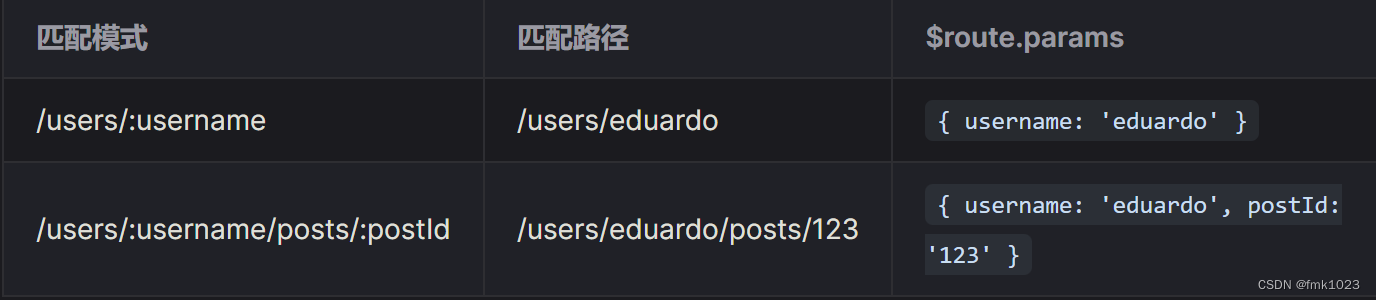
注意:本文引用自专业人工智能社区Venus AI
更多AI知识请参考原站 ([www.aideeplearning.cn])
什么是语音情感识别?
语音情感识别,缩写为 SER,是试图从语音中识别人类情感和情感状态的行为。这是利用了这样一个事实:声音通常通过音调和音调反映潜在的情感。这也是狗和马等动物用来理解人类情感的现象。
SER 很困难,因为情感是主观的,并且注释音频具有挑战性。
什么是librosa?
librosa 是一个用于分析音频和音乐的Python 库。它具有更扁平的封装布局、标准化的接口和名称、向后兼容性、模块化功能和可读的代码。此外,在这个 Python 迷你项目中,我们演示了如何使用 pip 安装它(以及其他一些包)。
语音情感识别——目标
使用 librosa 和 sklearn 库以及 RAVDESS 数据集构建一个模型来识别语音情感。
语音情感识别 – 关于 Python Mini 项目
在此 Python 迷你项目中,我们将使用 librosa、soundfile 和 sklearn(以及其他库)库来使用 MLPClassifier 构建模型。这将能够从声音文件中识别情感。我们将加载数据,从中提取特征,然后将数据集分为训练集和测试集。然后,我们将初始化 MLPClassifier 并训练模型。最后,我们将计算模型的准确性。
数据集
对于这个 Python 迷你项目,我们将使用 RAVDESS 数据集;这是瑞尔森情感言语和歌曲视听数据库数据集,可免费下载。该数据集包含 7356 个文件,由 247 个人对情感有效性、强度和真实性进行了 10 次评级。整个数据集有 24.8GB,来自 24 个参与者,但我们降低了所有文件的采样率,您可以在此处下载。
先决条件
您需要使用 pip 安装以下库:
pip install librosa soundfile numpy scikit-learn pyaudio如果您在使用 pip 安装 librosa 时遇到问题,可以尝试使用 conda。
语音情感识别Python项目的步骤
1. 进行必要的导入:
import librosa
import soundfile
import os, glob, pickle
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score2. 定义函数 extract_feature 从声音文件中提取 mfcc、chroma 和 mel 特征。该函数有 4 个参数 – 文件名和三个布尔参数(用于三个功能):
- mfcc:梅尔频率倒谱系数,表示声音的短期功率谱
- 色度:涉及 12 个不同的音级
- mel:梅尔频谱图频率
使用 with-as 打开 soundfile.SoundFile 声音文件,这样一旦我们完成,它就会自动关闭。从中读取并将其命名为 X。另外,获取采样率。如果色度为 True,则获取 X 的短时傅立叶变换。
令 result 为空 numpy 数组。现在,对于这三个功能中的每个功能,如果存在,请从 librosa.feature 调用相应的函数(例如 mfcc 的 librosa.feature.mfcc),并获取平均值。使用结果和特征值从 numpy 调用函数 hstack(),并将其存储在结果中。hstack() 按顺序水平堆叠数组(以柱状方式)。然后,返回结果。
# Extract features (mfcc, chroma, mel) from a sound file
def extract_feature(file_name, mfcc, chroma, mel):
with soundfile.SoundFile(file_name) as sound_file:
X = sound_file.read(dtype="float32")
sample_rate=sound_file.samplerate
if chroma:
stft=np.abs(librosa.stft(X))
result=np.array([])
if mfcc:
mfccs=np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result=np.hstack((result, mfccs))
if chroma:
chroma=np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0)
result=np.hstack((result, chroma))
if mel:
mel = np.mean(librosa.feature.melspectrogram(y=X, sr=sample_rate).T, axis=0)
result=np.hstack((result, mel))
return result3. 现在,让我们定义一个字典来保存 RAVDESS 数据集中可用的数字和情绪,以及一个列表来保存我们想要的情绪 – 平静、快乐、恐惧、厌恶。
# Emotions in the RAVDESS dataset
emotions={
'01':'neutral',
'02':'calm',
'03':'happy',
'04':'sad',
'05':'angry',
'06':'fearful',
'07':'disgust',
'08':'surprised'
}
#DataFlair - Emotions to observe
observed_emotions=['calm', 'happy', 'fearful', 'disgust']4. 现在,让我们使用函数 load_data() 加载数据 – 该函数将测试集的相对大小作为参数。x 和 y 是空列表;我们将使用 glob 模块中的 glob() 函数来获取数据集中声音文件的所有路径名。我们使用的模式是:“speech-emotion-recognition-ravdess-data/Actor_*/*.wav”。这是因为我们的数据集如下所示:
![图片[1]-语音情感识别python项目-VenusAI](https://img-blog.csdnimg.cn/img_convert/06a6bb3031c5cde0f38ea4e333e7e3a0.png)
使用我们的情绪字典,这个数字被转换成一种情绪,我们的函数检查这种情绪是否在我们的observed_emotions列表中;如果没有,则继续处理下一个文件。它调用 extract_feature 并将返回的内容存储在“feature”中。然后,它将特征附加到 x 并将情感附加到 y。因此,列表 x 包含特征,y 包含情感。我们使用这些、测试大小和随机状态值调用函数 train_test_split,然后返回该值。
5. 将数据集分成训练集和测试集,让我们将测试集保留为所有内容的 25%,并为此使用 load_data 函数。
# Split the dataset
x_train,x_test,y_train,y_test=load_data(test_size=0.25)6. 现在,让我们初始化一个 MLPClassifier。这是一个多层感知器分类器;它使用 LBFGS 或随机梯度下降来优化对数损失函数。与 SVM 或朴素贝叶斯不同,MLPClassifier 有一个用于分类目的的内部神经网络。这是一个前馈 ANN 模型。
# Initialize the Multi Layer Perceptron Classifier
model=MLPClassifier(alpha=0.01, batch_size=256, epsilon=1e-08, hidden_layer_sizes=(300,), learning_rate='adaptive', max_iter=500)7. 拟合/训练模型。
# Train the model
model.fit(x_train,y_train)8. 预测测试集的值。这给了我们 y_pred(测试集中特征的预测情绪)。
# Predict for the test set
y_pred=model.predict(x_test)9. 为了计算模型的准确性,我们将调用从sklearn导入的 precision_score() 函数。最后,我们将精度四舍五入到小数点后两位并打印出来。
# Calculate the accuracy of our model
accuracy=accuracy_score(y_true=y_test, y_pred=y_pred)
# Print the accuracy
print("Accuracy: {:.2f}%".format(accuracy*100))概括
在这个 Python 迷你项目中,我们学会了从语音中识别情绪。我们为此使用了 MLPClassifier,并使用 soundfile 库来读取声音文件,并使用 librosa 库从中提取特征。正如您将看到的,该模型的准确率为 61.98%。这对我们来说已经足够好了。
![图片[2]-语音情感识别python项目-VenusAI](https://img-blog.csdnimg.cn/img_convert/a3af046ea27c578b42b6568e33e70799.png)
项目全部资料
详情请见网站语音情感识别python项目-VenusAI (aideeplearning.cn)