文章目录
- 30. 串联所有单词的子串(hard)
- 方法一:暴力
- 方法二:滑窗
- 再次优化
- 小记-map的使用
30. 串联所有单词的子串(hard)

方法一:暴力
思路:
map存每个单词出现的个数。枚举s串的每一个下标i作为起始点:从起始点i开始,每m位(m = words[i].length)截出一个子串,一共截出n个(n = words.length),在map中查询该子串是否为单词且还有剩余个数——若否,则i不是答案;若是,剩余个数减1。如果n个单词都通过了检查,则i是答案。每一趟i的循环都要将map复原。
数据范围:
1 <= s.length <= 104
1 <= words.length <= 5000
1 <= words[i].length <= 30
时间复杂度分析:
O
(
10000
∗
(
5000
∗
30
∗
l
o
g
5000
+
5000
)
)
O(10000*(5000*30*log5000+5000) )
O(10000∗(5000∗30∗log5000+5000))
所以很自然的超时了(通过175/179)

附上代码:
struct p {
int total, res;
};
class Solution {
vector<int> ans;
map<string, p> mymap;
int n; //字符串s长度
int cnt; //单词个数
int m; //每个单词的长度
public:
vector<int> findSubstring(string s, vector<string>& words)
{
cnt = words.size();
n = s.length();
m = words[0].length();
for (auto & word : words)
mymap[word].total++;
for (int i=0; i<n; i++)
{
for (auto &[k,v] : mymap)
v.res = v.total;
int j;
for (j = i; j<i+cnt*m; j+=m )
{
string tmpword = s.substr(j, m);
if (mymap[tmpword].res > 0)
mymap[tmpword].res--;
else
break;
}
if (j == i+cnt * m)
ans.push_back(i);
}
return ans;
}
};
方法二:滑窗
思路:
单词分割方式只有m种(m = words[i].length)。比如s="acbdefghijkl"且m=3的话:
abc def ghi jkl
bcd efg hij
cde fgh ijk
def ghi jkl(到这儿就会发现和第一行重复了)
所以无需像方法一那样枚举每一个s串的下标,而是只枚举前m个下标。
然后对于每一种分割方式。
map1存单词表中每个单词出现的个数。map2存每个单词到整数的映射。数组cnt[5000]存滑窗中每个单词出现的次数。
通过代码:
class Solution {
vector<int> ans;
map<string, int> map1, map2; //map1存单词表中每个单词出现的个数。map2存每个单词到整数的映射。
int st[5000];
public:
vector<int> findSubstring(string s, vector<string>& words)
{
int cnt = words.size(), n = s.length(), m = words[0].length(), num = 0;
for (auto & word : words)
map1[word]++;
for (auto &[k,v] : map1)
map2[k] = num++;
s = s + " " + " " + " ";
for (int i=0; i<m; i++)
{
int pl = i, pr = i;
while (pr <= n)
{
string currWord = s.substr(pr, m);
int currWordIndex = map2[currWord];
int currWordCnt = map1[currWord];
if (st[currWordIndex] >= currWordCnt)
{
// 检查是否为答案
if (pr - pl == m * cnt) ans.push_back(pl);
//pl右移
while (st[currWordIndex] >= currWordCnt)
{
st[map2[s.substr(pl, m)]]--;
pl += m;
}
}
st[currWordIndex]++;
pr+=m;
}
}
return ans;
}
};

再次优化
这个思路已经很好了,但是为什么运行还是太慢?因为map中存了大量不属于单词表的串。
考虑下面的代码,size是1不是0
map<string, int> mm;
cout << mm["haha"];
printf("%d", mm.size());
所以为了避免不属于单词表的子串存入map1和map2,代码改为如下:
class Solution {
vector<int> ans;
map<string, int> map1, map2; //map1存单词表中每个单词出现的个数。map2存每个单词到整数的映射。
int st[5000];
public:
vector<int> findSubstring(string s, vector<string>& words)
{
int cnt = words.size(), n = s.length(), m = words[0].length(), num = 0;
for (auto & word : words)
map1[word]++;
for (auto &[k,v] : map1)
map2[k] = num++;
for (int i=0; i<m; i++)
s += " ";
for (int i=0; i<m; i++)
{
int pl = i, pr = i;
while (pr <= n)
{
string currWord = s.substr(pr, m);
if (map1.count(currWord) == 0)
{
if (pr - pl == m * cnt) ans.push_back(pl);
while (pl < pr)
{
st[map2[s.substr(pl, m)]]--;
pl += m;
}
pr += m;
pl = pr;
continue;
}
int currWordIndex = map2[currWord];
int currWordCnt = map1[currWord];
if (st[currWordIndex] >= currWordCnt)
{
// 检查是否为答案
if (pr - pl == m * cnt) ans.push_back(pl);
//pl右移
while (st[currWordIndex] >= currWordCnt)
{
st[map2[s.substr(pl, m)]]--;
pl += m;
}
}
st[currWordIndex]++;
pr+=m;
}
}
return ans;
}
};
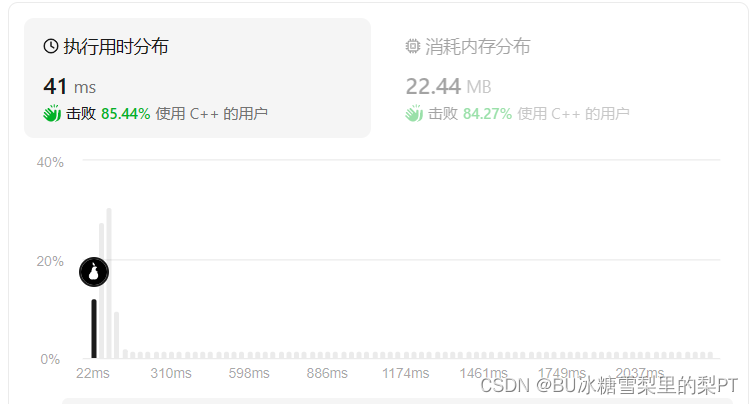
这个结果就很好了。
小记-map的使用
- 考虑下面的代码,size是1不是0
map<string, int> mm;
cout << mm["haha"];
printf("%d", mm.size());
- map的遍历方法
for (auto &[k,v] : map1)
map2[k] = num++;

![[LeetCode][426]【学习日记】将二叉搜索树转化为排序的双向链表——前驱节点pre 和 当前节点cur 的使用](https://img-blog.csdnimg.cn/direct/bd25e0beff2f48fea447f203816a4cee.png)