文章目录
- 1. redis底层数据结构
- 2. 插入KV底层源码流程分析
1. redis底层数据结构
redis 6数据结构和底层数据结构的关系

String类型本质是SDS动态字符串,即redis层面的数据结构底层会有对应的数据结构实现,上面是redis 6之前的实现
redis 7数据结构和底层数据结构的关系
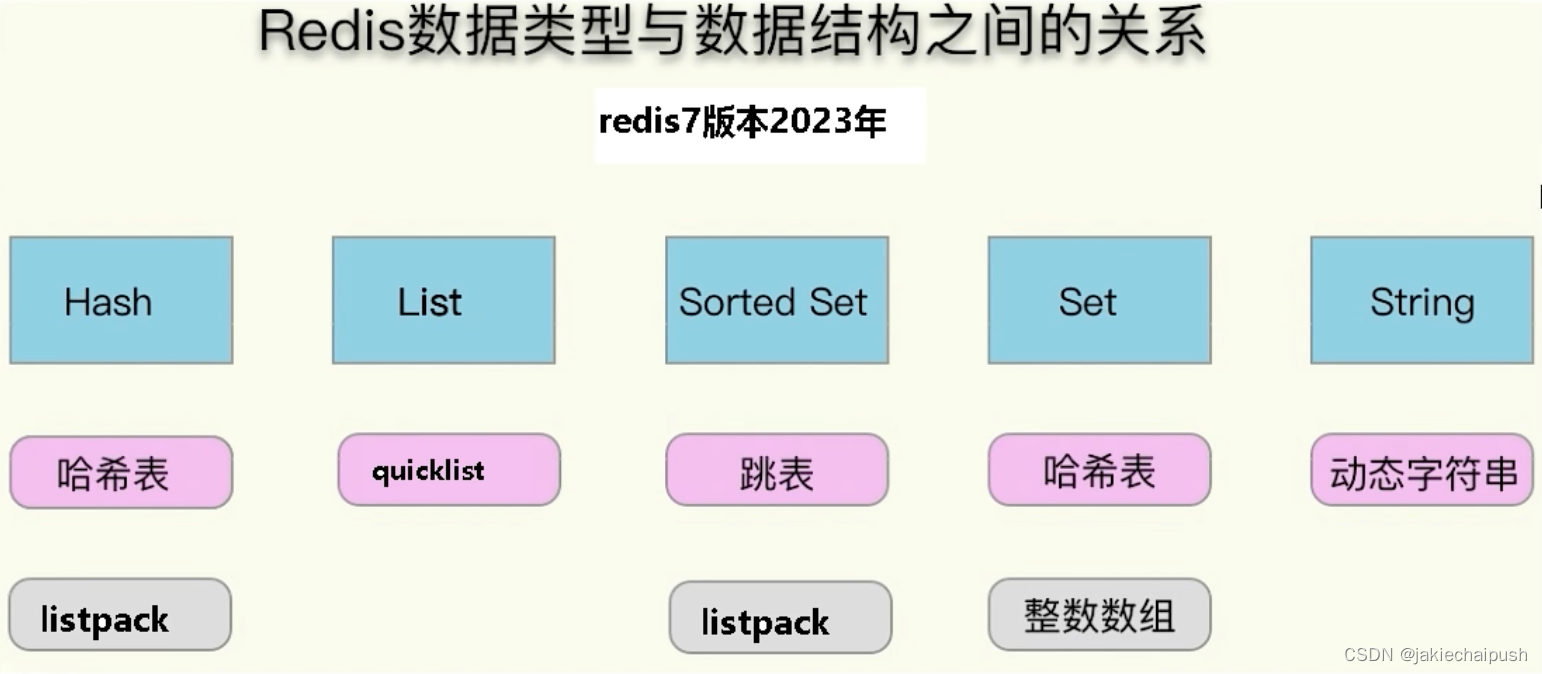
Redis 7和6之间的关系就是压缩列表不见了,然后引入了listpack这个数据结构(紧凑列表)。
redis 7新特性:


2. 插入KV底层源码流程分析
例如我们插入下面一对kv
set hello word

可以看到hello的类型是String
我们看一下key的底层编码
object encoding hello

为什么key是String类型,底层却在操作一个什么embstr类型?
set hello word,因为redis是kv键值对的数据库,每个键值对都会有一个dictEntry,里面指向了key和value的指针,next指向下一个dictEntry,key是字符串,但是redis没有直接使用C的字符数组来表示字符串,而是存储在redis自定义SDS中。value既不是直接作为字符串存储,也不是存储在SDS中,而是存储在redisObject中,实际上常用五种数据类型的任意一种,都是通过redisObject来存储的。
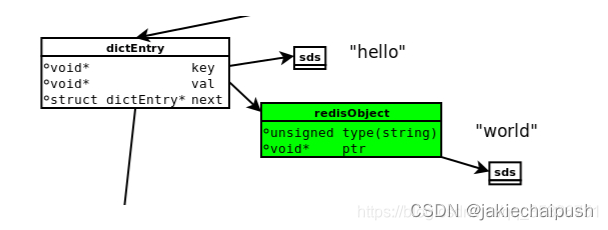
struct redisObject {
//对象的类型
unsigned type:4;
//具体的数据结构
unsigned encoding:4;
//最近最少使用,用于内存淘汰
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
* //
//引用计数,用于c的垃圾回收
int refcount;
//真正指向value的实际数据结构
void *ptr;
};
为了便于操作,redis采用了redisObject结构来统一五种不同的数据类型,这样所有的数据类型都可以以相同的形式在函数之间传递,而不使用特定的类型结构。同时,为了识别不同的数据类型,redisObject定义了type和encoding字段对不同的数据类型加以区别。简单来说,redisObject就是String、hash、list、set、zset的父类(但是c中没有类的说法,因为它是面向结构的编程语言),可以在函数间隐藏具体的类型信息,所以作者抽象redisObject结构来达到目的。

type:表示value具体的数据类型
encoding:表示该类型的物理编码,同一种数据结构就有多种不同的编码,如上面的embstr就是字符串的一种编码方式(String的编码方式有3种:int、emstr和raw)
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */
lru:表示当内存超限时采用lru算法清除内存中的对象
refcount:表示对象的引用计数(有点类似JVM中垃圾收集的引用计数法)
ptr:指向value真正底层的数据结构
- 各个类型的数据结构和编码映射的定义
// object.c文件中
char *strEncoding(int encoding) {
switch(encoding) {
case OBJ_ENCODING_RAW: return "raw";
case OBJ_ENCODING_INT: return "int";
case OBJ_ENCODING_HT: return "hashtable";
case OBJ_ENCODING_QUICKLIST: return "quicklist";
case OBJ_ENCODING_LISTPACK: return "listpack";
case OBJ_ENCODING_INTSET: return "intset";
case OBJ_ENCODING_SKIPLIST: return "skiplist";
case OBJ_ENCODING_EMBSTR: return "embstr";
case OBJ_ENCODING_STREAM: return "stream";
default: return "unknown";
}
}
我们再看一个set hello word,然后我们使用Debug Object key,这是redis的一个调试命令,它不应该被客户端使用。我们直接使用回报错

我们需要修改配置开启本地调试,可以使用修改redis的配置文件来设置这个选项:


- value at:内存地址
- refcount:引用次数
- encoding:物理编码
- serializedlength:序列化后的长度(注意这里的长度是序列化后的长度,保存为rdb文件时使用了该算法,不是真正存储在内存中的大小),会对字符串做一些可能的压缩以便底层优化
- lru:记录最近使用的时间戳
- lru_seconds_idle:空闲时间