目录
一、线程资源的分配
(一)线程私有资源
(二)线程共享资源
二、原生线程库
三、线程控制接口
(一)线程创建 - pthread_create()
1. 一个线程
2. 一批线程
(二)线程等待 - pthread_join()
(三)线程终止 - pthread_exit()
四、线程实操
五、线程控制接口补充
(一)关闭线程 - pthread_cancel()
(二)获取线程ID - pthread_self()
(三)线程分离 - pthread_detach()
六、线程库的深入理解
(一)线程的ID
(二)线程独立栈
(三)线程的局部存储
一、线程资源的分配
(一)线程私有资源
我们已经知道一个结论:Linux 中没有真线程,只有复用 PCB 设计思想的 TCB 结构。
因此 Linux 中的线程本质上就是 轻量级进程(LWP),一个进程内的多个线程看到的是同一个进程地址空间,所以所有的线程可能会共享进程的大部分资源。
但是如果多个执行流(多个线程)都使用同一份资源,如何确保自己的相对独立性呢?
- 相对独立性:线程各司其职,不至于乱成一锅粥
显然,多线程虽然共同 “生活” 在一个进程中,但也需要有自己的 “隐私”,而这正是 线程私有资源
线程私有资源:
- 线程 ID:内核观点中的 LWP
- 一组寄存器: 线程切换时,当前线程的上下文数据需要被保存
- 线程独立栈: 线程在执行函数时,需要创建临时变量
- 错误码 errno: 线程因错误终止时,需要告知父进程
- 信号屏蔽字: 不同线程对于信号的屏蔽需求不同
- 调度优先级: 线程也是要被调度的,需要根据优先级进行合理调度
其中,线程最重要的资源是 一组寄存器(体现切换特性)和 独立栈(体现临时运行特性),这两个资源共同构成了最基本的线程。
(二)线程共享资源
除了上述提到的 线程私有资源 外,多线程还共享着进程中的部分资源。
共享的定义:不需要太多的额外成本,就可以实现随时访问资源。
基于 多线程看到的是同一块进程地址空间,理论上 凡是在进程地址空间中出现的资源,多线程都是可以看到的,但实际上为了确保线程调度、运行时的独立性,只能共享部分资源。
这也就是线程中的栈区称作 “独立栈” 的原因:某块栈空间属于某个线程,其他线程是可以访问的,为了确保独立性,并不会这样做。
在 进程地址空间 中,诸如 共享区、全局数据区等 这类天生自带共享属性的区域支持 多线程共享: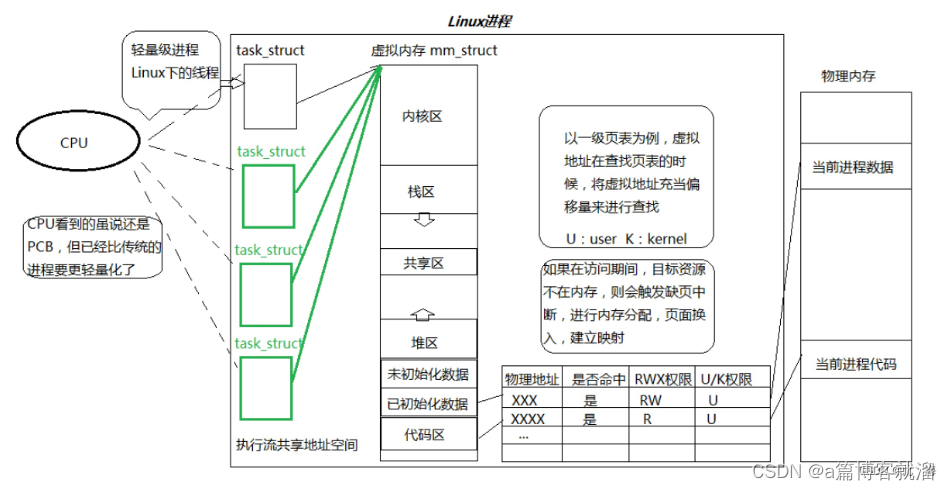
在 Linux 中,多线程共享资源如下:
- 共享区、全局数据区、字符常量区、代码区: 常规资源共享区
- 文件描述符表: 进行 IO 操作时,无需再次打开文件
- 每种信号的处理方式: 多线程共同构成一个整体,信号的处理动作必须统一
- 当前工作目录: 即使是多线程,也是位于同一工作目录下
- 用户 ID 和 组 ID: 进程属于某个组中的某个用户,多线程也是如此
其中,线程 较重要 的共享资源是:文件描述符表;涉及 IO 操作时,多线程 多路转接 非常实用
进程和线程关系图示: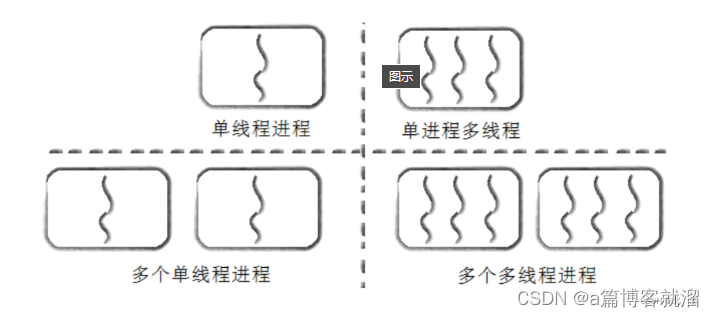
二、原生线程库
在之前编译多线程相关代码时,我们必须带上一个选项:-lpthread,否则就无法使用多线程相关接口,带上这个选项的目的很简单:使用 pthread 原生线程库。
接下来对 原生线程库 进行一个系统性的理解:
首先,在 Linux 中是没有真正意义上的线程的,有的只是通过进程模拟实现的线程(LWP)
- 站在操作系统角度:并不会提供对线程控制的相关接口,最多提供轻量级进程操作的相关接口
- 但对于用户角度来说:只认识线程,并不清楚轻量级进程
所以为了使用户能愉快的对线程进行操作,就需要对系统提供的轻量级进程操作相关接口进行封装:对下封装轻量级进程操作相关接口,对上给用户提供线程控制的相关接口。这里很好的体现了计算机界的哲学:通过添加一层软件层解决问题:

库的简单介绍
- 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以
pthread_打头的 - 要使用这些函数库,要通过引入头文
<pthread.h> - 链接这些线程函数库时要使用编译器命令的 -
lpthread选项,即可正常使用多线程控制相关接口。 - 原生指的是大部分Linux 系统都会默认带上该线程库,都必须预载的。
三、线程控制接口
线程是进程内部的一个执行流,作为 CPU 运行的基本单位,对于线程的合理控制与任务的执行效率息息相关,因此掌握线程基本操作(线程控制)是很有必要的。
(一)线程创建 - pthread_create()
如何创建一个线程,对于 原生线程库 来说,创建线程使用的是 pthread_create 这个接口:
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);

参数:
- 参数1
pthread_t*:线程ID,用于标识线程,其实这玩意本质上就是一个unsigned long int类型。注:pthread_t*表明这是一个输出型参数,旨在创建线程后,获取新线程ID。 - 参数2
const pthread_attr_t*:用于设置线程的属性,比如优先级、状态、私有栈大小,这个参数一般不考虑,直接传递nullptr使用默认设置即可。 - 参数3
void *(*start_routine) (void *):这是一个很重要的参数,它是一个 返回值为void*参数也为void*的函数指针,线程启动时,会自动回调此函数(类似于signal函数中的参数2)。 - 参数4
void*:显然,这个类型与回调函数中的参数类型匹配上了,而这正是线程运行时,传递给回调函数的参数。
返回值 int:创建成功返回 0,失败返回 error number
1. 一个线程
我们先来创建一个线程试试水:
#include <iostream>
#include <unistd.h>
#include <pthread.h>
using namespace std;
void* thread_run(void *arg)
{
while(true)
{
cout << "我是次线程,我正在运行..." << endl;
sleep(1);
}
}
int main()
{
pthread_t t;
pthread_create(&t, nullptr, thread_run, nullptr);
while(true)
{
cout << "我是主线程,次线程ID是:" << t << endl;
sleep(1);
}
return 0;
}错误:未定义 pthread_create 这个函数。原因:没有指明使用 原生线程库,这是一个非常常见的问题
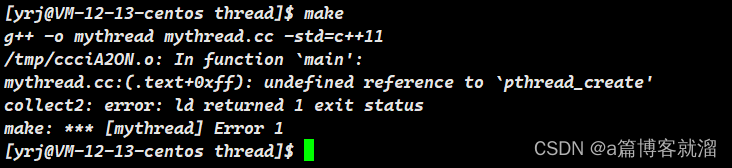
解决方法:编译时带上 -lpthread,指明使用 原生线程库:
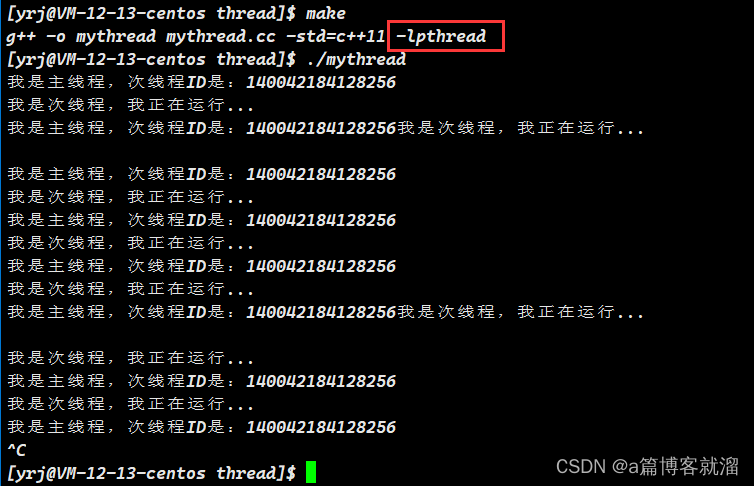
现在我们已经得到了一个链接 原生线程库 的可执行程序,可以通过 ldd 可执行程序 查看库的链接情况:
ldd mythread

也可以查看原生线程库的路径:/lib64/libpthread.so.0
足以证明原生线程库确确实实的存在于我们的系统中。
可以通过 ps -aL 查看正在运行中的线程信息:
为什么打印的次线程
ID如此长?并且与ps -aL查出来的LWP不一致?
很长是因为它本质上是一个无符号长整型,至于为什么显示不一致的问题,需要到下面才能解答。
程序运行时,主次线程的运行顺序谁先谁后?
线程的调度机制源于进程,而多进程运行时,谁先运行取决于调度器,因此主次线程运行的先后顺序不定,具体取决于调度器的调度。
2. 一批线程
那我们上点强度试试多个线程:
#define NUM 5
void* thread_run(void *name)
{
while(true)
{
cout << "我是次线程 " << (char*)name << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t pt[NUM];
for(int i = 0; i < NUM; i++)
{
char name[64];
snprintf(name, sizeof(name), "thread-%d", i+1);
pthread_create(pt+i, nullptr, thread_run, name);
}
while(true)
{
cout << "我是主线程,我正在运行..." << endl;
sleep(1);
}
return 0;
}细节:传递 pthread_create 的参数1时,可以通过 起始地址+偏移量 的方式进行传递,传递的就是 pthread_t*
预期结果:打印 thread-1、thread-2、thread-3 …
实际结果:确实有五个次线程在运行,但打印的结果全是 thread-5:
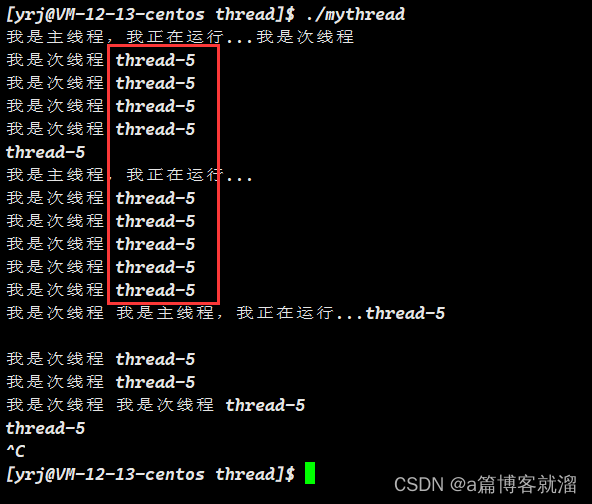
原因:char name[64] 属于主线程中栈区之上的变量,多个线程实际指向的是同一块空间,最后一次覆盖后,所有线程都打印 thread-5 :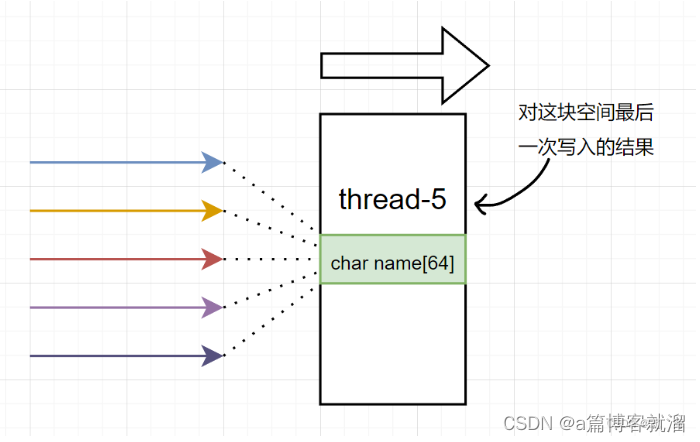
这是由于多线程共享同一块区域引发的问题,解决方法就是在堆区动态匹配空间,使不同的线程读取不同的空间,这样就能确保各自信息的独立性:
#define NUM 5
void* thread_run(void *args)
{
char *name = (char*)args;
while(true)
{
cout << "我是次线程 " << name << endl;
sleep(1);
}
delete name;
return nullptr;
}
int main()
{
pthread_t pt[NUM];
for(int i = 0; i < NUM; i++)
{
char *tname = new char[64];
snprintf(tname, 64, "thread-%d", i+1);
pthread_create(pt+i, nullptr, thread_run, tname);
}
while(true)
{
cout << "我是主线程,我正在运行..." << endl;
sleep(1);
}
return 0;
}显然,线程每次的运行顺序取决于调度器:
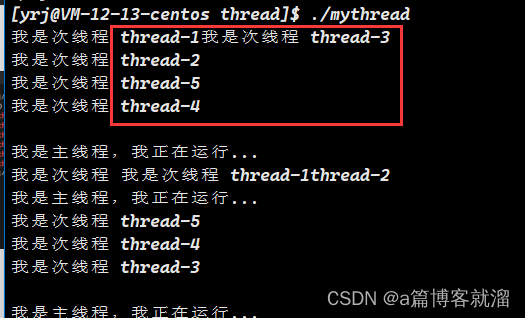
在上面的程序中,主线程也是在死循环式运行,假若主线程等待 3 秒后,再 return, 会发生什么呢?
#define NUM 5
void* thread_run(void *args)
{
char *name = (char*)args;
while(true)
{
cout << "我是次线程 " << name << endl;
sleep(1);
}
delete name;
return nullptr;
}
int main()
{
pthread_t pt[NUM];
for(int i = 0; i < NUM; i++)
{
char *tname = new char[64];
snprintf(tname, 64, "thread-%d", i+1);
pthread_create(pt+i, nullptr, thread_run, tname);
}
sleep(3);
return 0;
}结果:程序运行 3 秒后,主线程退出,同时其他次线程也被强制结束了
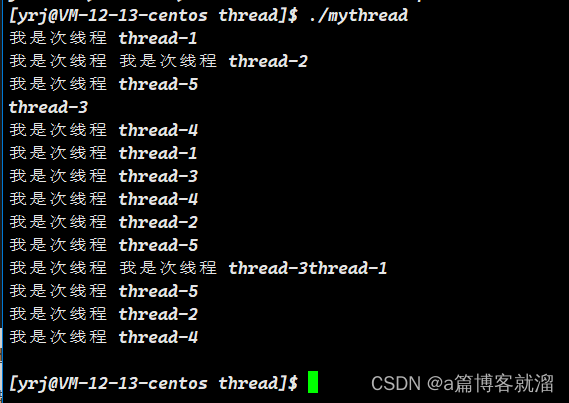
这是因为 主线程结束了,整个进程的资源都得被释放,次线程自然也就无法继续运行了。
换句话说,次线程由主线程创建,主线程就得对他们负责,必须等待他们运行结束,类似于父子进程间的等待机制;如果不等待,就会引发僵尸进程问题,不过线程这里没有僵尸线程的概念,直接影响就是次线程也全部退出了。
(二)线程等待 - pthread_join()
主线程需要等待次线程,在 原生线程库 中刚好存在这样一个接口 pthread_join,用于等待次线程运行结束:
int pthread_join(pthread_t thread, void **retval);

参数:
- 参数1
pthread_t:待等待的线程ID,本质上就是一个无符号长整型类型;这里传递是数值,并非地址。 - 参数2
void**:这是一个输出型参数,用于获取次线程的退出结果,如果不关心,可以传递nullptr。
返回值:成功返回 0,失败返回 error number
函数原型很简单,使用也很简单,我们可以直接在主线程中调用并等待所有次线程运行结束:
int main()
{
pthread_t pt[NUM];
for(int i = 0; i < NUM; i++)
{
char *tname = new char[64];
snprintf(tname, 64, "thread-%d", i+1);
pthread_create(pt+i, nullptr, thread_run, tname);
}
//等待每个线程结束
for(int i = 0; i < NUM; i++)
{
int ret = pthread_join(pt[i], nullptr);
if(ret != 0)
{
cerr << "等待线程 " << pt[i] << "失败" << endl;
}
}
return 0;
}(三)线程终止 - pthread_exit()
线程可以被创建并运行,也可以被终止,线程终止方式有很多种,比如 等待线程回调函数执行结束,次线程运行五秒后就结束了,然后被主线程中的 pthread_join 等待成功,次线程使命完成
void* thread_run(void *args)
{
char *name = (char*)args;
// 运行五秒结束
int n = 5;
while(n--)
{
cout << "我是次线程 " << name << endl;
sleep(1);
}
delete name;
return nullptr;
}还有一种方法是 在次线程回调方法中调用 exit() 函数,但这会引发一个大问题:只要其中一个线程退出了,其他线程乃至整个进程都得跟着退出,显然这不是很合理,不推荐这样玩多线程
void* thread_run(void *args)
{
char *name = (char*)args;
while(true)
{
cout << "我是次线程 " << name << endl;
sleep(1);
//退出码设为10
exit(10);
}
delete name;
return nullptr;
} 每个线程顶多存活一秒(存活在同一秒中)就被终止了,通过 echo $? 查询最近一次退出码,正是 10
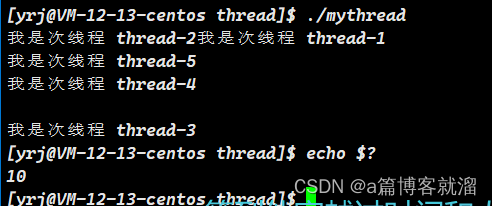
其实 原生线程库 中有专门终止线程运行的接口 pthread_exit,专门用来细粒度地终止线程,谁调用就终止谁,不会误伤其他线程。
void pthread_exit(void *retval);
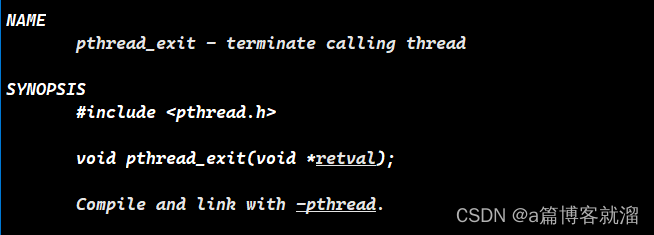
仅有一个参数 void*:用于传递线程退出时的信息。
这个参数名叫 retval,pthread_join 中的参数2也叫 retval,两者有什么不可告人的秘密吗?
答案是这俩其实本质上是同一个东西,pthread_join 中的 void **retval 是一个输出型参数,可以把一个 void* 指针的地址传递给 pthread_join 函数,当线程调用 pthread_exit 退出时,可以根据此地址对 retval赋值,从而起到将退出信息返回给主线程的作用: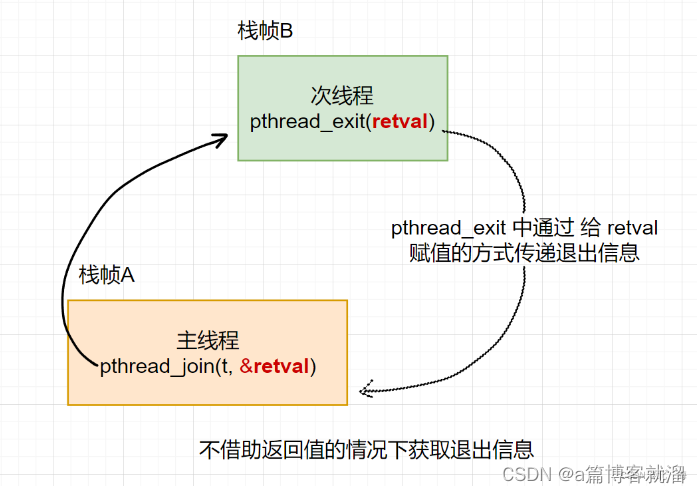
为什么 pthread_join 中的参数2类型为 void**?
- 因为主线程和次线程此时并不在同一个栈帧中,要想远程修改值就得传地址,类似于
int->&int,不过这里的retval类型是void*
注意: 直接在 回调方法 中 return 退出信息,主线程中的 retval 也是可以得到信息的,因为类型都是 void*,彼此相互呼应。
所以比较完善的多线程操作应该是这样的:
void* thread_run(void *args)
{
char *name = (char*)args;
cout << "我是次线程 " << name << endl;
delete name;
pthread_exit((void*)"EXIT");
// return (void*)"EXIT";这样也是ok的
}
int main()
{
pthread_t pt[NUM];
for(int i = 0; i < NUM; i++)
{
char *tname = new char[64];
snprintf(tname, 64, "thread-%d", i+1);
pthread_create(pt+i, nullptr, thread_run, tname);
}
//等待每个线程结束
void *retval = nullptr;
for(int i = 0; i < NUM; i++)
{
int ret = pthread_join(pt[i], &retval);
if(ret != 0)
{
cerr << "等待线程 " << pt[i] << "失败" << endl;
}
cout << "线程 " << pt[i] << "等待成功,退出信息为:" << (const char*)retval << endl;
}
cout << "所以线程都已退出" << endl;
return 0;
}
既然线程复用进程的设计思想,为什么线程退出时不需要考虑是否正常退出、错误码是什么之类的?
- 因为线程是进程的一部分,在进程中获取线程的错误信息等是无意义的,前面说过,如果一个线程因错误而被终止了,那么整个进程也就都活不了了,错误信息甄别交给父进程去完成,因此 pthread_join 就没必要关注线程退出时的具体状态了;如果次线程有信息要交给主线程,可以通过 retval 输出型参数获取。
四、线程实操
无论是 pthread_create 还是 pthread_join,他们的参数都有一个共同点:包含了一个 void* 类型的参数,这就是意味着我们可以给线程传递对象,并借此进行某种任务处理。
比如我们先创建一个包含一下信息的线程信息类,用于计算 [0, N] 的累加和:
- 线程名字(包含
ID) - 线程编号
- 线程创建时间
- 待计算的值
N - 计算结果
- 状态
为了方便访问成员,权限设为 public
// 线程状态
enum class Status
{
OK = 0,
ERROT
};
// 线程信息类
class ThreadData
{
public:
ThreadData(const string &name, int id, int n)
:_name(name)
,_id(id)
,_createTime(time(nullptr))
,_n(n)
,_result(0)
,_status(Status::OK)
{}
public:
string _name;
int _id;
time_t _createTime;
int _n;
int _result;
Status _status;
};
此时就可以编写 回调方法 中的任务实现了:
void* thread_run(void *args)
{
ThreadData *td = static_cast<ThreadData*>(args);
//任务处理
for(int i = 0; i <= td->_n; i++)
td->_result += i;
// 如果业务处理过程中发现异常行为,可以设置 _status 为 ERROR
cout << "线程 " << td->_name << " ID " << td->_id
<< " CreateTime " << td->_createTime << " done..." << endl;
pthread_exit((void*)td);
// return td;这样也是ok的
}
主线程在创建线程及等待线程时,就可以使用 ThreadData 对象了,后续涉及任务修改时,也只需要修改类及回调方法即可,无需再更改创建及等待逻辑,有效做到了 解耦:
#include <iostream>
#include <unistd.h>
#include <string>
#include <ctime>
#include <pthread.h>
.....
int main()
{
pthread_t pt[NUM];
for(int i = 0; i < NUM; i++)
{
char tname[64];
snprintf(tname, sizeof(tname), "thread-%d", i+1);
// 创建对象
ThreadData *td = new ThreadData(tname, i, 50*(10+i));
pthread_create(pt+i, nullptr, thread_run, td);
sleep(1); // 尽量拉开创建时间
}
//等待每个线程结束
void *retval = nullptr;
for(int i = 0; i < NUM; i++)
{
int ret = pthread_join(pt[i], &retval);
if(ret != 0)
{
cerr << "等待线程 " << pt[i] << "失败" << endl;
}
ThreadData *td = static_cast<ThreadData*>(retval);
if(td->_status == Status::OK)
{
cout << "线程" << pt[i] << " 计算 [0, " << td->_n
<< "] 的累加和结果为 " << td->_result << endl;
}
}
cout << "所以线程都已退出" << endl;
return 0;
}程序可以正常运行,各个线程也都能正常计算出结果;这里只是简单计算累加和,线程还可以用于其他场景:网络传输、密集型计算、多路 IO等,无非就是修改线程的业务逻辑。
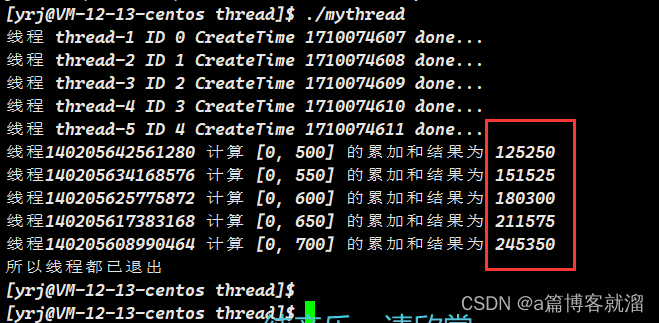
结论:多线程可以传递对象指针,自由进行任务处理。
五、线程控制接口补充
(一)关闭线程 - pthread_cancel()
线程可以被创建,自然也可以被关闭,可以使用 pthread_cancel 关闭已经创建并运行中的线程
int pthread_cancel(pthread_t thread);
参数1 pthread_t:被关闭的线程 ID
返回值:成功返回 0,失败返回一个非零的 error number
这里可以直接模拟关闭线程的场景
#include <iostream>
#include <unistd.h>
#include <pthread.h>
using namespace std;
void *thread_run(void *args)
{
const char *ps = static_cast<const char*>(args);
while(true)
{
cout << "线程 " << ps << " 正在运行" << endl;
sleep(1);
}
pthread_exit((void*)10);
}
int main()
{
pthread_t t;
pthread_create(&t, nullptr, thread_run, (void*)"good morning");
// 3秒后关闭线程
sleep(3);
pthread_cancel(t);
void *retval = nullptr;
pthread_join(t, &retval);
// 细节:使用 int64_t 而非 uint64_t
cout << "线程 " << t << " 已退出,退出信息为 " << (int64_t)retval << endl;
return 0;
}程序运行 3 秒后,可以看到退出信息为 -1,与我们预设的 10 不相符

原因很简单:只要是被 pthread_cancel 关闭的线程,退出信息统一为 PTHREAD_CANCELED 即 -1。这也就解释了为什么要强转为 ingt64_t,因为无符号的 -1 非常大,不太好看

比较奇怪的实验
- 次线程可以自己关闭自己吗?答案是可以的,但貌似关闭后,主线程没有正常等待,整个进程疑似正常结束(退出码为
0) - 次线程可以关闭主线程吗?答案是不可以,类似于
kill -9无法终止1号进程
(二)获取线程ID - pthread_self()
线程 ID 是线程的唯一标识符,可以通过 pthread_self 获取当前线程的 ID
pthread_t pthread_self(void);
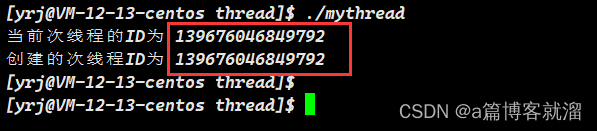
void *thread_run(void *args)
{
cout << "当前次线程的ID为 " << pthread_self() << endl;
return nullptr;
}
int main()
{
pthread_t t;
pthread_create(&t, nullptr, thread_run, nullptr);
pthread_join(t, nullptr);
cout << "创建的次线程ID为 " << t << endl;
return 0;
}可以看到结果都是一样的
(三)线程分离 - pthread_detach()
父进程需要阻塞式等待子进程退出,主线程等该次线程时也是阻塞式等待,父进程可以设置为 WNOHANG,变成轮询式等待,避免自己一直处于阻塞;次线程该如何做才能避免等待时阻塞呢?
答案是 分离 Detach
默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
原生线程库 提供的线程分离接口是 pthread_detach
int pthread_detach(pthread_t thread);
参数1 pthread_t:被关闭的线程 ID
返回值:成功返回 0,失败返回一个非零的 error number
线程分离的本质是将 joinable 属性修改为 detach,告诉系统线程退出后资源自动释放。
注意:joinable和detach是冲突的,一个线程不能既是joinable又是detach的。
简单使用一下 线程分离:
void *thread_run(void *args)
{
string name = static_cast<const char*>(args);
int cnt = 5;
while(cnt--)
{
cout << name << cnt << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t t;
pthread_create(&t, nullptr, thread_run, (void*)"thread: ");
int cnt = 3;
while(cnt--)
{
cout << "main thread: " << cnt << endl;
sleep(1);
}
return 0;
}主线程可以不用等待次线程,两个执行流并发运行,并且不必担心次线程出现僵尸问题:
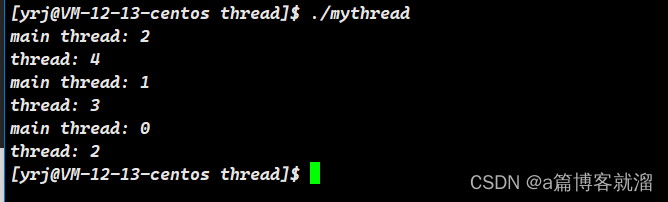
下面我们进行线程分离以后再进行等待,看看会发生什么:
void *thread_run(void *args)
{
string name = static_cast<const char*>(args);
int cnt = 5;
while(cnt--)
{
cout << name << " : " << cnt << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t t;
pthread_create(&t, nullptr, thread_run, (void*)"thread 1");
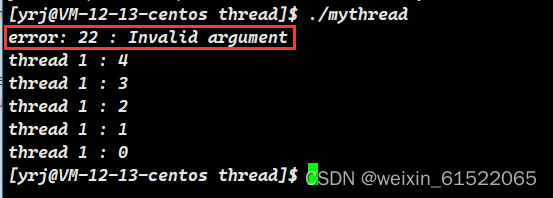
pthread_detach(t);
int n = pthread_join(t, nullptr);
if(n != 0)
{
cerr << "error: " << n << " : " << strerror(n) << endl;
}
sleep(10);
return 0;
}发现pthread_join函数立刻调用失败,返回错误码,并且执行sleep指令暂时不退出。而新线程继续正常执行。如果不在主线程中写sleep指令,则主线程会立刻退出,并连带所有线程退出:
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离:
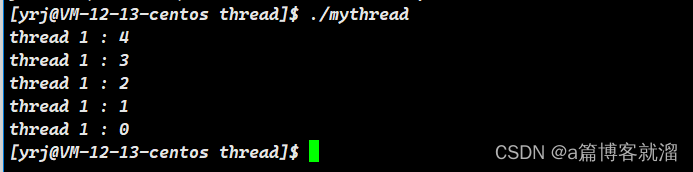
pthread_detach(pthread_self());void *thread_run(void *args)
{
pthread_detach(pthread_self());
string name = static_cast<const char*>(args);
int cnt = 5;
while(cnt--)
{
cout << name << " : " << cnt << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t t;
pthread_create(&t, nullptr, thread_run, (void*)"thread 1");
int n = pthread_join(t, nullptr);
if(n != 0)
{
cerr << "error: " << n << " : " << strerror(n) << endl;
}
return 0;
}发现结果与线程没分离时一致,这是因为线程被创建出来后,谁先调度是由调度器决定的。于是虽然新线程被创建出来了,但还没来的及调度执行分离函数,就被主线程先执行join函数等待了:
为了避免这个问题,在创建完新线程后,主线程等待2秒再开始执行:
int main()
{
pthread_t t;
pthread_create(&t, nullptr, thread_run, (void*)"thread 1");
sleep(2);
int n = pthread_join(t, nullptr);
if(n != 0)
{
cerr << "error: " << n << " : " << strerror(n) << endl;
}
return 0;
}
结论:建议将 pthread_detach 放在待分离线程的 线程创建 语句之后,如果放在线程执行函数中,可能会因为调度优先级问题引发错误(未知结果)。
总之,线程被分离后,主线程就可以不必关心了,即不需要 join 等待,是否分离线程取决于具体的应用场景。
六、线程库的深入理解
(一)线程的ID
原生线程库本质上也是一个文件,是一个存储在 /lib64 目录下的动态库,要想使用这个库,就得在编译时带上 -lpthread 指明使用动态库
程序运行时,原生线程库 需要从 磁盘 加载至 内存 中,再通过 进程地址空间 映射至 共享区 中供线程使用: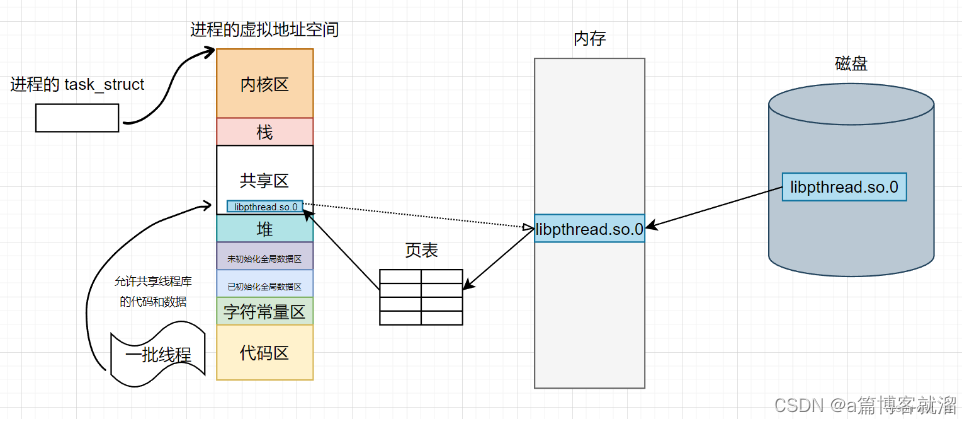
由于用户并不会直接使用 轻量级进程 的接口,于是 需要借助第三方库进行封装,类似于用户可能不了解系统提供的 文件接口,从而使用 C语言 封装的 FILE 库一样: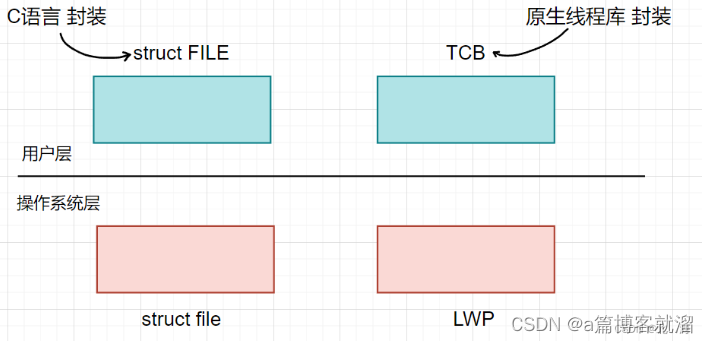
对于 原生线程库 来说,线程不止一个,因此遵循 先描述,再组织 原则,在线程库中创建 TCB 结构(类似于 PCB),其中存储 线程 的各种信息,比如 线程独立栈 信息。
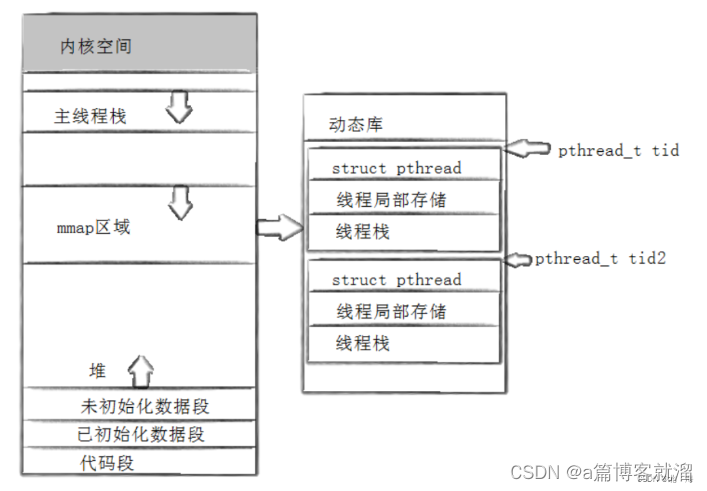
在内存中,整个 线程库 就像一个 “数组”,其中的一块块空间聚合排布 TCB 信息,而 每个 TCB 的起始地址就表示当前线程的 ID,地址是唯一的,因此线程 ID也是唯一的。
因此,我们之前打印 pthread_t 类型的 线程 ID 时,实际打印的是地址,不过是以 十进制 显示的,可以通过函数将地址转化为使用 十六进制 显示
#include <iostream>
#include <string>
#include <unistd.h>
#include <pthread.h>
using namespace std;
string HexAdress(pthread_t t)
{
char id[64];
// 转换成十六进制
snprintf(id, sizeof(id), "0x%x", t);
return id;
}
void *thread_run(void *args)
{
cout << "new thread | ID: " << HexAdress(pthread_self()) << endl;
return (void*)0;
}
int main()
{
pthread_t t;
pthread_create(&t, nullptr, thread_run, nullptr);
pthread_join(t, nullptr);
cout << "main thread | ID: " << HexAdress(pthread_self()) << endl;
return 0;
}线程 ID 确实能转化为地址(虚拟进程地址空间上的地址)

注意: 即便是 C++11 提供的 thread 线程库,在 Linux 平台中运行时,也需要带上 -lpthread 选项,因为它本质上是对 原生线程库 的封装
(二)线程独立栈
线程 之间存在 独立栈,可以保证彼此之前执行任务时不会相互干扰,可以通过代码证明。
多个线程使用同一个入口函数,并打印其中临时变量的地址
string HexAdress(pthread_t t)
{
char id[64];
// 转换成十六进制
snprintf(id, sizeof(id), "0x%x", t);
return id;
}
void *threadRoutine(void *args)
{
int tmp = 0;
cout << "new thread | ID: " << HexAdress(pthread_self())
<< " &tmp: " << &tmp << endl;
return (void*)0;
}
int main()
{
pthread_t t[5];
for(int i = 0; i < 5; i++)
{
pthread_create(t+i, nullptr, threadRoutine, nullptr);
sleep(1);
}
for(int i = 0; i < 5; i++)
pthread_join(t[i], nullptr);
return 0;
}可以看到五个线程打印 “同一个” 临时变量的地址并不相同,足以证明 线程独立栈 的存在 :

存在这么多 栈结构,CPU 在运行时是如何区分的呢?
答案是 通过 栈顶指针
ebp和 栈底指针esp进行切换,ebp和esp是CPU中两个非常重要的 寄存器,即便是程序启动,也需要借助这两个 寄存器 为main函数开辟对应的 栈区。
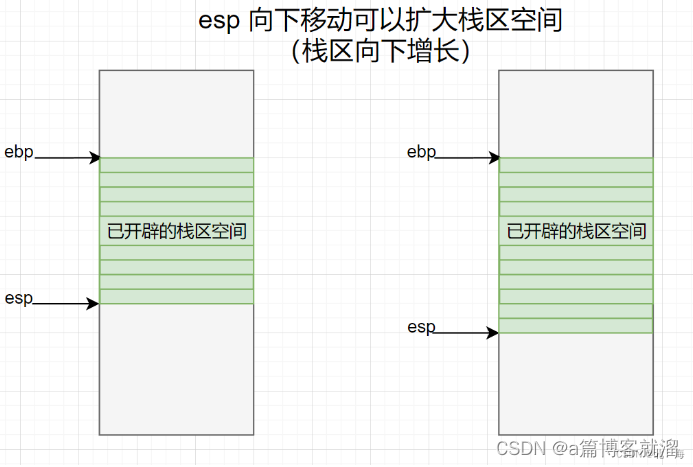
除了移动 esp 扩大栈区外,还可以同时移动 ebp 和 esp 更改当前所处栈区:
所以,多线程中 独立栈 可以通过 ebp 和 esp 轻松切换并使用
如果想要在栈区中开辟整型空间,可以使用
ebp - 4定位对应的空间区域并使用,其他类型也是如此,原理都是 基地址 + 偏移量
注意:
- 所有线程都要有自己独立的栈结构(独立栈),主线程中用的是进程系统栈,次线程用的是库中提供的栈。
- 多个线程调用同一个入口函数(回调方法),其中的局部变量地址一定不一样,因为存储在线程独立栈中。
(三)线程的局部存储
线程 之间共享 全局变量,对 全局变量 进行操作时,会影响其他线程:
int g_val = 100;
string HexAdress(pthread_t t)
{
char id[64];
// 转换成十六进制
snprintf(id, sizeof(id), "0x%x", t);
return id;
}
void *threadRoutine(void *args)
{
int tmp = 0;
cout << "new thread | ID: " << HexAdress(pthread_self())
<< " g_val: " << ++g_val << ", &g_val: " << &g_val << endl;
return (void*)0;
}
int main()
{
pthread_t t[5];
for(int i = 0; i < 5; i++)
{
pthread_create(t+i, nullptr, threadRoutine, nullptr);
sleep(1);
}
for(int i = 0; i < 5; i++)
pthread_join(t[i], nullptr);
return 0;
}在5个线程的累加下,g_val 最终变成了105
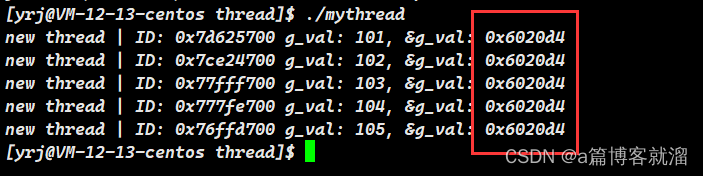
如何让全局变量私有化呢?即每个线程看到的全局变量不同
可以给全局变量加
__thread修饰,修饰之后,全局变量不再存储至全局数据区,而且存储至线程的 局部存储区中。
__thread int g_val = 100;
结果:修饰之后,每个线程确实看到了不同的 “全局变量”。此时的 “全局变量” 的地址也变大了:
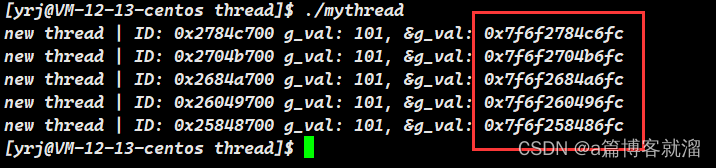
“全局变量” 地址变大是因为此时它不再存储在 全局数据区 中,而且存储在线程的 局部存储区 中,线程的局部存储区位于 共享区,并且 共享区 的地址天然大于 全局数据区。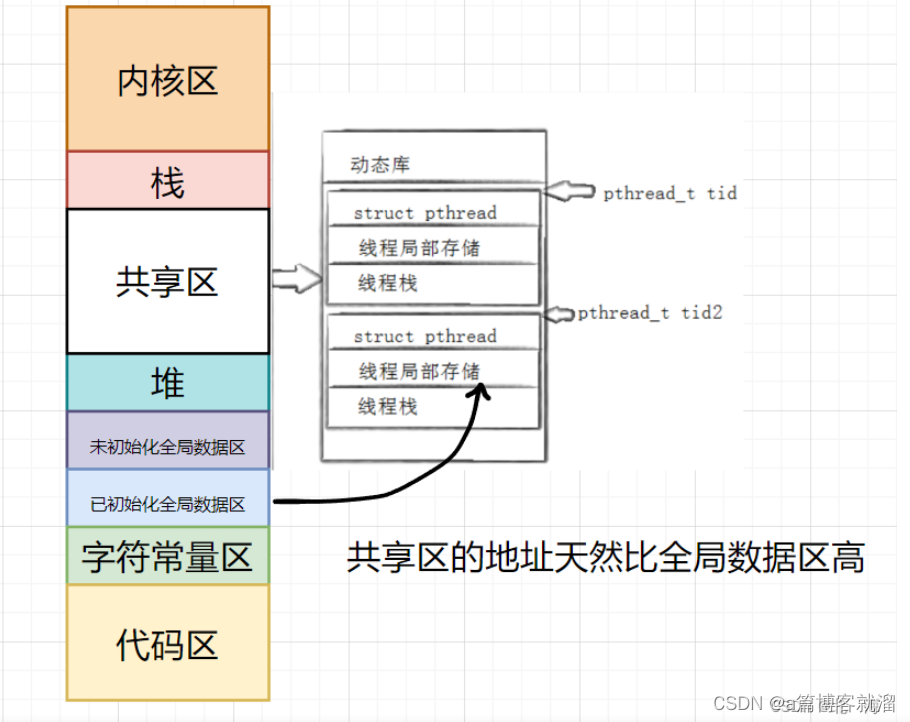
结论: 局部存储区位于共享区中,可以通过 __thread 修饰来改变变量的存储位置。



![[WiFi] 802.11w/802.11k/802.11v/802.11r/802.11u/802.11ai/802.11ah简介](https://img-blog.csdnimg.cn/img_convert/2a882869e7595dd8f64cd2a120b4f360.png)




![[C语言]——数组练习](https://img-blog.csdnimg.cn/direct/817c06d92d084a1eaa59303673cbb525.png)