前面给大家介绍过,本人既精通GIS开发全栈技术,也精通爬虫技术,对人工智能算法也比较熟悉。这些技术我会一一给大家讲解。
今天,咱们的主题是给大家通过一个案例讲解一下正则表达式的强大之处。当我们用爬虫获取网页的源码或内容时,这些内容可能比较杂乱无序,但是我们只需要提取一些重要的信息。比如下面这个例子:
ctn=`<meta data-vue-meta="true" http-equiv="X-UA-Compatible"
content="IE=edge"><meta data-vue-meta="true" itemprop="keywords" name="keywords" content="日本渔民亲口承认当地渔业遭受重创,搞笑研究所,生活记录,日本,脱口秀,恶搞,搞笑,核废水,搞笑研究所2023 5.0 爆笑一夏,生活,搞笑,哔哩哔哩,bilibili,B站,弹幕"><meta data-vue-meta="true" itemprop="description" name="description" content="日本渔民亲口承认当地渔业遭受重创, 视频播放量 209940、弹幕量 479、点赞数 15820、投硬币枚数 2837、收藏人数 782、转发人数 1112, 视频作者 张全蛋, 作者简介 上古时期自媒体创作者">`
现在我们有个需求,想要提取这些内容中的视频播放量 、弹幕量 、点赞数 、投硬币数 、收藏人数 、转发人数 这6项内容。
我们先分析下,第一眼看到这样的内容,很明显是从某网站上获取到的网页源码,也就是html文件内容。我们知道,一个html是由大量的标签组成的,标签内部又有很多内容,此外,html的内容也必然是多行。这种情况下,如果想精准的提取某些高价值的信息,必须要借助强大的正则表达式才行。为了方便大家学习和验证,下面我直接上代码,大家可以直接使用,代码为Javascript。
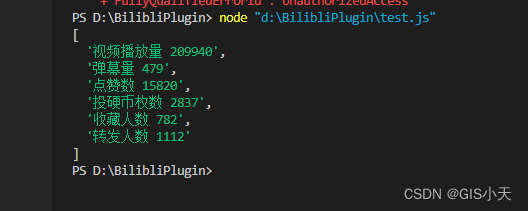
var pattern = /视频播放量.*,.*/; // 匹配两个单词之间的空格
var result = ctn.match(pattern);
gg=result[0]
vvv=gg.split(',')[0]
vvvvv=vvv.split('、')
console.log(vvvvv[0]); // 打印第一个匹配到的结果代码运行结果见下图: