实现Event(event bus)
event bus既是node中各个模块的基石,又是前端组件通信的依赖手段之一,同时涉及了订阅-发布设计模式,是非常重要的基础。
简单版:
class EventEmeitter {
constructor() {
this._events = this._events || new Map(); // 储存事件/回调键值对
this._maxListeners = this._maxListeners || 10; // 设立监听上限
}
}
// 触发名为type的事件
EventEmeitter.prototype.emit = function(type, ...args) {
let handler;
// 从储存事件键值对的this._events中获取对应事件回调函数
handler = this._events.get(type);
if (args.length > 0) {
handler.apply(this, args);
} else {
handler.call(this);
}
return true;
};
// 监听名为type的事件
EventEmeitter.prototype.addListener = function(type, fn) {
// 将type事件以及对应的fn函数放入this._events中储存
if (!this._events.get(type)) {
this._events.set(type, fn);
}
};
面试版:
class EventEmeitter {
constructor() {
this._events = this._events || new Map(); // 储存事件/回调键值对
this._maxListeners = this._maxListeners || 10; // 设立监听上限
}
}
// 触发名为type的事件
EventEmeitter.prototype.emit = function(type, ...args) {
let handler;
// 从储存事件键值对的this._events中获取对应事件回调函数
handler = this._events.get(type);
if (args.length > 0) {
handler.apply(this, args);
} else {
handler.call(this);
}
return true;
};
// 监听名为type的事件
EventEmeitter.prototype.addListener = function(type, fn) {
// 将type事件以及对应的fn函数放入this._events中储存
if (!this._events.get(type)) {
this._events.set(type, fn);
}
};
// 触发名为type的事件
EventEmeitter.prototype.emit = function(type, ...args) {
let handler;
handler = this._events.get(type);
if (Array.isArray(handler)) {
// 如果是一个数组说明有多个监听者,需要依次此触发里面的函数
for (let i = 0; i < handler.length; i++) {
if (args.length > 0) {
handler[i].apply(this, args);
} else {
handler[i].call(this);
}
}
} else {
// 单个函数的情况我们直接触发即可
if (args.length > 0) {
handler.apply(this, args);
} else {
handler.call(this);
}
}
return true;
};
// 监听名为type的事件
EventEmeitter.prototype.addListener = function(type, fn) {
const handler = this._events.get(type); // 获取对应事件名称的函数清单
if (!handler) {
this._events.set(type, fn);
} else if (handler && typeof handler === "function") {
// 如果handler是函数说明只有一个监听者
this._events.set(type, [handler, fn]); // 多个监听者我们需要用数组储存
} else {
handler.push(fn); // 已经有多个监听者,那么直接往数组里push函数即可
}
};
EventEmeitter.prototype.removeListener = function(type, fn) {
const handler = this._events.get(type); // 获取对应事件名称的函数清单
// 如果是函数,说明只被监听了一次
if (handler && typeof handler === "function") {
this._events.delete(type, fn);
} else {
let postion;
// 如果handler是数组,说明被监听多次要找到对应的函数
for (let i = 0; i < handler.length; i++) {
if (handler[i] === fn) {
postion = i;
} else {
postion = -1;
}
}
// 如果找到匹配的函数,从数组中清除
if (postion !== -1) {
// 找到数组对应的位置,直接清除此回调
handler.splice(postion, 1);
// 如果清除后只有一个函数,那么取消数组,以函数形式保存
if (handler.length === 1) {
this._events.set(type, handler[0]);
}
} else {
return this;
}
}
};
实现具体过程和思路见实现event
Array.prototype.map()
Array.prototype.map = function(callback, thisArg) {
if (this == undefined) {
throw new TypeError('this is null or not defined');
}
if (typeof callback !== 'function') {
throw new TypeError(callback + ' is not a function');
}
const res = [];
// 同理
const O = Object(this);
const len = O.length >>> 0;
for (let i = 0; i < len; i++) {
if (i in O) {
// 调用回调函数并传入新数组
res[i] = callback.call(thisArg, O[i], i, this);
}
}
return res;
}
二叉树深度遍历
// 二叉树深度遍历
class Node {
constructor(element, parent) {
this.parent = parent // 父节点
this.element = element // 当前存储内容
this.left = null // 左子树
this.right = null // 右子树
}
}
class BST {
constructor(compare) {
this.root = null // 树根
this.size = 0 // 树中的节点个数
this.compare = compare || this.compare
}
compare(a,b) {
return a - b
}
add(element) {
if(this.root === null) {
this.root = new Node(element, null)
this.size++
return
}
// 获取根节点 用当前添加的进行判断 放左边还是放右边
let currentNode = this.root
let compare
let parent = null
while (currentNode) {
compare = this.compare(element, currentNode.element)
parent = currentNode // 先将父亲保存起来
// currentNode要不停的变化
if(compare > 0) {
currentNode = currentNode.right
} else if(compare < 0) {
currentNode = currentNode.left
} else {
currentNode.element = element // 相等时 先覆盖后续处理
}
}
let newNode = new Node(element, parent)
if(compare > 0) {
parent.right = newNode
} else if(compare < 0) {
parent.left = newNode
}
this.size++
}
// 前序遍历
preorderTraversal(visitor) {
const traversal = node=>{
if(node === null) return
visitor.visit(node.element)
traversal(node.left)
traversal(node.right)
}
traversal(this.root)
}
// 中序遍历
inorderTraversal(visitor) {
const traversal = node=>{
if(node === null) return
traversal(node.left)
visitor.visit(node.element)
traversal(node.right)
}
traversal(this.root)
}
// 后序遍历
posterorderTraversal(visitor) {
const traversal = node=>{
if(node === null) return
traversal(node.left)
traversal(node.right)
visitor.visit(node.element)
}
traversal(this.root)
}
// 反转二叉树:无论先序、中序、后序、层级都可以反转
invertTree() {
const traversal = node=>{
if(node === null) return
let temp = node.left
node.left = node.right
node.right = temp
traversal(node.left)
traversal(node.right)
}
traversal(this.root)
return this.root
}
}
先序遍历

二叉树的遍历方式

// 测试
var bst = new BST((a,b)=>a.age-b.age) // 模拟sort方法
bst.add({age: 10})
bst.add({age: 8})
bst.add({age:19})
bst.add({age:6})
bst.add({age: 15})
bst.add({age: 22})
bst.add({age: 20})
// 先序遍历
// console.log(bst.preorderTraversal(),'先序遍历')
// console.log(bst.inorderTraversal(),'中序遍历')
// 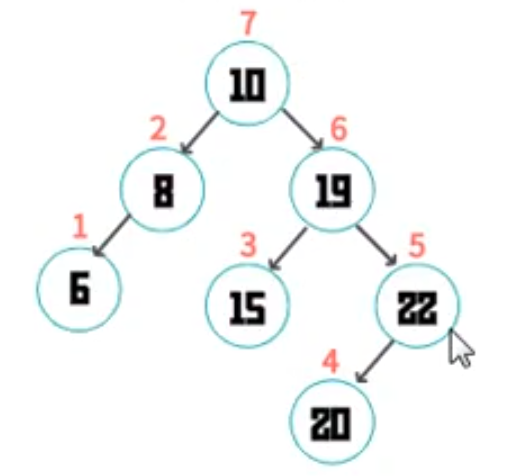
// console.log(bst.posterorderTraversal(),'后序遍历')
// 深度遍历:先序遍历、中序遍历、后续遍历
// 广度遍历:层次遍历(同层级遍历)
// 都可拿到树中的节点
// 使用访问者模式
class Visitor {
constructor() {
this.visit = function (elem) {
elem.age = elem.age*2
}
}
}
// bst.posterorderTraversal({
// visit(elem) {
// elem.age = elem.age*10
// }
// })
// 不能通过索引操作 拿到节点去操作
// bst.posterorderTraversal(new Visitor())
console.log(bst.invertTree(),'反转二叉树')
版本号排序的方法
题目描述:有一组版本号如下 ['0.1.1', '2.3.3', '0.302.1', '4.2', '4.3.5', '4.3.4.5']。现在需要对其进行排序,排序的结果为 ['4.3.5','4.3.4.5','2.3.3','0.302.1','0.1.1']
arr.sort((a, b) => {
let i = 0;
const arr1 = a.split(".");
const arr2 = b.split(".");
while (true) {
const s1 = arr1[i];
const s2 = arr2[i];
i++;
if (s1 === undefined || s2 === undefined) {
return arr2.length - arr1.length;
}
if (s1 === s2) continue;
return s2 - s1;
}
});
console.log(arr);
判断是否是电话号码
function isPhone(tel) {
var regx = /^1[34578]\d{9}$/;
return regx.test(tel);
}
请实现 DOM2JSON 一个函数,可以把一个 DOM 节点输出 JSON 的格式
<div>
<span>
<a></a>
</span>
<span>
<a></a>
<a></a>
</span>
</div>
把上面dom结构转成下面的JSON格式
{
tag: 'DIV',
children: [
{
tag: 'SPAN',
children: [
{ tag: 'A', children: [] }
]
},
{
tag: 'SPAN',
children: [
{ tag: 'A', children: [] },
{ tag: 'A', children: [] }
]
}
]
}
实现代码如下:
function dom2Json(domtree) {
let obj = {};
obj.name = domtree.tagName;
obj.children = [];
domtree.childNodes.forEach((child) => obj.children.push(dom2Json(child)));
return obj;
}
参考 前端进阶面试题详细解答
实现千位分隔符
// 保留三位小数
parseToMoney(1234.56); // return '1,234.56'
parseToMoney(123456789); // return '123,456,789'
parseToMoney(1087654.321); // return '1,087,654.321'
function parseToMoney(num) {
num = parseFloat(num.toFixed(3));
let [integer, decimal] = String.prototype.split.call(num, '.');
integer = integer.replace(/\d(?=(\d{3})+$)/g, '$&,');
return integer + '.' + (decimal ? decimal : '');
}
创建10个标签,点击的时候弹出来对应的序号
var a
for(let i=0;i<10;i++){
a=document.createElement('a')
a.innerHTML=i+'<br>'
a.addEventListener('click',function(e){
console.log(this) //this为当前点击的<a>
e.preventDefault() //如果调用这个方法,默认事件行为将不再触发。
//例如,在执行这个方法后,如果点击一个链接(a标签),浏览器不会跳转到新的 URL 去了。我们可以用 event.isDefaultPrevented() 来确定这个方法是否(在那个事件对象上)被调用过了。
alert(i)
})
const d=document.querySelector('div')
d.appendChild(a) //append向一个已存在的元素追加该元素。
}
手写深度比较isEqual
思路:深度比较两个对象,就是要深度比较对象的每一个元素。=> 递归
- 递归退出条件:
- 被比较的是两个值类型变量,直接用“===”判断
- 被比较的两个变量之一为
null,直接判断另一个元素是否也为null
- 提前结束递推:
- 两个变量
keys数量不同 - 传入的两个参数是同一个变量
- 两个变量
- 递推工作:深度比较每一个
key
function isEqual(obj1, obj2){
//其中一个为值类型或null
if(!isObject(obj1) || !isObject(obj2)){
return obj1 === obj2;
}
//判断是否两个参数是同一个变量
if(obj1 === obj2){
return true;
}
//判断keys数是否相等
const obj1Keys = Object.keys(obj1);
const obj2Keys = Object.keys(obj2);
if(obj1Keys.length !== obj2Keys.length){
return false;
}
//深度比较每一个key
for(let key in obj1){
if(!isEqual(obj1[key], obj2[key])){
return false;
}
}
return true;
}
二叉树层次遍历
// 二叉树层次遍历
class Node {
constructor(element, parent) {
this.parent = parent // 父节点
this.element = element // 当前存储内容
this.left = null // 左子树
this.right = null // 右子树
}
}
class BST {
constructor(compare) {
this.root = null // 树根
this.size = 0 // 树中的节点个数
this.compare = compare || this.compare
}
compare(a,b) {
return a - b
}
add(element) {
if(this.root === null) {
this.root = new Node(element, null)
this.size++
return
}
// 获取根节点 用当前添加的进行判断 放左边还是放右边
let currentNode = this.root
let compare
let parent = null
while (currentNode) {
compare = this.compare(element, currentNode.element)
parent = currentNode // 先将父亲保存起来
// currentNode要不停的变化
if(compare > 0) {
currentNode = currentNode.right
} else if(compare < 0) {
currentNode = currentNode.left
} else {
currentNode.element = element // 相等时 先覆盖后续处理
}
}
let newNode = new Node(element, parent)
if(compare > 0) {
parent.right = newNode
} else if(compare < 0) {
parent.left = newNode
}
this.size++
}
// 层次遍历 队列
levelOrderTraversal(visitor) {
if(this.root == null) {
return
}
let stack = [this.root]
let index = 0 // 指针 指向0
let currentNode
while (currentNode = stack[index++]) {
// 反转二叉树
let tmp = currentNode.left
currentNode.left = currentNode.right
currentNode.right = tmp
visitor.visit(currentNode.element)
if(currentNode.left) {
stack.push(currentNode.left)
}
if(currentNode.right) {
stack.push(currentNode.right)
}
}
}
}
// 测试
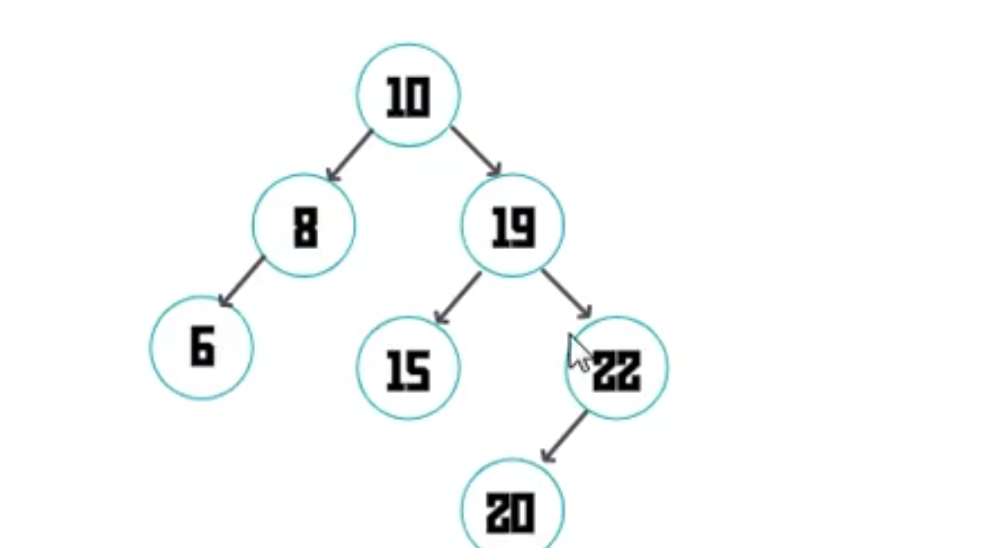
var bst = new BST((a,b)=>a.age-b.age) // 模拟sort方法
// 
// 
bst.add({age: 10})
bst.add({age: 8})
bst.add({age:19})
bst.add({age:6})
bst.add({age: 15})
bst.add({age: 22})
bst.add({age: 20})
// 使用访问者模式
class Visitor {
constructor() {
this.visit = function (elem) {
elem.age = elem.age*2
}
}
}
// 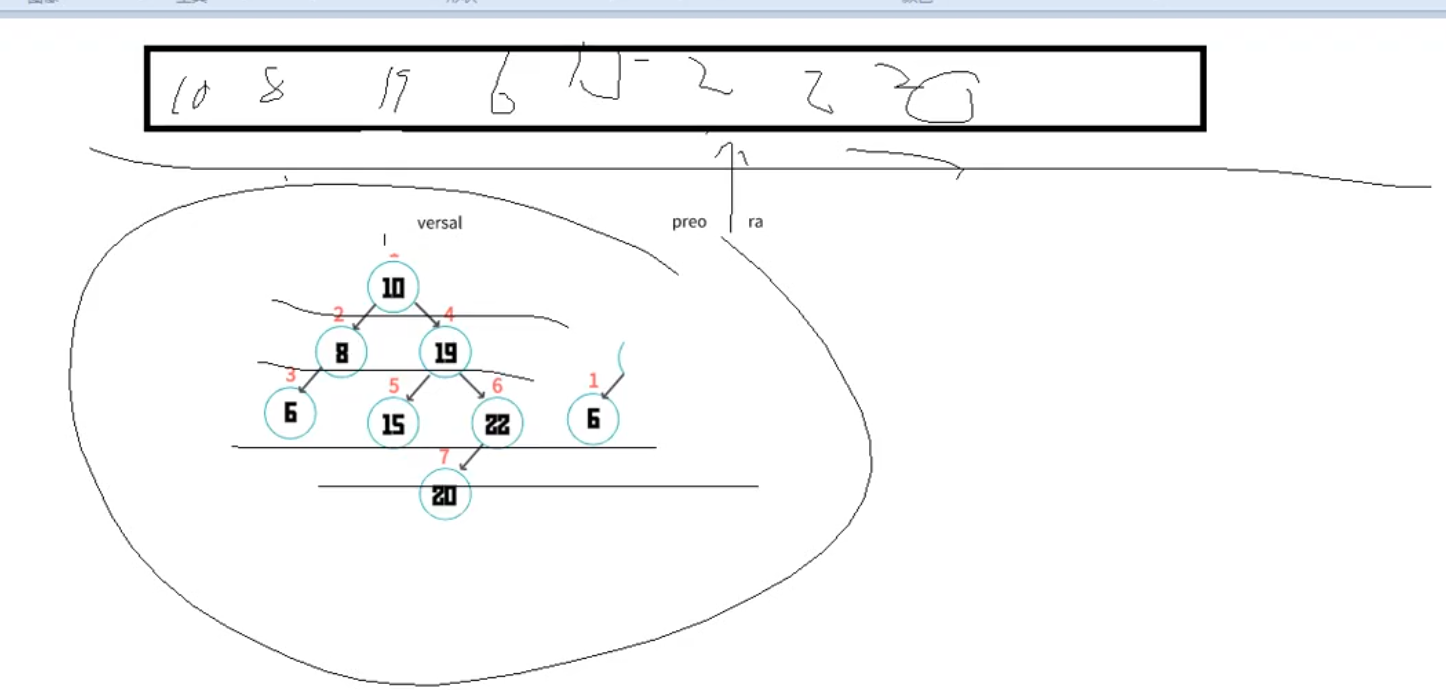
console.log(bst.levelOrderTraversal(new Visitor()))
reduce用法汇总
语法
array.reduce(function(total, currentValue, currentIndex, arr), initialValue);
/*
total: 必需。初始值, 或者计算结束后的返回值。
currentValue: 必需。当前元素。
currentIndex: 可选。当前元素的索引;
arr: 可选。当前元素所属的数组对象。
initialValue: 可选。传递给函数的初始值,相当于total的初始值。
*/
reduceRight()该方法用法与reduce()其实是相同的,只是遍历的顺序相反,它是从数组的最后一项开始,向前遍历到第一项
1. 数组求和
const arr = [12, 34, 23];
const sum = arr.reduce((total, num) => total + num);
// 设定初始值求和
const arr = [12, 34, 23];
const sum = arr.reduce((total, num) => total + num, 10); // 以10为初始值求和
// 对象数组求和
var result = [
{ subject: 'math', score: 88 },
{ subject: 'chinese', score: 95 },
{ subject: 'english', score: 80 }
];
const sum = result.reduce((accumulator, cur) => accumulator + cur.score, 0);
const sum = result.reduce((accumulator, cur) => accumulator + cur.score, -10); // 总分扣除10分
2. 数组最大值
const a = [23,123,342,12];
const max = a.reduce((pre,next)=>pre>cur?pre:cur,0); // 342
3. 数组转对象
var streams = [{name: '技术', id: 1}, {name: '设计', id: 2}];
var obj = streams.reduce((accumulator, cur) => {accumulator[cur.id] = cur; return accumulator;}, {});
4. 扁平一个二维数组
var arr = [[1, 2, 8], [3, 4, 9], [5, 6, 10]];
var res = arr.reduce((x, y) => x.concat(y), []);
5. 数组去重
实现的基本原理如下:
① 初始化一个空数组
② 将需要去重处理的数组中的第1项在初始化数组中查找,如果找不到(空数组中肯定找不到),就将该项添加到初始化数组中
③ 将需要去重处理的数组中的第2项在初始化数组中查找,如果找不到,就将该项继续添加到初始化数组中
④ ……
⑤ 将需要去重处理的数组中的第n项在初始化数组中查找,如果找不到,就将该项继续添加到初始化数组中
⑥ 将这个初始化数组返回
var newArr = arr.reduce(function (prev, cur) {
prev.indexOf(cur) === -1 && prev.push(cur);
return prev;
},[]);
6. 对象数组去重
const dedup = (data, getKey = () => { }) => {
const dateMap = data.reduce((pre, cur) => {
const key = getKey(cur)
if (!pre[key]) {
pre[key] = cur
}
return pre
}, {})
return Object.values(dateMap)
}
7. 求字符串中字母出现的次数
const str = 'sfhjasfjgfasjuwqrqadqeiqsajsdaiwqdaklldflas-cmxzmnha';
const res = str.split('').reduce((pre,next)=>{
pre[next] ? pre[next]++ : pre[next] = 1
return pre
},{})
// 结果
-: 1
a: 8
c: 1
d: 4
e: 1
f: 4
g: 1
h: 2
i: 2
j: 4
k: 1
l: 3
m: 2
n: 1
q: 5
r: 1
s: 6
u: 1
w: 2
x: 1
z: 1
8. compose函数
redux compose源码实现
function compose(...funs) {
if (funs.length === 0) {
return arg => arg;
}
if (funs.length === 1) {
return funs[0];
}
return funs.reduce((a, b) => (...arg) => a(b(...arg)))
}
实现apply方法
思路: 利用
this的上下文特性。apply其实就是改一下参数的问题
Function.prototype.myApply = function(context = window, args) {
// this-->func context--> obj args--> 传递过来的参数
// 在context上加一个唯一值不影响context上的属性
let key = Symbol('key')
context[key] = this; // context为调用的上下文,this此处为函数,将这个函数作为context的方法
// let args = [...arguments].slice(1) //第一个参数为obj所以删除,伪数组转为数组
let result = context[key](...args); // 这里和call传参不一样
// 清除定义的this 不删除会导致context属性越来越多
delete context[key];
// 返回结果
return result;
}
// 使用
function f(a,b){
console.log(a,b)
console.log(this.name)
}
let obj={
name:'张三'
}
f.myApply(obj,[1,2]) //arguments[1]
实现Object.create
Object.create()方法创建一个新对象,使用现有的对象来提供新创建的对象的__proto__
// 模拟 Object.create
function create(proto) {
function F() {}
F.prototype = proto;
return new F();
}
实现有并行限制的 Promise 调度器
题目描述:JS 实现一个带并发限制的异步调度器 Scheduler,保证同时运行的任务最多有两个
addTask(1000,"1");
addTask(500,"2");
addTask(300,"3");
addTask(400,"4");
的输出顺序是:2 3 1 4
整个的完整执行流程:
一开始1、2两个任务开始执行
500ms时,2任务执行完毕,输出2,任务3开始执行
800ms时,3任务执行完毕,输出3,任务4开始执行
1000ms时,1任务执行完毕,输出1,此时只剩下4任务在执行
1200ms时,4任务执行完毕,输出4
实现代码如下:
class Scheduler {
constructor(limit) {
this.queue = [];
this.maxCount = limit;
this.runCounts = 0;
}
add(time, order) {
const promiseCreator = () => {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(order);
resolve();
}, time);
});
};
this.queue.push(promiseCreator);
}
taskStart() {
for (let i = 0; i < this.maxCount; i++) {
this.request();
}
}
request() {
if (!this.queue || !this.queue.length || this.runCounts >= this.maxCount) {
return;
}
this.runCounts++;
this.queue
.shift()()
.then(() => {
this.runCounts--;
this.request();
});
}
}
const scheduler = new Scheduler(2);
const addTask = (time, order) => {
scheduler.add(time, order);
};
addTask(1000, "1");
addTask(500, "2");
addTask(300, "3");
addTask(400, "4");
scheduler.taskStart();
实现一个JS函数柯里化
预先处理的思想,利用闭包的机制
- 柯里化的定义:接收一部分参数,返回一个函数接收剩余参数,接收足够参数后,执行原函数
- 函数柯里化的主要作用和特点就是
参数复用、提前返回和延迟执行
- 柯里化把多次传入的参数合并,柯里化是一个高阶函数
- 每次都返回一个新函数
- 每次入参都是一个
当柯里化函数接收到足够参数后,就会执行原函数,如何去确定何时达到足够的参数呢?
有两种思路:
- 通过函数的
length属性,获取函数的形参个数,形参的个数就是所需的参数个数 - 在调用柯里化工具函数时,手动指定所需的参数个数
将这两点结合一下,实现一个简单 curry 函数
通用版
// 写法1
function curry(fn, args) {
var length = fn.length;
var args = args || [];
return function(){
newArgs = args.concat(Array.prototype.slice.call(arguments));
if (newArgs.length < length) {
return curry.call(this,fn,newArgs);
}else{
return fn.apply(this,newArgs);
}
}
}
// 写法2
// 分批传入参数
// redux 源码的compose也是用了类似柯里化的操作
const curry = (fn, arr = []) => {// arr就是我们要收集每次调用时传入的参数
let len = fn.length; // 函数的长度,就是参数的个数
return function(...args) {
let newArgs = [...arr, ...args] // 收集每次传入的参数
// 如果传入的参数个数等于我们指定的函数参数个数,就执行指定的真正函数
if(newArgs.length === len) {
return fn(...newArgs)
} else {
// 递归收集参数
return curry(fn, newArgs)
}
}
}
// 测试
function multiFn(a, b, c) {
return a * b * c;
}
var multi = curry(multiFn);
multi(2)(3)(4);
multi(2,3,4);
multi(2)(3,4);
multi(2,3)(4)
ES6写法
const curry = (fn, arr = []) => (...args) => (
arg => arg.length === fn.length
? fn(...arg)
: curry(fn, arg)
)([...arr, ...args])
// 测试
let curryTest=curry((a,b,c,d)=>a+b+c+d)
curryTest(1,2,3)(4) //返回10
curryTest(1,2)(4)(3) //返回10
curryTest(1,2)(3,4) //返回10
// 柯里化求值
// 指定的函数
function sum(a,b,c,d,e) {
return a + b + c + d + e
}
// 传入指定的函数,执行一次
let newSum = curry(sum)
// 柯里化 每次入参都是一个参数
newSum(1)(2)(3)(4)(5)
// 偏函数
newSum(1)(2)(3,4,5)
// 柯里化简单应用
// 判断类型,参数多少个,就执行多少次收集
function isType(type, val) {
return Object.prototype.toString.call(val) === `[object ${type}]`
}
let newType = curry(isType)
// 相当于把函数参数一个个传了,把第一次先缓存起来
let isString = newType('String')
let isNumber = newType('Number')
isString('hello world')
isNumber(999)
实现一个管理本地缓存过期的函数
封装一个可以设置过期时间的
localStorage存储函数
class Storage{
constructor(name){
this.name = 'storage';
}
//设置缓存
setItem(params){
let obj = {
name:'', // 存入数据 属性
value:'',// 属性值
expires:"", // 过期时间
startTime:new Date().getTime()//记录何时将值存入缓存,毫秒级
}
let options = {};
//将obj和传进来的params合并
Object.assign(options,obj,params);
if(options.expires){
//如果options.expires设置了的话
//以options.name为key,options为值放进去
localStorage.setItem(options.name,JSON.stringify(options));
}else{
//如果options.expires没有设置,就判断一下value的类型
let type = Object.prototype.toString.call(options.value);
//如果value是对象或者数组对象的类型,就先用JSON.stringify转一下,再存进去
if(Object.prototype.toString.call(options.value) == '[object Object]'){
options.value = JSON.stringify(options.value);
}
if(Object.prototype.toString.call(options.value) == '[object Array]'){
options.value = JSON.stringify(options.value);
}
localStorage.setItem(options.name,options.value);
}
}
//拿到缓存
getItem(name){
let item = localStorage.getItem(name);
//先将拿到的试着进行json转为对象的形式
try{
item = JSON.parse(item);
}catch(error){
//如果不行就不是json的字符串,就直接返回
item = item;
}
//如果有startTime的值,说明设置了失效时间
if(item.startTime){
let date = new Date().getTime();
//何时将值取出减去刚存入的时间,与item.expires比较,如果大于就是过期了,如果小于或等于就还没过期
if(date - item.startTime > item.expires){
//缓存过期,清除缓存,返回false
localStorage.removeItem(name);
return false;
}else{
//缓存未过期,返回值
return item.value;
}
}else{
//如果没有设置失效时间,直接返回值
return item;
}
}
//移出缓存
removeItem(name){
localStorage.removeItem(name);
}
//移出全部缓存
clear(){
localStorage.clear();
}
}
用法
let storage = new Storage();
storage.setItem({
name:"name",
value:"ppp"
})
下面我把值取出来
let value = storage.getItem('name');
console.log('我是value',value);
设置5秒过期
let storage = new Storage();
storage.setItem({
name:"name",
value:"ppp",
expires: 5000
})
// 过期后再取出来会变为 false
let value = storage.getItem('name');
console.log('我是value',value);
图片懒加载
// <img src="default.png" data-src="https://xxxx/real.png">
function isVisible(el) {
const position = el.getBoundingClientRect()
const windowHeight = document.documentElement.clientHeight
// 顶部边缘可见
const topVisible = position.top > 0 && position.top < windowHeight;
// 底部边缘可见
const bottomVisible = position.bottom < windowHeight && position.bottom > 0;
return topVisible || bottomVisible;
}
function imageLazyLoad() {
const images = document.querySelectorAll('img')
for (let img of images) {
const realSrc = img.dataset.src
if (!realSrc) continue
if (isVisible(img)) {
img.src = realSrc
img.dataset.src = ''
}
}
}
// 测试
window.addEventListener('load', imageLazyLoad)
window.addEventListener('scroll', imageLazyLoad)
// or
window.addEventListener('scroll', throttle(imageLazyLoad, 1000))
实现Object.freeze
Object.freeze冻结一个对象,让其不能再添加/删除属性,也不能修改该对象已有属性的可枚举性、可配置可写性,也不能修改已有属性的值和它的原型属性,最后返回一个和传入参数相同的对象
function myFreeze(obj){
// 判断参数是否为Object类型,如果是就封闭对象,循环遍历对象。去掉原型属性,将其writable特性设置为false
if(obj instanceof Object){
Object.seal(obj); // 封闭对象
for(let key in obj){
if(obj.hasOwnProperty(key)){
Object.defineProperty(obj,key,{
writable:false // 设置只读
})
// 如果属性值依然为对象,要通过递归来进行进一步的冻结
myFreeze(obj[key]);
}
}
}
}
实现Node的require方法
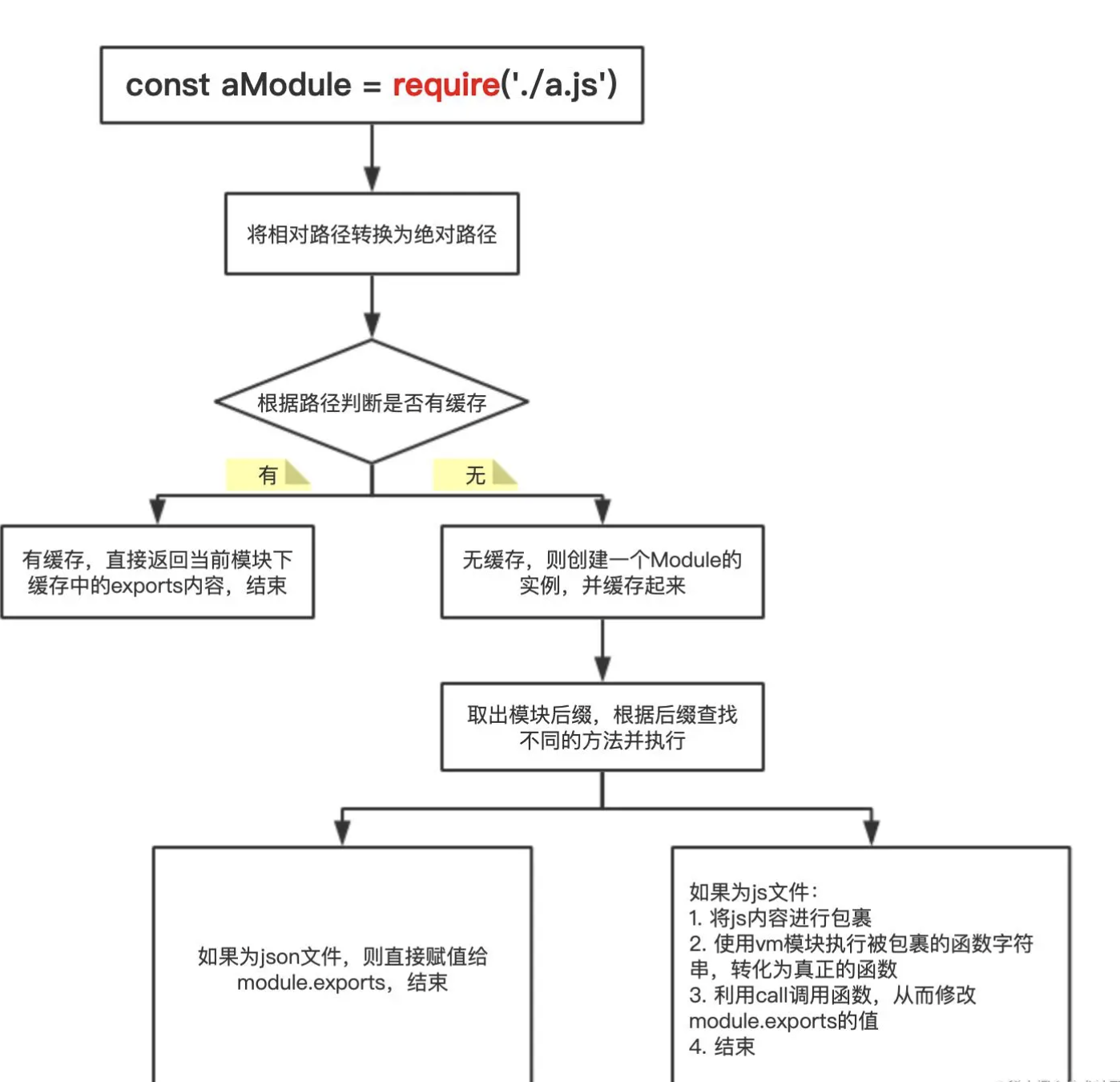
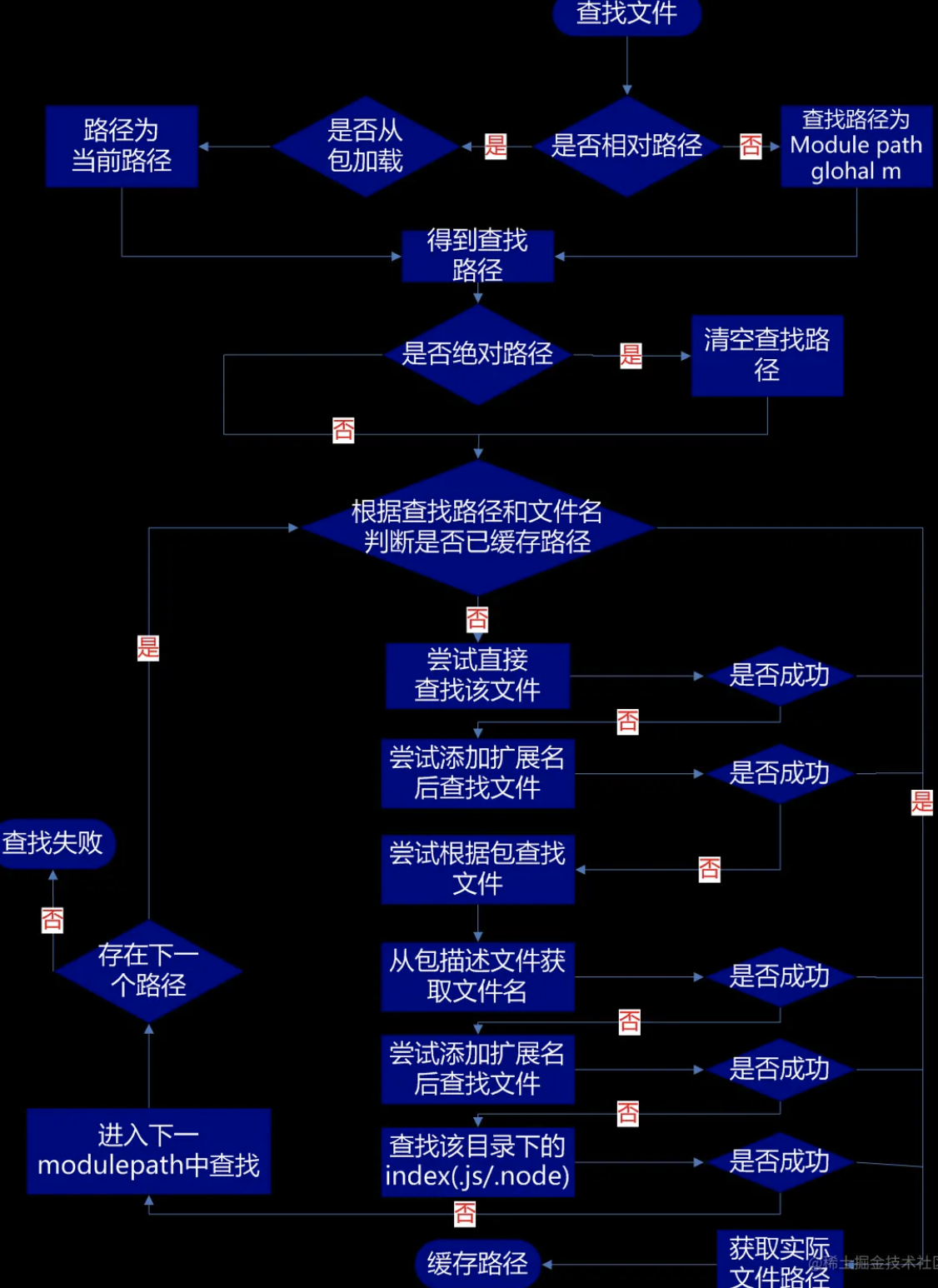
require 基本原理
require 查找路径
require和module.exports干的事情并不复杂,我们先假设有一个全局对象{},初始情况下是空的,当你require某个文件时,就将这个文件拿出来执行,如果这个文件里面存在module.exports,当运行到这行代码时将module.exports的值加入这个对象,键为对应的文件名,最终这个对象就长这样:
{
"a.js": "hello world",
"b.js": function add(){},
"c.js": 2,
"d.js": { num: 2 }
}
当你再次
require某个文件时,如果这个对象里面有对应的值,就直接返回给你,如果没有就重复前面的步骤,执行目标文件,然后将它的module.exports加入这个全局对象,并返回给调用者。这个全局对象其实就是我们经常听说的缓存。所以require和module.exports并没有什么黑魔法,就只是运行并获取目标文件的值,然后加入缓存,用的时候拿出来用就行
手写实现一个require
const path = require('path'); // 路径操作
const fs = require('fs'); // 文件读取
const vm = require('vm'); // 文件执行
// node模块化的实现
// node中是自带模块化机制的,每个文件就是一个单独的模块,并且它遵循的是CommonJS规范,也就是使用require的方式导入模块,通过module.export的方式导出模块。
// node模块的运行机制也很简单,其实就是在每一个模块外层包裹了一层函数,有了函数的包裹就可以实现代码间的作用域隔离
// require加载模块
// require依赖node中的fs模块来加载模块文件,fs.readFile读取到的是一个字符串。
// 在javascrpt中我们可以通过eval或者new Function的方式来将一个字符串转换成js代码来运行。
// eval
// const name = 'poetry';
// const str = 'const a = 123; console.log(name)';
// eval(str); // poetry;
// new Function
// new Function接收的是一个要执行的字符串,返回的是一个新的函数,调用这个新的函数字符串就会执行了。如果这个函数需要传递参数,可以在new Function的时候依次传入参数,最后传入的是要执行的字符串。比如这里传入参数b,要执行的字符串str
// const b = 3;
// const str = 'let a = 1; return a + b';
// const fun = new Function('b', str);
// console.log(fun(b, str)); // 4
// 可以看到eval和Function实例化都可以用来执行javascript字符串,似乎他们都可以来实现require模块加载。不过在node中并没有选用他们来实现模块化,原因也很简单因为他们都有一个致命的问题,就是都容易被不属于他们的变量所影响。
// 如下str字符串中并没有定义a,但是确可以使用上面定义的a变量,这显然是不对的,在模块化机制中,str字符串应该具有自身独立的运行空间,自身不存在的变量是不可以直接使用的
// const a = 1;
// const str = 'console.log(a)';
// eval(str);
// const func = new Function(str);
// func();
// node存在一个vm虚拟环境的概念,用来运行额外的js文件,他可以保证javascript执行的独立性,不会被外部所影响
// vm 内置模块
// 虽然我们在外部定义了hello,但是str是一个独立的模块,并不在村hello变量,所以会直接报错。
// 引入vm模块, 不需要安装,node 自建模块
// const vm = require('vm');
// const hello = 'poetry';
// const str = 'console.log(hello)';
// wm.runInThisContext(str); // 报错
// 所以node执行javascript模块时可以采用vm来实现。就可以保证模块的独立性了
// 分析实现步骤
// 1.导入相关模块,创建一个Require方法。
// 2.抽离通过Module._load方法,用于加载模块。
// 3.Module.resolveFilename 根据相对路径,转换成绝对路径。
// 4.缓存模块 Module._cache,同一个模块不要重复加载,提升性能。
// 5.创建模块 id: 保存的内容是 exports = {}相当于this。
// 6.利用tryModuleLoad(module, filename) 尝试加载模块。
// 7.Module._extensions使用读取文件。
// 8.Module.wrap: 把读取到的js包裹一个函数。
// 9.将拿到的字符串使用runInThisContext运行字符串。
// 10.让字符串执行并将this改编成exports
// 定义导入类,参数为模块路径
function Require(modulePath) {
// 获取当前要加载的绝对路径
let absPathname = path.resolve(__dirname, modulePath);
// 自动给模块添加后缀名,实现省略后缀名加载模块,其实也就是如果文件没有后缀名的时候遍历一下所有的后缀名看一下文件是否存在
// 获取所有后缀名
const extNames = Object.keys(Module._extensions);
let index = 0;
// 存储原始文件路径
const oldPath = absPathname;
function findExt(absPathname) {
if (index === extNames.length) {
throw new Error('文件不存在');
}
try {
fs.accessSync(absPathname);
return absPathname;
} catch(e) {
const ext = extNames[index++];
findExt(oldPath + ext);
}
}
// 递归追加后缀名,判断文件是否存在
absPathname = findExt(absPathname);
// 从缓存中读取,如果存在,直接返回结果
if (Module._cache[absPathname]) {
return Module._cache[absPathname].exports;
}
// 创建模块,新建Module实例
const module = new Module(absPathname);
// 添加缓存
Module._cache[absPathname] = module;
// 加载当前模块
tryModuleLoad(module);
// 返回exports对象
return module.exports;
}
// Module的实现很简单,就是给模块创建一个exports对象,tryModuleLoad执行的时候将内容加入到exports中,id就是模块的绝对路径
// 定义模块, 添加文件id标识和exports属性
function Module(id) {
this.id = id;
// 读取到的文件内容会放在exports中
this.exports = {};
}
Module._cache = {};
// 我们给Module挂载静态属性wrapper,里面定义一下这个函数的字符串,wrapper是一个数组,数组的第一个元素就是函数的参数部分,其中有exports,module. Require,__dirname, __filename, 都是我们模块中常用的全局变量。注意这里传入的Require参数是我们自己定义的Require
// 第二个参数就是函数的结束部分。两部分都是字符串,使用的时候我们将他们包裹在模块的字符串外部就可以了
Module.wrapper = [
"(function(exports, module, Require, __dirname, __filename) {",
"})"
]
// _extensions用于针对不同的模块扩展名使用不同的加载方式,比如JSON和javascript加载方式肯定是不同的。JSON使用JSON.parse来运行。
// javascript使用vm.runInThisContext来运行,可以看到fs.readFileSync传入的是module.id也就是我们Module定义时候id存储的是模块的绝对路径,读取到的content是一个字符串,我们使用Module.wrapper来包裹一下就相当于在这个模块外部又包裹了一个函数,也就实现了私有作用域。
// 使用call来执行fn函数,第一个参数改变运行的this我们传入module.exports,后面的参数就是函数外面包裹参数exports, module, Require, __dirname, __filename
Module._extensions = {
'.js'(module) {
const content = fs.readFileSync(module.id, 'utf8');
const fnStr = Module.wrapper[0] + content + Module.wrapper[1];
const fn = vm.runInThisContext(fnStr);
fn.call(module.exports, module.exports, module, Require,__filename,__dirname);
},
'.json'(module) {
const json = fs.readFileSync(module.id, 'utf8');
module.exports = JSON.parse(json); // 把文件的结果放在exports属性上
}
}
// tryModuleLoad函数接收的是模块对象,通过path.extname来获取模块的后缀名,然后使用Module._extensions来加载模块
// 定义模块加载方法
function tryModuleLoad(module) {
// 获取扩展名
const extension = path.extname(module.id);
// 通过后缀加载当前模块
Module._extensions[extension](module);
}
// 至此Require加载机制我们基本就写完了,我们来重新看一下。Require加载模块的时候传入模块名称,在Require方法中使用path.resolve(__dirname, modulePath)获取到文件的绝对路径。然后通过new Module实例化的方式创建module对象,将模块的绝对路径存储在module的id属性中,在module中创建exports属性为一个json对象
// 使用tryModuleLoad方法去加载模块,tryModuleLoad中使用path.extname获取到文件的扩展名,然后根据扩展名来执行对应的模块加载机制
// 最终将加载到的模块挂载module.exports中。tryModuleLoad执行完毕之后module.exports已经存在了,直接返回就可以了
// 给模块添加缓存
// 添加缓存也比较简单,就是文件加载的时候将文件放入缓存中,再去加载模块时先看缓存中是否存在,如果存在直接使用,如果不存在再去重新,加载之后再放入缓存
// 测试
let json = Require('./test.json');
let test2 = Require('./test2.js');
console.log(json);
console.log(test2);
实现防抖函数(debounce)
防抖函数原理:在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。
那么与节流函数的区别直接看这个动画实现即可。
手写简化版:
// 防抖函数
const debounce = (fn, delay) => {
let timer = null;
return (...args) => {
clearTimeout(timer);
timer = setTimeout(() => {
fn.apply(this, args);
}, delay);
};
};
适用场景:
- 按钮提交场景:防止多次提交按钮,只执行最后提交的一次
- 服务端验证场景:表单验证需要服务端配合,只执行一段连续的输入事件的最后一次,还有搜索联想词功能类似
生存环境请用lodash.debounce