文章目录
- Compose
- ToTensor
- Normalize
- Resize
在PyTorch中,transforms是一个用于图像预处理和数据增强的模块,通常与torchvision库一起使用。torchvision提供了大量预先定义的transforms,它们可以方便地应用于图像数据,以进行预处理或增强。这些transforms对于训练和评估机器学习模型(尤其是深度学习模型)非常有用。
python中的call方法
在Python中,__call__ 是一个特殊方法,也被称为“魔法方法”或“双下划线方法”。当一个对象实例被当作函数一样调用时,Python会自动调用该对象的 __call__ 方法。这意味着你可以定义你自己的对象,使其能够被“调用”,就像调用一个函数一样。
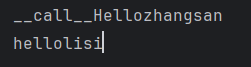
class Person:
def __call__(self,name):
print("__call__"+"Hello"+name)
def hello(self,name):
print("hello"+name)
person = Person()
person("zhangsan")
person.hello("lisi")
class CallableClass:
def __init__(self, value):
self.value = value
def __call__(self, *args, **kwargs):
print(f"Called with {args} and {kwargs}")
return self.value
# 创建一个实例
obj = CallableClass(42)
# 使用该实例,就像调用一个函数一样
result = obj(1, 2, 3, a=4, b=5)
print(result) # 输出: 42
Compose
在PyTorch中,Compose是一个功能强大的工具,它允许你将多个转换(transforms)组合成一个单一的转换序列。这样,你就可以一次性地对数据进行一系列复杂的预处理操作。Compose通常与torchvision.transforms模块一起使用,该模块提供了许多预定义的转换函数。
from torchvision import transforms
# 定义一系列的转换
transform_sequence = transforms.Compose([
transform1,
transform2,
transform3,
# ...
])
# 然后你可以将这个转换序列应用于图像
transformed_image = transform_sequence(image)
from torchvision import transforms
from PIL import Image
# 加载一张图像
image = Image.open('path_to_image.jpg')
# 定义转换序列
transform = transforms.Compose([
transforms.Resize((256, 256)), # 将图像大小调整为256x256
transforms.CenterCrop(224), # 从中心裁剪出224x224的区域
transforms.ToTensor(), # 将PIL图像或NumPy ndarray转换为torch.Tensor
transforms.Normalize( # 对图像进行标准化
mean=[0.485, 0.456, 0.406], # 使用ImageNet数据集上的RGB通道的均值
std=[0.229, 0.224, 0.225] # 使用ImageNet数据集上的RGB通道的标准差
)
])
# 应用转换序列到图像
transformed_image = transform(image)
在这个例子中,我们首先使用Resize将图像大小调整为256x256,然后使用CenterCrop从中心裁剪出224x224的区域。接着,使用ToTensor将图像转换为PyTorch张量,最后使用Normalize对图像进行标准化处理。所有这些转换都被组合在一起,并通过一次调用transform(image)来应用。
ToTensor
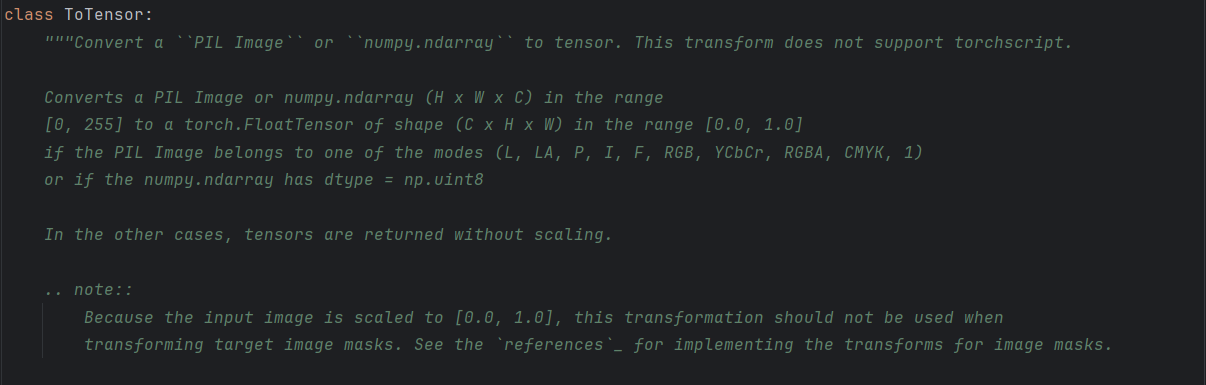
这是transforms源码中的解释
在PyTorch中是一个常用的转换函数,用于将PIL Image或NumPy ndarray转换为torch.Tensor。但是,在转换过程中,它会自动将图像的像素值范围从[0, 255]缩放到[0.0, 1.0]。这通常是因为神经网络的输入通常期望在[0.0, 1.0]范围内。
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
imge_path = "images/OIP.jpg"
imge = Image.open(imge_path)
trans_totensor = transforms.ToTensor()
# 这是就是call函数的调用
imge_tensor = trans_totensor(imge)
writer.add_image("ToTensor",imge_tensor)
writer.close()
Normalize
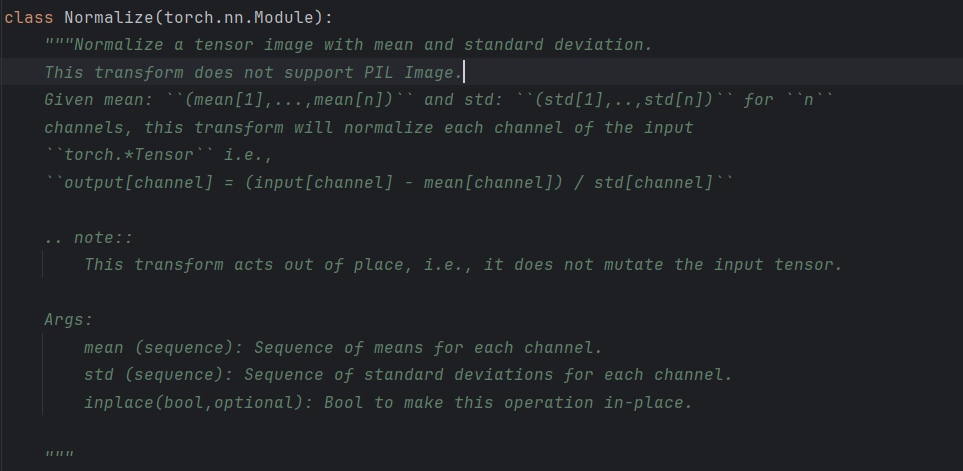
归一化公式:
o
u
t
p
u
t
[
c
h
a
n
n
e
l
]
=
(
i
n
p
u
t
[
c
h
a
n
n
e
l
]
−
m
e
a
n
[
c
h
a
n
n
e
l
]
)
s
t
d
[
c
h
a
n
n
e
l
]
output[channel] = \frac{(input[channel] - mean[channel])}{std[channel]}
output[channel]=std[channel](input[channel]−mean[channel])
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
imge_path = "images/OIP.jpg"
imge = Image.open(imge_path)
# ToTensor
trans_totensor = transforms.ToTensor()
imge_tensor = trans_totensor(imge)
writer.add_image("ToTensor", imge_tensor)
print(imge_tensor[0][0][0])
# Normalize
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(imge_tensor)
print(img_norm[0][0][0])
writer.add_image("Norm",img_norm)
writer.close()
可以看出来归一化的结果还是有些不同的

Resize
# Resize
print(imge.size)
trans_resize = transforms.Resize((512, 512))
img_resize = trans_resize(imge)
print(img_resize)
img_resize=trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
writer.close()