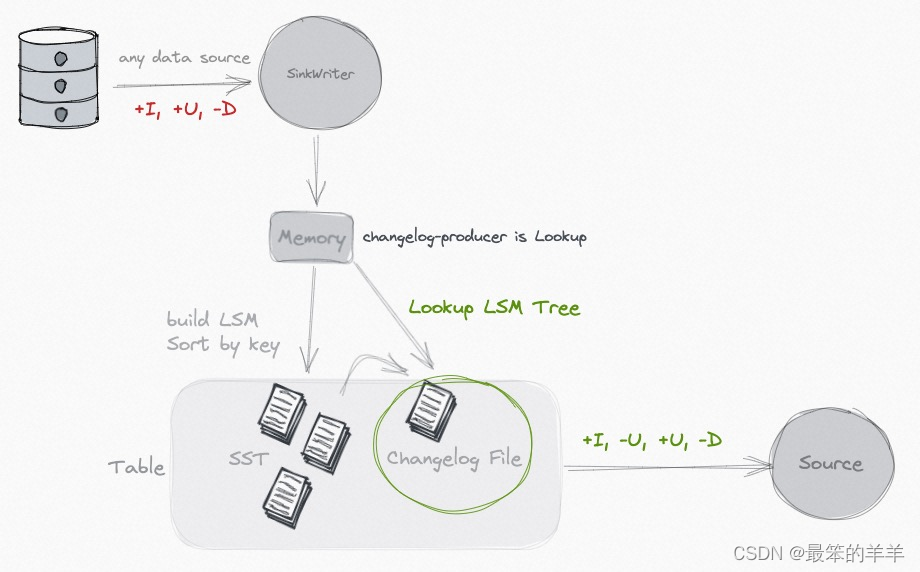
Lookup 会将数据缓存在内存和本地磁盘上,您可以使用以下选项来调整性能:

Lookupchangelog- Producer 支持changelog- Producer.row-deduplicate 以避免为同一记录生成-U、+U 变更日志。
(注意:请增加 ‘execution.checkpointing.max-concurrent-checkpoints’ Flink 配置,这对性能非常重要)。
4.Full Compaction
如果你觉得“lookup”的资源消耗太大,可以考虑使用“full-compaction”的changelog Producer,它可以解耦数据写入和changelog生成,更适合高延迟的场景(例如10分钟) )。
通过指定 ‘changelog- Producer’ = ‘full-compaction’,Paimon 将比较完全压缩之间的结果并生成差异作为变更日志。变更日志的延迟受到完全压缩频率的影响。
通过指定 full-compaction.delta-commits 表属性,在增量提交(检查点)后将不断触发完全压缩。默认情况下设置为 1,因此每个检查点都会进行完全压缩并生成更改日志。
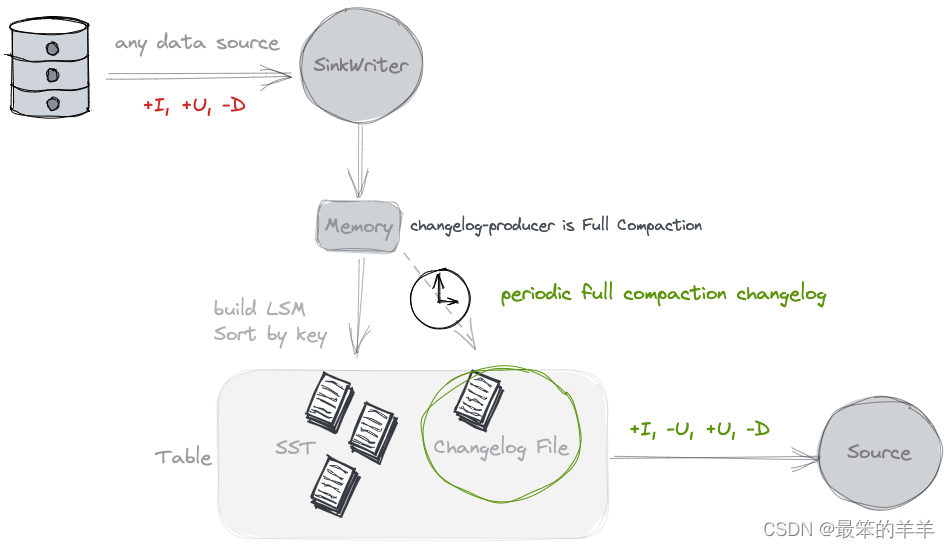
完全压缩变更日志生成器可以为任何类型的源生成完整的变更日志。然而,它不如输入变更日志生成器那么高效,并且生成变更日志的延迟可能很高。
全压缩changelog- Producer 支持changelog- Producer.row-deduplicate 以避免为同一记录生成-U、+U 变更日志。
(注意:请增加 ‘execution.checkpointing.max-concurrent-checkpoints’ Flink 配置,这对性能非常重要)。
五、Sequence and Rowkind
创建表时,可以通过指定字段来指定“sequence.field”来确定更新的顺序,也可以指定“rowkind.field”来确定记录的changelog种类。 ‘sequence.field’ 通过指定字段来确定更新的顺序,或者可以指定’rowkind.field’ 来确定记录的changelog 类型。
1.Sequence Field
默认情况下,主键表根据输入顺序确定合并顺序(最后输入的记录将是最后合并的)。然而在分布式计算中,会存在一些导致数据混乱的情况。这时,可以使用时间字段作为sequence.field,例如:
CREATE TABLE my_table (
pk BIGINT PRIMARY KEY NOT ENFORCED,
v1 DOUBLE,
v2 BIGINT,
update_time TIMESTAMP
) WITH (
'sequence.field' = 'update_time'
);
最大的sequence.field值的记录将是最后合并的,如果值相同,将根据输入顺序来确定哪一条是最后一条。
您可以为sequence.field定义多个字段,例如’update_time,flag’,多个字段将按顺序进行比较。
2.Row Kind Field
默认情况下,主键表根据输入行确定行类型。您还可以定义“rowkind.field”以使用字段来提取行类型。
有效的行类型字符串应为“+I”、“-U”、“+U”或“-D”。