Java语言特点
简单易学、面向对象(继承、封装、多态)、平台无关性(Java虚拟机jvm)、支持多线程、可靠、安全、高效、支持网络编程、编译与解释共存
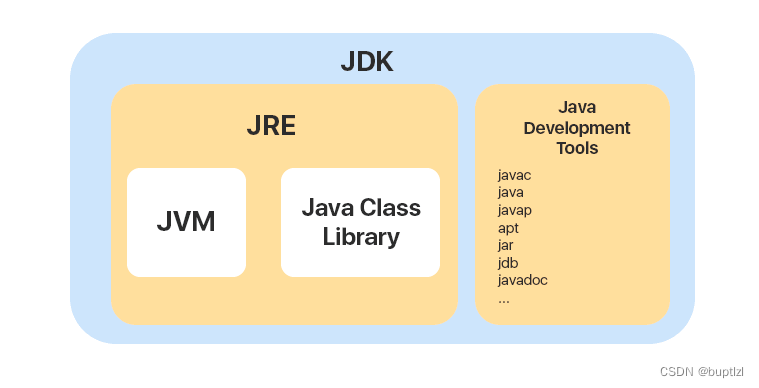
JVM:Java虚拟机(跨平台的关键)
JRE(Java运行虚拟环境):JVM+Java类库
JDK(JAVA SDK):JRE+JAVAC(JAVA编译器)+其他
字节码文件:.class文件
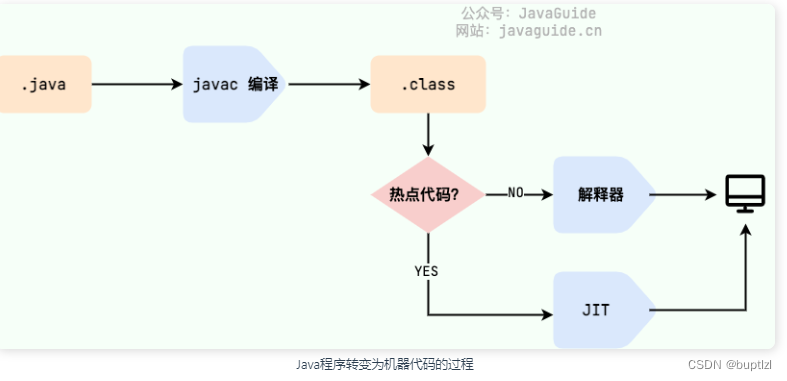
编译型语言:通过编译器将源代码一次性编译成机器码
解释型语言:通过解释器一句一句将代码解释
Java 语言既具有编译型语言的特征,也具有解释型语言的特征。因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(.class 文件),这种字节码必须由 Java 解释器来解释执行
java注释:单行、多行、文档注释
标识符、关键字:标识符就是一个名字,包括程序、类、变量、方法等。关键字是为赋予特殊含义的标识符,关键字都是小写。
自增自减运算符:符号在前就先加减,符号在后就后加减
移位运算符:在 Java 代码里使用 <<、 >> 和>>>转换成的指令码运行起来会更高效些

移位操作符实际上支持的类型只有int和long,编译器在对short、byte、char类型进行移位前,都会将其转换为int类型再操作。同时float和double类型不支持移位运算。
<< :左移运算符,向左移若干位,高位丢弃,低位补零。x << 1,相当于 x 乘以 2(不溢出的情况下)。 >> :带符号右移,向右移若干位,高位补符号位,低位丢弃。正数高位补 0,负数高位补 1。x >> 1,相当于 x 除以 2。>>> :无符号右移,忽略符号位,空位都以 0 补齐
return:return;直接用来结束方法的执行,用于没有返回值的函数
Java数据类型:8种,
6 种数字类型:4 种整数型:byte、short、int、long 2 种浮点型:float、double
1 种字符类型:char
1 种布尔型:boolean。
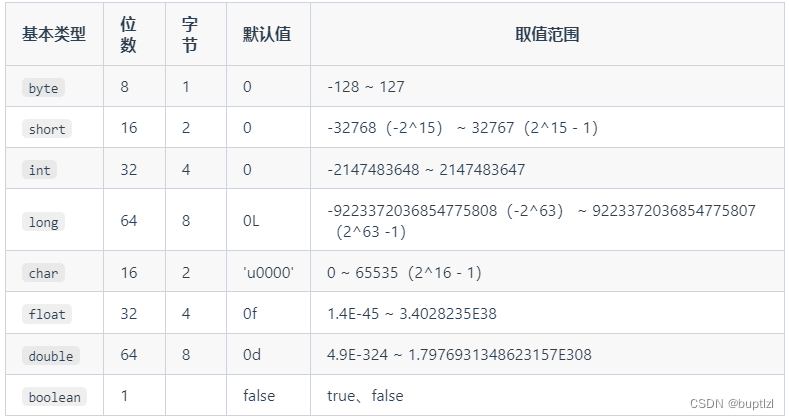
Java 里使用 long 类型的数据一定要在数值后面加上 L,否则将作为整型解析。
char a = 'h’char :单引号,String a = “hello” :双引号。
所有整型包装类对象之间值的比较,全部使用 equals 方法比较
自动装箱、拆箱
装箱:将基本类型用他们对应的引用类型包装起来 用Interger.valueOf()
拆箱:将包装类型转换为基本类型 用intValue()
频繁装箱拆箱会严重影响系统性能
为什么浮点数运算会有精度丢失的风险?
因为用二进制保存数据,宽度是有限的,无限循环小数只能被截断。可以采用BigDecimal来对浮点数进行运算。
超过long类型的数据可以采用BigInteger来存储,其内部采用int[]来存储任意大小的整形数据,但其运算效率相对较低
变量:
成员变量与局部变量的区别?
成员变量是属于类的,局部变量是方法内的,成员变量可以被public、private、static进行修饰,可以被外部访问,但成员变量不可以。二者都可以用final进行修饰
成员变量如果被static修饰,其是属于类的,如果没有被static修饰,那么这个变量就是属于实例的。对象存在在堆内存中,局部变量存在于栈内存中。
成员变量随着对象创建而创建,局部变量随着方法调用创建,方法结束后消失
成员变量如果没有赋初始值,则会自动以类型的默认值而赋值,而成员变量不会自动赋值。
为什么成员变量有默认值?
对于编译器(javac)来说,局部变量没赋值很好判断,可以直接报错。而成员变量可能是运行时赋值,无法判断,误报“没默认值”又会影响用户体验,所以采用自动赋默认值。
静态变量有什么作用?
静态变量是被static修饰的变量,他可以被类的所有实例共享。静态变量只会被分配依次内存,即使创建多个对象,这样可以节省内存
静态方法为什么不能调用非静态成员?
静态方法是属于类的,可以通过类名直接访问,非静态成员属于实例对象,只有在对象实例化之后才存在,需要通过类的实例对象才能访问
静态方法和实例方法有何不同?
静态方法可以直接通过类调用,实例方法必须先创建对象,通过对象调用
面向对象基础
面向对象和面向过程:
面向过程是把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题
面向对象会先抽象出对象,然后用对象执行方法的方式解决问题
对象相等和引用相等的区别?
对象相等一般比较的是内存中存放的内容是否相等
引用相等一般比较的是他们指向的内存地址是否相等
如果是基本数据类型用==,比较的是数值是否相等
如果是引用数据类型,比较的是内存地址是否一样
引用数据类型如果要比较数值,可以用.equals()方法
面向对象三大特征
封装(private,把对象的一部分属性隐藏在内部,不允许外部对象直接访问)
继承(extend,)子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。子类可以拥有自己属性和方法,即子类可以对父类进行扩展。子类可以用自己的方式实现父类的方法。注意,Java只能单继承,就是说子类只能继承一个父类,但是父类可以有多个子类。 但是接口可以多继承
多态:一个对象具有多种状态,具体表现为父类的引用指向子类的实例。
深拷贝和浅拷贝的区别?
浅拷贝:拷贝对象和原对象共用同一个内部对象
深拷贝:完全复制整个对象,包括内部对象
引用拷贝:两个不同的引用指向同一个对象
== 对于基本类型和引用类型的作用效果是不同的:
对于基本数据类型来说,== 比较的是值。
对于引用数据类型来说,== 比较的是对象的内存地址
equals() 不能用于判断基本数据类型的变量,只能用来判断两个对象是否相等
String 中的 equals 方法是被重写过的,因为 Object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
hashCode() 和 equals()都是用于比较两个对象是否相等
注意:hashcode值相等不一定代表两个对象相等,因为可能会发生哈希碰撞。
只有hashcode相等并且equals方法返回true,认为两个对象一样。
equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
两个对象有相同的 hashCode 值,他们也不一定是相等的(哈希碰撞)
string是不可变的(String 类中使用 final 关键字修饰字符数组来保存字符串,所以不可改变),其是线程安全的,stringbuffer也是线程安全的,但stringbuilder不是线程安全的,但其性能有提升。
操作少量的数据: 适用 String
单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder
多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer
字符串对象通过“+”的字符串拼接方式,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象 。循环内使用“+”进行字符串的拼接的话,存在比较明显的缺陷:编译器不会创建单个 StringBuilder 以复用,会导致创建过多的 StringBuilder 对象。如果直接使用 StringBuilder 对象进行字符串拼接的话,就不会存在这个问题了
String 中的 equals 方法是被重写过的,比较的是 String 字符串的值是否相等。 Object 的 equals 方法是比较的对象的内存地址。
字符串常量池作用?
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
异常:在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类:
exception:程序本身可以处理的异常,可以通过catch来进行捕获
error:程序无法处理的错误,不能通过catch捕获,一般这些异常发生的时候,jvm会选择线程终止。
try-catch-finally 如何使用?
try块:用于捕获异常。其后可接零个或多个 catch 块,如果没有 catch 块,则必须跟一个 finally 块。
catch块:用于处理 try 捕获到的异常。
finally 块:无论是否捕获或处理异常,finally 块里的语句都会被执行。当在 try 块或 catch 块中遇到 return 语句时,finally 语句块将在方法返回之前被执行。
不要在 finally 语句块中使用 return!
如果finally之前虚拟机被终止的话,finally中的代码就不会执行。
动态代理的实现也依赖反射,注解的实现也用到了反射
java中只有值传递:方法接收的实参值的拷贝,会创建副本
引用传递:方法接收的值是实参所引用对象在堆中的地址,不会创建副本,对形参的修改会影响到实参。
java序列化与反序列化:
序列化:将数据结构或对象转换成二进制字节流的过程
反序列化:将在序列化过程中生成的二进制字节流转换成数据结构或者对象的过程
应用场景:
对象在进行网络传输之前先序列化,接收到序列化的对象之后需要反序列化。
对象存储到文件之前需要序列化,将对象读取出来的时候需要反序列化
将对象存储到数据库之前需要序列化,将对象从缓存数据库中读出来需要反序列化
将对象存储到内存之前需要序列化,从内存中读取出来之后需要进行反序列化。
序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
序列化协议对应:应用层、传输层、网络层、网络接口层
serialVersionUID:版本控制的作用,反序列化的时候会检查是否和当前类一致,不一致会抛出异常。
如果字段不想被序列化,可以用transient进行修饰。
kryo是一个高性能的序列化/反序列化工具(不推荐使用JDK自带的序列化方式,其不支持跨语言调用,性能差且存在安全问题)
反射:本质是JVM得到class对象之后,再通过class对象进行反编译,从而获取对象的各种信息。









![[AIGC] Kafka解析:分区、消费者组与消费者的关系](https://img-blog.csdnimg.cn/direct/9579ec75d04e4690ae63b42a8f70842a.png)