文章目录
- 前言
- Abstract
- 1.Introduction
- 1.1. Related Work
- 1.2. Motivations and contributions
- 2. Method
- 2.1. Deconvolution layer
- 2.2. Efficient sub-pixel convolution layer
- 3. Experiments
- 3.1. Datasets
- 3.2. Implementation details
- 3.3. Image super-resolution results
- 3.3.1 Benefits of the sub-pixel convolution layer
- 3.3.2 Comparison to the state-of-the-art
- 3.4. Video super-resolution results
- 3.5. Run time evaluations
- 4. Conclusion
- 5. Future work
前言
论文题目:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network —— 加速超分辨率卷积神经网络
论文地址:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
代码地址:https://github.com/leftthomas/ESPCN
Abstract
最近,基于深度神经网络的几个模型在单幅图像超分辨率的重构精度和计算性能方面都取得了巨大的成功。在这些方法中,低分辨率 (LR) 输入图像在重建之前使用单个滤波器(通常是双三次插值)放大到高分辨率 (HR) 空间。这意味着超分辨率 (SR) 操作是在 HR 空间中执行的。我们证明了这是次优的,并增加了计算复杂度。在本文中,我们提出了第一个卷积神经网络 (CNN),能够在单个 K2 GPU 上实时 SR 1080p 视频。为了实现这一点,我们提出了一种新颖的 CNN 架构,其中特征图是在 LR 空间中提取的。此外,我们引入了一种高效的亚像素卷积层,该层学习一系列放大滤波器,以将最终的 LR 特征图升级到 HR 输出中。通过这样做,我们有效地将 SR 管道中手工制作的双三次滤波器替换为专门为每个特征图训练的更复杂的放大滤波器,同时还降低了整体 SR 操作的计算复杂度。我们使用来自公开可用数据集的图像和视频来评估所提出的方法,并表明它的性能明显优于(图像 +0.15dB 和视频 +0.39dB),并且比以前基于 CNN 的方法快一个数量级。
摘要总览:一个新颖的CNN结构,用了亚像素卷积层(sub-pixel convolution),速度提升非常大。
1.Introduction
从低分辨率 (LR) 计数器部分恢复高分辨率 (HR) 图像或视频是数字图像处理中非常感兴趣的主题。该任务被称为超分辨率(SR),在许多领域都发现了直接应用,如HDTV[15]、医学成像[28,33]、卫星成像[38]、人脸识别[17]和监视[53]。全局 SR 问题假设 LR 数据是 HR 数据的低通滤波(模糊)、下采样和噪声版本。这是一个高度不适定的问题,由于在非可逆低通滤波和子采样操作期间发生的高频信息的损失。此外,SR 操作实际上是从 LR 到 HR 空间的一对多映射,可以有多个解决方案,其中确定正确的解决方案并非易事。许多 SR 技术的基础的一个关键假设是大部分高频数据是多余的,因此可以从低频分量中准确重建。因此,SR 是一个推理问题,因此依赖于我们问题中图像统计的模型。
许多方法假设多个图像可以作为同一场景的LR实例,具有不同的视角,即具有独特的先验仿射变换。这些可以分为多图像 SR 方法 [1, 11],并通过用附加信息约束不适定问题并尝试反转下采样过程来利用显式冗余。然而,这些方法通常需要计算复杂的图像配准和融合阶段,其准确性直接影响结果的质量。另一类方法是单图像超分辨率 (SISR) 技术 [45]。这些技术试图学习自然数据中存在的隐式冗余,以从单个 LR 实例中恢复缺失的 HR 信息。这通常以图像的局部空间相关性和视频中的附加时间相关性的形式出现。在这种情况下,需要以重构约束的形式的先验信息来限制重构的解空间。
1.1. Related Work
SISR方法的目标是从单个LR输入图像[14]中恢复HR图像。最近流行的SISR方法可以分为基于边缘的[35]、基于图像统计的[9,18,46,12]和基于补丁的[2,43,52,13,54,40,5]方法。有关更通用的SISR方法的详细回顾可以在[45]中找到。最近在解决SISR问题方面蓬勃发展的一类方法是基于稀疏性的技术。稀疏编码是一种有效的机制,它假设任何自然图像都可以在变换域中稀疏表示。该变换域通常是图像原子的字典 [25, 10],可以通过试图发现 LR 和 HR 补丁之间的对应关系的训练过程来学习。该词典能够嵌入约束超分辨率不可见数据的不适定问题所需的先验知识。这种方法是在[47,8]的方法中提出的。基于稀疏性的技术的一个缺点是,通过非线性重建引入稀疏性约束通常计算成本很高。
通过神经网络导出的图像表示[21,49,34]最近也显示出SISR的前景。这些方法采用反向传播算法[22]在大型图像数据库(如ImageNet[30])上进行训练,以学习LR和HR图像补丁的非线性映射。[4]中使用了堆叠协作局部自动编码器逐层超分辨率LR图像。Osendorfer等人[27]提出了一种基于预测卷积稀疏编码框架[29]的扩展的SISR方法。[7]中提出了一种受稀疏编码方法启发的多层卷积神经网络(CNN)。陈等人。al.[3]提出使用多级可训练非线性反应扩散(TNRD)作为CNN的替代方案,其中权值和非线性是可训练的。王等人。al[44]在LISTA(学习迭代收缩和阈值算法)[16]的启发下,从端到端训练级联稀疏编码网络,以充分利用图像的自然稀疏性。网络结构不限于神经网络,例如随机森林 [31] 也已成功用于 SISR。
1.2. Motivations and contributions
随着 CNN 的发展,算法的效率,尤其是它们的计算和内存成本,变得越来越重要 [36]。与之前手工制作的模型相比,深度网络模型学习非线性关系的灵活性已被证明可以获得更好的重建精度[27,7,44,31,3]。为了将 LR 图像超分辨率到 HR 空间中,有必要增加 LR 图像的分辨率以匹配 HR 图像在某个点的分辨率。
在Osendorfer等人[27]中,图像分辨率在网络中间逐渐增加。另一种流行的方法是增加网络第一层前后的分辨率[7,44,3]。然而,这种方法有一些缺点。首先,在图像增强步骤之前增加LR图像的分辨率会增加计算复杂度。这对于卷积网络来说尤其成问题,其中处理速度直接取决于输入图像分辨率。其次,通常用于完成任务的插值方法,如双三次插值[7,44,3],并没有带来额外的信息来解决不适定重构问题。
Dong et al.al.[6]的脚注简要建议学习升级过滤器。然而,将其集成到 CNN 中作为 SR 操作的一部分的重要性尚未得到充分识别,并且未探索选项。此外,正如Dong等人[6]所指出的,卷积层没有有效的实现,其输出大小大于输入大小,并且像convnet[21]这样的优化良好的实现不容易允许这种行为。
在本文中,与之前的工作相反,我们建议仅在网络的末尾将 LR 的分辨率从 HR 增加到 HR,并从 LR 特征图超分辨率 HR 数据。这消除了在更大 HR 分辨率下执行大部分 SR 操作的必要性。为此,我们提出了一种更有效的亚像素卷积层来学习图像和视频超分辨率的放大操作。
这些贡献的优点有两个方面:
-
在我们的网络中,升级由网络的最后一层处理。这意味着每个 LR 图像直接馈送到网络,特征提取通过 LR 空间中的非线性卷积进行。由于输入分辨率的降低,我们可以有效地使用更小的滤波器大小来整合相同的信息,同时保持给定的上下文区域。分辨率和滤波器尺寸的减小大大降低了计算和内存复杂度,以允许实时超分辨率高清(HD)视频,如第3.5节所示。
-
对于具有L层的网络,我们学习了nL−1特征映射的nL−1放大滤波器,而不是输入图像的一个放大滤波器。此外,不使用显式插值滤波器意味着网络隐式学习 SR 所需的处理。因此,与第一层的单个固定滤波器放大相比,该网络能够学习更好、更复杂的 LR 到 HR 映射。这导致模型的重建精度有额外的收益,如第3.3.2节和第3.4节所示。
我们使用来自公开可用的基准数据集的图像和视频验证了所提出的方法,并将我们的性能与包括 [7, 3, 31] 在内的以前的工作进行了比较。我们表明,所提出的模型实现了最先进的性能,并且比之前发布的图像和视频方法快近一个数量级。
创新点:1.最后一层才放大,前面都是在低分辨率下处理,这样就可以使用更小的卷积核,保证信息的联系。2.对于特征图学习对应层的filters,而不是对于输入图像。
2. Method
SISR的任务是在给定从相应的原始HR图像 I H R I^{HR} IHR缩小的LR图像 I L R I^{LR} ILR的情况下估计HR图像 I S R I^{SR} ISR。下采样操作是确定性的,已知:为了从 IHR 生成 ILR,我们首先使用高斯滤波器对 IHR 进行卷积——从而模拟相机的点扩散函数——然后将图像下采样 r 倍。我们将 r 称为放大率。一般来说,ILR 和 IHR 都可以有 C 个颜色通道,因此它们分别表示为大小为 H × W × C 和 rH × rW × C 的实值张量。
为了解决SISR问题,[7]中提出的SRCNN从ILR的放大和插值版本中恢复,而不是ILR。为了恢复 ISR,使用了 3 层卷积网络。在本节中,我们提出了一种新颖的网络架构,如图 1 所示,以避免在将其输入网络之前升级 ILR。在我们的架构中,我们首先将 l 层卷积神经网络直接应用于 LR 图像,然后应用亚像素卷积层来升级 LR 特征图以产生 ISR。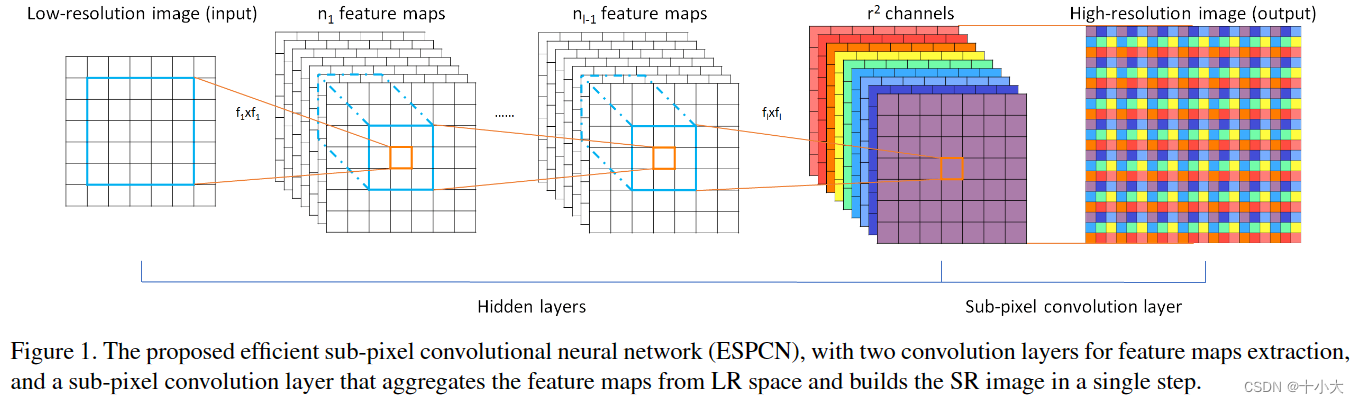
对于由 L 层组成的网络,第一个 L-1 层可以描述如下:
f
1
(
I
L
R
;
W
1
,
b
1
)
=
ϕ
(
W
1
∗
I
L
R
+
b
1
)
,
(1)
f^{1}\left(\mathbf{I}^{L R} ; W_{1}, b_{1}\right)=\phi\left(W_{1} * \mathbf{I}^{L R}+b_{1}\right),\tag{1}
f1(ILR;W1,b1)=ϕ(W1∗ILR+b1),(1)
f
l
(
I
L
R
;
W
1
:
l
,
b
1
:
l
)
=
ϕ
(
W
l
∗
f
l
−
1
(
I
L
R
)
+
b
l
)
,
(2)
f^{l}\left(\mathbf{I}^{L R} ; W_{1: l}, b_{1: l}\right)=\phi\left(W_{l} * f^{l-1}\left(\mathbf{I}^{L R}\right)+b_{l}\right),\tag{2}
fl(ILR;W1:l,b1:l)=ϕ(Wl∗fl−1(ILR)+bl),(2)
其中 Wl, bl, l ∈ (1, L − 1) 分别是可学习的网络权重和偏差。Wl 是一个大小为 nl−1 × nl × kl × kl 的 2D 卷积张量,其中 nl 是第 l 层的特征数,n0 = C,kl 是第 l 层的滤波器大小。偏差 bl 是长度为 nl 的向量。非线性函数(或激活函数)φ按元素应用并固定。最后一层 f L 必须将 LR 特征图转换为 HR 图像 ISR。
2.1. Deconvolution layer
反卷积层的添加是从最大池化和其他图像下采样层恢复分辨率的流行选择。这种方法已成功应用于可视化层激活[49]和使用来自网络[24]的高级特征生成语义分割。很容易证明 SRCNN 中使用的双三次插值是反卷积层的特例,如 [24, 7] 中所建议的。[50] 中提出的反卷积层可以看作是每个输入像素乘以步长为 r 的滤波器元素相乘,并将结果输出窗口的总和也称为反向卷积 [24]。然而,卷积后的任何减少(求和)都很昂贵。
2.2. Efficient sub-pixel convolution layer
另一种升级 LR 图像的方法是在 LR 空间中以 1/r 的分数步幅卷积,如 [24] 中所述,这可以通过从 LR 空间到 HR 空间的插值、穿孔 [27] 或未池化 [49] 天真地实现,然后在 HR 空间中步幅为 1 的卷积。这些实现将计算成本增加了 r^2 倍,因为卷积发生在 HR 空间中。
或者,在 LR 空间中步长为 1/r 的卷积,滤波器 Ws 的大小为 ks,权重间距为 1/r,将激活 Ws 的不同部分进行卷积。落在像素之间的权重只是没有被激活,不需要计算。激活模式的数量正好是 r^2。每个激活模式根据其位置,最多激活⌈ ks/r ⌉ ^ 2 个权重。根据不同的亚像素位置,这些模式在图像过滤器的卷积期间周期性地激活:mod (x, r) , mod (y, r),其中 x, y 是 HR 空间中的输出像素坐标。在本文中,我们提出了一种在 mod (ks, r) = 0 时实现上述操作的有效方法:
I
S
R
=
f
L
(
I
L
R
)
=
P
S
(
W
L
∗
f
L
−
1
(
I
L
R
)
+
b
L
)
(3)
\mathbf{I}^{S R}=f^{L}\left(\mathbf{I}^{L R}\right)=\mathcal{P S}\left(W_{L} * f^{L-1}\left(\mathbf{I}^{L R}\right)+b_{L}\right)\tag{3}
ISR=fL(ILR)=PS(WL∗fL−1(ILR)+bL)(3)
其中 PS 是一个周期性混洗算子,它将 H × W × C · r2 张量的元素重新排列为形状为 rH × rW × C 的张量。该操作的效果如图1所示。在数学上,该操作可以用以下方式描述
P
S
(
T
)
x
,
y
,
c
=
T
⌊
x
/
r
⌋
,
⌊
y
/
r
⌋
,
c
⋅
r
⋅
m
o
d
(
y
,
r
)
+
c
⋅
m
o
d
(
x
,
r
)
(4)
\mathcal{P} \mathcal{S}(T)_{x, y, c}=T_{\lfloor x / r\rfloor,\lfloor y / r\rfloor, c \cdot r \cdot \bmod (y, r)+c \cdot \bmod (x, r)}\tag{4}
PS(T)x,y,c=T⌊x/r⌋,⌊y/r⌋,c⋅r⋅mod(y,r)+c⋅mod(x,r)(4)
因此,卷积算子WL的形状为nL−1 ×r^2C × kL × kL。请注意,我们不会对最后一层卷积的输出应用非线性。很容易看出,当 kL = ksr 和 mod (ks, r) = 0 时,它等效于带有滤波器 Ws 的 LR 空间中的亚像素卷积。我们将我们的新层称为亚像素卷积层,我们的网络称为高效的亚像素卷积神经网络 (ESPCN)。最后一层直接从 LR 特征图生成 HR 图像,每个特征图都有一个放大滤波器,如图 4 所示。
给定一个由 HR 图像示例
I
n
H
R
I_n^{HR}
InHR, n = 1…N 组成的训练集 ,我们生成相应的 LR 图像
I
n
H
R
I_n^{HR}
InHR , n = 1… N ,并将重建的像素级均方误差 (MSE) 计算为训练网络的目标函数:
ℓ
(
W
1
:
L
,
b
1
:
L
)
=
1
r
2
H
W
∑
x
=
1
r
H
∑
x
=
1
r
W
(
I
x
,
y
H
R
−
f
x
,
y
L
(
I
L
R
)
)
2
(5)
\ell\left(W_{1: L}, b_{1: L}\right)=\frac{1}{r^{2} H W} \sum_{x=1}^{r H} \sum_{x=1}^{r W}\left(\mathbf{I}_{x, y}^{H R}-f_{x, y}^{L}\left(\mathbf{I}^{L R}\right)\right)^{2}\tag{5}
ℓ(W1:L,b1:L)=r2HW1x=1∑rHx=1∑rW(Ix,yHR−fx,yL(ILR))2(5)
值得注意的是,与 HR 空间中的归约或卷积相比,上述周期性混洗的实现可以非常快,因为每个操作都是独立的,因此在一个周期中可以简单地并行化。因此,与前向传递中的反卷积层相比,我们提出的层比前向传递中的反卷积层快 log2r2 倍,与在卷积之前使用各种形式的放大的实现相比快 r2 倍。
3. Experiments
补充材料中提供了定量评估的详细报告,包括图像和视频、下采样数据、超分辨率数据、整体和个人分数以及 K2 GPU 上的运行时间。
3.1. Datasets
在评估过程中,我们使用了公开可用的基准数据集,包括SISR论文[7,44,3]广泛使用的Timmofte数据集[40],它为多种方法、91张训练图像和两个测试数据集Set5和Set14提供5和14张图像的源代码;Berkeley分割数据集[26] BSD300和BSD500提供100和200张图像进行测试,超级纹理数据集[5]提供136张纹理图像。对于我们的最终模型,我们使用来自 ImageNet [30] 的 50,000 张随机选择的图像进行训练。在之前的工作之后,在本节中我们只考虑YCbCr颜色空间的亮度通道,因为人类对亮度变化更敏感[31]。对于每个放大因子,我们训练一个特定的网络。
对于视频实验,我们使用来自公开可用的 Xiph 数据库 1 的 1080p HD 视频,该视频已用于报告以前的方法中的视频 SR 结果 [37, 23]。该数据库包含8个高清视频的集合,长度约为10秒,宽度和高度为1920 × 1080。此外,我们还使用了Ultra Video Group数据库2,包含7个视频1920 × 1080大小和 5 秒的长度。
3.2. Implementation details
对于 ESPCN,我们在评估中设置 l = 3、(f1, n1) = (5, 64)、(f2, n2) = (3, 32) 和 f3 = 3。参数的选择受到SRCNN的3层9-5-5模型和2.2节中的方程的启发。在训练阶段,从训练地面真实图像IHR中提取17r × 17r像素子图像,其中r为放大因子。为了合成低分辨率样本ILR,我们使用高斯滤波器模糊IHR,并通过放大因子对其进行子采样。子图像是从原始图像中提取的,步幅为 IHR 的 (17 − ∑ mod (f, 2)) × r,步幅为 ILR 的 17 − ∑ mod (f, 2)。这确保了原始图像中的所有像素出现一次,只有一次作为训练数据的ground truth。我们选择 tanh 而不是 relu 作为我们的实验结果驱动的最终模型的激活函数。
在 100 个 epoch 之后没有观察到成本函数的改进后,训练停止。初始学习率设置为 0.01,最终学习率设置为 0.0001,当成本函数的改进小于阈值 μ 时逐渐更新。最后一层学习慢 10 倍,如 [7] 所示。在91张图像上的K2 GPU上训练大约需要3小时,ImageNet[30]图像的7天,放大系数为3。我们使用PSNR作为性能指标来评估我们的模型。SRCNN和Chen模型在扩展基准数据集上的PSNR是基于[7,3]提供的Matlab代码和模型计算的。
参数:l=3 三层网络,第一层(5,64),第二层(3,32),最后一层是亚像素卷积层卷积核是3。训练的时候从真实值中提取17r×17r的像素,为啥是这个大小呢,因为它可以确保所有像素只出现一次。
激活函数由Relu改成了tanh;训练100个epoch,学习率初始为0.01,最终为0.0001,当损失小于阈值的时候下降。最后一层学习率小10倍(参照SRCNN)。放大倍数为3,评价指标PSNR。
3.3. Image super-resolution results
3.3.1 Benefits of the sub-pixel convolution layer
在本节中,我们展示了亚像素卷积层以及 tanh 激活函数的积极影响。我们首先通过比较SRCNN的标准9-1-5模型[6]来评估亚像素卷积层的功率。在这里,我们遵循 [6] 中的方法,在本实验中使用 relu 作为我们模型的激活函数,并使用来自 ImageNet 的图像训练一组具有 91 张图像的模型和另一组模型。结果如表1所示。1. 与SRCNN模型相比,在ImageNet图像上训练的relu的ESPCN在统计上显著提高了更好的性能。值得注意的是,ESPCN (91) 的性能与 SRCNN (91) 非常相似。与具有相似参数数量(+0.33 vs +0.07)的 SRCNN 相比,使用 EPCN 训练更多图像对 PSNR 的影响要大得多。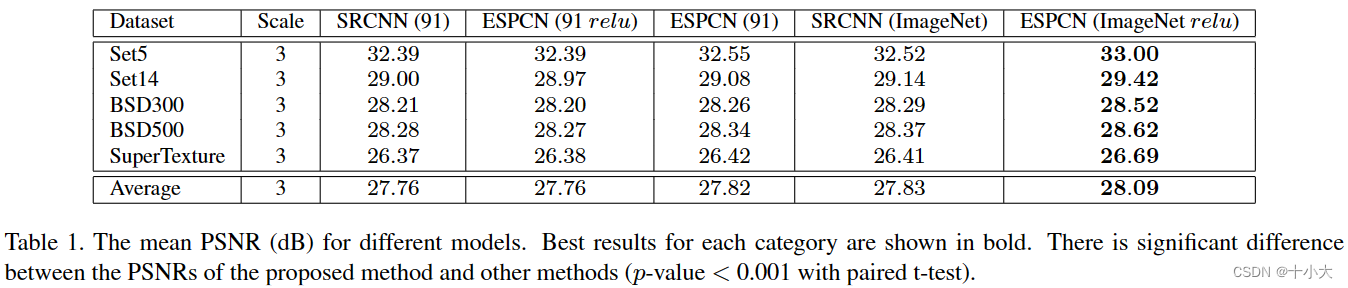
为了使我们的模型与亚像素卷积层和SRCNN的视觉比较,我们在图3和图4中可视化了我们的ESPCN (ImageNet)模型与[7]中的SRCNN 9-5-5 ImageNet模型的权重。我们的第一层和最后一层滤波器的权重与设计的特征有很强的相似性,包括log-Gabor滤波器[48]、小波[20]和Haar特征[42]。值得注意的是,尽管每个过滤器在 LR 空间中是独立的,但我们的独立过滤器实际上在 PS 之后的 HR 空间中是平滑的。与 SRCNN 的最后一层过滤器相比,我们最终的层过滤器对于不同的特征图具有复杂的模式,它也具有更丰富和更有意义的表示。

我们还基于在 91 张图像和 ImageNet 图像上训练的上述模型评估了 tanh 激活函数的效果。表1结果表明与 relu 相比,tanh 函数对 SISR 表现更好。具有 tanh 激活的 ImageNet 图像的结果如表2所示。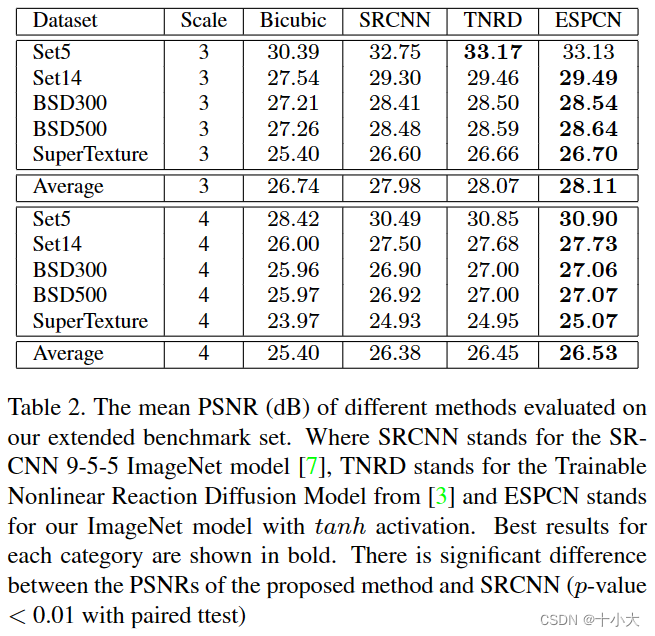
数值说明用了亚像素卷积层和tanh更好。
3.3.2 Comparison to the state-of-the-art
在本节中,我们展示了与SRCNN[7]和TNRD[3]的结果相比,在ImageNet上训练的ESPCN,后者是目前发表的性能最好的方法。为简单起见,我们没有显示已知比 [3] 差的结果。对于感兴趣的读者,其他以前的方法的结果可以在[31]中找到。我们选择与本节[7]中最好的SRCNN 9-5-5 ImageNet模型进行比较。对于 [3],结果是根据 7 × 7 5 阶段模型计算的。
在表2中,我们的结果显示明显优于 SRCNN 9-5-5 ImageNet 模型,同时接近,在某些情况下表现不佳,TNRD [3]。虽然TNRD使用单个双三次插值将输入图像升级到HR空间,但它可能受益于可训练的非线性函数。这种可训练的非线性函数不是我们的网络独有的,未来将会很有趣。超分辨率图像的视觉比较如图5和图6所示,CNN方法创建了一个更清晰、更高的对比度图像,ESPCN比SRCNN提供了显著的改进。

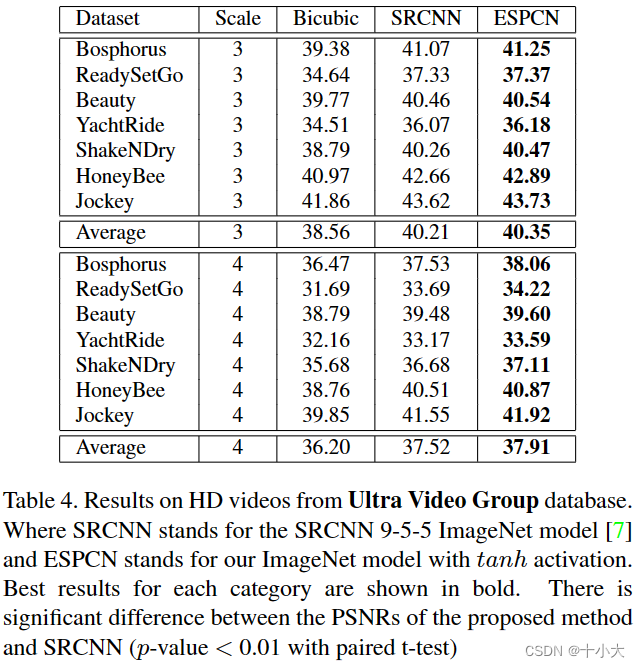
3.4. Video super-resolution results
在本节中,我们在两个流行的视频基准上将 ESPCN 训练模型与单帧双三次插值和 SRCNN [7] 进行比较。我们网络的一大优势是它的速度。这使得视频 SR 的理想候选者,它允许我们逐帧超分辨率视频帧。在表3和表4中 ,我们的结果显示优于 SRCNN 9-5-5 ImageNet 模型。改进比图像数据的结果更显着,这可能是由于数据集之间的差异。类似的视差可以在图像基准的不同类别中观察到,如Set5 vs SuperTexture。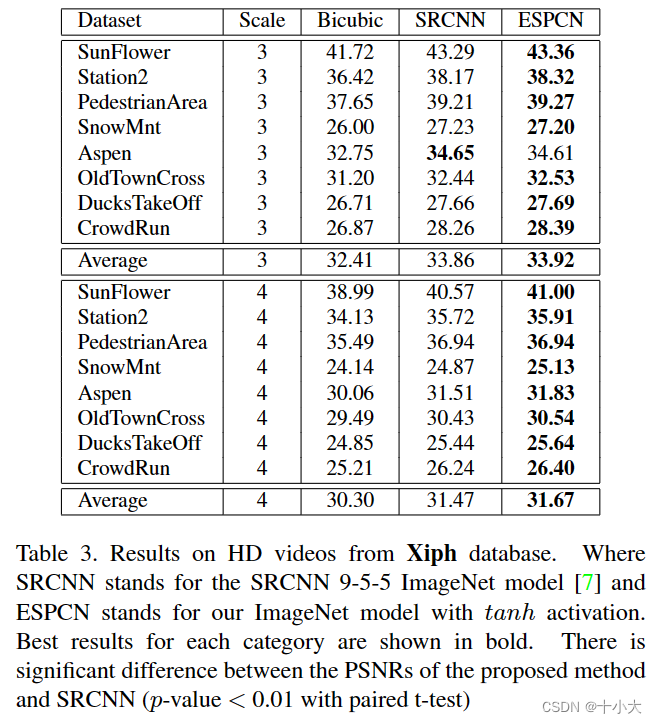
3.5. Run time evaluations
在本节中,我们评估了我们最好的模型在Set14^3上运行时间,缩放因子为3。我们从[40]和[31]提供的Matlab代码中评估了其他方法[2,51,39]的运行时间。对于使用卷积的方法,使用python/theano实现来提高基于[7,3]中提供的Matlab代码的效率。结果如图2所示。我们的模型运行速度比目前发布的最快方法快一个数量级。与SRCNN 9-5-5 ImageNet模型相比,超分辨率一幅图像所需的卷积次数小r × r倍,模型总参数个数小2.5倍。超分辨率操作的总复杂度降低了 2.5 × r × r 倍。我们在 K2 GPU 上实现了从 Set14 超分辨率一张图像的惊人平均速度 4.7 毫秒。利用网络的惊人速度,使用[36]中讨论的独立训练模型探索集成预测将在未来获得更好的SR性能会很有趣。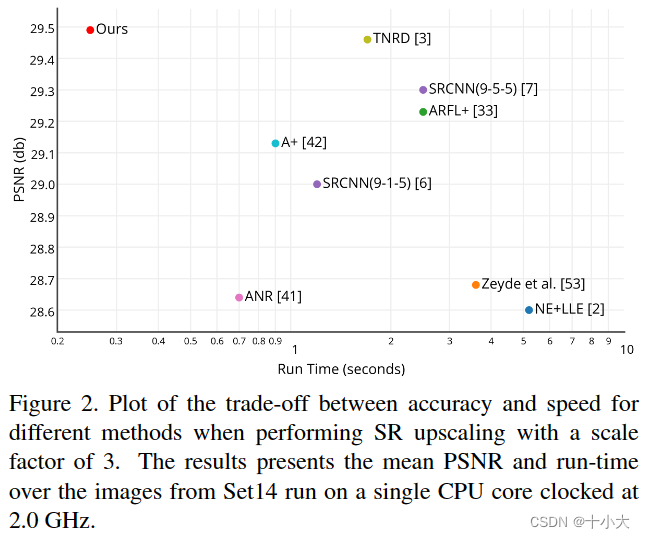
我们还使用 Xiph 和 Ultra Video Group 数据库中的视频评估了 1080 HD 视频超分辨率的运行时间。SRCNN 9-5 ImageNet 模型的提升因子为 3,每帧 SRCNN 9-5-5 ImageNet 模型需要 0.435 秒,而我们的 EPCN 模型每帧只需要 0.038 秒。SRCNN 9-5 ImageNet 模型的升级因子为 4,每帧需要 0.434 秒,而我们的 EPCN 模型每帧只需要 0.029 秒。
4. Conclusion
在本文中,我们证明了第一层的固定滤波器放大并不能为SISR提供任何额外的信息,但需要更多的计算复杂度。为了解决这个问题,我们建议在 LR 空间中执行特征提取阶段而不是 HR 空间。为此,我们提出了一种新颖的亚像素卷积层,它能够将 LR 数据超分辨率到 HR 空间中,与相比几乎没有额外的计算成本到反卷积层[50]。与之前具有更多参数的 CNN 方法相比,在放大因子为 4 的扩展基准数据集上进行的评估表明,与之前的具有更多参数的 CNN 方法相比,我们具有显着速度(> 10 倍)和性能(图像上的 +0.15dB 和视频上的 +0.39dB)提升 [7](53-3 对 9-5-5-5-5-5)。这使得我们的模型是第一个能够在单个 GPU 上实时 SR HD 视频的 CNN 模型。
5. Future work
处理视频信息时一个合理的假设是,大多数场景的内容都由相邻的视频帧共享。这一假设的例外是场景变化,物体偶尔出现或消失从场景中。这创建了额外的数据隐式冗余,可用于视频超分辨率,如[32,23]所示。时空网络很受欢迎,因为它们充分利用了视频中的时间信息进行人体动作识别[19,41]。未来,我们将研究将我们的 EPCN 网络扩展到时空网络,以使用 3D 卷积从多个相邻帧超分辨率一帧。
总结:
- 只在网络结构最后一层上采样,前面都是低分辨率,更容易提取特征,视频超分速度也更快。
- 最后一层用亚像素卷积,不用反卷积,上采样的重建效果更好。(为啥亚像素卷积更好呢?因为亚像素卷积不是卷积,而是像素重排,处理速度快。)
- 其他的细节看代码进一步理解。