上一篇文章中,我们解读了Transformer中的Self-Attention的实现细节,这篇文章中,就Transformer的整体做一个算法解读。
首先,我们还是把Transformer的架构图贴出来,作为本篇内容的抓手。

从图中我们可以看到,网络中有三种Attention,分别是:(1) Encoder中的Multi-Head Attention,(2) Decoder中的Multi-Head Attention(Encoder-Decoder Attention),(3) Decoder中的 Masked Multi-Head Attention。所以,接下来,我们先从Multi-Head Attention讲起。
1. Multi-Head Attention
Jay Alammar把多头注意力机制比喻成多头兽。它的结构如下图所示:

那么这头多头兽能带来什么优势呢?
首先,它能提升模型关注不同位置的能力,这在较复杂的句子翻译中非常有用;
其次,它为注意力层提供了多重表示子空间(Representation subspaces)。
在Muti-Head Attention中,我们有多套Query/Key/Value的权重矩阵,在论文中,这个数量为8。每套权重矩阵都被随机初始化,并且在经过训练后,每套Query/Key/Value矩阵可以将输入embeddings映射到不同的表示子空间。

现在问题来了,这8套Q/K/V将会产生8个输出Z0, Z1, ... , Z7,而后续的Feed-Forward模块只接收一个矩阵输入,这8个输出将如何整合在一起呢?这就需要想办法把它们压缩进一个矩阵。具体做法是,将8个输出级联到一起变成一个矩阵,然后再与一个权重矩阵WO做矩阵乘法,得到最终的输出矩阵Z:

论文中给出的公式是:

好了,以上就是Multi-Head Attention的实现方式了。总结一下,每一层的Multi-Head Attention完整实现如下图所示。(感谢Jay Alammar,为我们提供这么直观的示意图)。

前面我们讲到,Multi-Head Attention在Transformer中的应用,主要有三种方式。
1. 在Encoder中的Multi-Head Attention:Q/K/V都来自于上一层Encoder的输出,对每个位置的编码,都能参考上一层输出中的所有其他位置。
2. Decoder中的Encoder-Decoder Attention:Q来自于上一层Decoder的输出,而K和V则来自于Encoder的输出。
3. Decoder中的Masked Multi-Head Attention:在掩码模式中,每个位置可以参考截至该位置的所有位置信息,也就是只能参考该位置之前的信息,对于不能参考的位置信息,在点积操作中,通过设置mask的方式(setting to -inf)来阻止访问非法位置。
2. Positional Encoding
由于网络不含递归和卷积操作,我们需要想办法把序列元素的位置信息利用起来。论文中使用的方法是,将位置信息的编码加入到底部Encoder和Decoder的Embeddings上。

具体编码方式如下列公式所示,pos是词语位置,i为维度index(总维度大小为512,i的取值范围应为0~511)。
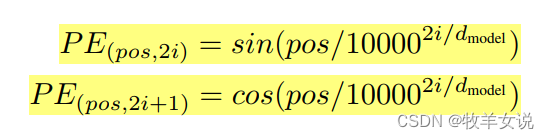
这样计算出来的位置编码数据范围在[-1,1]之间,因此,假如输入embedding的维度为4,则下图可以帮助我们理解上面的加法操作:

当然,上图是个非常简化的示意图,并且该图存在一点问题,偶数维度和奇数维度应该是交错排列,原图作者是将其concate在了一起。实际上,编码的维度与输入embedding的维度一致,在论文实现中为512。
3. Position-wise Feed-Forward Networks
Feed-Forward模块相对较简单,对每个位置进行两次线性变换(当然,不同Layer的Weight不同),中间使用了一个ReLU激活:
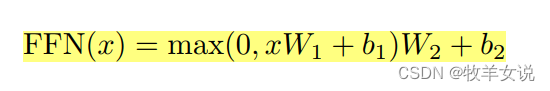
以上公式也可以描述为两个kernel为1的卷积。FFN模块的输入和输出维度都是512,中间维度为2048。
4. The Residuals
从Transformer的模型结构我们可以看到,该模型中使用了残差连接。把模型的局部放大,大概是下面这个样子:

向量加法后面紧接着会做一个Layer Normalization的操作。
残差连接在Encoder和Decoder中都有应用,例如,2层Encoder和2层Decoder的Transformer结构大致如下:

5. The Final Linear and Softmax Layer
Decoder输出的是float向量,那么这个浮点向量如何转换成词语呢?这就是最后Linear Layer和Softmax Layer干的事情。
Linear层是一个简单的全连接网络,它的作用是将Decoder的输出向量(维度为512)映射到一个更大的向量,称为logits向量。
logits向量的维度对应模型所知道的词汇表的大小,假设模型训练中,已知10000个英语单词,那么logits向量则有10000个元素的维度,每个元素对应一个单词的分数。
而Softmax层则是将词汇分数转换成0.0~1.0之间的概率,拥有最高概率的词语将被选中并输出。

6. How the Network works?
好了,以上就是Transformer中各个模块的解读,相信你已经对每个模块都比较清晰了。那么,整个Transformer是如何工作的呢?下面这个动图很好地说明了整个网络的工作过程。

正如前面我们讲Multi-Head Attention时提到过的,Decoder的Attention模块与Encoder有所不同。
首先,Decoder有两个Attention模块,Masked Mutli-Head Attention只允许关注当前位置之前的位置,对于未来的位置则通过在softmax之前将其设置为-inf来将其“屏蔽”掉,从上图也可以看出来,Decoder会将之前的输出当作当前位置的输入,来预测当前位置的输出。
其次,Encoder-Decoder Attention, Query矩阵来自上一层Decoder,而Key矩阵和Value矩阵来来自Encoder的输出。
参考资料:
1.《The Illustrated Transformer》
2. 《Attention Is All You Need》