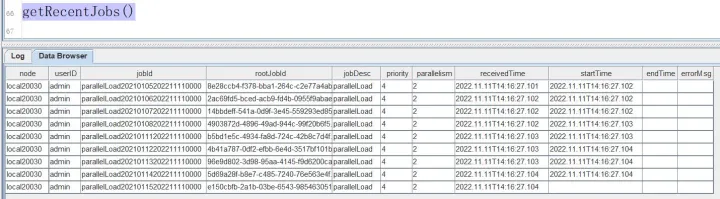
众所周知,个性化推荐系统能够根据用户的兴趣、偏好等信息向用户推荐相关内容,使得用户更感兴趣,从而提升用户体验,提高用户粘度,之前我们曾经使用协同过滤算法构建过个性化推荐系统,但基于显式反馈的算法就会有一定的局限性,本次我们使用无监督的Lda文本聚类方式来构建文本的个性化推荐系统。
推荐算法:协同过滤/Lda聚类
我们知道,协同过滤算法是一种基于用户的历史行为来推荐物品的算法。协同过滤算法利用用户之间的相似性来推荐物品,如果两个用户对某些物品的评分相似,则协同过滤算法会将这两个用户视为相似的,并向其中一个用户推荐另一个用户喜欢的物品。
说白了,它基于用户的显式反馈,什么是显式反馈?举个例子,本如本篇文章,用户看了之后,可能会点赞,也可能会疯狂点踩,或者写一些关于文本的评论,当然评论内容可能是负面、正面或者中性,所有这些用户给出的行为,都是显式反馈,但如果用户没有反馈出这些行为,就只是看了看,协同过滤算法的效果就会变差。
LDA聚类是一种文本聚类算法,它通过对文本进行主题建模来聚类文本。LDA聚类算法在聚类文本时,不考虑用户的历史行为,而是根据文本的内容和主题来聚类。
说得通俗一点,协同过滤是一种主动推荐,系统根据用户历史行为来进行内容推荐,而LDA聚类则是一种被动推荐,在用户还没有产生用户行为时,就已经开始推荐动作。
LDA聚类的主要目的是将文本分为几类,使得每类文本的主题尽可能相似。
LDA聚类算法的工作流程大致如下:
1.对文本进行预处理,去除停用词等。
2.使用LDA模型对文本进行主题建模,得到文本的主题分布。
3.将文本按照主题分布相似性进行聚类。
4.将聚类结果作为类标签,对文本进行分类。
大体上,LDA聚类算法是一种自动将文本分类的算法,它通过对文本进行主题建模,将文本按照主题相似性进行聚类,最终实现文本的分类。
Python3.10实现
实际应用层面,我们需要做的是让主题模型能够识别在文本里的主题,并且挖掘文本信息中隐式信息,并且在主题聚合、从非结构化文本中提取信息。
首先安装分词以及聚类模型库:
pip3 install jieba
pip3 install gensim
随后进行分词操作,这里以笔者的几篇文章为例子:
import jieba
import pandas as pd
import numpy as np
title1="乾坤大挪移,如何将同步阻塞(sync)三方库包转换为异步非阻塞(async)模式?Python3.10实现。"
title2="Generator(生成器),入门初基,Coroutine(原生协程),登峰造极,Python3.10并发异步编程async底层实现"
title3="周而复始,往复循环,递归、尾递归算法与无限极层级结构的探究和使用(Golang1.18)"
title4="彩虹女神跃长空,Go语言进阶之Go语言高性能Web框架Iris项目实战-JWT和中间件(Middleware)的使用EP07"
content = [title1,title2, title3,title4]
#分词
content_S = []
all_words = []
for line in content:
current_segment = [w for w in jieba.cut(line) if len(w)>1]
for x in current_segment:
all_words.append(x)
if len(current_segment) > 1 and current_segment != '\r\t':
content_S.append(current_segment)
#分词结果转为DataFrame
df_content = pd.DataFrame({'content_S':content_S})
print(all_words)
可以看到,这里通过四篇文章标题构建分词列表,最后打印分词结果:
['乾坤', '挪移', '如何', '同步', '阻塞', 'sync', '三方', '库包', '转换', '异步', '阻塞', 'async', '模式', 'Python3.10', '实现', 'Generator', '生成器', '入门', '初基', 'Coroutine', '原生', '协程', '登峰造极', 'Python3.10', '并发', '异步', '编程', 'async', '底层', '实现', '周而复始', '往复', '循环', '递归', '递归', '算法', '无限极', '层级', '结构', '探究', '使用', 'Golang1.18', '彩虹', '女神', '长空', 'Go', '语言', '进阶', 'Go', '语言', '高性能', 'Web', '框架', 'Iris', '项目', '实战', 'JWT', '中间件', 'Middleware', '使用', 'EP07']
接着就可以针对这些词进行聚类操作,我们可以先让ChatGPT帮我们进行聚类看看结果:

可以看到,ChatGPT已经帮我们将分词结果进行聚类操作,分为两大类:Python和Golang。
严谨起见,我们可以针对分词结果进行过滤操作,过滤内容是停用词,停用词是在文本分析、自然语言处理等应用中,用来过滤掉不需要的词的。通常来说,停用词是指在英文中的介词、代词、连接词等常用词,在中文中的助词、介词、连词等常用词:
———
》),
)÷(1-
”,
)、
=(
:
→
℃
&
*
一一
~~~~
’
.
『
.一
./
--
』
=″
【
[*]
}>
[⑤]]
[①D]
c]
ng昉
*
//
[
]
[②e]
[②g]
={
}
,也
‘
A
[①⑥]
[②B]
[①a]
[④a]
[①③]
[③h]
③]
1.
--
[②b]
’‘
×××
[①⑧]
0:2
=[
[⑤b]
[②c]
[④b]
[②③]
[③a]
[④c]
[①⑤]
[①⑦]
[①g]
∈[
[①⑨]
[①④]
[①c]
[②f]
[②⑧]
[②①]
[①C]
[③c]
[③g]
[②⑤]
[②②]
一.
[①h]
.数
[]
[①B]
数/
[①i]
[③e]
[①①]
[④d]
[④e]
[③b]
[⑤a]
[①A]
[②⑧]
[②⑦]
[①d]
[②j]
〕〔
][
://
′∈
[②④
[⑤e]
12%
b]
...
...................
…………………………………………………③
ZXFITL
[③F]
」
[①o]
]∧′=[
∪φ∈
′|
{-
②c
}
[③①]
R.L.
[①E]
Ψ
-[*]-
↑
.日
[②d]
[②
[②⑦]
[②②]
[③e]
[①i]
[①B]
[①h]
[①d]
[①g]
[①②]
[②a]
f]
[⑩]
a]
[①e]
[②h]
[②⑥]
[③d]
[②⑩]
e]
〉
】
元/吨
[②⑩]
2.3%
5:0
[①]
::
[②]
[③]
[④]
[⑤]
[⑥]
[⑦]
[⑧]
[⑨]
……
——
?
、
。
“
”
《
》
!
,
:
;
?
.
,
.
'
?
·
———
──
?
—
<
>
(
)
〔
〕
[
]
(
)
-
+
~
×
/
/
①
②
③
④
⑤
⑥
⑦
⑧
⑨
⑩
Ⅲ
В
"
;
#
@
γ
μ
φ
φ.
×
Δ
■
▲
sub
exp
sup
sub
Lex
#
%
&
'
+
+ξ
++
-
-β
<
<±
<Δ
<λ
<φ
<<
=
=
=☆
=-
>
>λ
_
~±
~+
[⑤f]
[⑤d]
[②i]
≈
[②G]
[①f]
LI
㈧
[-
......
〉
[③⑩]
第二
一番
一直
一个
一些
许多
种
有的是
也就是说
末##末
啊
阿
哎
哎呀
哎哟
唉
俺
俺们
按
按照
吧
吧哒
把
罢了
被
本
本着
比
比方
比如
鄙人
彼
彼此
边
别
别的
别说
并
并且
不比
不成
不单
不但
不独
不管
不光
不过
不仅
不拘
不论
不怕
不然
不如
不特
不惟
不问
不只
朝
朝着
趁
趁着
乘
冲
除
除此之外
除非
除了
此
此间
此外
从
从而
打
待
但
但是
当
当着
到
得
的
的话
等
等等
地
第
叮咚
对
对于
多
多少
而
而况
而且
而是
而外
而言
而已
尔后
反过来
反过来说
反之
非但
非徒
否则
嘎
嘎登
该
赶
个
各
各个
各位
各种
各自
给
根据
跟
故
故此
固然
关于
管
归
果然
果真
过
哈
哈哈
呵
和
何
何处
何况
何时
嘿
哼
哼唷
呼哧
乎
哗
还是
还有
换句话说
换言之
或
或是
或者
极了
及
及其
及至
即
即便
即或
即令
即若
即使
几
几时
己
既
既然
既是
继而
加之
假如
假若
假使
鉴于
将
较
较之
叫
接着
结果
借
紧接着
进而
尽
尽管
经
经过
就
就是
就是说
据
具体地说
具体说来
开始
开外
靠
咳
可
可见
可是
可以
况且
啦
来
来着
离
例如
哩
连
连同
两者
了
临
另
另外
另一方面
论
嘛
吗
慢说
漫说
冒
么
每
每当
们
莫若
某
某个
某些
拿
哪
哪边
哪儿
哪个
哪里
哪年
哪怕
哪天
哪些
哪样
那
那边
那儿
那个
那会儿
那里
那么
那么些
那么样
那时
那些
那样
乃
乃至
呢
能
你
你们
您
宁
宁可
宁肯
宁愿
哦
呕
啪达
旁人
呸
凭
凭借
其
其次
其二
其他
其它
其一
其余
其中
起
起见
起见
岂但
恰恰相反
前后
前者
且
然而
然后
然则
让
人家
任
任何
任凭
如
如此
如果
如何
如其
如若
如上所述
若
若非
若是
啥
上下
尚且
设若
设使
甚而
甚么
甚至
省得
时候
什么
什么样
使得
是
是的
首先
谁
谁知
顺
顺着
似的
虽
虽然
虽说
虽则
随
随着
所
所以
他
他们
他人
它
它们
她
她们
倘
倘或
倘然
倘若
倘使
腾
替
通过
同
同时
哇
万一
往
望
为
为何
为了
为什么
为着
喂
嗡嗡
我
我们
呜
呜呼
乌乎
无论
无宁
毋宁
嘻
吓
相对而言
像
向
向着
嘘
呀
焉
沿
沿着
要
要不
要不然
要不是
要么
要是
也
也罢
也好
一
一般
一旦
一方面
一来
一切
一样
一则
依
依照
矣
以
以便
以及
以免
以至
以至于
以致
抑或
因
因此
因而
因为
哟
用
由
由此可见
由于
有
有的
有关
有些
又
于
于是
于是乎
与
与此同时
与否
与其
越是
云云
哉
再说
再者
在
在下
咱
咱们
则
怎
怎么
怎么办
怎么样
怎样
咋
照
照着
者
这
这边
这儿
这个
这会儿
这就是说
这里
这么
这么点儿
这么些
这么样
这时
这些
这样
正如
吱
之
之类
之所以
之一
只是
只限
只要
只有
至
至于
诸位
着
着呢
自
自从
自个儿
自各儿
自己
自家
自身
综上所述
总的来看
总的来说
总的说来
总而言之
总之
纵
纵令
纵然
纵使
遵照
作为
兮
呃
呗
咚
咦
喏
啐
喔唷
嗬
嗯
嗳
这里使用哈工大的停用词列表。
首先加载停用词列表,然后进行过滤操作:
#去除停用词
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(word)
contents_clean.append(line_clean)
return contents_clean,all_words
#停用词加载
stopwords = pd.read_table('stop_words.txt',names = ['stopword'],quoting = 3)
contents = df_content.content_S.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
接着交给Gensim进行聚类操作:
from gensim import corpora,models,similarities
import gensim
dictionary = corpora.Dictionary(contents_clean)
corpus = [dictionary.doc2bow(sentence) for sentence in contents_clean]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus,id2word=dictionary,num_topics=2,random_state=3)
#print(lda.print_topics(num_topics=2, num_words=4))
for e, values in enumerate(lda.inference(corpus)[0]):
print(content[e])
for ee, value in enumerate(values):
print('\t分类%d推断值%.2f' % (ee, value))
这里使用LdaModel模型进行训练,分类设置(num_topics)为2种,随机种子(random_state)为3,在训练机器学习模型时,很多模型的训练过程都会涉及到随机数的生成,例如随机梯度下降法(SGD)就是一种随机梯度下降的优化算法。在训练过程中,如果不设置random_state参数,则每次训练结果可能都不同。而设置random_state参数后,每次训练结果都会相同,这就方便了我们在调参时对比模型的效果。如果想要让每次训练的结果都随机,可以将random_state参数设置为None。
程序返回:
[['乾坤', '挪移', '同步', '阻塞', 'sync', '三方', '库包', '转换', '异步', '阻塞', 'async', '模式', 'Python3.10', '实现'], ['Generator', '生成器', '入门', '初基', 'Coroutine', '原生', '协程', '登峰造极', 'Python3.10', '并发', '异步', '编程', 'async', '底层', '实现'], ['周而复始', '往复', '循环', '递归', '递归', '算法', '无限极', '层级', '结构', '探究', '使用', 'Golang1.18'], ['彩虹', '女神', '长空', 'Go', '语言', '进阶', 'Go', '语言', '高性能', 'Web', '框架', 'Iris', '项目', '实战', 'JWT', '中间件', 'Middleware', '使用', 'EP07']]
乾坤大挪移,如何将同步阻塞(sync)三方库包转换为异步非阻塞(async)模式?Python3.10实现。
分类0推断值0.57
分类1推断值14.43
Generator(生成器),入门初基,Coroutine(原生协程),登峰造极,Python3.10并发异步编程async底层实现
分类0推断值0.58
分类1推断值15.42
周而复始,往复循环,递归、尾递归算法与无限极层级结构的探究和使用(Golang1.18)
分类0推断值12.38
分类1推断值0.62
彩虹女神跃长空,Go语言进阶之Go语言高性能Web框架Iris项目实战-JWT和中间件(Middleware)的使用EP07
分类0推断值19.19
分类1推断值0.81
可以看到,结果和ChatGPT聚类结果一致,前两篇为一种分类,后两篇为另外一种分类。
随后可以将聚类结果保存为模型文件:
lda.save('mymodel.model')
以后有新的文章发布,直接对新的文章进行分类推测即可:
from gensim.models import ldamodel
import pandas as pd
import jieba
from gensim import corpora
doc0="巧如范金,精比琢玉,一分钟高效打造精美详实的Go语言技术简历(Golang1.18)"
# 加载模型
lda = ldamodel.LdaModel.load('mymodel.model')
content = [doc0]
#分词
content_S = []
for line in content:
current_segment = [w for w in jieba.cut(line) if len(w)>1]
if len(current_segment) > 1 and current_segment != '\r\t':
content_S.append(current_segment)
#分词结果转为DataFrame
df_content = pd.DataFrame({'content_S':content_S})
#去除停用词
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(word)
contents_clean.append(line_clean)
return contents_clean,all_words
#停用词加载
stopwords = pd.read_table('stop_words.txt',names = ['stopword'],quoting = 3)
contents = df_content.content_S.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
dictionary = corpora.Dictionary(contents_clean)
word = [w for w in jieba.cut(doc0)]
bow = dictionary.doc2bow(word)
print(lda.get_document_topics(bow))
程序返回:
➜ nlp_chinese /opt/homebrew/bin/python3.10 "/Users/liuyue/wodfan/work/nlp_chinese/new_text.py"
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/5x/gpftd0654bv7zvzyv39449rc0000gp/T/jieba.cache
Loading model cost 0.264 seconds.
Prefix dict has been built successfully.
[(0, 0.038379338), (1, 0.9616206)]
这里显示文章推断结果为分类2,也就是Golang类型的文章。
完整调用逻辑:
import jieba
import pandas as pd
import numpy as np
from gensim.models import ldamodel
from gensim import corpora,models,similarities
import gensim
class LdaRec:
def __init__(self,cotent:list) -> None:
self.content = content
self.contents_clean = []
self.lda = None
def test_text(self,content:str):
self.lda = ldamodel.LdaModel.load('mymodel.model')
self.content = [content]
#分词
content_S = []
for line in self.content:
current_segment = [w for w in jieba.cut(line) if len(w)>1]
if len(current_segment) > 1 and current_segment != '\r\t':
content_S.append(current_segment)
#分词结果转为DataFrame
df_content = pd.DataFrame({'content_S':content_S})
contents = df_content.content_S.values.tolist()
dictionary = corpora.Dictionary(contents)
word = [w for w in jieba.cut(content)]
bow = dictionary.doc2bow(word)
print(self.lda.get_document_topics(bow))
# 训练
def train(self,num_topics=2,random_state=3):
dictionary = corpora.Dictionary(self.contents_clean)
corpus = [dictionary.doc2bow(sentence) for sentence in self.contents_clean]
self.lda = gensim.models.ldamodel.LdaModel(corpus=corpus,id2word=dictionary,num_topics=num_topics,random_state=random_state)
for e, values in enumerate(self.lda.inference(corpus)[0]):
print(self.content[e])
for ee, value in enumerate(values):
print('\t分类%d推断值%.2f' % (ee, value))
# 过滤停用词
def drop_stopwords(self,contents,stopwords):
contents_clean = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
contents_clean.append(line_clean)
return contents_clean
def cut_word(self) -> list:
#分词
content_S = []
for line in self.content:
current_segment = [w for w in jieba.cut(line) if len(w)>1]
if len(current_segment) > 1 and current_segment != '\r\t':
content_S.append(current_segment)
#分词结果转为DataFrame
df_content = pd.DataFrame({'content_S':content_S})
# 停用词列表
stopwords = pd.read_table('stop_words.txt',names = ['stopword'],quoting = 3)
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
self.contents_clean = self.drop_stopwords(contents,stopwords)
if __name__ == '__main__':
title1="乾坤大挪移,如何将同步阻塞(sync)三方库包转换为异步非阻塞(async)模式?Python3.10实现。"
title2="Generator(生成器),入门初基,Coroutine(原生协程),登峰造极,Python3.10并发异步编程async底层实现"
title3="周而复始,往复循环,递归、尾递归算法与无限极层级结构的探究和使用(Golang1.18)"
title4="彩虹女神跃长空,Go语言进阶之Go语言高性能Web框架Iris项目实战-JWT和中间件(Middleware)的使用EP07"
content = [title1,title2, title3,title4]
lr = LdaRec(content)
lr.cut_word()
lr.train()
lr.lda.save('mymodel.model')
lr.test_text("巧如范金,精比琢玉,一分钟高效打造精美详实的Go语言技术简历(Golang1.18)")
至此,基于聚类的推荐系统构建完毕,每一篇文章只需要通过既有分类模型进行训练,推断分类之后,给用户推送同一分类下的文章即可,截止本文发布,该分类模型已经在本站进行落地实践:

结语
金无足赤,LDA聚类算法也不是万能的,LDA聚类算法有许多超参数,包括主题个数、学习率、迭代次数等,这些参数的设置对结果有很大影响,但是很难确定最优参数,同时聚类算法的时间复杂度是O(n^2)级别的,在处理大规模文本数据时,计算速度较慢,反之,在样本数据较少的情况下,模型的泛化能力较差。最后,奉上项目地址,与君共觞:https://github.com/zcxey2911/Lda-Gensim-Recommended-System-Python310