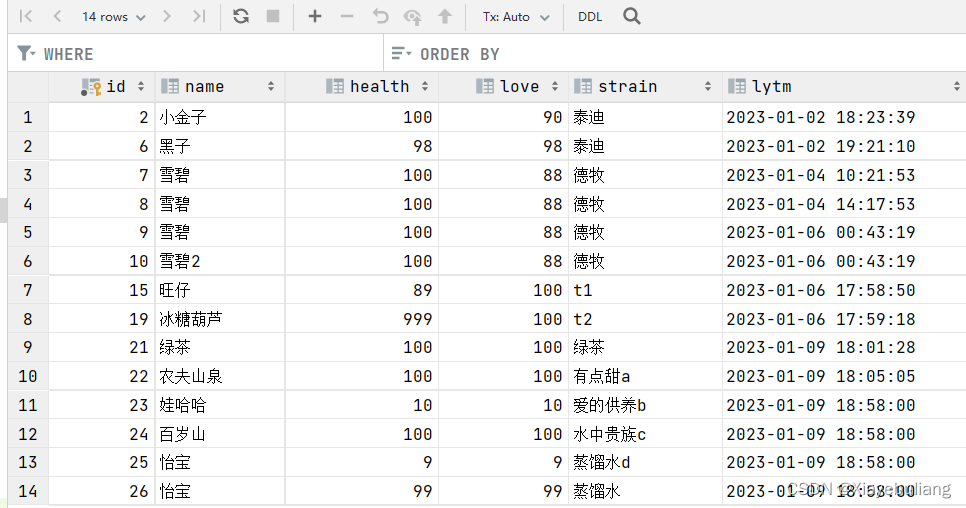
案例
calc.y
%union
{
int ival;
const char *sval;
}
%token <ival> NUM
%nterm <ival> exp
%token <sval> STR
%nterm <sval> useless
%left '+' '-'
%left '*'
%%
exp:
exp '+' exp
| exp '-' exp
| exp '*' exp
| exp '/' exp
| NUM
;
useless: STR;
%%
编译
$ bison --report=state calc.y
calc.y: warning: 1 nonterminal useless in grammar [-Wother]
calc.y: warning: 1 rule useless in grammar [-Wother]
calc.y:20.1-7: warning: nonterminal useless in grammar: useless [-Wother]
20 | useless: STR;
| ^~~~~~~
calc.y: warning: 7 shift/reduce conflicts [-Wconflicts-sr]
calc.y: note: rerun with option '-Wcounterexamples' to generate conflict counterexamples
Output文件分析
$ cat calc.output
第一部分:无用tokens
Nonterminals useless in grammar
useless
Terminals unused in grammar
STR
Rules useless in grammar
6 useless: STR
第二部分:冲突总结
State 8 conflicts: 1 shift/reduce
State 9 conflicts: 1 shift/reduce
State 10 conflicts: 1 shift/reduce
State 11 conflicts: 4 shift/reduce
第三部分:打印语法树
Grammar
0 $accept: exp $end
1 exp: exp '+' exp
2 | exp '-' exp
3 | exp '*' exp
4 | exp '/' exp
5 | NUM
第四部分:tokens的使用情况报告
POSIX只允许%type表示终结符,但是bison也允许%nterm标记终结符。
含义: 终结符符号 |(ASCII码)| 在几号语法规则中用到了
Terminals, with rules where they appear
$end (0) 0
-- 实例: '*' (42) 3
-- 含义: 终结符乘号 (ASCII42) 在3号语法规则中用到了
'+' (43) 1
'-' (45) 2
'/' (47) 4
error (256)
NUM <ival> (258) 5
STR <sval> (259)
Nonterminals, with rules where they appear
$accept (9)
on left: 0
exp <ival> (10)
on left: 1 2 3 4 5
on right: 0 1 2 3 4
第五部分:状态0
- 进入状态机。
- 每个item都用”点规则“描述状态。
- 点规则即:使用"•"标记输入位置的规则。
状态0:
- 当前在exp之前的位置,进入状态0。
- 在状态0时,收到了一个reduce出来的exp,状态机进入状态2。
- 如果没有非终结符exp上来,向前看是一个number,则符号发生移进,进入解析堆栈,状态机进入状态1。
State 0
0 $accept: • exp $end
NUM shift, and go to state 1
exp go to state 2
第六部分:状态1
状态1:
- 注意•的位置!输入的位置在后面,说明规则5:
5 exp: NUM •已经匹配上了。不管lookahead是什么,解析器都会开始规约。 - 如果他是从状态机0过来的,规约完成了会跳回状态0。状态0收到exp后会跳到状态2。
$default表示任何向前看lookahead的字符(•位置表示的字符)是什么都能匹配上后面的规则。
State 1
5 exp: NUM •
$default reduce using rule 5 (exp)
第七部分:状态2
状态2:注意dot的位置。
- 状态2只能移进一个符号。
- 比如
exp • '+' expdot向前看来了一个'+',则移进解析堆栈,转移到状态4。 - 没有default,如果匹配补上,直接
syntax error。
State 2
0 $accept: exp • $end
1 exp: exp • '+' exp
2 | exp • '-' exp
3 | exp • '*' exp
4 | exp • '/' exp
$end shift, and go to state 3
'+' shift, and go to state 4
'-' shift, and go to state 5
'*' shift, and go to state 6
'/' shift, and go to state 7
第八部分:状态3
状态3:
- 最终状态 或 accepting状态。
- 初始规则匹配完成,解析成功并退出。
State 3
0 $accept: exp $end •
$default accept
第九部分:状态4-7
状态4:
- 如果dot后面是num,移进解析堆栈后转移到状态1。
- 如果dot后面是非终结符exp,进入状态8。
State 4
1 exp: exp '+' • exp
NUM shift, and go to state 1
exp go to state 8
State 5
2 exp: exp '-' • exp
NUM shift, and go to state 1
exp go to state 9
State 6
3 exp: exp '*' • exp
NUM shift, and go to state 1
exp go to state 10
State 7
4 exp: exp '/' • exp
NUM shift, and go to state 1
exp go to state 11
第十部分:状态8
回忆下所有rules:
Grammar
0 $accept: exp $end
1 exp: exp '+' exp
2 | exp '-' exp
3 | exp '*' exp
4 | exp '/' exp
5 | NUM
状态8
- 产生冲突的符号是出现两次的
'\''\'的第一个选择:走rule4,把’'移进解析堆栈。'\'的第二个选择:走rule1把前面的exp'+'exprecude掉,再处理后面的’'。
- 上述问题原因是
'\'与'+'之间没有优先级,可能出现:NUM + (NUM / NUM)(NUM + NUM) / NUM
State 8
1 exp: exp • '+' exp
1 | exp '+' exp • [$end, '+', '-', '/'] (使用--report=lookahead能看到末尾dot代表的字符)
2 | exp • '-' exp
3 | exp • '*' exp
4 | exp • '/' exp
'*' shift, and go to state 6
'/' shift, and go to state 7
'/' [reduce using rule 1 (exp)]
$default reduce using rule 1 (exp)
State 9
1 exp: exp • '+' exp
2 | exp • '-' exp
2 | exp '-' exp •
3 | exp • '*' exp
4 | exp • '/' exp
'*' shift, and go to state 6
'/' shift, and go to state 7
'/' [reduce using rule 2 (exp)]
$default reduce using rule 2 (exp)
State 10
1 exp: exp • '+' exp
2 | exp • '-' exp
3 | exp • '*' exp
3 | exp '*' exp •
4 | exp • '/' exp
'/' shift, and go to state 7
'/' [reduce using rule 3 (exp)]
$default reduce using rule 3 (exp)
第十一部分:状态11
状态11:
- 除了缺乏优先级外,也缺失结合性。
(1/2)/3和1/(2/3)无法区分。- 选择:
'/' shift, and go to state 7 - 还是选择:
'/' [reduce using rule 4 (exp)]
- 选择:
State 11
1 exp: exp • '+' exp
2 | exp • '-' exp
3 | exp • '*' exp
4 | exp • '/' exp
4 | exp '/' exp •
'+' shift, and go to state 4
'-' shift, and go to state 5
'*' shift, and go to state 6
'/' shift, and go to state 7
'+' [reduce using rule 4 (exp)]
'-' [reduce using rule 4 (exp)]
'*' [reduce using rule 4 (exp)]
'/' [reduce using rule 4 (exp)]
$default reduce using rule 4 (exp)
bison --report=state和lookahead的区别
lookahead会补充最后的dot,列出可能性。

bison --report=state和itemset的区别
itemset会展开item项目,展开非终结符,补充非终结符的内容。

bison --report=state和solved的区别
solved会尝试给出解决方法。

bison --report=state和counterexamples的区别
counterexamples会给出用例。