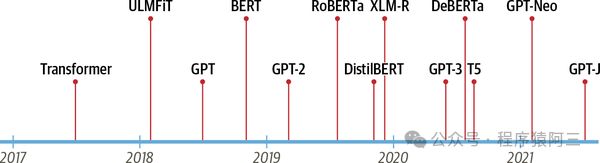
在《机器学习综述》中大致罗列人工智能常见算法,近些年深度学习发展快速,其中Transformer为甚,其英文的意思是变形金刚,对的就是我们看电影变形金刚的意思。Transformer是大语言模型的基础,比如现在常见的GPT、Bert、PaLM等大模型。Transformer概念是由谷歌在2017年《Attention is All You Need》首次提出。它提出了sequence to sequence with self-attention机制,利用attention解决RNN等长文本无法并行计算。
参考李宏毅的视频,来全面介绍一下Transformer的原理。
1 背景
在transformer出现之前,一般采用的是基于RNN(包括其变种LSTM、GRU等)或CNN的encoder-decoder框架。
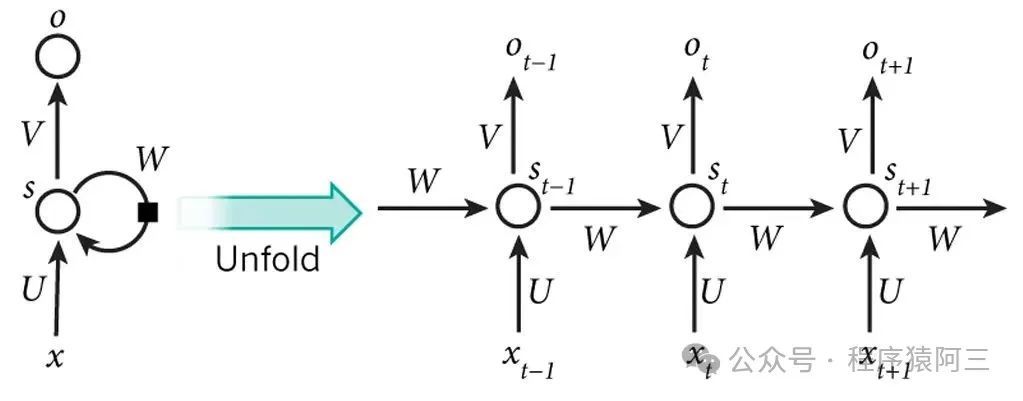
由于RNN模型是按照时间顺序处理文本(如上图),无法并行计算,在长文本中处理中经常出现梯度消失和爆炸问题,同时需要大量内存维护隐藏状态。
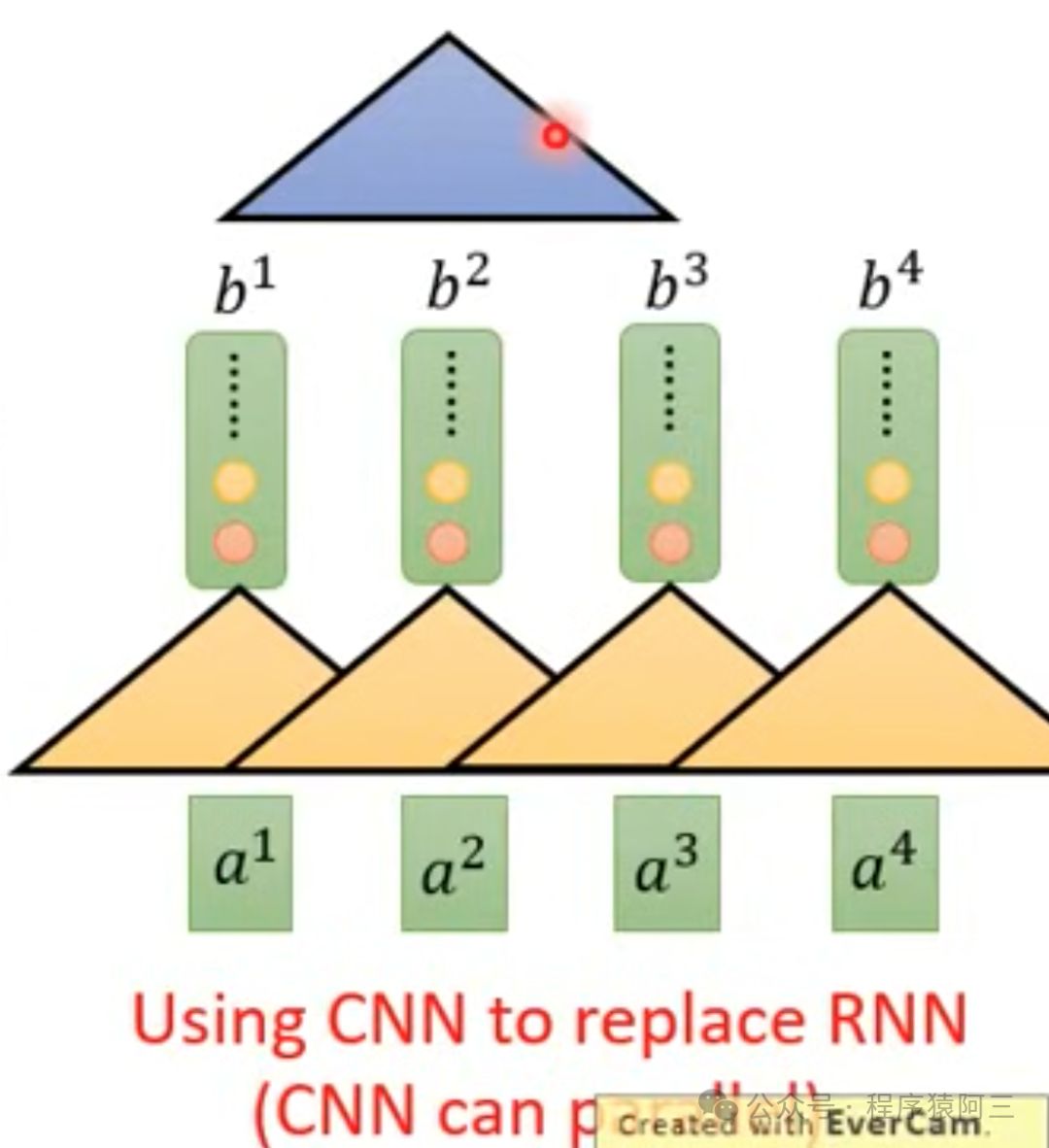
后面也有人使用CNN去做文本并行计算(如上图),但是CNN缺少长时依赖建模能力,很难捕捉长距离的语义关系。
2 Transformer架构应运而生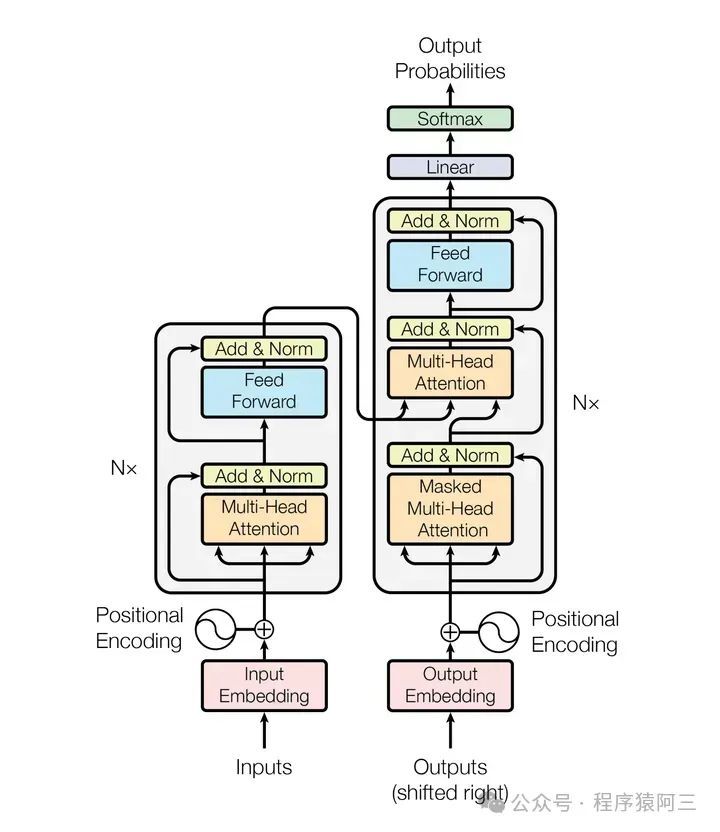
Transformer架构包括编码器和解码器2部分。
2.1 输入向量化
2.1.1 词向量
首先对输入文本进行向量化。计算机无法识别字符,只识别数字,将现实生活中的文字映射成计算机能够识别的向量。
2.1.2 位置向量
由于是并行计算,文本的顺序看错是被打乱了,为了让同个词在不同文本中的含义不一样,将位置向量考虑进来,不是简单将2个向量相加,而是进行连接串起来。
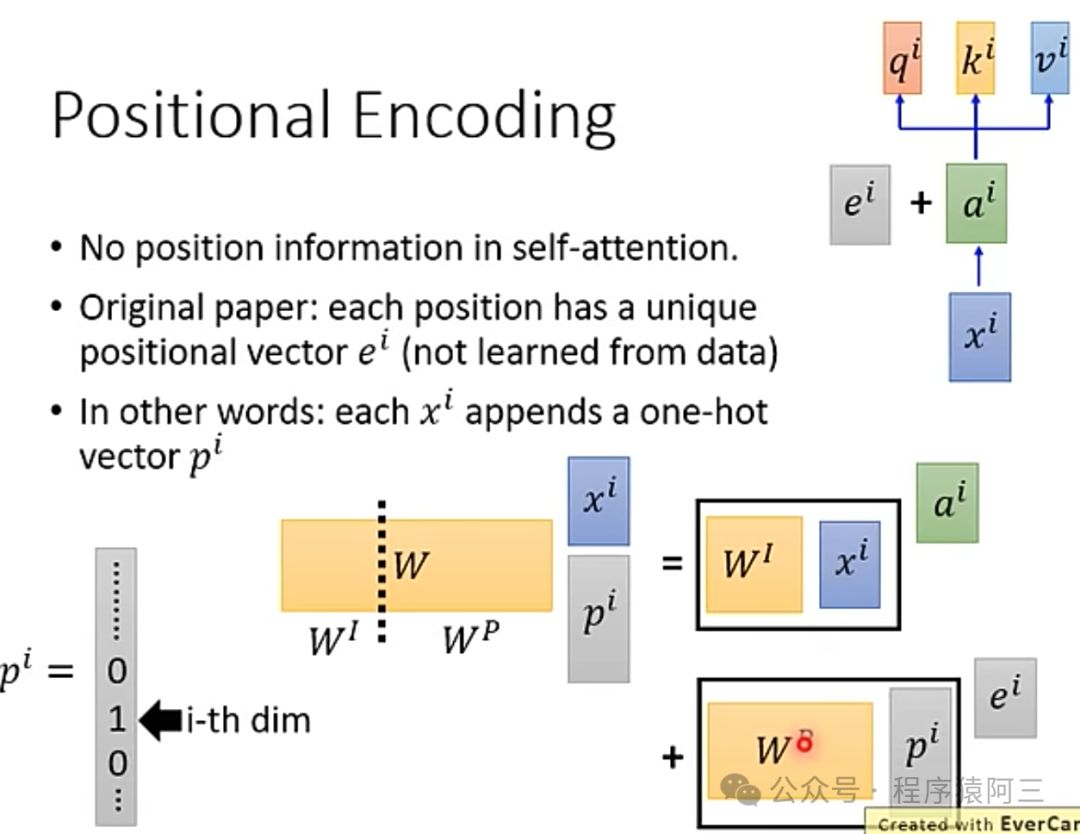
常见的位置向量有人工预设和自学习方式。
2.2 自注意力机制
在Encoder和Decoder机制中都有Attention机制,何为自注意力机制,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性,能够专注输入的不同部分,正如人类在处理信息会更加关注某些细节和词语。注意力机制是基于三个向量运作的:
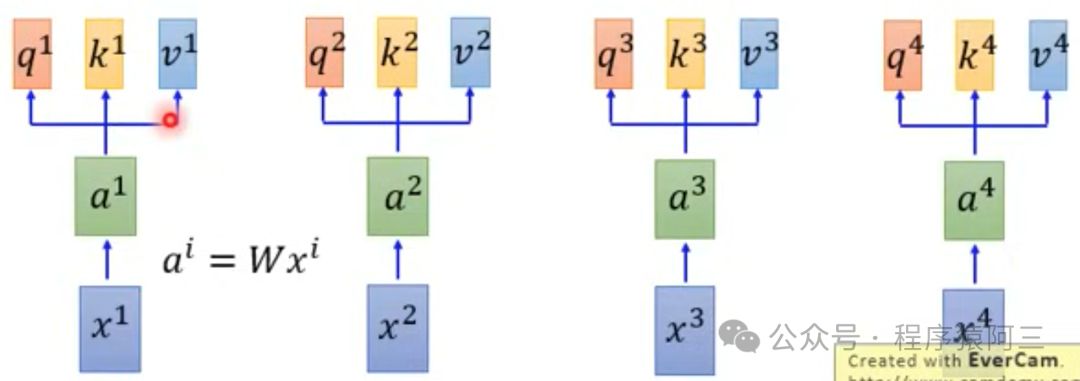
查询(Queries):取匹配其他部分的作用
键(Key):用来被匹配的
值(Values):被抽取出来的信息
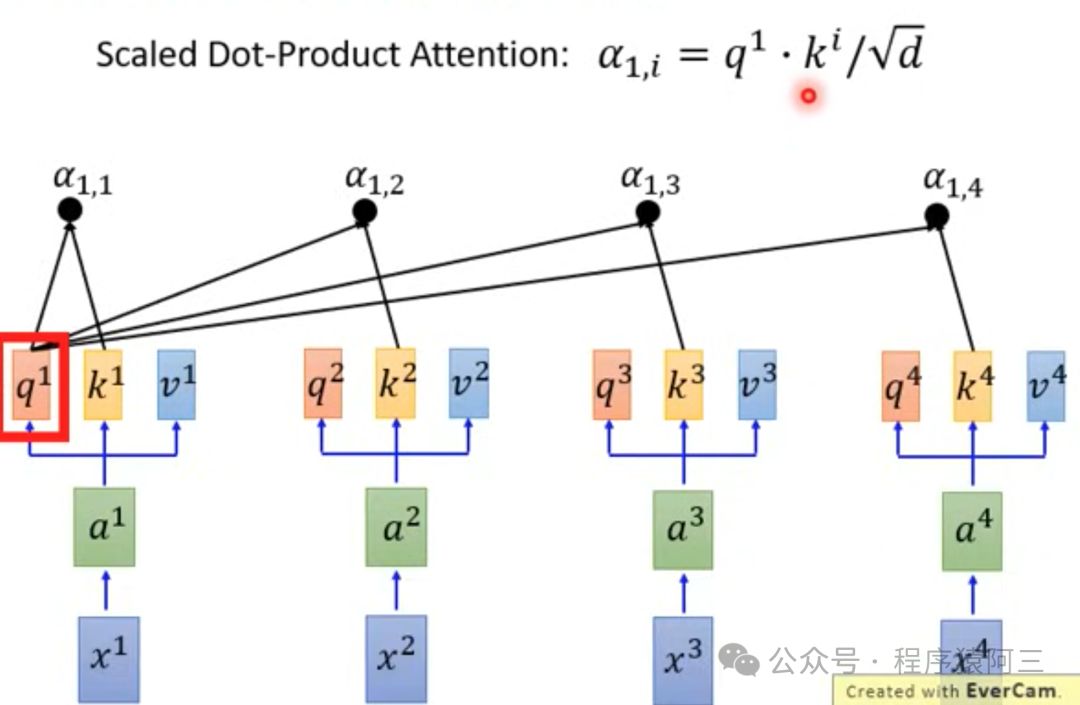
接下来,将每个Query去对每个Key做Attention,得到一个分数,决定了模型对输入各个部分的关注度。通过Softmax函数之后,得到正则化的关注评分:
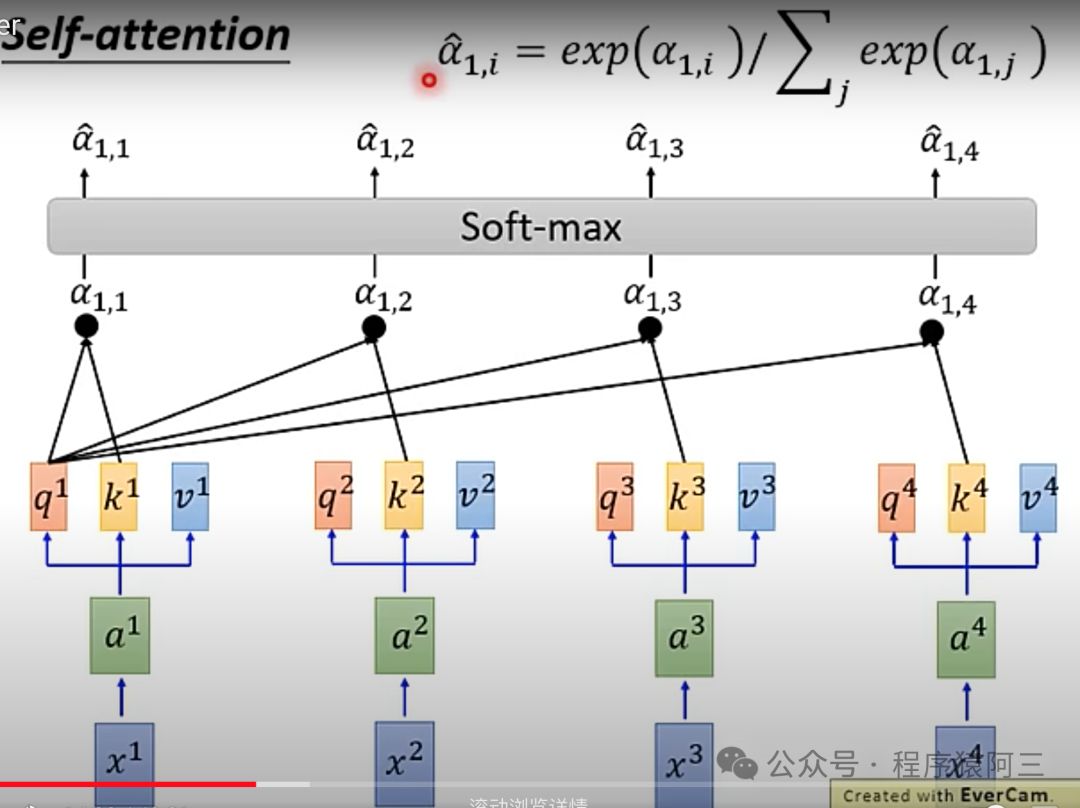
关注度与每个抽取信息作乘积求和,得到输出的第一个向量b1,产生b1已经看到所有输入,并且跟所有输入有不同关注,比如,需要不关心某i个位置输入,只要将a1,i设置为0。
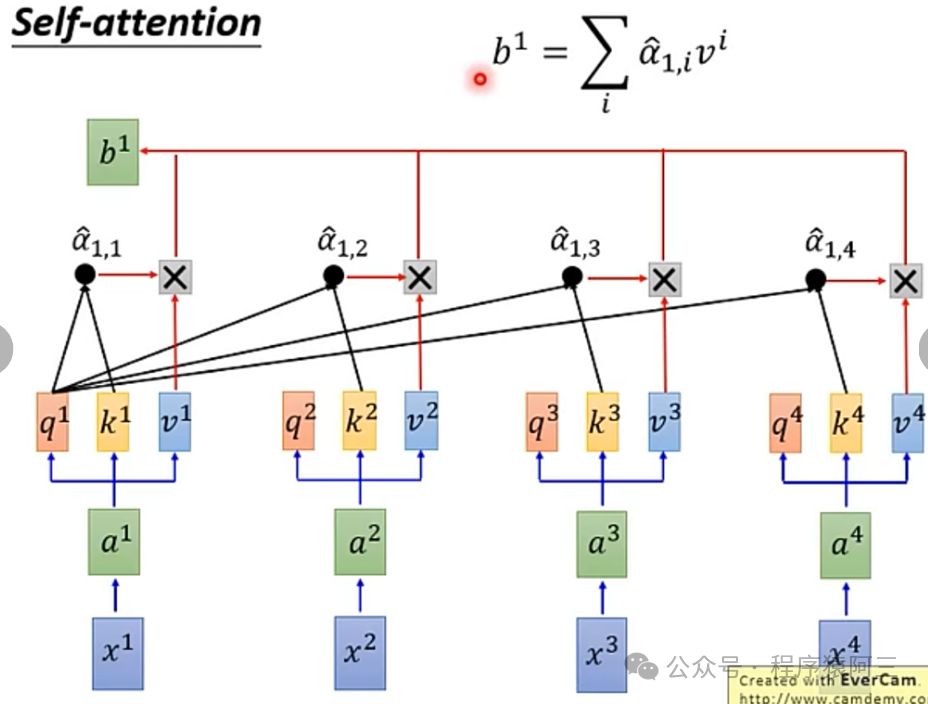
参考上述的计算逻辑,可以计算出每个位置的输出向量(注意这个过程可以并行),而RNN生成必须按照a1、a2、a3、a4顺序计算。这个也是为什么Transformer在速度,伸缩性上较RNN来说要好很多。
2.3 多头注意力机制
所谓多头注意力机制,是基于上述注意力机制,分化出多个q、k、v,如下图所示,以2个头为例。
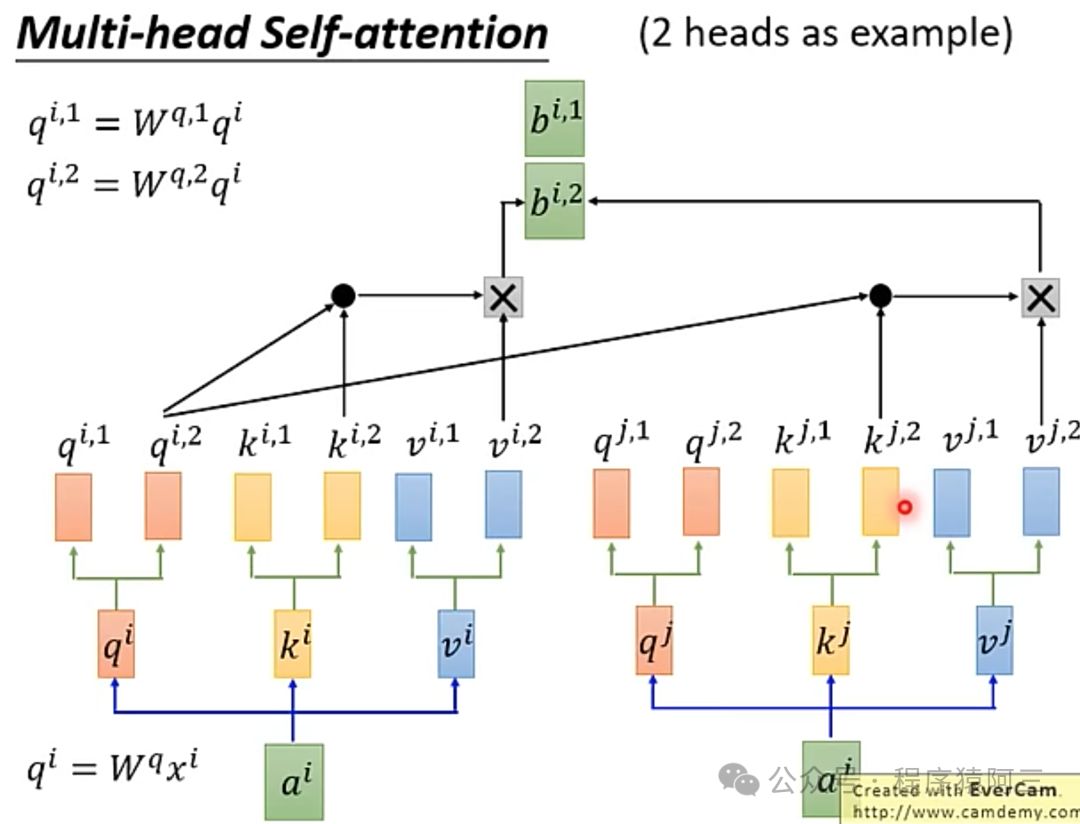
为啥要做多头呢?在文章《Attention Is You Need》中提到,多个头为的是可以有多个关注点,每个关注点关注的内容不一样。
2.5 Encoder架构
在了解向量化和注意力机制之后,我们来进一步剖析Transformer中的Encoder架构。
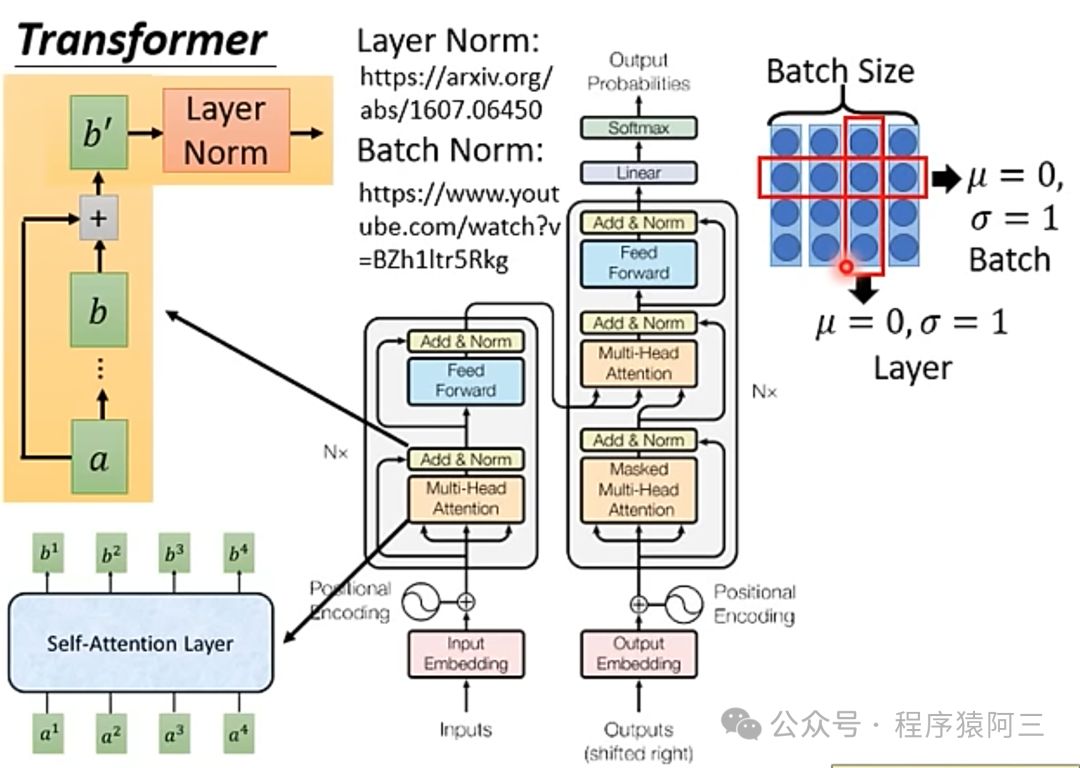
Muli-Head Attention就是上面介绍的多头注意力机制,在注意力机制层后,多了一个Add&Norm层,再进行全链接层,最后再来一个Add&Norm层,其中Add&Norm层就是输入+输出再进行Layer Norm结果。这样Encoder架构可以叠加N个。
2.6 Decoder架构
Transformer Decoder与Encoder最大不同之处在于Decoder有两个注意层。
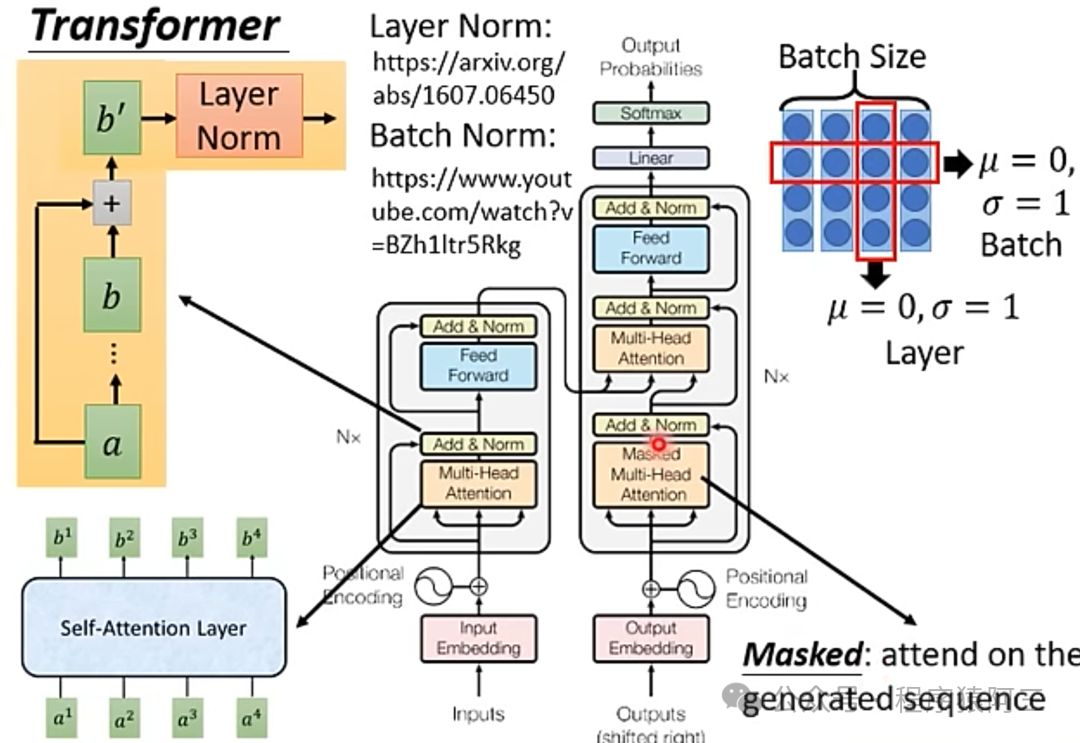
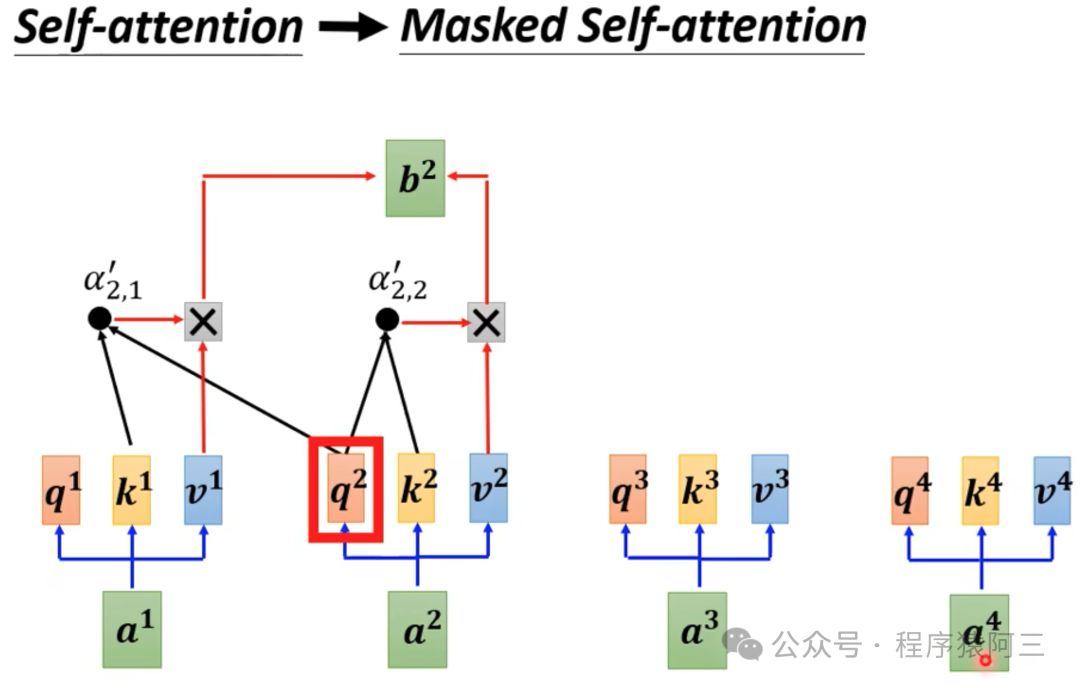
Masked Multi-head self-attention layer: 确保在每个时间的词语是基于过去的输出和当前的预测词语。
Encoder-decoder attention layer:以解码器的中间表示作为 queries,对 encoder stack 的输出 key 和 value 向量执行 Multi-head Attention。通过这种方式,Encoder-Decoder Attention Layer 就可以学习到如何关联来自两个不同序列的词语。
2.7 Encoder和Decoder如何产生关系
主要是使用了cross attention机制:
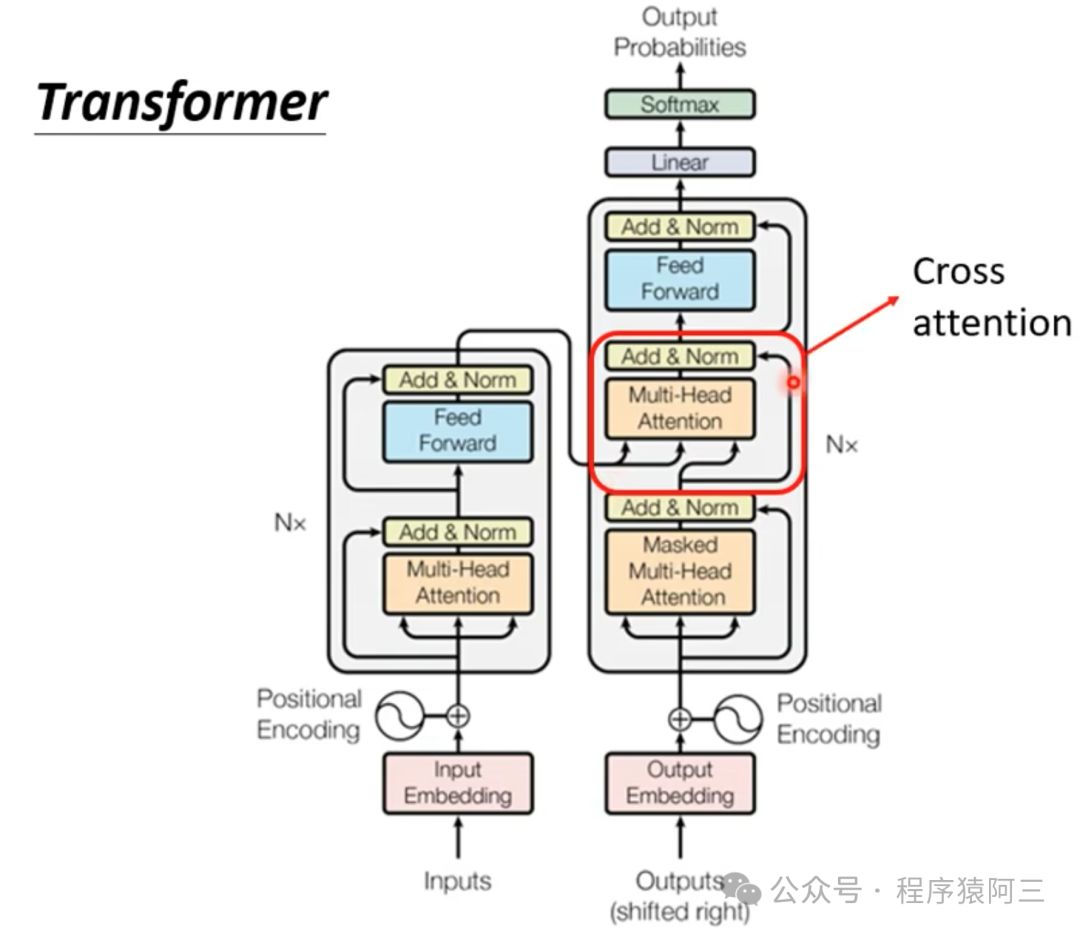
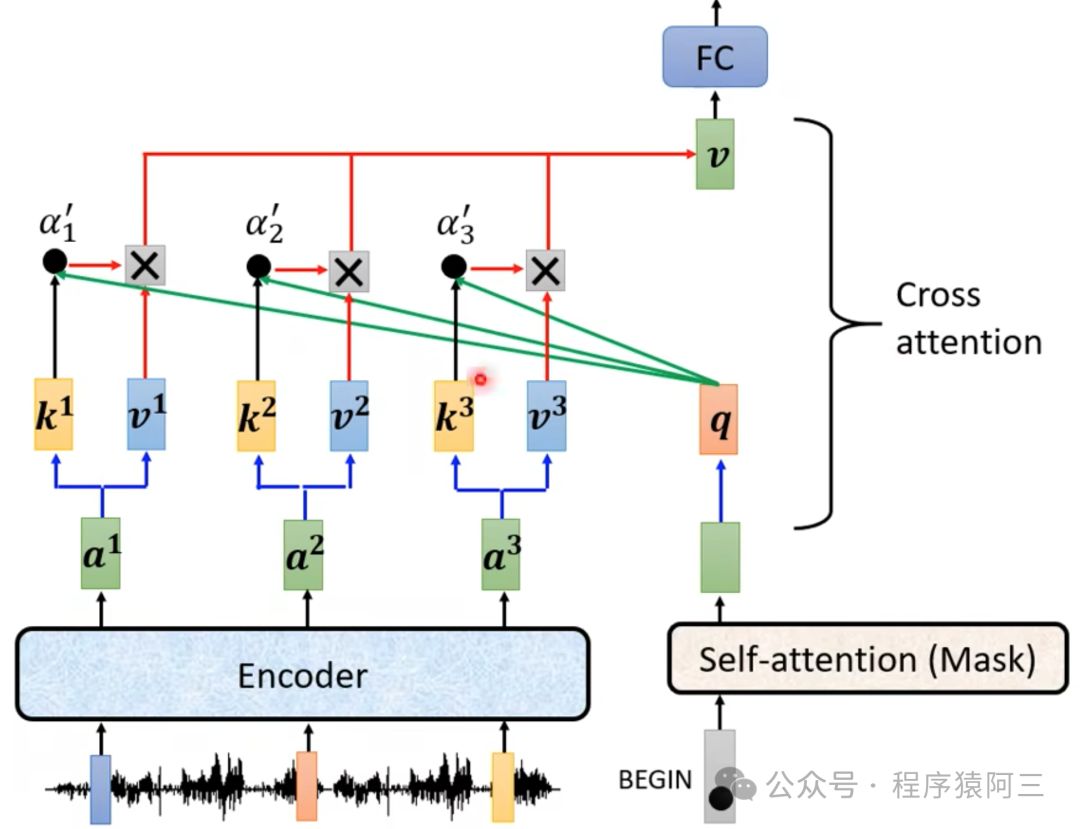
decoder生成queries,对 encoder stack 的输出 key 和 values 向量执行 Multi-head Attention。通过这种方式,Encoder-Decoder Attention Layer 就可以学习到如何关联来自两个不同序列的词语,例如两种不同的语言。解码器可以访问每个 block 中 Encoder 的 keys 和 values。
 3 应用场景
3 应用场景
transformer不仅仅可以应用于文本领域:
(1)语音
(2)图像识别(CNN是特殊的self-attention)
(3)NLP(文本摘要、文本情感等)
(4)GNN(图网络)
(5).......
等等,为很多领域提供了新的思路和工具,Transformer在人工智能有一统模型江湖的感觉。