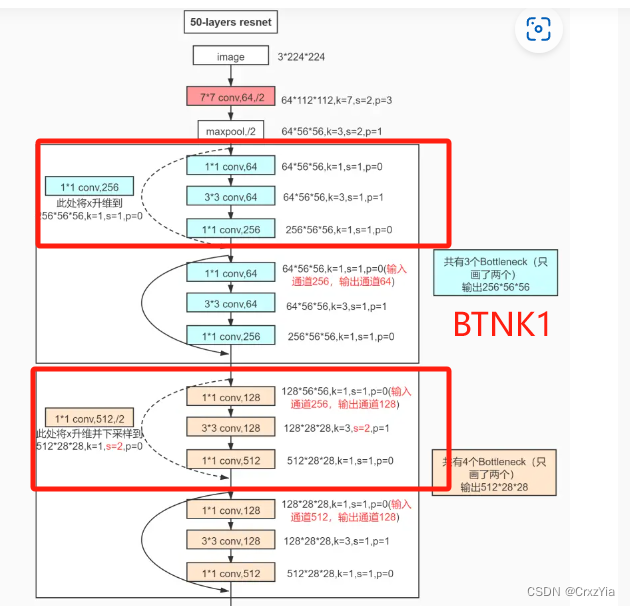
在我使用Imagenet2012对Darknet53进行预训练的时候,往往训练到一半,就会出现过拟合,导致无法继续向下训练,尝试了很多方法,最后发现问题出现在下图红框的部分。

得出这个结论是因为当我使用Resnet中,包含有下采样作用的 BTNK1结构代替了上面红框里的卷积层后,模型变得可以训练了。
表现在代码里:
原代码:
class ResidualBlock(Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
self.conv1 = Conv2d(in_channels=in_channels, out_channels=in_channels // 2, kernel_size=1, stride=1, padding=0)
self.bn1 = BatchNorm2d(in_channels // 2)
self.conv2 = Conv2d(in_channels // 2, in_channels, 3, 1, 1)
self.bn2 = BatchNorm2d(in_channels)
def forward(self, x):
y = self.conv1(x)
y = self.bn1(y)
y = leaky_relu(y)
y = self.conv2(y)
y = self.bn2(y)
y = leaky_relu(y) + x
return y修改后的代码:
class ResidualBlock(Module):
def __init__(self, in_channels, hidden_channels, shortcut=False, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = Conv2dBnLeakyReLU(in_channels, hidden_channels, 1, 1, 0)
self.conv2 = Conv2dBnLeakyReLU(hidden_channels, hidden_channels * 4, 3, stride, 1)
# self.conv3 = Conv2dBnLeakyReLU(hidden_channels, hidden_channels * 4, 1, 1, 0)
self.shortcut = Conv2dBnLeakyReLU(in_channels, hidden_channels * 4, 1, stride, 0) if shortcut else None
def forward(self, x):
if self.shortcut is None:
return x + self.conv2(self.conv1(x))
else:
return self.shortcut(x) + self.conv2(self.conv1(x))原模型代码:
class Darknet53(Module):
def __init__(self, init_weights=True, num_classes=1000):
super(Darknet53, self).__init__()
self.conv1 = Conv2dBnLeakyReLU(3, 32, 3, 1, 1)
self.conv2 = Conv2dBnLeakyReLU(32, 64, 3, 2, 1)
self.residual_block1 = ResidualBlock(64)
self.conv3 = Conv2dBnLeakyReLU(64, 128, 3, 2, 1)
self.residual_block2 = Sequential(*([ResidualBlock(128)] * 2))
self.conv4 = Conv2dBnLeakyReLU(128, 256, 3, 2, 1)
self.residual_block3 = Sequential(*([ResidualBlock(256)] * 8))
self.conv5 = Conv2dBnLeakyReLU(256, 512, 3, 2, 1)
self.residual_block4 = Sequential(*([ResidualBlock(512)] * 8))
self.conv6 = Conv2dBnLeakyReLU(512, 1024, 3, 2, 1)
self.residual_block5 = Sequential(*([ResidualBlock(1024)] * 4))
self.avg_pool = AdaptiveAvgPool2d(1)
self.fn = Linear(1024, num_classes)
if init_weights:
self._initialize_weights()修改后的模型代码:
class Darknet53(Module):
def __init__(self, init_weights=True, num_classes=1000):
super(Darknet53, self).__init__()
self.conv1 = Conv2dBnLeakyReLU(3, 32, 3, 1, 1)
# self.conv2 = Conv2dBnLeakyReLU(32, 64, 3, 2, 1)
self.conv2 = ResidualBlock(32, 16, shortcut=True, stride=2)
self.residual_block1 = ResidualBlock(64, 16)
# self.conv3 = Conv2dBnLeakyReLU(64, 128, 3, 2, 1)
self.conv3 = ResidualBlock(64, 32, shortcut=True, stride=2)
self.residual_block2 = Sequential(*([ResidualBlock(128, 32)] * 2))
# self.conv4 = Conv2dBnLeakyReLU(128, 256, 3, 2, 1)
self.conv4 = ResidualBlock(128, 64, shortcut=True, stride=2)
self.residual_block3 = Sequential(*([ResidualBlock(256, 64)] * 8))
# self.conv5 = Conv2dBnLeakyReLU(256, 512, 3, 2, 1)
self.conv5 = ResidualBlock(256, 128, shortcut=True, stride=2)
self.residual_block4 = Sequential(*([ResidualBlock(512, 128)] * 8))
# self.conv6 = Conv2dBnLeakyReLU(512, 1024, 3, 2, 1)
self.conv6 = ResidualBlock(512, 256, shortcut=True, stride=2)
self.residual_block5 = Sequential(*([ResidualBlock(1024, 256)] * 4))
self.avg_pool = AdaptiveAvgPool2d(1)
self.fn = Linear(1024, num_classes)
if init_weights:
self._initialize_weights()于是有了大胆的猜测,Darknet相比Resnet,因为中间的下采样卷积层没有残差结构连接,所以模型实际上是被分割了,小loss很难向后传播到模型头部,所以会逐渐倾向于用尾部的几层网络来拟合数据,刚好Darknet的尾部很重,所以模型会逐渐走向过拟合,
以下内容就是发牢骚,但我真的好气呀,明明这么信任它。
熟悉YOLO系列的同学应该都知道,Darknet53是YOLOv3的主干网络,本人乘着暑假也在学习YOLO,从1学到了3,基本上都会用代码复现一遍,和作者所说的效果过基本吻合以后再开始新的篇章,直到遇上了Darknet53,按照作者的话说,Darknet53在ImageNet2012上的效果堪比Resnet152,而速度几乎是Resnet的2两倍。才看到这句话,我是不信的,人家Resnet152比你怎么说也多了近100层,你说这效果差不多,那Resnet家族不是很尴尬,这家人以后还怎么混是吧。但一想,YOLOv3也是久经考验的老同志了,要是数据造假,那不是早就被拖出来游街了,奈何网上又找不到相关的资料,那就自己上手训练吧。
Darknet53的网络并不复杂,用pytorch不用半个小时就搭建好了,上数据,开炼。
本人只有一张游戏显卡,为了速度上了混合精度,懒得调参,优化器用了Adam,100个epoch差不多也跑了一整天。
一看效果,在train上Top1 acc到了80,而在val上有65。这可比论文里的77.2差远了,可能是开了混合精度造成的损失?关了试一试吧,好,又是两天过去了,这次再val上的Top1 acc到了68,步子迈进了一步,可还是离77.2差了一截,难道是Adam的锅,那换SGDM再来!没想到,噩梦开始了。
自从换上SGDM,val的指标没有再突破过50,val在上升一定数值后就会逐步下降,毫无疑问,过拟合了。
batchsize小了?上梯度累计,不行!
weight_decay大了?换!,1e-4,1e-3,1e-2,1e-1,1...不行!
学习率设置大了?上指数衰减,上余弦衰减,上重启机制,全都失败。
找github看别人的代码,一行行对比,没什么区别。
怀疑过激活函数,怀疑过batchnorm,统统没用!!!
impossible!‘质子’干扰了实验。
啥都怀疑过,就是没怀疑过是网络本身的问题,毕竟有人复现过,当然都没说100%,github的同学跑出的数据是75,那也比咱强。
直到前前后后快半个月,所有能想到的方案我都试过后,一切的矛头都指向了Darknet53本身,它怎么就那么爱背答案。
砍,把后面的残差块砍掉一半。
可它死性不改,就是背。
明明Resnet50和它的层数差不多,但人家就没那么爱过拟合,到底是哪里出问题了。
抱着这个疑问,那就一点点测。
把Resnet的三层残差结构给他,不行!
把Resnet顶部的7X7卷积给他,不行!
直到!直到!直到!把Resnet用来代替池化层的BTNK1给它。
动了,它动了!问题找到了,是连接残差块的卷积层,它阻塞了loss向深度回传,在加上Darknet53很重的脚,所以只能走向过拟合。
这里面还出现了一个有意思的现象,在大学习率阶段,这种过拟合并不会太明显,但当学习率开始衰减,那么网络就会开始走向灭亡,这可能是由于在学习率较大时,loss还能有部分穿过残差块之间的间隙,而学习率逐步衰减,网络就只能靠底部的神经元进行学习了。
最后就只剩一个疑问,github上那些跑到75+的代码究竟用了什么魔法喂!。


![[JAVAEE]—进程和多线程的认识](https://img-blog.csdnimg.cn/direct/f50fc57edd544cd8a20160d3bb10ba8c.png)





![[论文精读]Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection](https://img-blog.csdnimg.cn/direct/44365d6ab5ce4781ba984c84ae0df9b5.png)