ELK (Elasticsearch、Logstash、Kibana)日志分析系统的好处是可以集中查看所有服务器日志,减轻了工作量,从安全性的角度来看,这种集中日志管理可以有效查询以及跟踪服务器被攻击的行为。
> Elasticsearch 是个开源分布式实时分析搜索引擎,建立在全文搜索引擎库Apache Lucene基 础上,同时隐藏了Apache Lucene的复杂性。Elasticsearch 将所有的功能打包成一个独立的服务,并提供了一个简单的RESTful API接口。它具有分布式、零配置、自动发现、索引自动分片、索引副本机制、RESTful 风格接口、多数据源,自动搜索负载等特点。
> Logstash 是一个完全开源的工具,主要用于日志收集,同时可以对数据处理,并输出给 Elasticsearch。
> Kibana 也是一个开源和免费的工具,Kibana可以为Logstash 和 ElasticSearch提供图形化的日志分析 Web 界面,可以汇总、分析和搜索重要数据日志。
进行日志处理分析,一般需要经过以下几个步骤。
(1) 将日志进行集中化管理。
(2) 将日志格式化(Logstash)并输出到 Elasticsearch。
(3) 对格式化后的数据进行索引和存储(Elasticsearch)。
(4) 前端数据的展示(Kibana)。
1. Elasticscarch介绍
Elasticsearch是一个基于Lucene 的搜索服务器。它稳定、可靠、快速,而且具有比较好的水平扩展能力,为分布式环境设计,在云计算中被广泛应用。Elasticsearch提供了一个分布式多用户能力的全文搜索引擎,基于RESTful Web接口。通过该接口,用户可以通过浏览器和 Elasticsearch 通信, Elasticsearch 是用 Java 开发的,并作为Apache许可条款下的开放源码发布,Wikipedia、 Stack、Overflow、GitHub等都基于Elasticsearch 来构建搜索引擎,具有实时搜索、稳定,可靠、快速,安装使用方便等特点,
Elasticsearch的基础核心概念。
> 接近实时(NRT): Elasticsearch 是一个搜索速度接近实时的搜索平台,响应速度非常快,从 索引一个文档直到这个文档能够被搜索到只有一个轻微的延迟(通常是1s)。
> 群集(cluster):群集就是由一个或多个节点组织在一起,在所有的节点上存放用户数据并一起提供索引和搜索功能。通过选举产生主节点,并提供跨节点的联合索引和搜索的功能。每个群集都有一个唯一标示的名称,默认是Elasticsearch,每个节点是基于群集名字加 入到其群集中的。一个群集可以只有一个节点,为了具备更好的容错性,通常配置多个节 点,在配置群集时,建议配置成群集模式。
> 节点(node):是指一台单一的服务器,多个节点组织为一个群集,每个节点都存储数据并 参与群集的索引和搜索功能。和群集一样,节点也是通过名字来标识的,默认情况下,在节点启动时会随机分配字符名。也可以自定义。通过指定群集名字,节点可以加入到群集 中。默认情况,每个节点都已经加入 Elasticsearch群集。如果群集中有多个节点,它们将会 自动组建一个名为Elasticsearch 的群集。
> 索引 (index):类似于关系型数据库中的“库”。当索引一个文档后.就可以使用 Elasticsearch 搜索到该文档,也可以简单地将索引理解为存储数据的地方,可以方便地进行全文索引。 在 index下面包含存储数据的类型(Type),Type类似于关系型数据库中的“表”,用来存放具体数据,而Type 下面包含文档(Document),文档相当于关系型数据库的“记录”,一个 文档是一个可被索引的基础信息单元。
> 分片和副本(shards & replicas):Elasticsearch 将索引分成若干个部分,每个部分称为一个分片,每个分片就是一个全功能的独立的索引。分片的数量一般在索引创建前指定,且创建索引后不能更改。
分片的两个最主要原因如下。
* 水平分割扩展,增大存储量。
* 分布式并行跨分片操作,提高性能和吞吐量。
2. Logstash 介绍
Logstash 的理念很简单,它只做三件事情:数据输入、数据加工(如过滤,改写等)以及数据输出。通过组合输入和输出,可以实现多种需求。Logstash 处理日志时,典型的部署架构围。
LogStash的主要组件如下。
> Shipper:日志收集者。负责监控本地日志文件的变化,及时收集最新的日志文件内容。通常,远程代理端(agent)只需要运行这个组件即可。
> Indexer:日志存储者。负责接收日志并写入到本地文件。
> Broker:日志Hub。负责连接多个Shipper和多个Indexer.
> Search and Storage:允许对事件进行搜索和存储。
> Web Interface:基于Web的展示界面。
3. Kibana介绍
Kibana是一个针对Elasticsearch 的开源分析及可视化平台,主要设计用来和 Elasticsearch 一起工作,可以搜索,查看存储在Elasticsearch 索引中的数据,并通过各种图表进行高级数据分析及展示。 Kibana可以让数据看起来一目了然。它操作简单,基于浏览器的用户界面可以让用户在任何位置都可以实时浏览。Kibena可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。Kibana使 用非常简单,只需要添加索引就可以监测Elasticsearch 索引数据。
Kibana的主要功能如下。
> Elasticsearch无缝之集成。Kibana架构是为Elasticsearch 定制的,可以将任何(结构化和非结 构化)数据加入Elasticsearch索引。Kibana还充分利用了 Elasticsearch 强大的搜索和分析功能。
> 整合数据。Kibana可以让海是数据变得更容易理解,根据数据内容可以创建形象的柱形图, 折线图、散点图、直方图、饼图和地图,以方便用户查看。
> 复杂数据分析。Kibana 提升了 Elasticsearch 的分析能力,能够更加智能地分析数据,执行数 学转换并且根据要求对数据切割分块,
> 让更多团队成员受益。强大的数据库可视化接口让各业务岗位都能够从数据集合受益。 接口灵活,分享更容易。使用Kibana可以更加方便地创建、保存、分享数据,并将可视化数据快速交流。
> 配置简单。Kibana的配置和启用非常简单,用户体验非常友好。Kibana自带Web服务器。 可以快速启动运行,
> 可视化多数据源。Kibana可以非常方便地把来自Logstash、ES-Hadoop、Beats 或第三方技术 的数据整合到 Elasticsearch,支持的第三方技术包括Apache Flume、Fluentd等,
> 简单数据导出。Kibana可以方便地导出感兴趣的数据,与其他数据集合并融合后快速建模分析,发现新结果。
部署配置实验
实验环境
虚拟机 3台 centos7.9
网卡NAT模式 数量 1
组件包
elasticsearch-5.5.0.rpm elasticsearch-head.tar.gz node-v8.2.1.tar.gz
phantomjs-2.1.1-linux-x86_64.tar.bz2 logstash-5.5.1.rpm kibana-5.5.1-x86_64.rpm
| 设备 | IP | 备注 |
| Centos01 | 192.168.161.11 | Node11 elasticsearch |
| Centos02 | 192.168.161.12 | Node22 kibana |
| Centos03 | 192.168.161.13 | httpd logstash+httpd |
环境准备
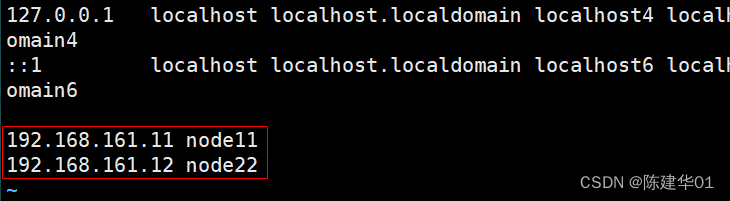
在两个EUK节点上配置域名解析,通过本地/etc/hosts文件实现(node11和node22操作相同)。
[root@node11 ~]# hostname
[root@node11 ~]# vim /etc/hosts
192.168.161.11 node11
192.168.161.12 node22
检查java环境
[root@node11 ~]# java -version

上传组件包至/root目录 elasticsearch-5.5.0.rpm logstash-5.5.1.rpm elasticsearch-head.tar.gz node-v8.2.1.tar.gz

安装Elasticseach软件。
[root@node11 ~]# rpm -ivh elasticsearch-5.5.0.rpm
加载系统服务
[root@node11 ~]# systemctl daemon-reload
[root@node11 ~]# systemctl enable elasticsearch.service 
更改Elasticsearch主配置文件。
[root@node11 ~]# vim /etc/elasticsearch/elasticsearch.yml

创建数据存放路径并授权。
[root@node11 ~]# mkdir -p /data/elk_data
[root@node11 ~]# chown elasticsearch:elasticsearch /data/elk_data/
[root@node22 ~]# mkdir -p /data/elk_data //node22创建目录
[root@node22 ~]# chown elasticsearch:elasticsearch /data/elk_data/启动Elasticsearch并查看是否成功开启。
[root@node11 ~]# systemctl start elasticsearch.service
[root@node11 ~]# cd /etc/elasticsearch/
[root@node11 elasticsearch]# netstat -antp | grep 9200
查看节点信息
在node11上。打开Web链接http://192.168.161.11:9200,可以查看节点node11的信息,如下图所示。

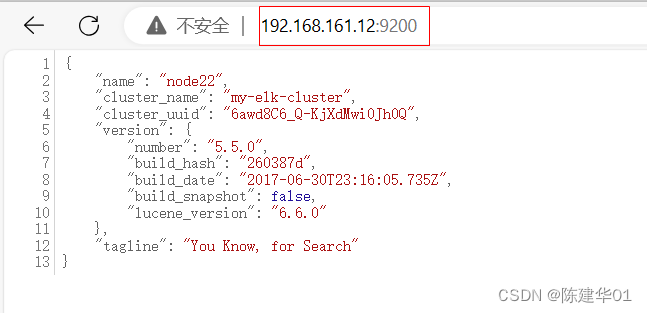
在node22上,打开Web链接http://192.168.161.12:9200,可以查看节点node22的信息,如下图所示。
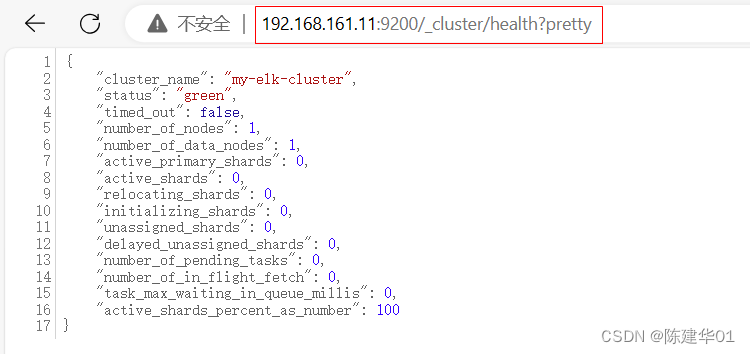
通过在浏览器中输入http://192.168.161.11:9200/_cluster/health?pretty 查看群集的健康情况, 可以看到staus值为 green(绿色),表示节点健康运行,如下图所示。
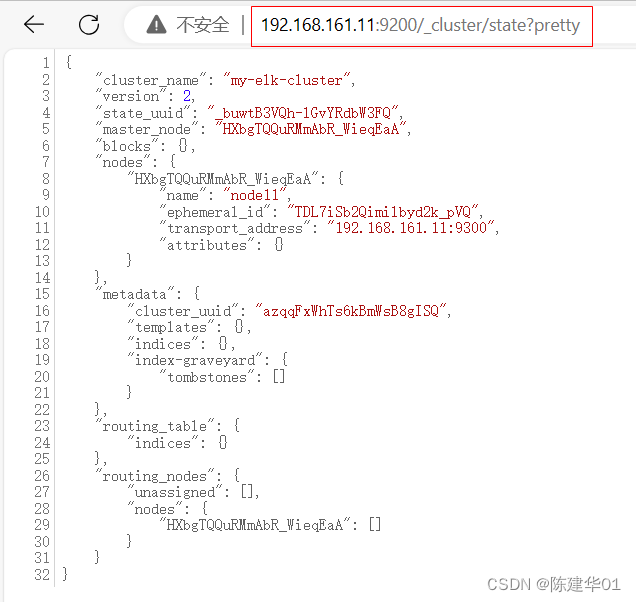
通过在浏览器中输入http://192.168.161.12:9200/_cluster/state?pretty查看群集的状态信息。 如下图所示。
通过以上方式查看群集的状态对用户并不友好,可以通过安装Elasticsearch-head 插件,可以更方便地管理群集。
12.2.3 安装 Elasticsearch-head 插件(以下操作为node11,node22无需操作)
(1)编译安装node。编译安装node耗时较长,大约20min,根据机器的配置可能略有不同,请耐心等待。
[root@node11 ~]# tar zxvf node-v8.2.1.tar.gz
[root@node11 ~]# cd node-v8.2.1/
[root@node11 node-v8.2.1]# ./configure
[root@node11 node-v8.2.1]# make
[root@node11 node-v8.2.1]# make install安装phantomjs。
[root@node11 ~]# tar xvjf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
[root@node11 ~]# cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin/
[root@node11 bin]# cp phantomjs /usr/local/bin/
安装Elasticsearch-head。
[root@node11 ~]# tar xvzf elasticsearch-head.tar.gz -C /usr/local/src/
[root@node11 ~]# cd /usr/local/src/elasticsearch-head/
[root@node11 elasticsearch-head]# npm install //安装依赖包
修改Elasticsearch主配置文件。
[root@node11 ~]# vim /etc/elasticsearch/elasticsearch.yml //以下内容需自行添加
http.cors.enabled:true //开启跨域访问支持,默认为false
http.cors.allow-origin:"*" //跨城访问允许的域名地址
http.cors.allow-headers: Authorization,Content-Type
[root@node11 ~]# systemctl restart elasticsearch.service

启动服务。
必须在解压后的elasticsearch-head目录下启动服务,进程会读取该目录下的 gruntfile.js文件,否则可能启动失败。elasticsearch-head 监听的端口是9100。通过该端口是否监听来判断服务是否正常开启。
[root@node11 ~]# cd /usr/local/src/elasticsearch-head/
[root@node11 elasticsearch-head]# npm run start &
[root@node11 elasticsearch-head]# netstat -lnupt | grep 9100

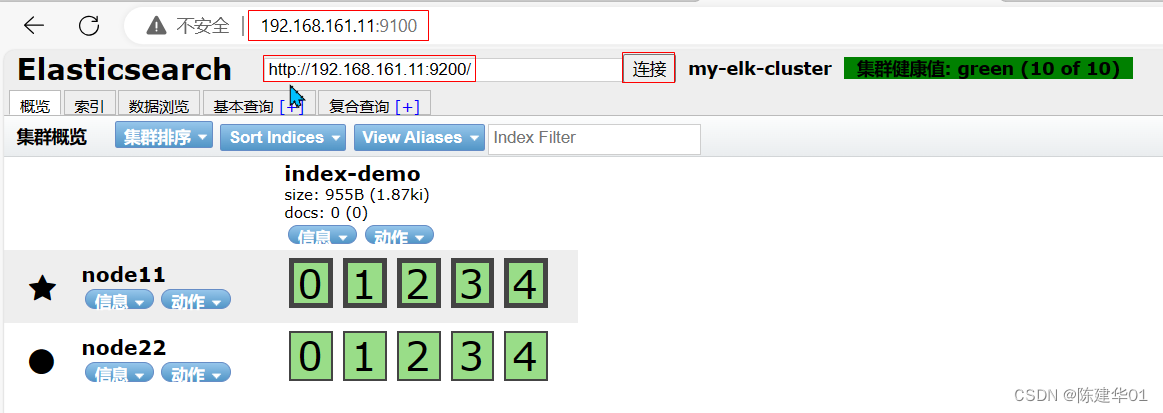
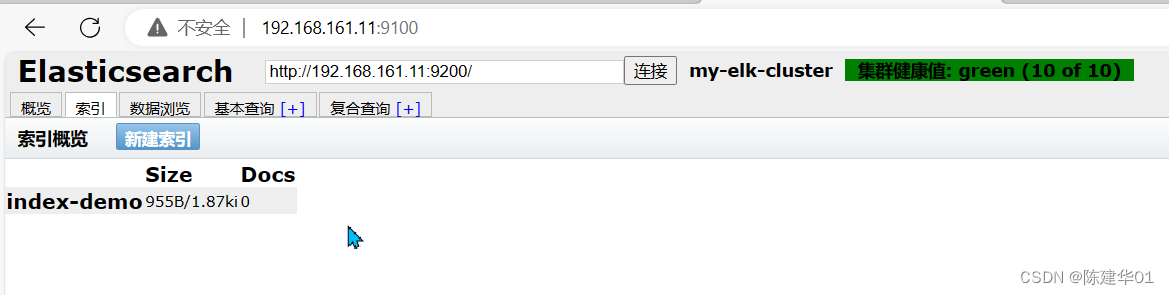
通过 Elasticsearch-head查看 Elasticsearch信息。通过浏览器访问http://192.168.161.11:9100/ 并连接群集,如下图所示。可以看到群集很健康,健康值为green绿色,单击数据浏览,可以查看索引信息。此时索引为空,如下图所示。
12.2.4 Logstash安装及使用方法
Logstash一般部署在需要监控其日志的服务器中,在本案例中,Logstash 部署在Apache服务器上, 用于收集Apache服务器的日志信息并发送到Elasticsearch中。在正式部署之前,先在Node1上部署 Logstash,以熟悉Logstash的使用方法。Logstash也需要Java环境,所以安装之前也要检查当前机器的Java环境是否存在。
(1)在node11上安装Logstash。
[root@node11 ~]# rpm -ivh logstash-5.5.1.rpm
[root@node11 ~]# systemctl start logstash.service
[root@node11 ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/ //创建链接
httpd上部署 httpd+ logstash
上传安装包 logstash-5.5.1.rpm
将 httpd 服务器的日志添加到 Elasticsearch并通过Kibane显示。
[root@httpd ~]# yum -y install httpd
[root@httpd ~]# rpm -ivh logstash-5.5.1.rpm
[root@httpd ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/sbin/
[root@httpd ~]# systemctl start httpd在apache服务器上安装Logstash,以便将收集的日志炭送到Elasticseerch中。
[root@httpd ~]# java -version
[root@httpd ~]# systemctl daemon-reload
[root@httpd ~]# systemctl enable logstash.service 编写 Logslash配置文件 httpd_log.conf 如下。
[root@httpd ~]# vim /etc/logstash/conf.d/httpd_log.conf
input {
file{
path => "/etc/httpd/logs/access_log" //收集Apache访问日志
type => "access" //类型指定为access
start_position => "beginning" //从开始处收集
}
file{
path => "/etc/httpd/logs/error_log" //收集Apache错误日志
type => "error" //类型指定为error
start_position => "beginning" //从开始处收集
}
}
output {
if [type] == "access" { //如果类型为access,即apache访问日志
elasticsearch { //输出到elasticsearch
hosts => ["192.168.161.11:9200"] // elasticsearch监听地址及端口
index => "apache_access-%{+YYYY.MM.dd}" //指定索引格式
}
}
if [type] == "error" { //如果类型为error,即Apache 错误日志
elasticsearch { //输出到elasticsearch
hosts => ["192.168.161.11:9200"] //elasticsearch监听地址及端口
index => "apache_error-%{+YYYY.MM.dd}" //指定索引格式
}
}
}

启动日志传递
[root@httpd ~]# nohup logstash -f /etc/logstash/conf.d/httpd_log.conf &

访问http://192.168.160.51:9200
验证
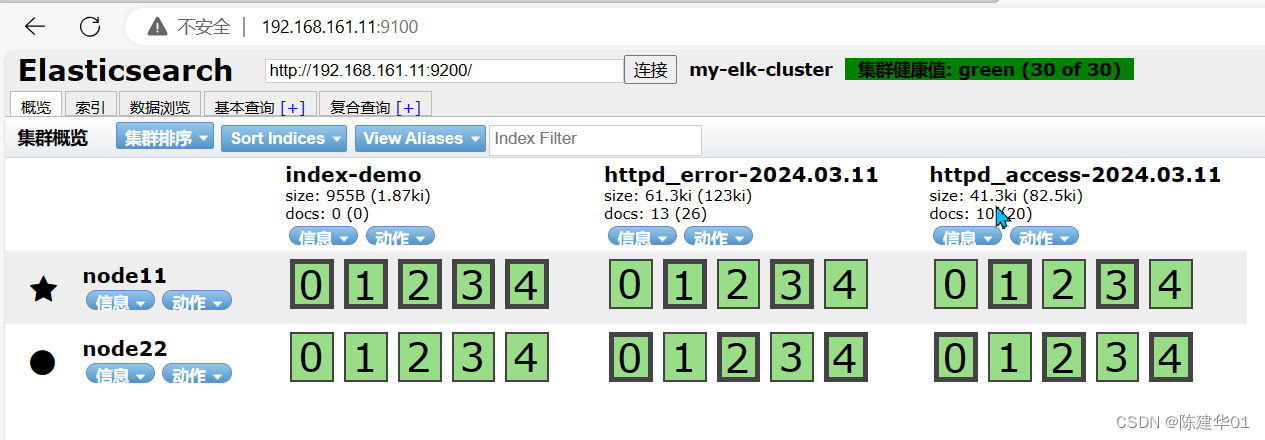
查看索引下的日志信息

Node22 安装 kibana 图形化查看工具
上传安装包 kibana-5.5.1-x86_64.rpm
[root@node22 ~]# rpm -ivh kibana-5.5.1-x86_64.rpm
cat << EOF >> /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.160.51:9200"
kibana.index: ".kibana"
EOF
[root@node22 ~]# vim /etc/kibana/kibana.yml


[root@node22 ~]# systemctl enable kibana.service --now

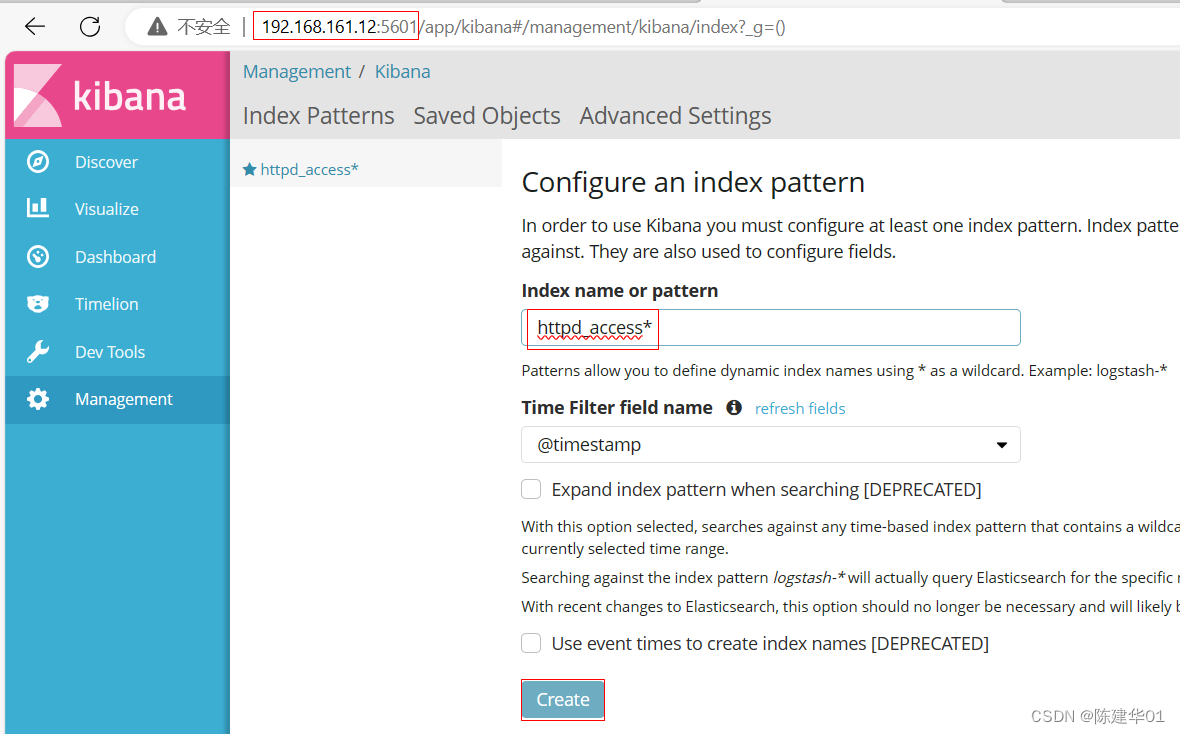
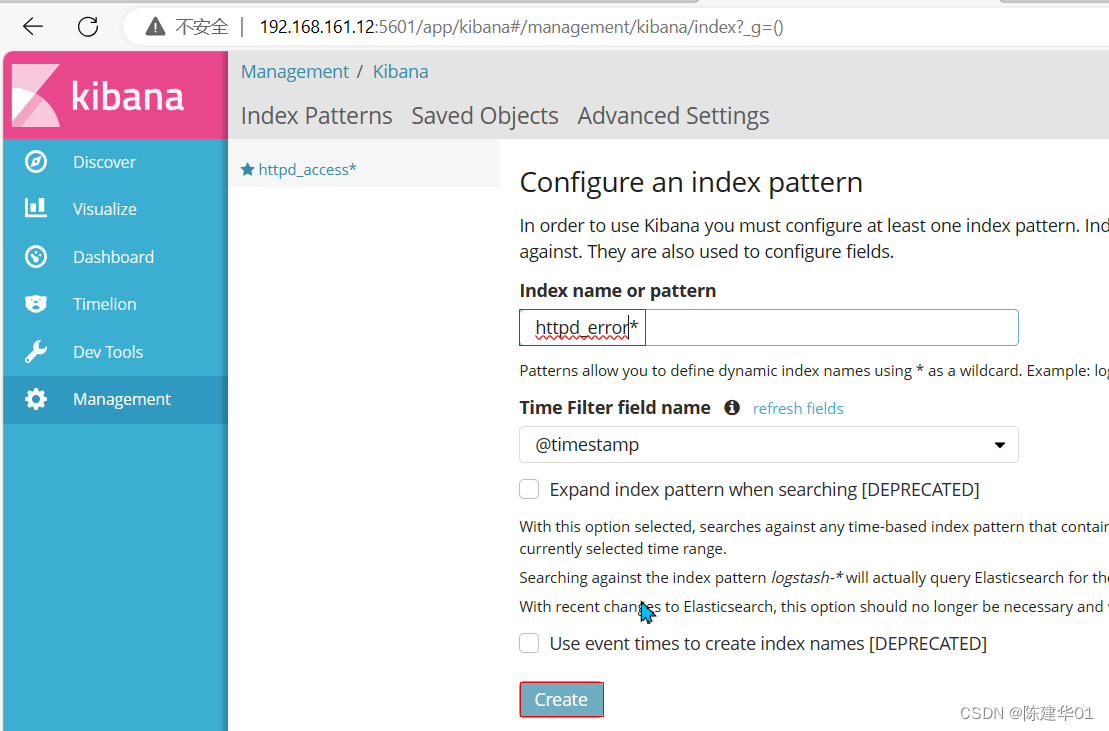
验证
http://192.168.161.12:5601 并 创建索引
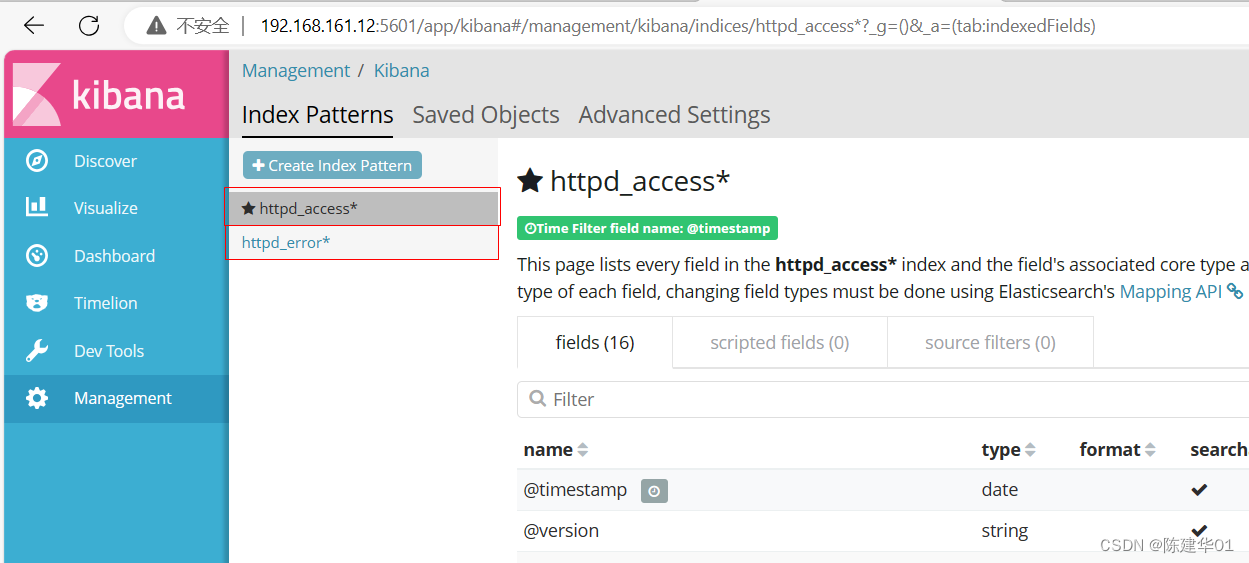
![[BUG] docker运行Java程序时配置代理-Dhttp.proxyHost后启动报错](https://img-blog.csdnimg.cn/direct/8d032c79b7b842b3b17fc104ba88bdb1.png)