LVS、Nginx、HAproxy的区别
LVS、Nginx和HAproxy都是常见的负载均衡器,用于将网络负载分散到多个服务器上,以提高系统的可用性和性能
功能不同:
LVS是一个Linux内核模块,在网络层(第四层)运行的。
Nginx和HAproxy则是运行在应用层(第七层)的反向代理服务器,可以实现更精细的负载均衡和流量控制。
支持的协议不同:
LVS支持的协议更多,包括TCP、UDP、FTP等。
Nginx和HAproxy主要支持HTTP和HTTPS协议。
性能不同:
LVS的性能较高,但配置和管理相对复杂。
Nginx和HAproxy的性能也很不错,而且配置和管理比较简单。
高可用性:
LVS可以使用VRRP来实现高可用性,在负载均衡器的背后有多个备用服务器。
Nginx和HAproxy需要配合使用第三方工具来实现高可用性,如Keepalived。
应用场景不同:
LVS适用于高并发、高吞吐量的场景,比如Web服务器。
Nginx和HAproxy适用于处理HTTP流量,并可以进行更细粒度的控制,比如根据URL进行请求分发、负载均衡和流量控制等。
健康检测
lvs没有后端服务器健康性检测,nginx和haproxy有后端服务器健康性检测
选择LVS还是Nginx或HAproxy主要取决于具体的业务需求和系统的规模。
较大规模的系统可以使用LVS,较小规模的系统可以考虑使用Nginx或HAproxy。调度算法的区别
| nginx | haproxy | lvs |
|---|---|---|
http协议的报文
-
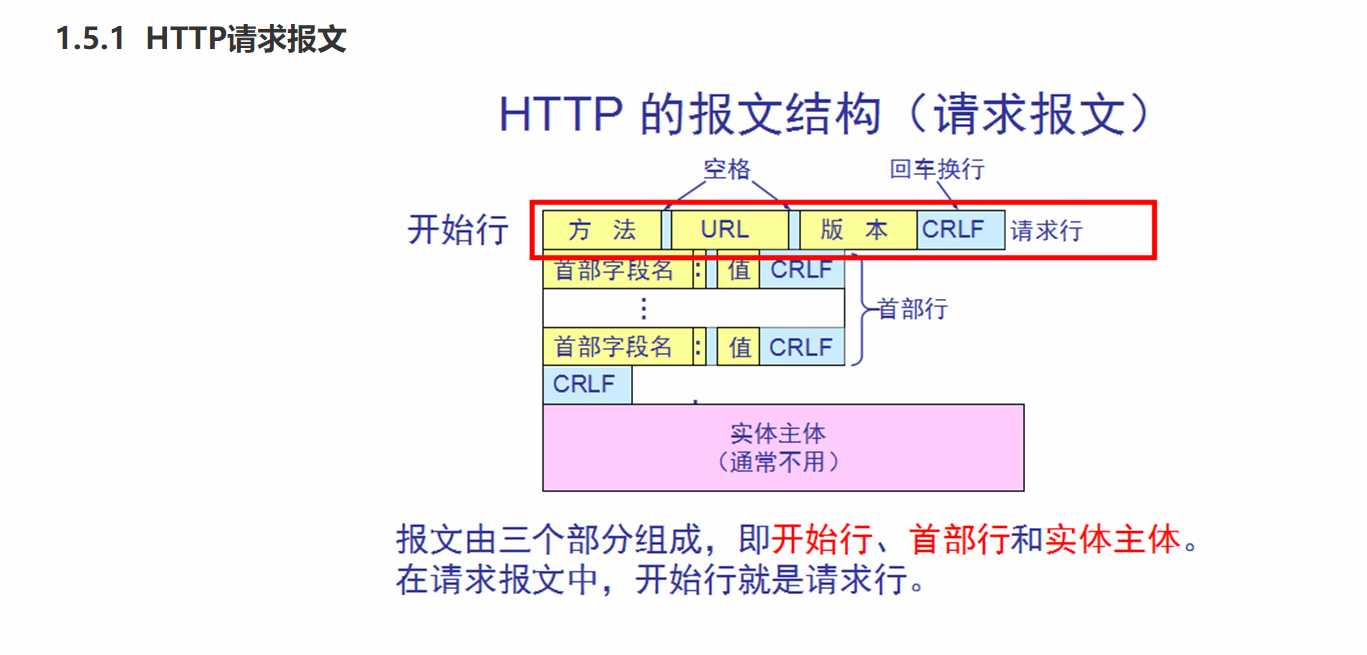
请求报文:
- 请求行:包含请求方法(GET、POST、PUT等)和请求的URI(Uniform Resource Identifier)。
- 请求头(Headers):包含了请求相关的一些信息,比如请求的主机地址、用户代理、Accept语义等。
- 请求体(Body):可选的,一般用于传递POST请求的参数和数据。
-
响应报文:
- 状态行:包含了响应的状态码(HTTP状态码)和原因短语。
- 响应头(Headers):包含了响应相关的一些信息,比如服务器类型、响应时间等。
- 响应体(Body):用于传输响应的具体内容,比如HTML页面、JSON数据等。
HTTP协议的七个过程
请求连接——建立连接——处理请求——访问资源——构建响应报文——发送响应报文——记录日志
dns解析——三次握手——七个过程——四次挥手
PV和UV
PV(Page View)是页面浏览量的缩写,表示用户在某个网站或者某个页面上的访问次数。
UV(Unique Visitor)是独立访客的缩写,表示一定时间内访问某个网站或页面的独立用户数量。
PV反映了页面的热度和用户行为,UV反映了网站或者页面的受众规模,通常结合PV和UV来综合评估网站或者页面的流量和用户活跃度
http协议的版本区别
HTTP(Hypertext Transfer Protocol)是一种用于传输超文本的应用层协议,常用于在Web浏览器和Web服务器之间进行通信
HTTP/0.9:是最早的HTTP协议版本,只支持GET(下载)请求,没有使用Header和状态码。
HTTP/1.0:在HTTP/0.9的基础上添加了支持POST(上传)请求、Header字段、状态码以及多种文件类型的传输。
HTTP/1.1:在HTTP/1.0的基础上进行了改进,加入了持久连接、管道化、HOST字段、缓存机制、断点续传、PUT和DELETE请求方法等新特性。
HTTP/2:是HTTP/1.1的继任者,引入了二进制传输、多路复用、头部压缩、服务器推送等特性,以提高性能和效率。
HTTP/3:是基于UDP协议的新一代HTTP协议,由于使用的传输层协议变为了QUIC(Quick UDP Internet Connections),支持无连接、低延迟和抗丢包等特性。
PUT和Post
如果一个方法重复执行多次,产生的效果是一样的,那就是idempotent的。也就是说:
PUT请求:如果两个请求相同,后一个请求会把第一个请求覆盖掉。(所以PUT用来改资源)
Post请求:后一个请求不会把第一个请求覆盖掉。(所以Post用来增资源)HTTP状态码
1xx(信息状态码):表示请求已接收,正在继续处理
100 Continue:继续。指示客户端可以继续发送请求
101 Switching Protocols:协议切换。服务器要求客户端切换协议
2xx(成功状态码):表示请求成功被服务器接收、理解和处理
200 OK:请求成功。服务器已成功处理请求
201 Created:已创建。请求已成功并创建了新的资源
202 Accepted:已接受。请求已接受但未完成处理
204 No Content:无内容。服务器成功处理请求,但无返回内容
3xx(重定向状态码):表示需要客户端进一步进行操作才能完成请求
301 Moved Permanently:永久重定向。请求的资源已被永久移动到新URL
302 Found:临时重定向。请求的资源已被临时移动到新URL
307 Temporary Redirect:临时重定向。请求的资源临时移动到新URL
4xx(客户端错误状态码):表示客户端发送的请求有错误
400 Bad Request:错误请求。请求语法错误或无法被服务器理解
401 Unauthorized:未授权。需要身份验证
403 Forbidden:禁止访问。服务器拒绝请求
404 Not Found:未找到。服务器找不到请求的资源
409 Conflict:当请求与服务器的当前状态冲突时,将发送此响应
5xx(服务器错误状态码):表示服务器在处理请求时发生错误
500 Internal Server Error:服务器错误。服务器在处理请求时发生错误
502 Bad Gateway:错误的网关。服务器作为网关或代理,从上游服务器接收到无效的响应
503 Service Unavailable:服务不可用。服务器暂时过载或维护MIME 类型
MIME (Multipurpose Internet Mail Extensions) 是描述消息内容类型的标准,用来表示文档、文件或字节流的性质和格式。
type/subtype
MIME 的组成结构非常简单,由类型与子类型两个字符串中间用 / 分隔而组成,不允许有空格。type 表示可以被分多个子类的独立类别,subtype 表示细分后的每个类型
常见的 MIME 类型
超文本标记语言文本 .html、.html:text/html
普通文本 .txt: text/plain
RTF 文本 .rtf: application/rtf
GIF 图形 .gif: image/gif
JPEG 图形 .jpeg、.jpg: image/jpeg
au 声音文件 .au: audio/basic
MIDI 音乐文件 mid、.midi: audio/midi、audio/x-midi
RealAudio 音乐文件 .ra、.ram: audio/x-pn-realaudio
MPEG 文件 .mpg、.mpeg: video/mpeg
AVI 文件 .avi: video/x-msvideo
GZIP 文件 .gz: application/x-gzip
TAR 文件 .tar: application/x-tarapache的工作模式
perfork
prefork模式(默认模式)要求稳定的时候使用
开启子进程,接待http请求(访问的人不多选)worker
worker模式 访问量多的时候使用
子进程开启线程event
event模式为了解决keep-alive保持长连接出现的一种工作模式;用来释放keep-alive类型的线程
event模式是不支持用在https上会话保持
压测工具ab
ab命令是Apache Bench的缩写。
ab命令是Apache自带的压力测试工具。
ab命令非常的实用,因为是基于URL地址测试的,所以它不仅可以对Apache服务器进行压力测试,也可以对Nginx、Tomcat、IIS等WEB服务器进行压力测试
ab命令对发出负载的计算机要求很低,它既不会占用很高CPU,也不会占用很多内存。但却会给目标服务器造成巨大的负载,其原理类似CC攻击。所以测试时需要注意,别上太多负载导致死机
nginx
select、poll和epoll的区别
select
select 的核心功能是调用tcp文件系统的poll函数,不停的查询,如果没有想要的数据,主动执行一次调度(防止一直占用cpu),直到有一个连接有想要的消息为止。从这里可以看出select的执行方式基本就是不停的调用poll,直到有需要的消息为止。
缺点:
1、每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大;
2、同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大;
3、select支持的文件描述符数量太小了,默认是1024。
优点:
1、select的可移植性更好,在某些Unix系统上不支持poll()。
2、select对于超时值提供了更好的精度:微秒,而poll是毫秒poll
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd
缺点:
1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义;
2、与select一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
优点:
1、poll() 不要求开发者计算最大文件描述符加一的大小。
2、poll() 在应付大数目的文件描述符的时候速度更快,相比于select。
3、它没有最大连接数的限制,原因是它是基于链表来存储的。epoll
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时, 返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一 个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射技术,这 样便彻底省掉了这些文件描述符在系统调用时复制的开销。
epoll的优点就是改进了前面所说缺点:
1、支持一个进程打开大数目的socket描述符:相比select,epoll则没有对FD的限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
2、IO效率不随FD数目增加而线性下降:epoll不存在这个问题,它只会对"活跃"的socket进行操作— 这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有"活跃"的socket才会主动的去调用 callback函数,其他idle状态socket则不会,在这点上,epoll实现了一个"伪"AIO,因为这时候推动力在os内核。在一些 benchmark中,如果所有的socket基本上都是活跃的—比如一个高速LAN环境,epoll并不比select/poll有什么效率,相 反,如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上了。
3、使用mmap加速内核与用户空间的消息传递:这点实际上涉及到epoll的具体实现了。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就 很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的三者对比与区别:
1、select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
2、select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。

阻塞和非阻塞
零拷贝技术
nginx模块
nginx编译安装脚本
分割日志
新生成的日志是不生效的,需要发送一个信号
server块构建虚拟主机
location语法规则优先级


动静分离
反向代理
重写功能
负载均衡
代理缓存
二叉树⭐
jvm
jre
jdk
tomcat 结合 nginx 实现动静分离(很重要★)











![[WUSTCTF2020]朴实无华](https://img-blog.csdnimg.cn/direct/4424d1e80e4046348651d79a5c195217.png)