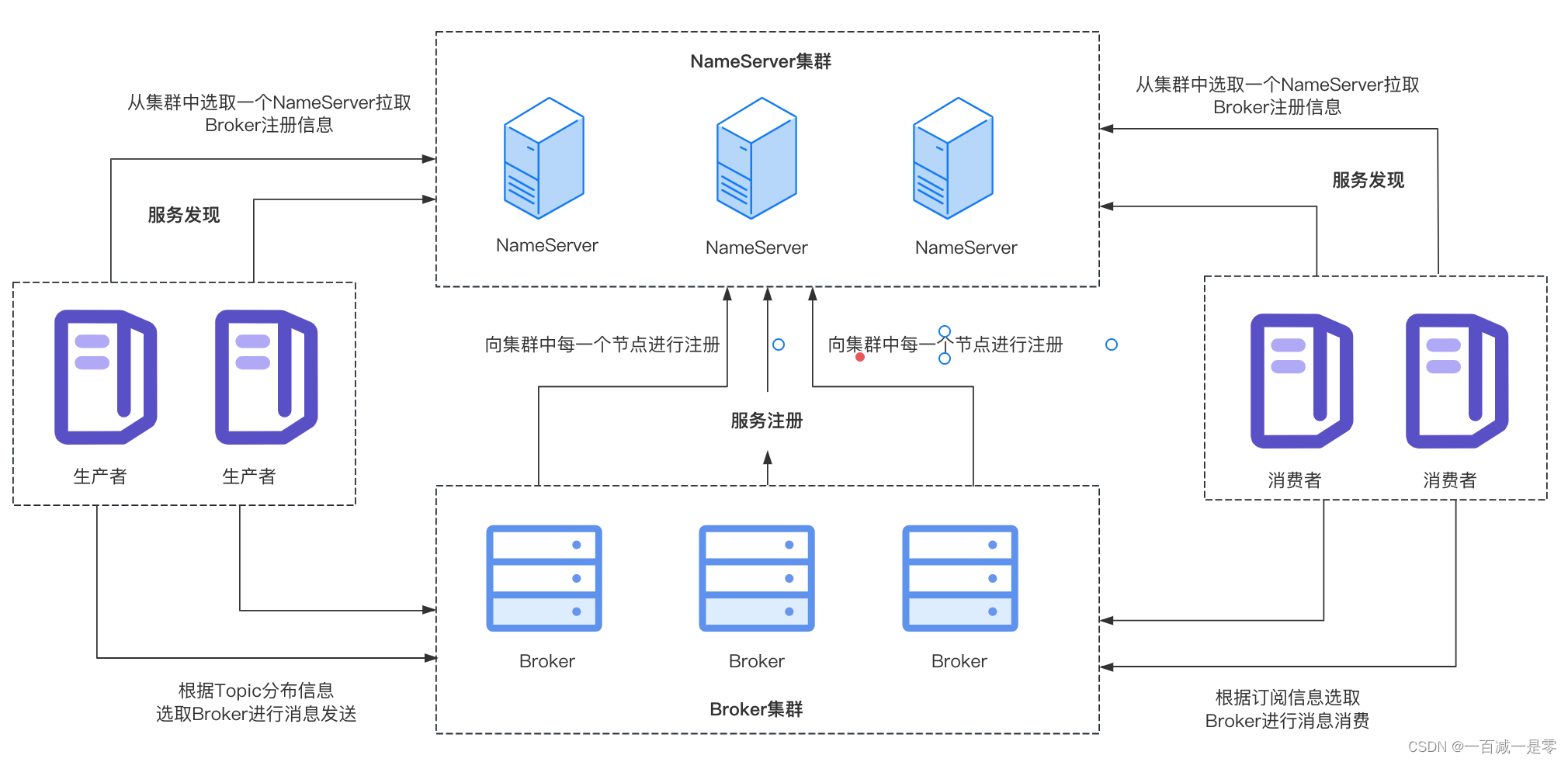
文章目录
- 一、基本概念
- 1.HTTP
- 2.域名
- 3.默认端口号
- 4.URL
- 二、请求与响应
- 1.抓包工具
- 2.基本框架
- 3.简易实现
- 3.1 HttpServer
- 3.2 HttpRequest
- 3.2.1 version1
- 3.2.2 version2
- 3.2.3 version3
- 总结
- 尾序
一、基本概念
- 常见的应用层协议:
- HTTPS (
HyperTextTransferProtocolSecure),安全的超文本传输数据。- FTP(
FileTransferProtocol) ,网络之间的文件传输。- SMTP(
SimpleMailTransferProtocol),邮件传输。- DNS(
DomainNameSystem),域名解析。- SSH(
SecureSHell),加密的远程登录会话。
- 一般来讲,大多数情况用现成的应用层协议即可,但是如果做游戏引擎,或者做一些比较私密,对安全性要求很高的项目时,可能需要内部指定自定义协议。
1.HTTP
- HTTP(
HyperTextTransferProtocol)是一种用于传输超文本数据的应用层协议。 - 应用于Web服务器与Web浏览器之间进行通信。
- 明文传输(可能会暴露个人隐私数据),因此不安全,但是简单易用,被广泛支持。
- 对于HTTP的不安全,之后发展出了HTTPS,即" 安全的HTTP "。
浏览器简介:
- 浏览器简单来看就是处理数据的一种工具,浏览器可以解析一些常用的应用层协议的数据,通过相应的连接方式向服务端发送请求,接收响应并将文件给我们以相应的格式呈现出来,具体如何呈现出一个完美的网页,则是前端开发人员的工作了,接下来的内容我们会制作一个简单的网页 ~
- 市面上的浏览器多种多样,因为掌握了浏览器,也就掌握了进入网络的通道,因此各大公司在早期为了发展,争相竞争推动了浏览器技术的发展,发展出了成熟的浏览器,目前浏览器呈现的一般都是跟搜索引擎相结合的模式,通过搜索网址和关键词,从而使用户进入目标网站。
- 现在由于ChatGpt的出现让信息可以通过对话的形式体现,相比搜索引擎的关键词搜索更加的便利,让我们获取知识的成本降低了不少,博主也推荐使用ChatGpt之类的工具来提高学习效率。
2.域名
通过 www.baidu.com,我们可以很明显的辨认出这是百度的网址,其实这就是百度的域名,那我们再来看39.156.66.14,这里你可能会感觉有点懵逼,其实这也是百度的网址,不信博主复制粘贴到浏览器去访问一下,下面截图为证:
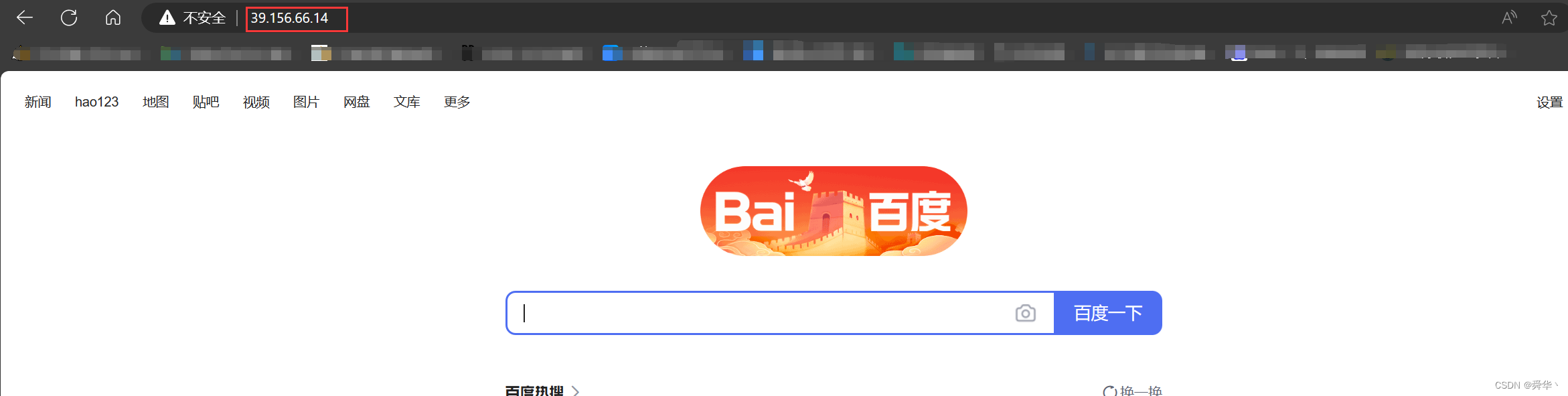
这一串数字是怎么得到的呢?
-
按下
win + r,输入cmd,按下回车。—— windows系统下 -
在命令窗口输入
ping www.baidu.com

这其实是百度的IP地址,通过它,我们就可以定位唯 一 一 台主机,进而访问百度的服务器,获取相应的首页资源。此时我们再回到讨论的话题,域名相比ip地址,用户记忆的成本更低,这就是域名的好处,但从专业的角度来看,域名背后其实绑定了ip地址,而且可能还不止一个,如果你ping的ip地址跟我的不一样,就证明了这一点。
3.默认端口号
常见的默认端口号有:
- HTTP: 80
- HTTPS: 443
- FTP: 21
- SSH: 22
- Telnet: 23
- SMTP: 25
- POP3: 110
- IMAP: 143
- DNS: 53
- 端口号所在文件:
/etc/services
这些端口号一般是不允许被修改的,就像110在我们的脑中已经跟报警电话已经联系了起来,80就是http协议的默认端口,而且这些端口号在访问时一般浏览器是忽略的,如果改了还得在后面跟上: + 修改的端口号,因为单凭ip地址只能锁定一台主机,还得指定端口号与相应的进程才能进行联系,因为网络的本质就是进程间通信。
4.URL
- 概念
- URL(
UniformResourceLocator)是统一资源定位符的缩写,用于指定互联网上资源的位置和访问方式。简单的理解其实就是网址。
- URL(
- 组成
图解:
- 例1:ssh登录
- 例二:http协议
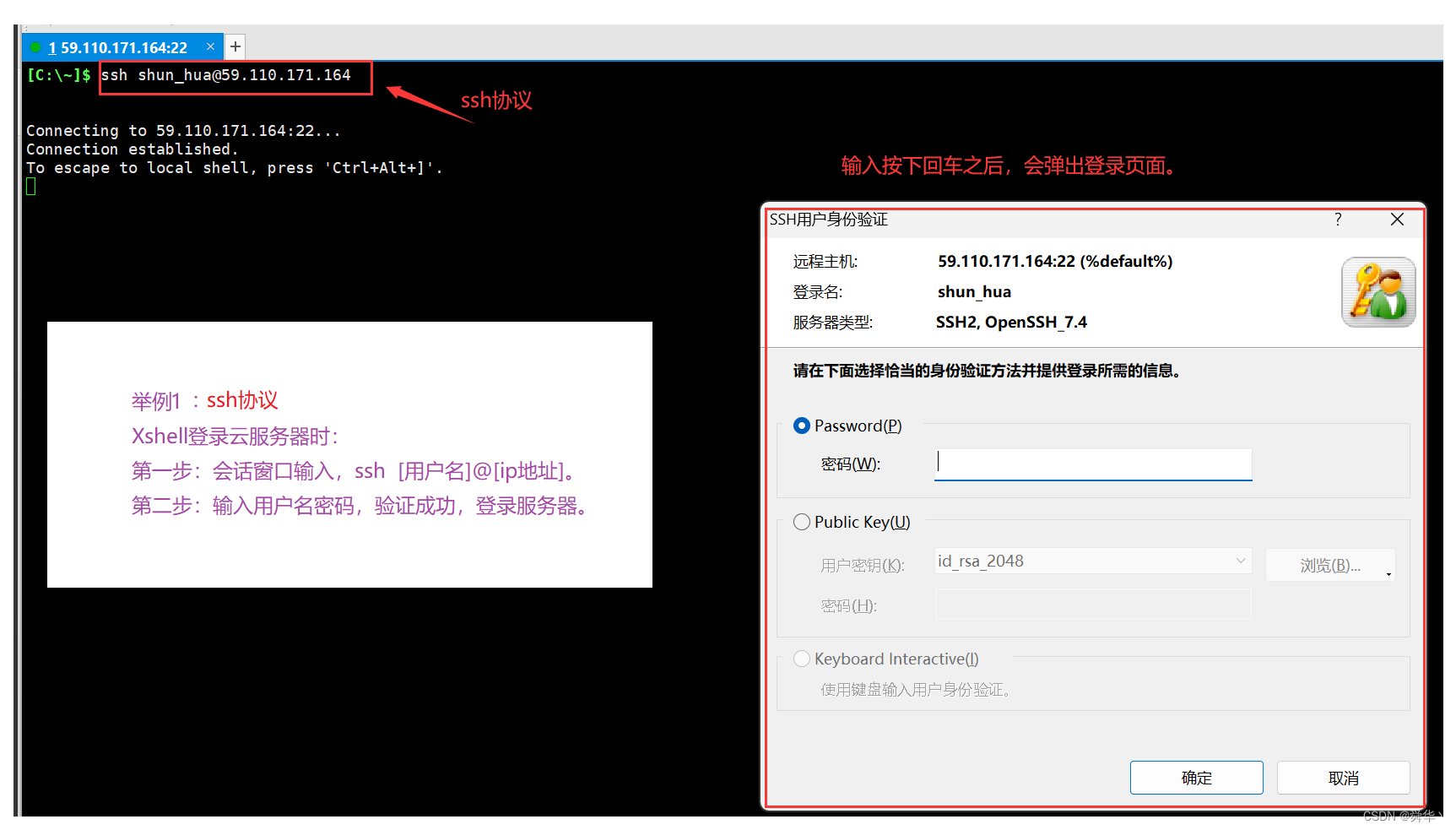
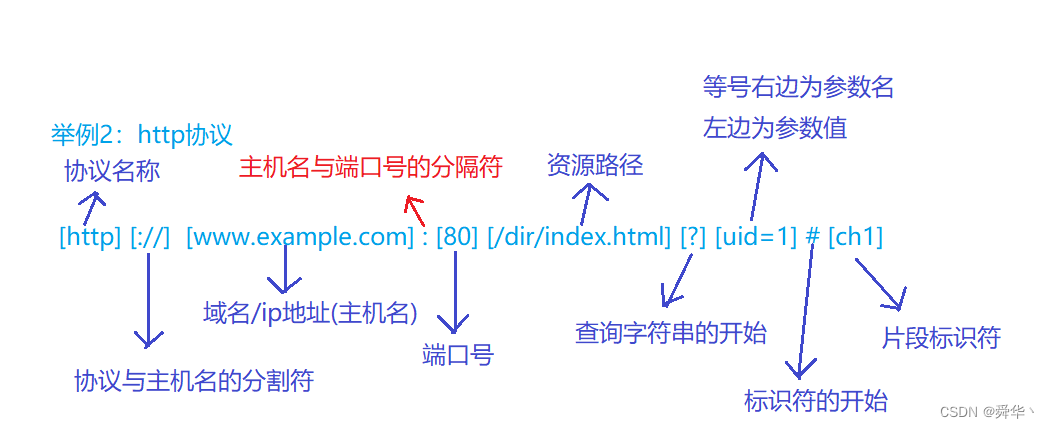
下面我们于查询字符串和片段标识符举两个例子:
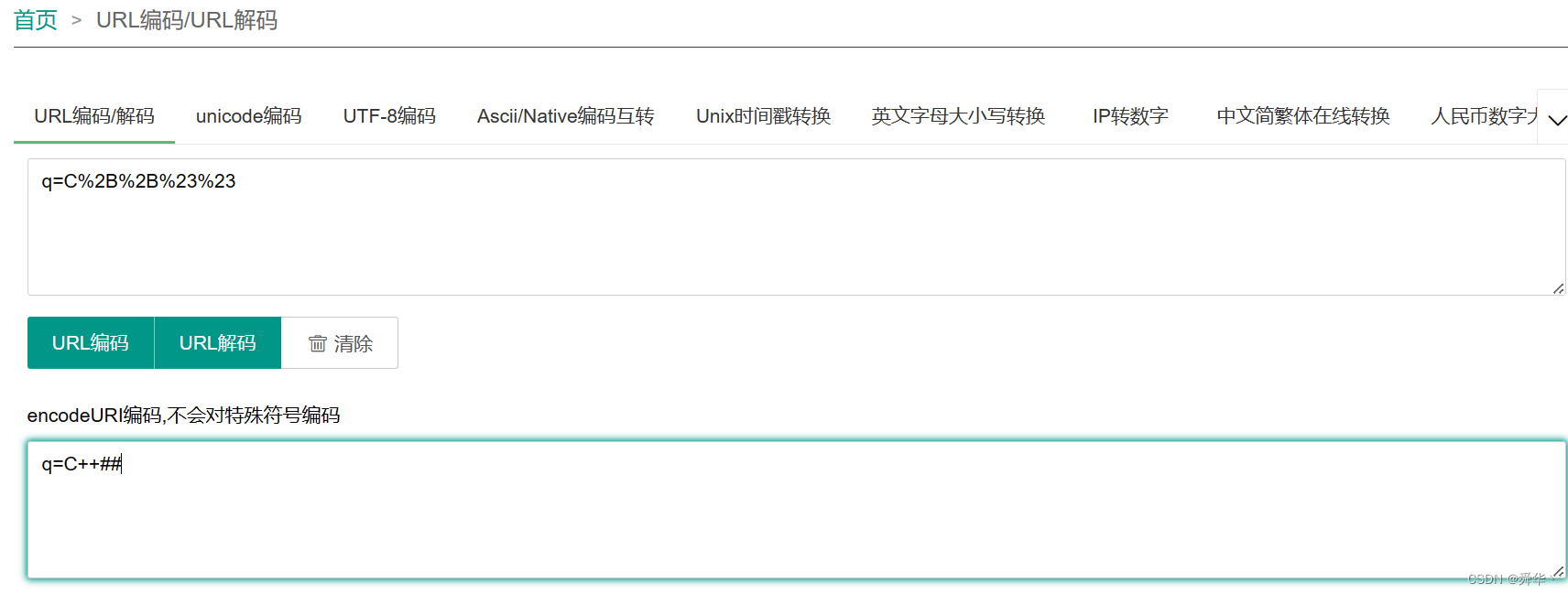
- 字符串查询:
搜索引擎上输入
C++##等带特殊字符的关键词。查看URL的查询参数:
- 如下图:
- 可见这些特殊字符是被编码了的,不过网上有现成的urlencode解码工具,进去将此字符串复制进行转换,可以查看到我们原来的查询的关键词。
- 如下图:
- 因此我们可以简单的理解查询不只是简单的查询,还要经过编码,从而
避免与网址的符号进行冲突。

- 片段标识符:
- 当我们想要在网址中定位某一个网页的位置时,需要通过片段标识符。
- 博主上一篇文章的网址 :
https://blog.csdn.net/Shun_Hua/article/details/136523510?spm=1001.2014.3001.5501。后面跟上和不跟上#_729,对比效果即可明白片段标识符的作用。
如何找到片段标识符呢?
- 在网页中右键,选择选项中的检查。查看网页源代码。
- 按下
ctrl + f在搜索框 搜索id这个标签。
- 例:
- 鼠标移动至此,可在网页上看到对应的效果,即标记位置信息。
二、请求与响应
1.抓包工具
- fiddler,需要输入认证信息之后才可进行下载。
- postman, 外网的访问会有些慢,需要使用魔法,或许访问不上。
- apifox,国内的比较好用。
2.基本框架
我们先使用telnet工具进行简单的HTTP请求,查看请求与响应的格式:
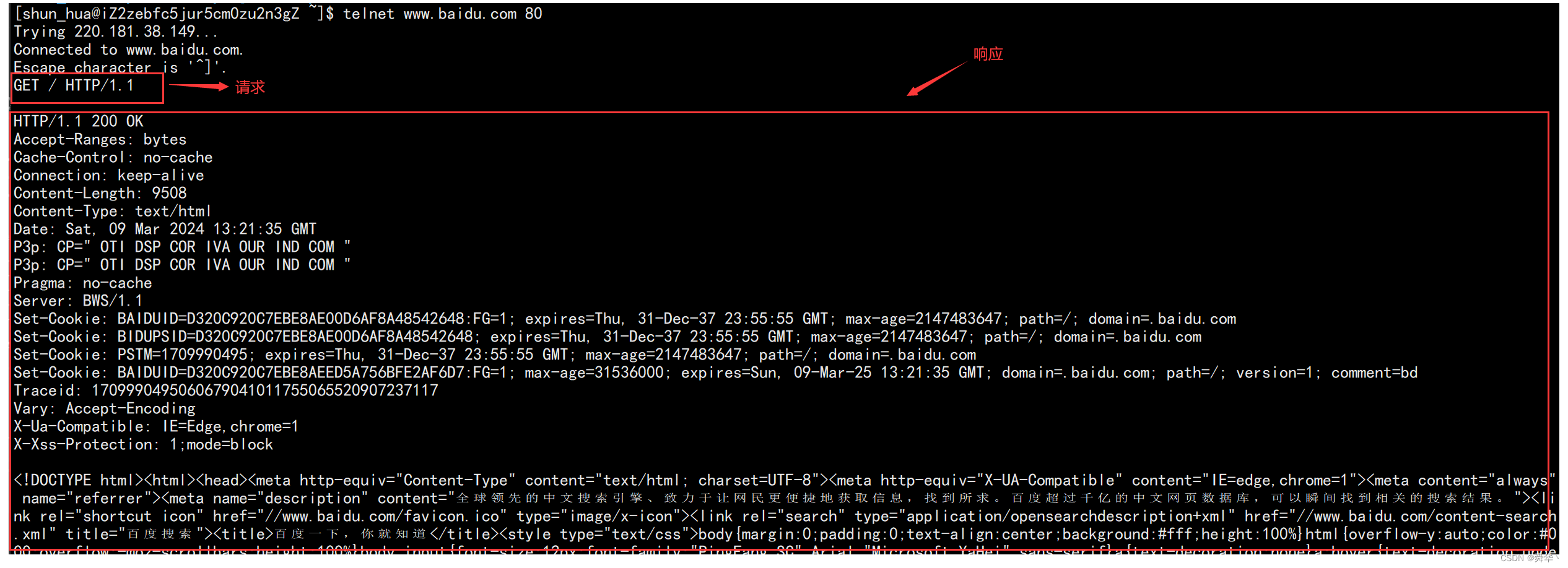
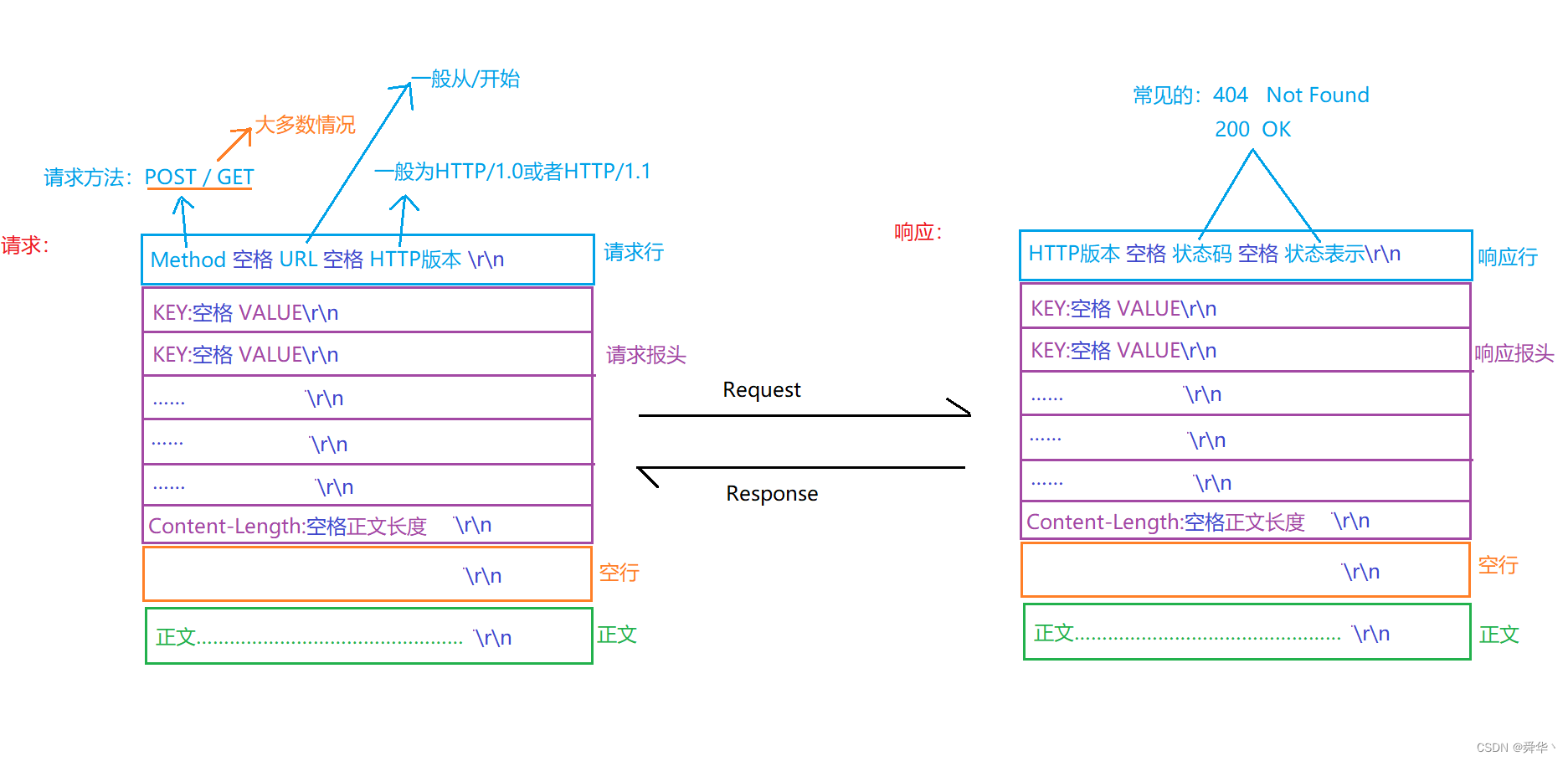
因此可以大致列出请求与响应的基本框架:
穿插知识:
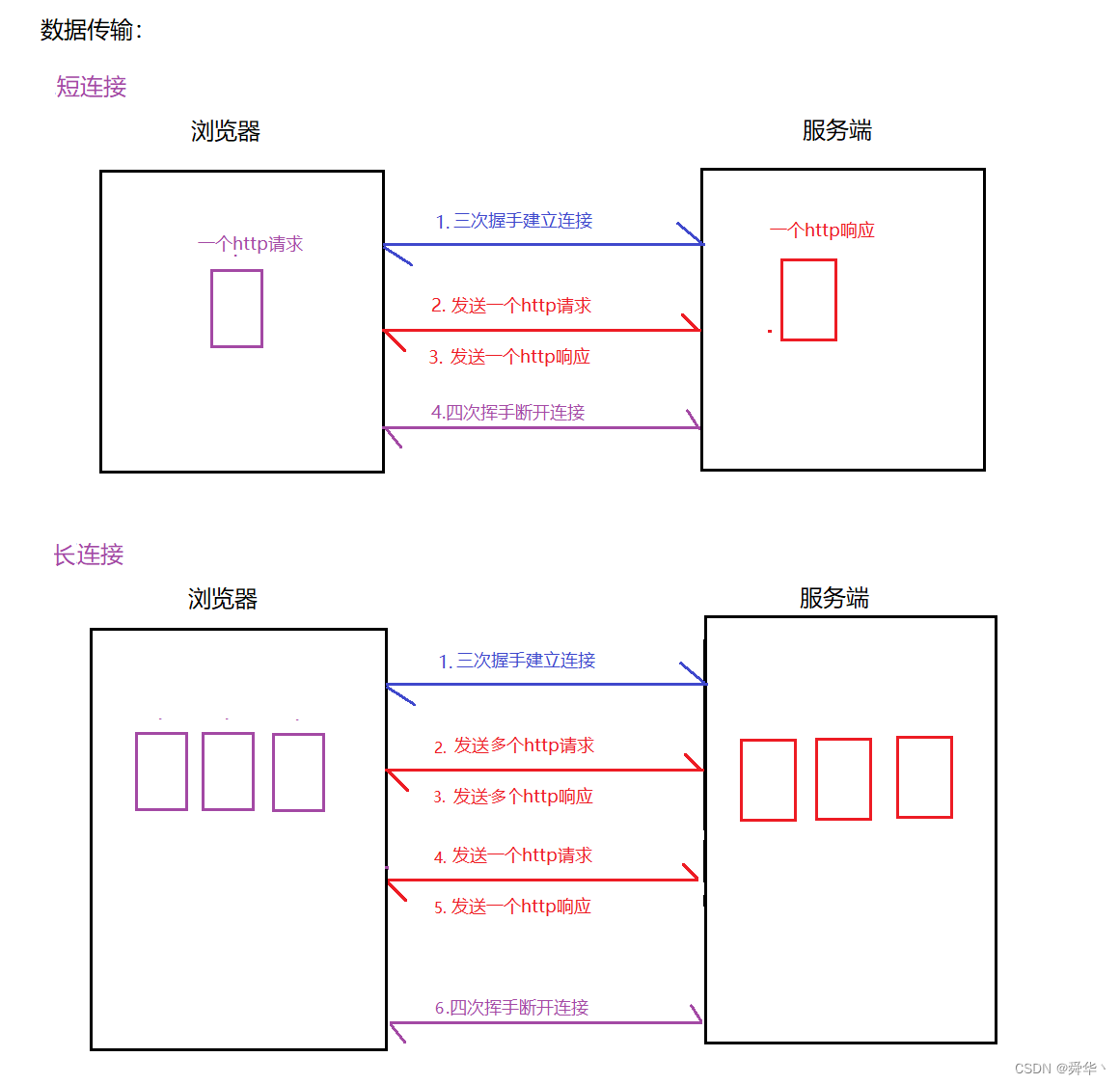
- 短连接:浏览器通常建立连接只能发一个请求,然后收一个响应,之后断开连接。若想再发送一个请求,只能再次申请连接,这适用于
无需多数据传输,无需保持连接,Http/1.0采用的是短连接。- 长连接:浏览器通常建立连接之后会保持一段时间,直接可以进行多次数据的传输,可以一次发送多个请求,接收多个响应,在无数据传输之后会断开连接。相比短连接减少因频繁建立和关闭连接而产生的额外开销,提高通信效率,尤其
适用于需要频繁交换数据的场景,Http/1.1版本支持长连接。- 说明:在请求报头中如果有
Connection: keep-alive,则意味申请长连接,申请成功时,会在响应报头处添加:Connection: keep-alive。
3.简易实现
在简易的了解Http的请求和响应的框架之后,我们可以通过代码,编写一个简单的Http服务器,并且制作一个简单的网页,来逐步理解Http的请求和响应。
3.1 HttpServer
在之前的文章,我们实现过守护进程,日志,封装基于TCP的socket等小组件,下面避免代码冗余就不再给出,下面的HttpServer其实就是一个基于TCP协议的服务端,写多了不管什么类型的服务端就是一种套路:
- 随机绑定端口与IP地址进行初始化。
- 对服务端进行初始化,即创建,绑定,监听套接字。
- 启动服务端,接收请求,建立链接,提供服务。
- 提供服务,其实就是将接收信息并对信息进行处理并返回。
关键就在于这个处理逻辑,按照什么方式处理,就决定了服务端是什么类型的。
- 实现代码:
#pragma once
#include<iostream>
#include<fstream>
#include<functional>
//容器
#include<vector>
#include<unordered_map>
//网络接口
#include<sys/types.h>
#include<sys/socket.h>
#include<arpa/inet.h>
#include<netinet/in.h>
//小组件
#include "../Tools/Log.hpp"
#include "../Tools/Socket.hpp"
using cal_t = function<string(string&)>;
string default_ip = "0.0.0.0";
uint16_t default_port = 8080;
class HttpServer;
struct PthreadData
{
PthreadData(int sockfd,HttpServer* hsp)
:fd(sockfd),hp(hsp)
{}
int fd;
HttpServer* hp;
};
class HttpServer
{
public:
HttpServer(uint16_t port = default_port,\
cal_t signal = nullptr,string ip = default_ip)
:_sockfd(port,ip)
{}
void Init()
{
_sockfd.Socket();
//使端口号可以重复被使用,之后的TCP内容中会详谈。
int opt = 1;
setsockopt(_sockfd.GetSocket(),SOL_SOCKET,\
SO_REUSEADDR|SO_REUSEPORT\
,&opt,sizeof(opt));
_sockfd.Bind();
_sockfd.Listen();
}
static void *Routine(void* args)
{
pthread_detach(pthread_self());
auto thp = static_cast<PthreadData*>(args);
HttpServer* hp = thp->hp;
int fd = thp->fd;
hp->Server(fd);
return nullptr;
}
void Run()
{
for(;;)
{
sockaddr_in client;
socklen_t len;
int fd = _sockfd.Accept(&client,&len);
pthread_t tid;
pthread_create(&tid,nullptr,Routine\
,new PthreadData(fd,this));
}
}
void Server(int fd)
{
string mes;
for(;;)
{
mes += _sockfd.Read(fd);
if(mes == "") break;
//处理信息
string echo_mes = cal(mes);
int num = _sockfd.Write(fd,echo_mes);
if(num == 0) break;
}
_sockfd.Close(fd);
}
private:
Sock _sockfd;
cal_t cal;
};
3.2 HttpRequest
如下是我们实现处理请求类的宏观框架,读者有个大致的认识即可,博主下面会分别行进行实现,逐一进行讲解。
- 实现代码:
struct HttpRequest
{
//构造函数。
HttpRequest();
//从请求中获取一个完整的报文
string InCode(string& str);
//从报文中将请求的信息进行打散。
bool Deserialize(string& str);
//对请求报头解析并获取对应的内容。
void Prase()
//从指定目录中读取相关消息并进行返回。
string ReadFromFile(const string& path)
//获取返回网络的文件的类型。
string GetContentType()
//解析URL获取对应的网络资源。
string GetSourse();
//处理服务器收到的请求。
string HanderHttpMes(string &mes);
public:
//正文之前的部分
vector<string> infors;
//提供文件在网络中的类型。
unordered_map<string,string> content_type;
//请求方法,大多数为POST和GET方法。
string Method;
//统一资源定位符。
string Url;
//URL里面可能有读取文件信息,请求的都是网页文件。
string suffix = ".html";
//HTTP的版本,一般为1.1或者1.0的。
string Version;
//请求正文,一般来说响应是没有的。
string content;
//获取资源在服务器的路径,即根目录。
const string root = "./wwwroot";
};
- 主程序:
#include<iostream>
#include<memory>
#include "httpserver.hpp"
void Usage(char* pragma_name)
{
cout << endl << "Usage: " << pragma_name \
<< " + port[8000-8888]" << endl << endl;
}
int main(int argc,char* argv[])
{
if(argc != 2)
{
Usage(argv[0]);
return 1;
}
uint16_t port = stoi(argv[1]);
HttpRequest req;
std::unique_ptr<HttpServer> htp(new HttpServer(port,\
bind(&HttpRequest::HanderHttpMes,&req,placeholders::_1)));
//bind函数:指定类域,固定this指针,以及参数,从而封装
//出了一个返回值为string类型,参数为string&的函数。
htp->Init();
htp->Run();
return 0;
}
- 对请求的处理和程序的运行有了宏观的认识之后,下面我们先来编写一段代码,在网页中打印出简单的消息。
- HanderHttpMes的实现:
3.2.1 version1
version1:打印出简单的信息。
string HanderHttpMes(string &mes)
{
//避免mes过长,我们将其清空。
mes = "";
//空行
string empty_line = "\r\n";
//状态行
string state_line = "HTTP/1.1 200 OK\r\n";
//正文
string text = "hello world\r\n";
//报文段
string package_line = "Content-Length: " +\
to_string(text.size()) + empty_line;
//响应
string response = state_line + package_line +\
empty_line + text;
return response;
}
- 运行结果:
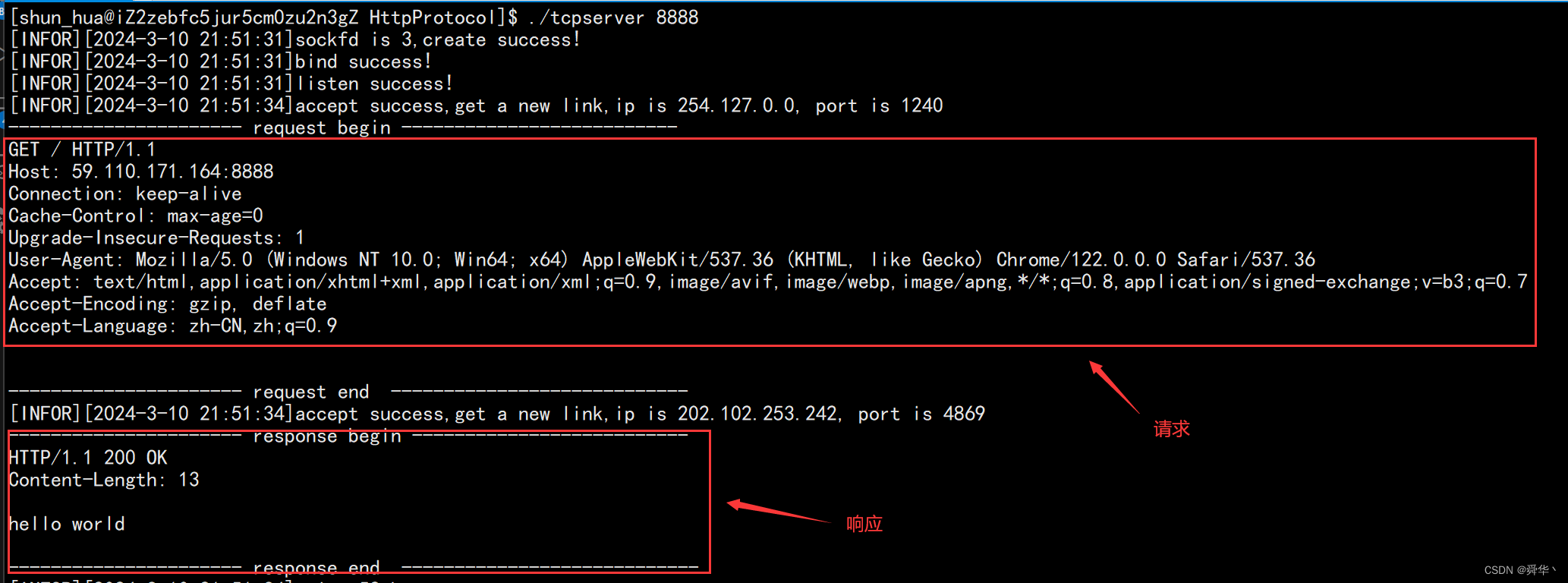
- 效果:
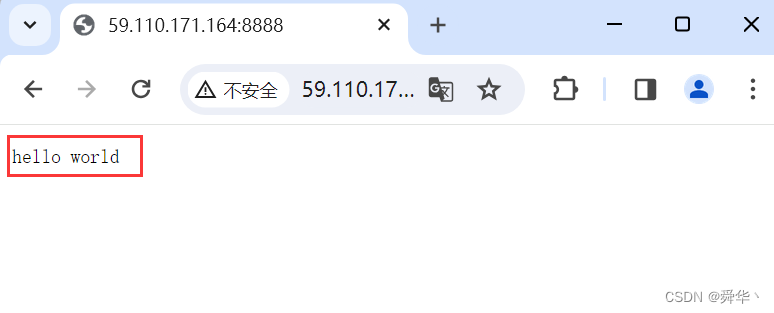
看到效果之后,我们便可大致明白,浏览器其实就是接收信息的客户端,并按照自定义协议将信息给上层用户进行呈现。
运用知识:
Content-Length:【空格】【正文段长度】【\r\n】—— 状态行信息,用于浏览器的获取正文段数据,并按照指定的方式呈现出来,这里我们只是打印出了文字。
- 缺陷:不管浏览器给我们发送什么请求,我们都只会返回hello world进行响应。
3.2.2 version2
version2: 完成请求的解析,提取出url,返回对应的网页资源。
- 请求解析。
- 思路:
1. 首先我们从缓存区中提取的不知道是否是一个完整的报文。
2. 因此我们应找到完整报文的解析符 ——\r\n\r\n。
3. 一般情况下,浏览器是不会发送正文段的,因此我们按照没有发送正文段的报文进行解析处理。- 拓展:我们可以看已经截取的请求报头中查看是否有Content-Length字段,如果有则有正文,解析其后的数据长度,截取正文段即可。
- InCode
string InConde(string& str)
{
string splite_str = "\r\n\r\n";
size_t pos = str.find(splite_str,0);
//如果没有找到说明不是一个完整的报文。
if(pos == string::npos)
{
return "";
}
int len = pos + splite_str.size();
string package = str.substr(0,len);
//将报文进行丢弃,便于截取下一次请求的报文。
str.erase(0,len);
return package;
}
- 打散请求
- 思路:
因为都是以\r\n以一行的形式进行呈现的,因此我们只需以\r\n截取出每一行即可,然后添加到类型为vector<string> 的infors即可。
- Deserialize
bool Deserialize(string& str)
{
//先看是否有完整的报文
string datagram = InConde(str);
int cur = 0;
while(true)
{
size_t pos = datagram.find(line_break,cur);
//从cur位置开始寻找。
//如果没有就说明解析出错了。
if(pos == string::npos) return false;
string line = datagram.substr(cur,pos - cur);
//截取pos - cur长度。
cur = pos + line_break.size();
//跳过line_break
if(line.empty()) break;
//读取到空行。
infors.push_back(line);
}
return true;
}
- 提取状态行。
- 思路:
- 这里报文都存在
infors中, 请求报头都在infors[0]中,因此我们将其解析出来即可。- 格式为:
[请求方法][空格][Url][空格][HTTP版本],以空格分隔出每一个元素即可。
除此之外,因为我们要从url中解析出相应的返回资源,下面我们列出第一次访问网址浏览器发送的两次请求:

- 说明: 第一次请求的是主页资源,主页资源的url也可以为 /index.html,第二次请求的是网页标签的logo。
- 举个百度标签的logo:

根据url解析出相应的文件信息,我们可以据此返回相应的资源了。
- Prase
void Prase()
{
//对一行的资源进行处理
string state_line = infors[0];
//[请求方法][空格][Url][空格][HTTP版本]
auto left = state_line.find(space);
auto right = state_line.rfind(space);
//请求方法
Method = state_line.substr(0,left);
//url
Url = state_line.substr(left + 1,right - left - 1);
//请求的HTTP版本。
Version = state_line.substr(right + 1);
//看URL中是否带有文件信息,如果有则解析出来,默认为 ".html"
auto pos = Url.rfind('.');
if(pos != string::npos)
{
suffix = Url.substr(pos);
//默认为.html
if(content_type[suffix] == "") suffix = ".html";
}
}
- 构造函数:
HttpRequest()
{
content_type[".jpg"] = "image/jpeg";
content_type[".html"] = "text/html";
content_type[".ico"] = "image/x-icon";
}
- 说明:
- 响应时,我们返回对应网页资源时,得说明是什么类型的,浏览器会按照响应的方式进行解析。
- 我们只需再状态行添加
[Content-Type:][空格][资源文件的类型],比如:Content-Type: text/html。
- 准备网页资源。
我们在当前目录下创建一个wwwroot作为根目录,存放网页资源文件,一般的网页以 .html 结尾。
因此我们成员变量设置了:
const string root = "./wwwroot"; //获取资源在服务器的路径,即根目录。
我们这里创建一个index.html,写一些网页信息:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Shun_Hua</title>
</head>
<body>
<h1 >欢迎来到我的主页!</h1>
</body>
</html>
- 说明:
- 首先博主采用的是vscode编写较为轻量,写起来也很轻松,按下
! 加上 Tab可以快速生成一个网页框架。- 这里涉及一些前端的知识,博主在写项目时候总结了一下常用的,具体可见:详见目录前端编写模块 。
下面是如何找的过程,首先我们要从url获取到文件的信息,再跟网页的根目录进行拼接,具体实现如下:
- GetSourse
string GetSourse()
{
//根据Url,确定返回的资源
string path = root;
//主页资源。
if(Url == "/" || Url == "/home.html")
path += "/home.html";
else
{
path += Url;
}
//从文件中读取消息。
return ReadFromFile(path);
}
下一步是从获取到的具体路径文件中,读取文件信息,作为正文段进行返回。
- ReadFromFile
string ReadFromFile(const string& path)
{
//从文件中读取对应的内容。
std::ifstream fs(path,ios_base::in);
if(!fs.is_open()) return "404 Not Found";
string content;
//直接读取到文件的结尾
fs.seekg(0,fs.end);
//获取文件的长度。
auto len = fs.tellg();
//回退到文件的长度。
fs.seekg(0,fs.beg);
//直接将内容读取出来,将内容打到进去,这是比较暴力但是比较简单的做法。
content.resize(len);
fs.read((char*)content.c_str(),content.size());
return content;
}
以上的代码写完之后,我们可以再写一个更加高级的处理消息的函数:
- HanderHttpMes
string HanderHttpMes(string &mes)
{
HttpRequest req;
//首先对mes进行解析,获取完整的报文,解析失败返回空串。
if(!req.Deserialize(mes)) return "";
//其次解析出报头信息。
req.Prase();
//从Url中获取相应的网页资源。
string text = req.GetSourse(); //正文
string empty_line = "\r\n"; //空行
string state_line = "HTTP/1.1 200 OK\r\n";//状态行
string package_line = "Content-Length: " \
+ to_string(text.size()) + empty_line;
string content_type_line = "Content-Type: "\
+ content_type[suffix] + empty_line;
string response = state_line + package_line + empty_line + text;
return response;
}
- 效果:
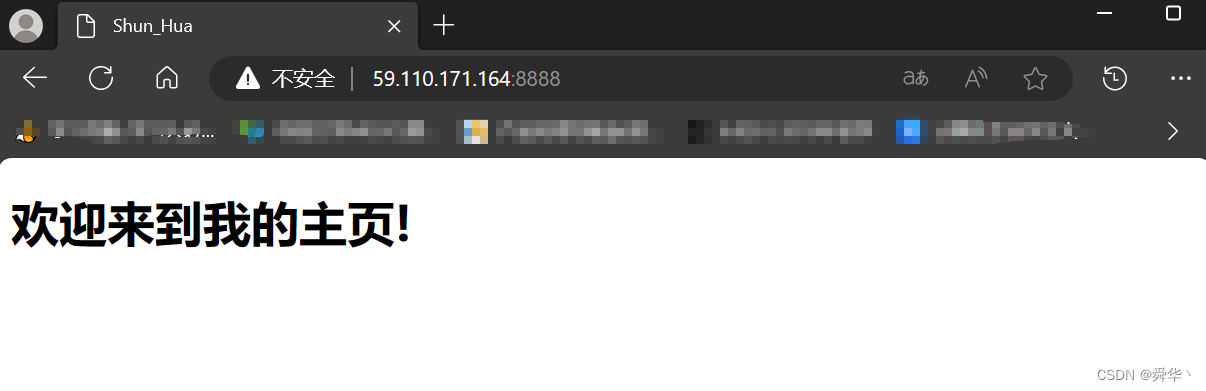
- 返回的响应:
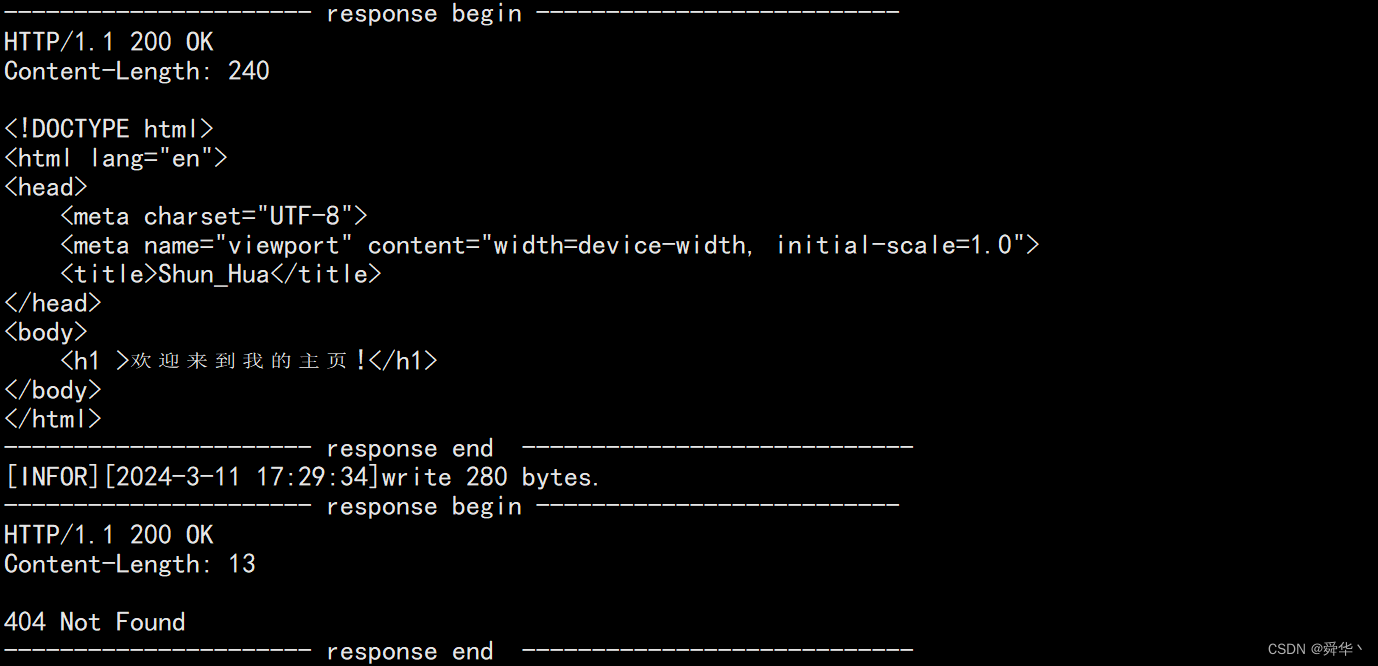
下面我们来一点前端的知识,让页面更加丰富多采一点:
- 增加网页标签logo
- 推荐网站:免费Favicon.ico图标在线生成器
- 这里我输入文字:舜华,进行自动生成。或者直接用现成的也可以。
- 点击图片下载保存到能找到的文件夹。
- 在Linux会话窗口使用:
rz -E命令,将.ico文件上传到Linux的存放网页文件的目录下。

然后我们再刷新网页,看一看效果:
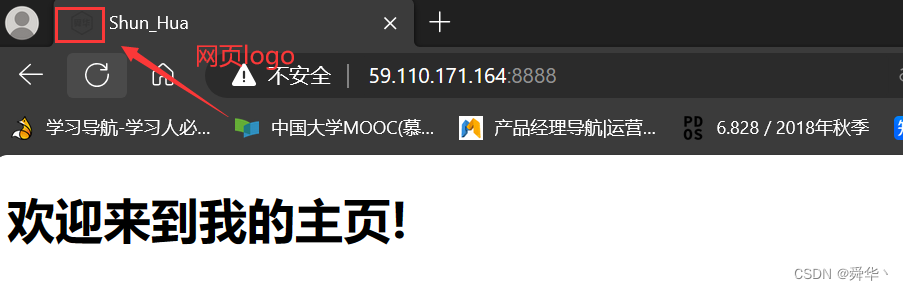
- 有总比没有强,虽然颜色有点重,hhh。
此后,我们可以直接在网页文件中编写内容,服务器启动着,浏览器刷新即可更新出新的网页内容。
- 说明:以下所有更新文件都在
./wwwroot路径下。
更新网页内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Shun_Hua</title>
</head>
<body>
<h1 >欢迎来到我的主页!</h1>
<!-- >更新内容,添加网页链接,可以跳转到指定网页 <-->
<a href="http://59.110.171.164:8888/"> 回到主页 </a>
</br> <!-- >回车换行的意思<-->
<a href="http://59.110.171.164:8888/tail.html"> 尾页 </a>
</body>
</html>
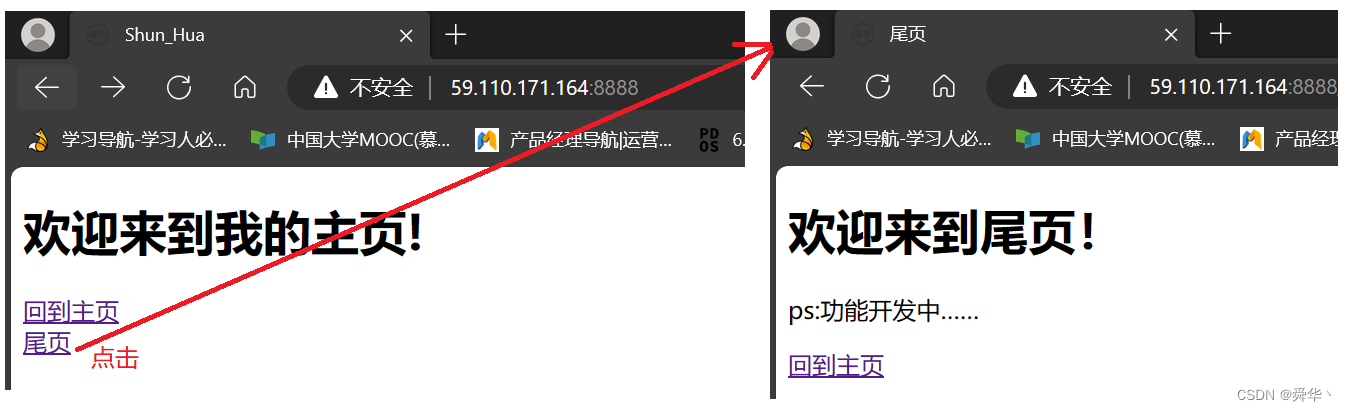
添加尾页内容:
- tail.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>尾页</title>
</head>
<body>
<h1>欢迎来到尾页!</h1>
<p>ps:功能开发中……</p>
<a href="http://59.110.171.164:8888/"> 回到主页 </a>
</body>
</html>
刷新界面:
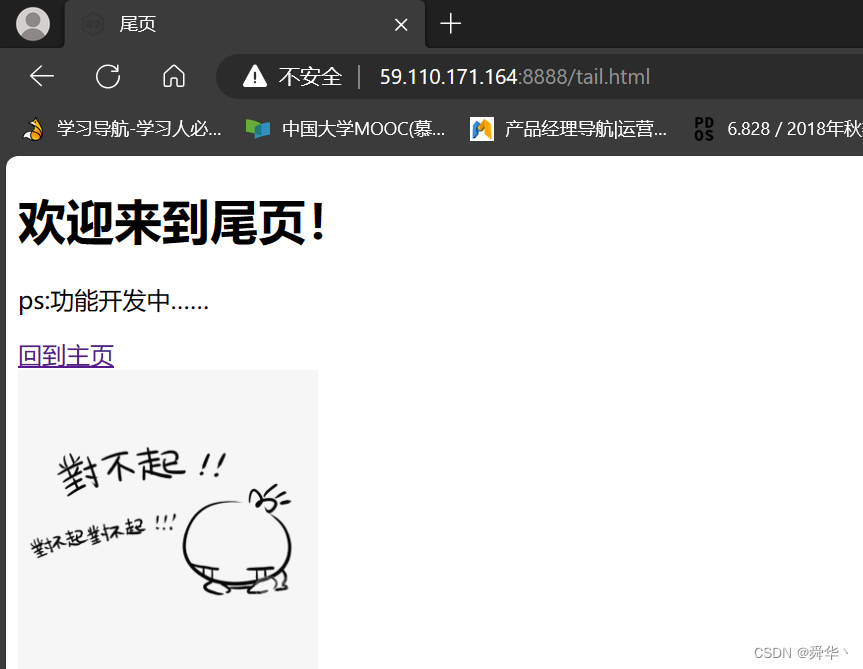
在尾页添加图片:
- 图片 ——1.png

- tail.html
<!-- >说明:未补充内容同上 <-->
<body>
<h1>欢迎来到尾页!</h1>
<p>ps:功能开发中……</p>
<a href="http://59.110.171.164:8888/"> 回到主页 </a>
<br>
<img src = "./1.jpg" alt="实在抱歉" width="200px" height="200px">
<!-- >加载对应的图片,设置图片加载失败时的提示,设置图片的宽度和高度 <-->
</body>
效果:
- 综上所述,我们使用一点点前端知识,将网页变的不至于那么单调,简单的完成与用户进行交互。
- 说明:以上都是请求成功的情况,那有没有请求失败的的情况呢?下面我们继续深入了解
响应行和响应报头。
3.2.3 version3
- version3: 学习响应行和响应报头。
- 重定向
- 状态码:3XX,重定向,需要进一步的操作以完成请求。这里使用 302 Found。
- 状态行: 既然重定向了,我们还得告诉浏览器的重定向的地址是什么,这里我们使用302,状态行表示成:
[Location:][空格][网址][\r\n]。
- HanderHttpMes
string HanderHttpMes(string &mes)
{
HttpRequest req;
string state_line = "HTTP/1.1 302 Found\r\n";//状态行
string location_line = "Location: https://www.baidu.com\r\n";
string empty_line = "\r\n"; //空行
string response = state_line + location_line + empty_line;
return response;
}
- 效果:

2. 网页资源不存在
- 状态码:4XX,客户端错误,请求包含语法错误或无法完成请求。这里使用 404 Not Found。
- 状态行: 既然找不到,我们就返回一个表示找不到的网页即可。
- HanderHttpMes
string HanderHttpMes(string &mes)
{
//如果解析出来的Url不存在,我们可以直接返回错误界面,
//这里我们只是简单的演示一下效果。
mes.resize(0);
HttpRequest req;
string text = ReadFromFile(root + "/errno.html") + "\r\n";
string state_line = "HTTP/1.1 404 Not Found\r\n";//状态行
string len_line = "Content-Length: " + to_string(text.size()) + "\r\n";
string empty_line = "\r\n"; //空行
string response = state_line + len_line + empty_line + text;
return response;
}
- errno.html
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>404 Not Found</title>
<style>
body {
text-align: center;
padding: 150px;
}
h1 {
font-size: 50px;
}
body {
font-size: 20px;
}
a {
color: #008080;
text-decoration: none;
}
a:hover {
color: #005F5F;
text-decoration: underline;
}
</style>
</head>
<body>
<div>
<h1>404</h1>
<p>页面未找到<br></p>
<p>
您请求的页面可能已经被删除、更名或者您输入的网址有误。<br>
请尝试使用以下链接或者自行搜索:<br><br>
<a href="https://www.baidu.com">百度一下></a>
</p>
</div>
</body>
</html>
- 说明:网上有现成的,直接拿来用即可。
- 效果:

- 设置cookie
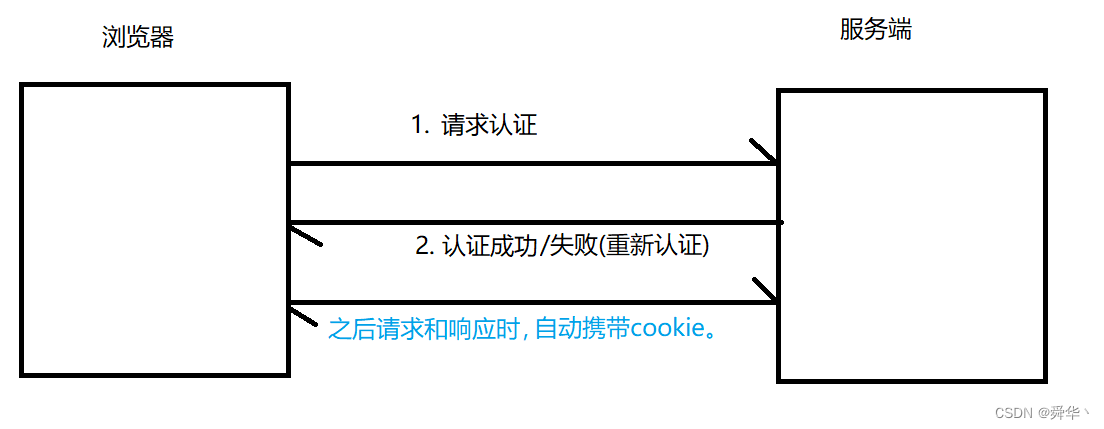
概念:cookie是一种文本文件,会进行存储记录用户的相关信息,发送给服务器进行认证。
优点:下一次登录时,会直接用已经存储好的cookie文件,无需再次登录认证。
- 图解:
如何查看呢?下面我们以CSDN的首页进行举例。
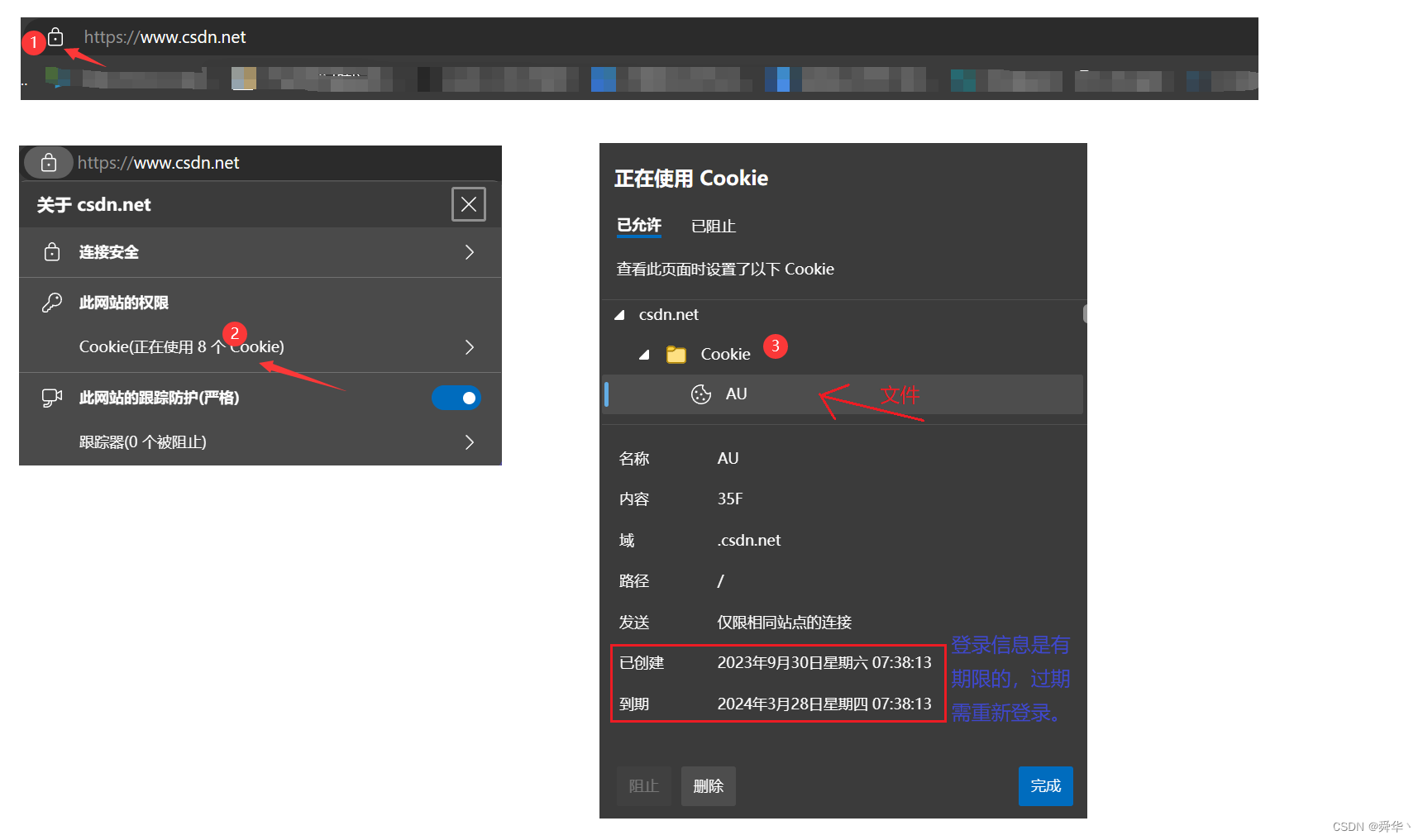
说明:cookie文件是有保质期的,过期了cookie会无效,需要再次认证。
- HanderHttpMes
string HanderHttpMes(string &mes)
{
//如果解析出来的Url不存在,我们可以直接返回错误界面,
//这里我们只是简单的演示一下效果。
HttpRequest req;
if(!req.Deserialize(mes)) return "";
req.Prase();
string text = req.GetSourse();
string state_line = "HTTP/1.1 200 OK\r\n";//状态行
string len_line = "Content-Length: " + to_string(text.size()) + "\r\n";
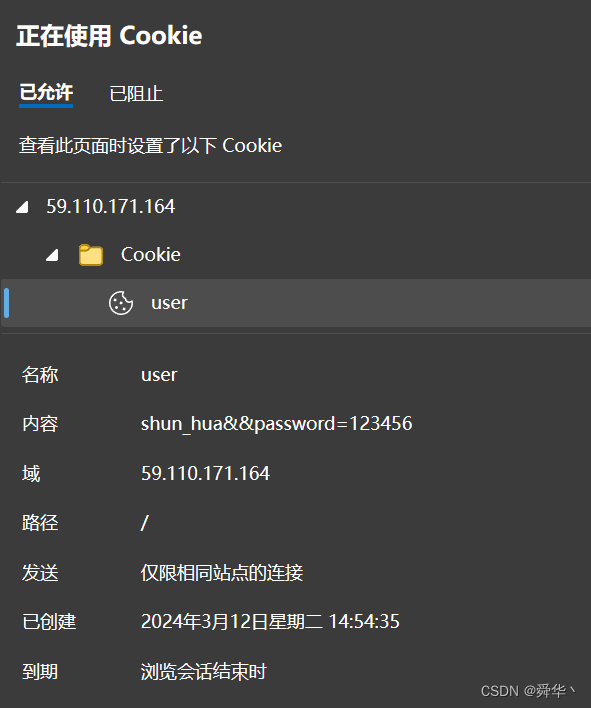
string cookie_line = "Set-Cookie: user=shun_hua&&password=123456\r\n";
string empty_line = "\r\n"; //空行
string response = state_line + len_line + cookie_line + empty_line + text;
return response;
}
-
效果:

-
网页中的cookie文件:
- 这里总结一下对响应和请求的大致分类:
- 状态码
| 状态码 | 状态描述 |
|---|---|
| 1XX | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2XX | 成功,操作被成功接收并处理 |
| 3XX | 重定向,需要进一步的操作以完成请求 |
| 4XX | 客户端错误,请求包含语法错误或无法完成请求 |
| 5XX | 服务器错误,服务器在处理请求的过程中发生了错误 |
- 当我们使用具体的状态码时,查表即可,但是我们要对状态码的分类比较清楚,上面我们使用了404,302,200进行了演示。
- Header
| Header | 描述 |
|---|---|
| Content-Type: | 数据类型(text/html等) |
| Content-Length: | Body的长度 |
| Host: | 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上; |
| User-Agent: | 声明用户的操作系统和浏览器版本信息; |
| referer: | 当前页面是从哪个页面跳转过来的; |
| location: | 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问; |
| Cookie: | 用于在客户端存储少量信息. 通常用于实现会话(session)的功能 |
- 常用状态码与响应头
- 请求方法
| 请求方法 | 描述 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体。 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
- 说明:大多数请求都是Get和Post,其它的我们当做了解即可。
总结
- 我们认识了一些现成的应用层协议,比如SMTP,FTP,SSH等。
- 了解了Http的基本概念,比如域名,默认端口号,统一资源定位符。
- 介绍了三个抓包工具,fiddler,postman,apifox。
- 使用telnet工具发送请求,接收响应。并列出了请求和响应的框架,据此学习了长连接和短连接的知识。
- 编程实践,编写一个网络的Server服务和Request类处理请求,通过此学习了常用的请求行的状态码,请求报头等,一些网页的前端知识,比如标题logo,图片,链接,编写了一个简单网页。
- 下期预告:
我们此文提及了cookie一般是含认证信和密码之类的信息,但http是明文传输的,这就导致了数据在网络中是不安全的,这就涉及到了加密,据此引出下篇文章要讨论的Https,敬请期待!。
尾序
我是舜华,期待与你的下一次相遇!