硬盘
文件指的是硬盘/磁盘上的文件
⚠硬盘 ≠ 磁盘
磁盘属于外存的一种;而软盘,硬盘(机械硬盘)这种属于用磁性介质来存储二进制数据
ssd硬盘(固态硬盘),内部完全是集成电路,和磁性介质无关。相比于机械硬盘,固态硬盘读写速度快了10倍。为什么?
下面是机械硬盘的构造
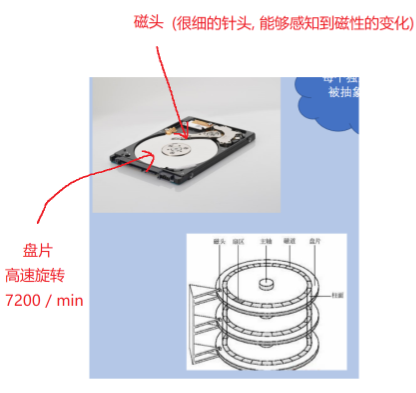
存储原理:磁头悬停在盘片的不同位置就能感知到磁性数据信息
对于机械硬盘来说,更擅长顺序读写,不擅长随机读写。
顺序读写:比如说有一个很大的文件,对这个文件整体复制一下。整个大文件就在盘片的某一个位置,磁头就在该位置进行数据感知,不需要太多的移动,速度就会加快。
随机读写:某个目录中有很多小文件(在硬盘上的存储不是连续的,是离散的,会出现在硬盘的各个位置),需要把整个目录都拷贝一下。此时磁头就需要不断变换位置去找文件,速度就会变慢。
计算机中的文件
文件是啥?
对于计算机来说,文件是一个广义的概念
1.硬盘上的普通文件
2.硬盘上的目录
3.很多硬件设备被操作系统抽象成了文件。比如键盘,显示器,网卡等
文件路径
操作系统有一个专门的模块--文件系统,可以把硬盘希捷封装好,提供统一的api供我们调用

操作系统使用路径来描述一个具体文件的位置
比如:"C:\Users\86156\Desktop\大二下\Coursera-ML-AndrewNg-Notes-master\Coursera-ML-AndrewNg-Notes-master\README.md"这个路径
Windows从盘符出发,一级一级往下走,走到目标文件,把中间经过的目录都串起来,使用/或者\进行分割。注意哦,这可不是遍历,遍历是要把文件树上每一个文件都不重不漏地遍历一遍
什么样地情况才算遍历?当我们直接搜索这个文件名的时候
Everything软件:一款秒搜Windows系统上文件的工具
核心思路:空间换时间
Everything里内置了一个数据库,在最初安装好的时候,软件会对整个文件系统进行一个遍历并把信息都放到内置数据库中,后面搜索的时候就直接在内置数据库里查询
Everything可以感知硬盘上的文件变化,并更新自己的数据库
路径有两种风格
1.绝对路径。从树的根节点出发(Windows是盘符),一层一层到达目标文件
2.相对路径。先指定一个“当前目录”/“工作目录”/“基准目录”,从当前目录出发,找到目标文件
举例:
1.当前目录 C:\Users\1,则相对路径是 ./test.txt(此时的 . 表示当前目录)
2.当前目录 C:\Users\1\AppData,则相对路径 ../test.txt(此时的 .. 表示上层目录)
\ 和 / 是怎么回事?
操作系统中分割目录的各个部分,正统使用 /
由于微软早期做了一个名为DOS的系统,同时支持用 \ 和 / 来进行分割,Windows也继承了这一特性。Linux系统基本采用 /
文件类型
文本文件:按照文本/字符串方式来理解文件内容,文本文件的二进制内容表示的是字符串;文本文档,.c,.java,.cpp都是文本文件
二进制文件:内容存储任何数据都可以(打开来有乱码的就是二进制文件);图片,音频,视频,可执行程序,动态库,.class都是二进制文件
富文本文件:比普通文件丰富的多,比如.docx,.pptx,.xlsx
Java对于文件操作的API
1.针对文件系统的操作(右键文件目录能进行的操作)
在java.io包中的File类中进行
io指的是输入和输出 (⚠输入指的是数据从硬盘到CPU的过程,输出指的是数据从CPU到硬盘的过程)
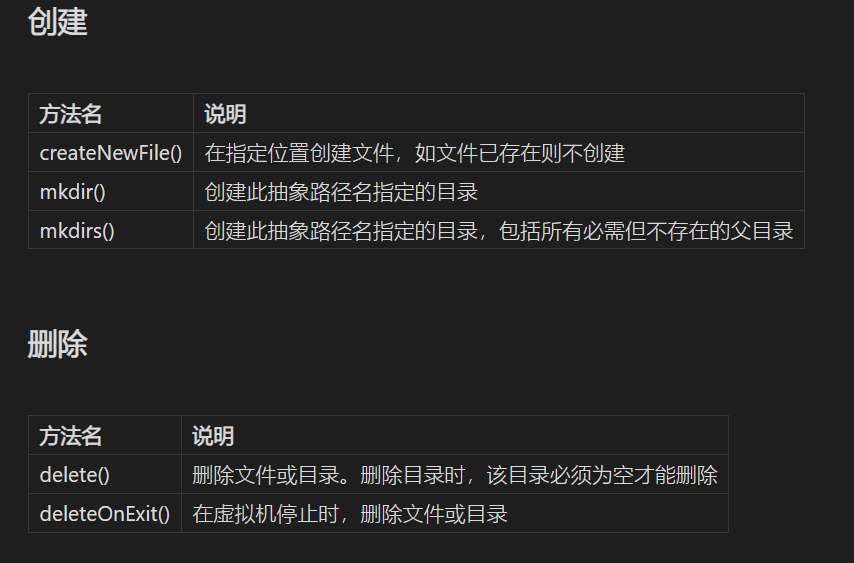
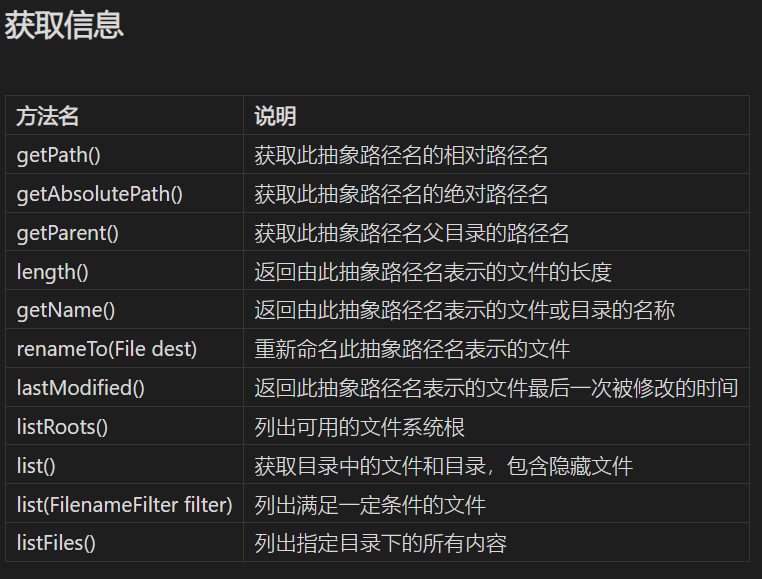
File类里面的方法

代码演示
绝对路径
File f = new File("C:/Users/1/test.txt");
System.out.println(f.getParent());
System.out.println(f.getName());
System.out.println(f.getPath());
System.out.println(f.getAbsolutePath());
System.out.println(f.getCanonicalFile()); 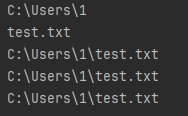
相对路径
File f = new File("./test.txt");
System.out.println(f.getParent());
System.out.println(f.getName());
System.out.println(f.getPath());
System.out.println(f.getAbsolutePath());
System.out.println(f.getCanonicalFile());//这个路径就是针对上面的绝对路径整理化简之后的效果了
创建文件

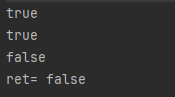
 isDirectory 是否是文件夹
isDirectory 是否是文件夹
第二次执行,因为文件已经存在了,所以会创建失败
删除文件

第二次执行

deleteOnExit 退出时再删除
退出后删除的文件也叫临时文件,给你实时编辑的内容进行保存,防止你文件没有保存电脑突然断电的情况(比如word等程序)
文件列表
System.out.println(Arrays.toString(files));


创建目录
mkdir: mk(make) dir(directory)
需要在构造方法中把路径创建好,再通过mkdir创建

文件重命名
执行前
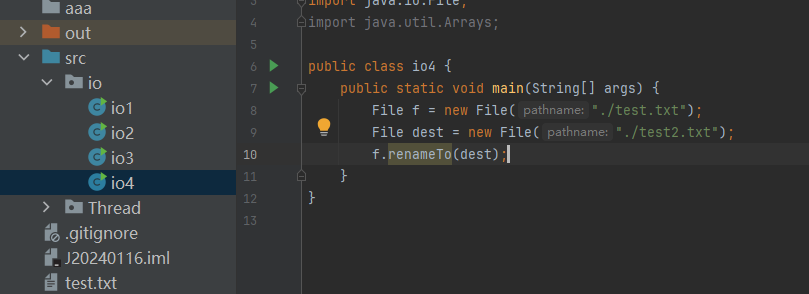
执行后

renameTo还可以移动文件
2.针对文件内容的操作,读文件/写文件
流:操作系统提供的概念
像接水一样,有100ml,可以一次接10ml,接10次;一次接5ml,接20次。怎么接结果都一样
文件流也一样,比如要读写100字节的数据,可以一次读写10字节,分10次;也可以一次读写5字节,分20次;此处的读写方式是任意多的情况,最终的效果是一样的
1.字节流
打开/关闭文件
以字节为单位进行读写,一次最少读写一个字节
InputStream和OutputStream
![]()
InputStream是一个抽象类,无法被实例化,所以不能直接new
但是我们可以使用InputStream其中一个子类进行实例化
![]()
这个表示从文件中读取,()内填写文件的路径,创建对象的同时也打开了文件

这里的关闭文件可以理解为释放了文件的相关资源
为什么要关闭文件?(文件资源泄露问题)
文件描述符表记录了当前进程都打开了哪些文件,这个表类似顺序表或者数组,数组中的每个元素都是一个结构体,这个结构体具体描述了了这个文件的一些属性。
因为每次打开一个文件都会在文件描述符表占据一个位置,如果长期不关闭文件就会使文件描述符表空间被耗尽(⚠文件描述符表无法自动扩容,因为操作系统内核任务重,对性能要求高,如果引起卡顿后果无法设想)
如果空间被耗尽,后面的文件就无法打开
上面的代码有点问题:如果在打开文件后写入的逻辑里面出现return,close指令就无法执行了
修改方法:用try和finally来包裹
//因为try里面定义的inputStream finally里面访问不到,所以我们把它定义到外面
InputStream inputStream = null;
try{
//打开文件
inputStream = new FileInputStream("./test.txt");
//写入其他逻辑
}finally{
//关闭文件
inputStream.close();
}
//或者写成下面这样
try(InputStream inputStream = new FileInputStream("./test.txt")){
}!!第二种写法的代码一旦出来try代码块,会自动执行close方法
读取文件

read() 无参数版本,每次调用读取一个字节,返回读取这个字节的值
返回类型是int,实际上是byte,取值范围是0~255. 有一个特殊情况,如果读取到文件末尾,继续进行read就会返回-1,所以还是用int表示.
read(byte[ ] b) 一个参数版本,传入的字节数组参数是一个输出型参数
byte[ ]是引用类型,使用read的时候,往往就是定义一个内容为空的数组,然后方法内部针对数组内容进行修改,方法执行结束之后在修改后的数组在方法外部也能生效
read(byte[ ] b, int off, int len) off是偏移量,len表示实际读取的字节个数
测试代码(先在文件目录里面创建一个test.txt,写上abcdef

try(InputStream inputStream = new FileInputStream("./test.txt")){
while (true){
int b = inputStream.read();
if(b == -1){
//文件读取完毕
break;
}
//不等于-1.打印这个字节的数据
System.out.printf("%x ",b);
}
}执行代码

打印的内容就是文件中每个字节的数据,也就是abcdef的ASCII码(注意16进制打印ASCII的跟10进制的值不一样)
如果文件带有中文,则打印出的每一个字节就对应到utf8编码的值
一次读若干字节,比一次读一个字节来的高效(都硬盘是低效操作,而访问内存是高效操作,如果可以每次把字节攒进内存一次性从硬盘中读取,就会高效很多)
byte[] buffer = new byte[1024];
int n = inputStream.read(buffer);
if(n == -1){
//文件读取完毕
break;
}
for (int i = 0; i < n; i++) {
System.out.printf("%x ",buffer[i]);2.字符流
以字符为单位进行读写。如果是utf8来表示汉字,3个字节就是一个汉字,每次读写都得一3个字节为单位来进行读写,不能一次读写半个汉字
写入文件

第一个:一次写一个字节;
第二个:一次写若干字节--写一整个数组
第三个:写数组的一部分
OutputStream在默认情况下,会把之前文件内容都清空掉,然后再重新开始写
我在刚创建的test.txt里面写入“你好”
 ,然后执行下面的代码
,然后执行下面的代码
public static void main(String[] args) {
//清空操作是下面这行try进行的
try(OutputStream outputStream = new FileOutputStream("./test.txt")){
byte[] buffer = new byte[]{97,98,99,100,101,102};//;abcdef
outputStream.write(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
}执行结果
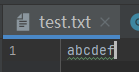 原来的“你好”没了,变成了abcdef
原来的“你好”没了,变成了abcdef
也可以不用清空原文件的内容,在原来文件的内容上追加写东西
![]()
Reader和Writer字符流
Reader的read方法(按照char为单位)


问题:char占2个字节,读取中文的时候,每个字符是3个字节的utf8,但是这里读出来的每个字符为何都变成2个字节了

此处这个代码相当于把当前文件中的utf8按照字符读取并转成Unicode,每个char[ ]数组里面存储的是对应的Unicode的值

在这个代码就把char[ ]数组转换成String utf8的形式,这个转换过程是Java已经封装好了,无法直接感知到的
Writer的write方法

基本代码模式

3.查找硬盘上的文件
给定一个文件名,去指定的目录进行搜索,找到文件名匹配的结果,并打印出完整的路径
因为文件系统目录是树形结构,所以我们需要用到递归来遍历树
注意:这里的遍历不是前,中,后序其中任何一种,因为此处是N叉树,每个节点上有很多文件
public static void main(String[] args) {
//1.输入必要的信息
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要搜索的文件名");
String fileName = scanner.next();
System.out.println("请输入要搜索的目录");
String rootPath = scanner.next();
File rootFile = new File(rootPath);
if(!rootFile.isDirectory()){
System.out.println("输入的路径有误");
return;
}
//2.有了路径之后就可以按照递归的方式来搜索
//知道递归的起点还需要知道要查询的文件名
scanDir(rootFile, fileName);
}
private static void scanDir(File rootFile, String fileName){
//1.把当前目录中的文件和目录都列出来
File[] files = rootFile.listFiles();
if(files == null){
//空的目录就直接返回
return;
}
//2.遍历上述files,判定每一个file是目录还是文件
for(File f : files){
if(f.isFile()){
//普通文件,判定文件名是否是搜索的文件
if(fileName.equals(f.getName())){
System.out.println("找到了符合要求的文件! "+f.getAbsolutePath());
}
} else if (f.isDirectory()) {
//目录文件,需要进一步的递归
scanDir(f, fileName);
}else{
;
}
}
}代码中判定文件名的操作和递归操作是混着来的,所以也解释了前中后序啥都不是的原因

4.复制文件
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要复制的原文件:");
String srcPath = scanner.next();
System.out.println("请输入要复制的目标文件:");
String destPath = scanner.next();
//文件合法性判定
//1)srcPath对应的文件是否存在
File srcFile = new File(srcPath);
if(!srcFile.isFile()){
System.out.println("源文件路径有误");
return;
}
//2)destPath 不要求对应的文件存在,但是目录得存在
File destFile = new File(destPath);
if(!destFile.getParentFile().isDirectory()){
System.out.println("目标路径有误!");
return;
}
//进行复制操作
try(InputStream inputStream = new FileInputStream(srcFile);
OutputStream outputStream = new FileOutputStream(destFile)){
while(true){
byte[] buffer = new byte[1024];
int n = inputStream.read(buffer);
if(n == -1){
break;
}
//把读到的内容写道outputStream中
outputStream.write(buffer, 0, n);
}
}
catch (IOException e) {
throw new RuntimeException(e);
}创建文件

在a1.txt里面写入120;执行程序,程序成功复制了文件

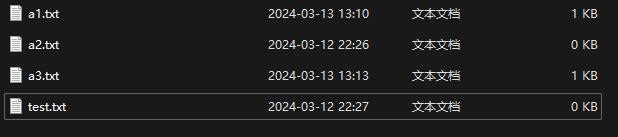
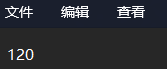
5.进阶搜索
在目录中搜索,按照文件内容搜索,用户输入目录名称和一个要搜索的词。如果在搜索过程中找到这个词就返回整个文件的路径
package io;
import java.io.*;
import java.util.Scanner;
public class IODemo15 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要搜索的路径: ");
String rootPath = scanner.next();
System.out.println("请输入要查询的词: ");
String word = scanner.next();
File rootFile = new File(rootPath);
if (!rootFile.isDirectory()) {
System.out.println("输入的要搜索的路径不正确!");
return;
}
scanDir(rootFile, word);
}
private static void scanDir(File rootFile, String word) {
File[] files = rootFile.listFiles();
if (files == null) {
return;
}
for (File f : files) {
System.out.println("当前遍历到: " + f.getAbsolutePath());
if (f.isFile()) {
// 在文件内容中搜索
searchInFile(f, word);
} else if (f.isDirectory()) {
// 递归遍历
scanDir(f, word);
} else {
// 暂时不需要
;
}
}
}
private static void searchInFile(File f, String word) {
// 通过这个方法在文件内部进行搜索
// 1. 把文件内容都读取出来.
try (InputStream inputStream = new FileInputStream(f)) {
StringBuilder stringBuilder = new StringBuilder();
while (true) {
byte[] buffer = new byte[1024];
int n = inputStream.read(buffer);
if (n == -1) {
break;
}
// 此处只是读取出文件的一部分. 需要把文件内容整体拼接在一起.
String s = new String(buffer, 0, n);
stringBuilder.append(s);
}
// 加了打印之后, 可以看到, 文件内容是对的. 说明后面的匹配有问题.
System.out.println("[debug] 文件内容: " + stringBuilder);
// 当文件读取完毕, 循环结束之后, 此时 stringBuilder 就是包含文件整个内容的字符串了.
if (stringBuilder.indexOf(word) == -1) {
// 没找到要返回.
return;
}
// 找到了, 打印文件的路径
System.out.println("找到了! " + word + " 存在于 " + f.getAbsolutePath());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}






![[JAVAEE]—进程和多线程的认识](https://img-blog.csdnimg.cn/direct/f50fc57edd544cd8a20160d3bb10ba8c.png)