源自:电子与信息学报
作者:周晓天, 孙上, 张海霞, 邓伊琴, 鲁彬彬
“人工智能技术与咨询” 发布
摘 要
AI质检是智能制造的重要环节,其设备在进行产品质量检测时会产生大量计算密集型和时延敏感型任务。由于设备计算能力不足,执行检测任务时延较大,极大影响生产效率。多接入边缘计算(MEC)通过将任务卸载至边缘服务器为设备提供就近算力,提升任务执行效率。然而,系统中存在信道变化和任 务随机到达等动态因素,极大影响卸载效率,给任务调度带来了挑战。该文面向多接入边缘计算赋能的AI质检任务调度系统,研究了联合任务调度与资源分配的长期时延最小化问题。由于该问题状态空间大、动作空间包含连续变量,该文提出运用深度确定性策略梯度(DDPG)进行实时任务调度算法设计。所设计算法可基于系统实时状态信息给出最优决策。仿真结果表明,与基准算法相比,该文所提算法具有更好的性能表现和更小的任务执行时延。
关键词
多接入边缘计算 / 任务调度 / 资源分配 / 深度强化学习 /AI质检系统
1. 引言
AI质检[1,2]作为智能工业生产中的重要一环,可以有效保障产品生产质量,降本增效。AI 质检过程中所产生如产品商标识别、不合格产品零件检测等智能任务,需要大量计算资源,具有计算密集特征。另外,工业生产流水线对质检的时延要求较高,若任务完成时延过大,会导致生产中断,造成经济损失。因此AI质检任务也是时延敏感型任务。然而,质检终端设备通常计算能力有限,难以在短时间内完成对这些兼具时延敏感和计算密集特性任务的处理。针对这一问题,有研究提出运用云计算赋能的工业物联网技术[3,4] 将任务卸载到远程云中心[5],利用云服务器强算力资源实现任务快速处理。然而,云服务器与设备间物理距离远,任务卸载会引入较长通信时延。此外,大量任务集中式地卸载到同一云服务器进行处理,也为骨干网传输带来压力,易导致网络拥塞。因此,基于云架构的工业物联网中易出现由于通信时延过高所导致的任务端到端整体服务时延非减反增情况,难以满足AI质检的低时延需求。
在此背景下,多接入边缘计算[6,7] (Multi-access Edge Computing, MEC) 作为云计算的演进思路被业界所提出。边缘计算通过分布式地将小型服务器部署在网络边缘以为设备提供就近算力服务。与云架构相比,边缘服务器距离终端更近,任务卸载的通信时延得以减少。而去中心化的分布式部署,又可以避免海量终端集中卸载,缓解骨干网拥塞。因此,相较云计算架构,边缘计算架构可以更好地实现算力下沉,保障AI质检任务时延需求,提升生产效率。但在实际应用中,以无线传输为基础的工业物联网环境动态变化[8,9],任务卸载时延受时变信道衰落等影响严重。此外,边缘计算架构计算资源分布式部署,易导致计算资源与终端计算需求分布不匹配问题。因此,如何设计有效的任务调度与资源分配联合优化策略,以匹配网络环境动态变化,实现AI质检任务长期处理时延最小化,是关键研究点。
围绕这一问题,文献[10]针对具有云边端3层网络架构的系统,建模了以最小化平均应用响应时间为目标的联合计算卸载与带宽分配问题,通过转化为分段凸优化问题求解,获取了最优解。文献[11]针对时延敏感型任务,设计了联合任务分割和资源分配的策略,并提出一种多维度搜索调整(Multi-Dimensional Search and Adjust, MDSA)的离线算法以实现系统时延最小化。文献[12]针对MEC中多边缘服务器协作计算的场景,在存储容量与卸载成功率约束下,将任务队列建模为M/M/s模型,设计了最小化任务平均等待时延的优化问题,并通过1维优化搜索方法获取了资源分配决策方案。文献[13]面向超密集异构边缘计算网络,构建了时延约束下的计算卸载和资源分配联合优化问题,并设计了混合粒子群优化算法进行问题求解。文献[14]则面向多用户MEC网络,设计了最小化能耗的协作式任务卸载与资源管理策略,并采用自适应遗传算法获取了优化方案。
以上研究工作均解决了MEC赋能的工业物联网系统下的任务调度和资源分配问题,但使用了较强的静态环境假设,如任务卸载过程中信道状态不变、任务到达时间间隔固定等,并未将系统长期性能纳入考虑。然而在AI质检系统中,终端设备与人的移动会导致信道衰落变化[8,9],实际任务的产生到达时间也具有随机性。因此,已有工作无法完全契合需要长期持续工作且环境动态变化的AI质检场景。此外,上述研究大多采用传统凸优化或启发式优化算法,求解算法复杂度较高且只能获取准静态的瞬时优化解,并不适用于AI质检场景下随实时感知状态变化的序列决策问题求解。
考虑到信道条件动态变化、任务到达随机等实际情况,本文针对兼具计算密集和时延敏感特性的AI质检任务,以最小化系统长期任务处理时延为目标,研究任务调度与计算资源分配的联合优化问题。由于所建模问题为序列决策问题,本文将其转化为马尔可夫决策过程 (Markov Decision Process, MDP) 进行求解。该MDP问题状态转移概率未知,状态空间大。动作空间内既存在离散的任务卸载决策变量,又包含连续的资源分配决策变量,因此难以采用传统动态规划方法求解。为此,本文借助强化学习手段,提出了一种基于深度确定性策略梯度 (Deep Deterministic Policy Gradient, DDPG)的任务实时调度算法。该算法通过改进Actor网络输出层结构实现了混合动作空间的分离,可以实现对系统环境的实时感知和对任务的实时调度。与已有的研究相比,本文所提基于DDPG的实时任务调度方案可以更好地适应AI质检系统的动态性,实现计算资源的合理优化配置,有效减小系统任务处理时延。仿真实验结果表明,本文所提MEC赋能的AI质检系统中基于DDPG的实时任务调度算法具有快速收敛优势,性能明显优于其他基准方案。
2. 系统建模及问题建立
2.1 系统架构
如图1所示,本文所考虑的MEC赋能AI质检系统由1个MEC服务器和N个AI质检设备组成。边缘云层包含了服务器与集中控制中心,后者负责收集系统环境状态信息、生成任务调度和计算资源分配决策。AI质检设备产生的任务有两种执行模式,可以由设备在本地执行计算,也可以卸载到MEC服务器上进行处理,再将执行结果返回。在该系统中,假设MEC服务器的覆盖半径为L(m),AI质检设备都在其服务范围内,每个设备具有有限的计算资源,设备集合表示为N={1,2,⋯,N} 。假定整个系统以时隙的方式进行工作[15],工作时间持续T个时隙,每时隙长度为Ts。在每时隙开始时,集中控制中心收集系统状态信息,做出任务调度和计算资源分配决策,同时向AI质检设备与MEC服务器发送控制指令。系统将在该时隙剩余时间内执行该命令,完成任务卸载或本地计算。
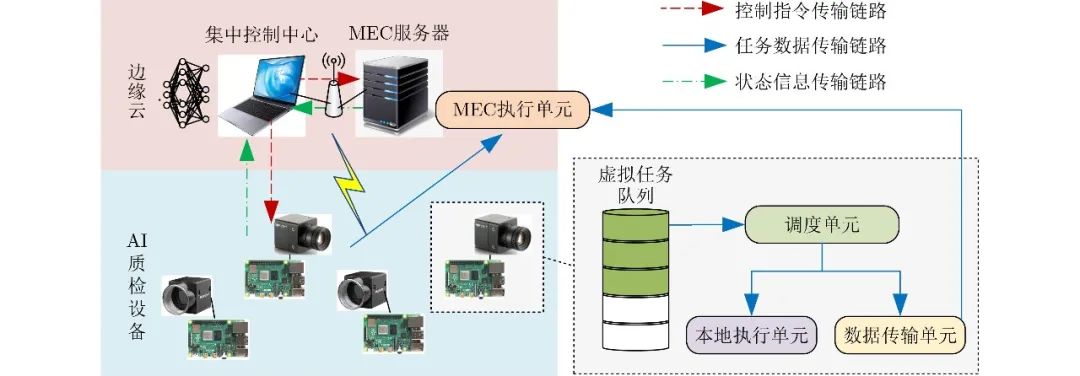
图 1 MEC赋能的AI质检系统任务调度结构图
为符合实际AI质检工作模式,假设AI质检设备产生的任务是串行任务流,任务随机到达,到达过程服从泊松分布。考虑到不同设备的工作负载差异,定义AI质检设备集合的平均任务到达率为λ=(λ1,⋯,λn,⋯,λN) ,其中λn 为第n个设备的平均任务到达率。第n个设备产生的任务集合表示为Mn={1,2,⋯,Mn} 为工作过程中生成的任务总数。假设系统中共有F种类型的任务,对应不同检测产品。定义任务集合为G={G1,⋯,Gj,⋯,GF} ,其中类型Gj 表示第j种类型任务,可进一步用2元组Gj=(dj,kj) 描述,其中dj 为任务输入数据量大小,kj 是处理单位数据所需CPU转数,单位为cycle/bit。考虑到不同类型任务的检测目标不同,因此其数据量与单位数据所需CPU转数也不同。另外,由于任务处理完成后输出数据量远小于输入数据量,因此假设在MEC服务器处理时,结果返回时间可以忽略不计[16]。
在任务调度过程中,所有未被处理的任务都存放在虚拟任务队列中等待执行,先产生的任务具有更高执行优先级。当某任务被执行时,它会被首先存放入本地调度单元中等待调度。此后,依照调度决策,该任务会被转移到本地执行单元处理,或通过数据传输单元卸载到MEC服务器。MEC服务器执行单元接收到原始数据后进行处理,最终将计算结果发回给AI质检设备。系统设备会根据任务执行结果进行后续不合格产品分流等处理。为方便描述,本文定义在t时隙,调度单元中的数据量为
![]()
,MEC执行单元中的数据量为
![]()
,数据传输单元中传输的数据量为
![]()
。
2.2 通信模型
假设MEC服务器与AI质检设备之间采用正交频分复用方式进行数据传输,每个设备使用不同的频带。根据文献[17],从设备n到MEC服务器的最大传输速率定义为
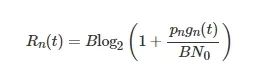
(1)
其中,pn 为设备n的发送功率,B为信道带宽,N0为高斯白噪声功率谱密度。gn(t) 为设备n在时隙t的无线信道增益,包含大尺度与小尺度衰落。大尺度衰落表示为
![]()
,其中d为设备到边缘服务器的距离,β1 和β2 分别是路损常数和路损指数,小尺度衰落服从瑞利分布[9,17]。
在t时隙,用x(t)=(x1(t),⋯,xn(t),⋯,xN(t))表示AI质检设备的卸载决策。对于设备n,xn(t)=0 表示任务在本地处理,xn(t)=1 表示任务卸载到MEC服务器处理。由此可得,在t 时隙设备n 卸载数据量为
![]()
(2)
2.3 计算模型
定义设备n的处理器处理频率为
![]()
,则在t 时隙,需在本地计算的数据量表示为
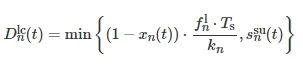
(3)
其中,kn 为设备n中当前被处理的任务1 bit数据量所需的CPU转数。
另外,定义MEC服务器在t时隙的计算资源分配比例为φ(t)=(φ1(t),⋯,φn(t),⋯,φN(t)) ,其中φn(t) 表示MEC服务器分配给设备n的计算资源比例。因此,设备n在t时隙通过MEC服务器计算的数据量为

(4)
其中, fc 为MEC服务器处理频率,kn 为处理设备n每 1 bit 任务数据量所需的CPU转数。
根据以上定义和公式,可以得出系统状态在相邻时隙的转移过程为
![]()
(5)

(6)
2.4 优化问题建立
本文拟通过联合优化任务卸载决策和计算资源分配来最小化系统的长期任务处理时延。由于本文以时隙为单位对任务进行调度,考虑到每个设备存储空间有限,一旦队列等待任务量超过队列容量,之后到达的任务会发生溢出。定义任务溢出指示变量为αn,m(t) ,当设备n的第m个任务溢出时,αn,m(t)=1 ,否则αn,m(t)=0 。显然,αn,m(t) 的取值受t时隙任务队列长度及决策变量xn(t) 和φn(t) 影响。由于决策的不确定性以及任务到达的随机性,本文假设αn,m(t) 的取值可通过监测设备队列状态获取。具体的,若检测到t时隙设备n的任务队列长度大于容量,则αn,m(t) 取值1,否则为0。定义dn,m(t) 为设备n的第m个任务在t时隙的时延,如果该任务在虚拟队列中等待或正在执行计算,则有dn,m(t)=Ts ,否则dn,m(t)=0 。此外,为保证系统可靠性、避免任务溢出,本文对溢出任务增加了时间惩罚参数ξ 。由此,优化问题可表述为

(7)
问题式(7)中,C1保证每设备在当前时隙只能选择一种计算模式。C2给定了每设备可获取服务器计算资源的比例约束,C3表明MEC服务器分配给所有设备的计算资源不能超过MEC服务器的计算资源总量。
3. 算法设计
上述优化问题为包含随机环境变量的混合整数非线性规划序列决策问题。该问题状态空间大,动作空间包含连续和离散变量,难以用传统优化方法求解。为此,本文将问题建模为MDP,借助深度强化学习 (Deep Reinforcement Learning, DRL) 工具,提出一种基于DDPG的AI质检任务实时调度算法。
3.1 MDP问题建立
定义MDP的5个关键因子为M=(S,A,P,r,γ) [18],其中S为状态空间,A为动作空间,P表示状态转移概率,r为奖励函数,γ∈[0,1] 为折扣因子。
(1) 状态空间:在每时隙起始,集中控制中心作为智能体收集系统状态信息。状态空间可描述为
![]()
(8)
其中,
![]()
为MEC执行单元中数据量,
![]()
表示设备调度单元中的数据量,
![]()
表示AI质检设备的任务队列长度,
![]()
是各设备到服务器间的信道增益。系统状态空间的维数为4N。
(2) 动作空间:在收集到状态信息后,智能体将做出决策并向MEC服务器和AI质检设备发送控制动作信号。对应的动作空间描述为
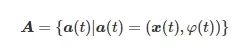
(9)
其中,x(t)=(x1(t),⋯,xn(t),⋯,xN(t))为设备卸载决策,φ(t)=(φ1(t),⋯,φn(t),⋯,φN(t)) 表示MEC服务器计算资源分配决策。系统动作空间的维数为2N。
(3) 状态转移概率:本文研究的状态转移过程由式(5)和式(6)决定,其概率定义为P(s(t+1)|s(t),a(t)) ,表示在选择动作a(t)时,系统从状态 s(t) 转移到状态 s(t + 1)的概率。需指出的是,由于系统环境的动态随机性,状态转移概率一般难以直接获得。因此本文通过强化学习的方法进行问题求解。
(4) 奖励函数:奖励函数 r(t) 表示在状态 s(t) 选择动作 a(t) 时所获得的瞬时奖励。考虑到本文优化目标是最小化系统长期任务执行时延,因此采用每时隙系统优化目标值的相反数作为奖励函数,表示为
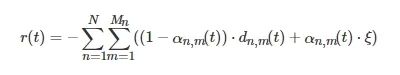
(10)
3.2 基于DDPG的AI质检任务实时调度算法设计
上述MDP问题的动作空间中包含离散的卸载决策和连续的计算资源分配决策,无法采用传统基于值的DRL方法求解。因此,本文拟采用可求解连续动作空间问题的DDPG作为算法核心,提出了一种基于DDPG的任务实时调度算法。如图2所示,该算法采用了由Actor网络和Critic网络组成的双网络模型,并通过改进Actor网络的输出层结构实现混合动作空间的分离。具体地,Actor网络的输出层采用两种方式处理连续资源分配动作和离散卸载动作,输出资源分配决策的神经元使用Softmax激活函数,实现了资源分配决策归一化,并保证其满足式 (7) 中的约束C3;输出卸载动作的神经元使用Sigmoid激活函数,将输出值限定在[0,1]内,用于表示任务卸载的概率,并以0.5为界限进行0或1离散化动作选择。

图 2 算法结构图
定义策略π 为状态到动作的映射,即a(t)=π(s(t)) ,定义Q值函数为Q(s(t),a(t)) ,表示在状态s(t)下采取行动a(t)的期望累积回报。根据贝尔曼方程[19],Q(s(t),a(t)) 表示为
![]()
(11)
在图2所示算法中,Actor网络按照策略π(s(t)|θμ(t)) 输出一个确定性动作a(t) ,即a(t)=π(s(t)|θμ(t)) ,Critic网络通过输出一个估计的Q值Q(s(t),a(t)|θQ(t)) 来评估这个动作,其中θμ(t) 和θQ(t) 分别表示t时隙Actor网络和Critic网络的网络参数。Critic网络的训练目标为,使其输出的估计Q值Q(s(t),a(t)|θQ(t)) 逼近Q值函数的实际值Q(s(t),a(t)) [17],即

(12)
算法中还使用目标网络来辅助训练,以使学习过程更稳定,收敛更快。定义目标Actor网络的输出为
![]()
,目标Critic网络的输出为
![]()
,其中
![]()
分别为t时隙目标网络Actor和Critic的网络参数。为使Critic网络的输出值逼近实际Q值,定义损失函数为二者均方误差[20],并采用随机梯度下降法进行网络参数θQ(t) 的更新,损失函数表示为

(13)
其中,
![]()
为计算所得实际Q值。
Actor网络的训练目标为寻找使Critic输出Q值
![]()
最大化的策略π(s(t)|θμ(t)) ,所提算法通过调整Actor网络梯度参数θμ(t) 来达到此目标[21],求得的Actor网络的梯度为
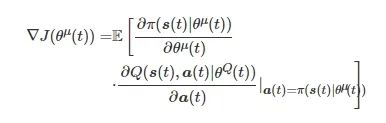
(14)
此外,本文使用了经验池来存储历史数据元组(s(t),a(t),r(t),s(t+1)) ,训练时将随机抽取小批量数据进行模型训练,以此消除数据相关性。为充分探索环境信息,得到更好的策略,本文在确定性动作中添加了奥恩斯坦-乌伦贝克(Ornstein-Uhlenbeck, OU)[22] 噪声,并设定其随着训练时间增加逐渐减小。为提高学习稳定性,进一步采用软替换策略来进行目标网络参数更新,每个训练周期内的目标网络参数更新过程为
![]()
(15)
其中,θ′(t) 为t时隙目标网络参数,θ(t) 为t时隙估计网络参数,ε 为策略参数。
算法的执行流程如算法1所示。首先对网络参数及其他系统参数进行初始化。在模型训练期间,通过网络与AI质检系统环境的交互收集数据元组(s(t),a(t),r(t),s(t+1)) 并将其存储到经验池中,具体地,获取环境状态s(t) ,输入至Actor网络中,将Actor网络的输出叠加噪声获得动作a(t) ,实施该动作后,系统输出奖励 r(t) 并转移至下一时刻状态s(t+1) 。在每时隙训练中,从经验池中抽取一个小批量数据样本,根据式 (13) 和式 (14) 更新估计网络Actor和Critic的网络参数,按式 (15) 更新目标网络参数。此外经验池中数据也会随着训练过程进行更新。最终,对网络进行K回合训练,直至收敛得到最终模型。训练完成后的Actor网络将部署至集中控制中心内。在系统运行时,每时隙集中控制中心进行实时环境状态检测,由Actor网络模型推理获得任务调度与资源分配决策,向设备与MEC服务器发送控制指令,完成任务调度。
算法1 基于DDPG的AI质检任务实时调度算法

4. 性能仿真与结果分析
4.1 仿真设置
为验证所提算法的性能,本文通过Python建模了MEC赋能的AI质检系统仿真环境,使用TensorFlow进行了算法实验验证。仿真参数见表1。
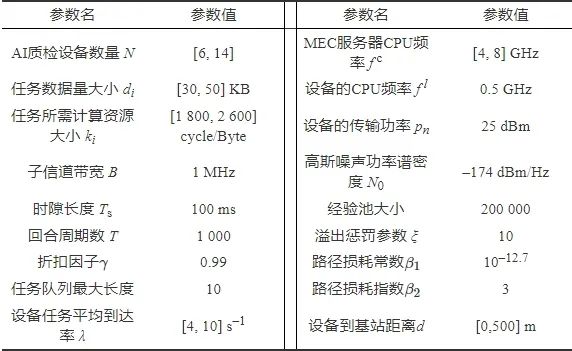
表 1 仿真参数设置
在所提算法中,Actor网络和Critic网络均采用4层全连接结构,包含1个输入层、3个隐藏层和1个输出层,算法参数设置见表2。

表 2 算法参数设置
4.2 收敛性分析
本文设置了3种学习率用于模型训练对比,均进行了3 500轮次训练,以系统累积奖励值作为衡量指标,结果如图3所示。由图3可知,当学习率设置为8×10–5时,算法在2 000轮次左右收敛,且收敛值最优。当学习率设置为1.6×10–4与3×10–5时,算法分别在1 500与2 000训练轮次左右收敛。学习率设置较大时算法收敛速度加快且波动较大,容易跳出全局最优解,学习率设置较小时算法收敛速度慢且容易陷入局部最优。依据上述结果,本文最终选择学习率为8×10–5进行后续实验。

图 3 不同学习率下的累积奖励
4.3 性能比较与分析
为验证所提算法性能,本文将提出的算法与3种基准方案进行比较,分别对比了这些算法在不同的设备数量、MEC服务器计算资源和任务所需计算资源大小下,系统的长期任务执行时延和平均任务时延。为了保证数据的可靠性,取200次实验的平均值作为最终的实验结果。所选取的3种基准方案如下:
(1) 随机卸载-平均分配(Random Offloading-Average Allocation, RO-AA)方案:设备任务随机卸载到MEC服务器上,MEC服务器的计算资源平均分配给每个设备;
(2) 全卸载-平均分配(All Offloading-Average Allocation, AO-AA)方案:所有设备任务卸载到MEC服务器上,MEC服务器的计算资源平均分配给每个设备;
(3) 非实时-深度确定性策略梯度(Non-Real Time-Deep Deterministic Policy Gradient, NRT-DDPG)方案:基于DDPG的非实时环境感知的任务调度和资源分配方案。所有设备只在任务生成时获得固定的调度方案,在任务执行过程中不再进行实时任务调度和资源分配[17]。
图4给出了在不同设备数量、不同MEC服务器计算资源量、不同任务计算需求情况下,4种方案的长期任务执行时延。可以发现在所有情况下,AO-AA方案耗时最长,RO-AA方案其次,再次为NRT-DDPG方案,本文所提算法时延最小。AO-AA方案将任务全部卸载到服务器,导致设备本地计算资源未被利用,因此具有最大时延。NRT-DDPG方案虽然通过联合任务调度和资源分配实现了性能提升,但仅在任务生成时进行优化,未能针对信道等环境状态变化而实时调整,因而性能依然差于本文提出的实时调度方案。具体的,从图4(a)可以看出,系统长期任务执行时延随用户数量的增加而增加。在设备数量为10时,相较其他3种方案,所提方案的时延分别减小了29%, 50%和11%。从图4(b)可发现,系统长期任务执行时延随MEC服务器计算资源的增加而减少。在服务器计算资源为6 GHz时,相比于其他3种方案,所提方案的时延分别减小了30%, 55%和12%。图4(c)揭示了系统长期任务执行时延随任务所需计算资源的增加而增大。在任务所需计算资源为2000 cycle/byte时,所提方案相较其他3种方案时延分别减小了29%, 50%和11%。

图 4 系统长期任务执行时延方案对比
图5给出了系统在不同设备数量、不同MEC服务器计算资源、不同任务计算需求的情况下,4种方案的平均任务执行时延。从图5可以看出本文所提算法在所有情况下均具有最小的平均任务执行时延。在设备数量为10时,相比于其他3种方案,所提方案的平均任务时延分别减小了20%, 45%和5%。在服务器计算资源为6 GHz时,所提方案相较其他方案,平均任务时延分别减小了30%, 53%和6%。在任务所需计算资源为2 000 cycle/byte时,所提方案相较其他方案,平均任务时延分别减小了41%, 63%和26%。

图 5 系统平均任务执行时延方案对比
5. 结束语
本文研究了MEC赋能的AI质检系统的任务调度问题,以最小化系统长期任务执行时延为目标,设计了联合卸载与计算资源分配的任务调度方案。由于所提问题为序列决策问题,本文将其建模为MDP。考虑到系统的环境状态动态变化,状态空间大、动作空间中连续与离散的优化变量共存,本文提出一种基于DDPG的AI质检任务实时调度算法。本算法通过改进Actor网络输出层结构实现了混合动作空间分离。所提算法可以通过对AI质检环境的实时感知,实现对任务的实时调度和对计算资源的实时分配。仿真结果表明,本文所提算法具有良好收敛性,且与其他基准算法相比具有最小的系统任务处理时延。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询” 发布





![[AIGC] Kafka解析:分区、消费者组与消费者的关系](https://img-blog.csdnimg.cn/direct/9579ec75d04e4690ae63b42a8f70842a.png)