LSTM (long short-term memory) 长短期记忆网络,具体理论的就不一一叙述,直接开始
流程
- 一、数据导入
- 二、数据归一化
- 三、划分训练集、测试集
- 四、划分标签和属性
- 五、转换成 LSTM 输入格式
- 六、设计 LSTM 模型
- 6.1 直接建模
- 6.2 找最好
- 七、测试与图形化展示
- 八、保存模型到 pkl 文件
- 九、模型调用
- 9.1 Python 模型调用端
- 9.2 Java 程序调用端
一、数据导入
- 正常的 pandas 读取数据,将时间列转成索引(看其他教程这样做,感觉没啥用,按照时间顺序就行)
# 获取数据
import pandas as pd
from datetime import datetime
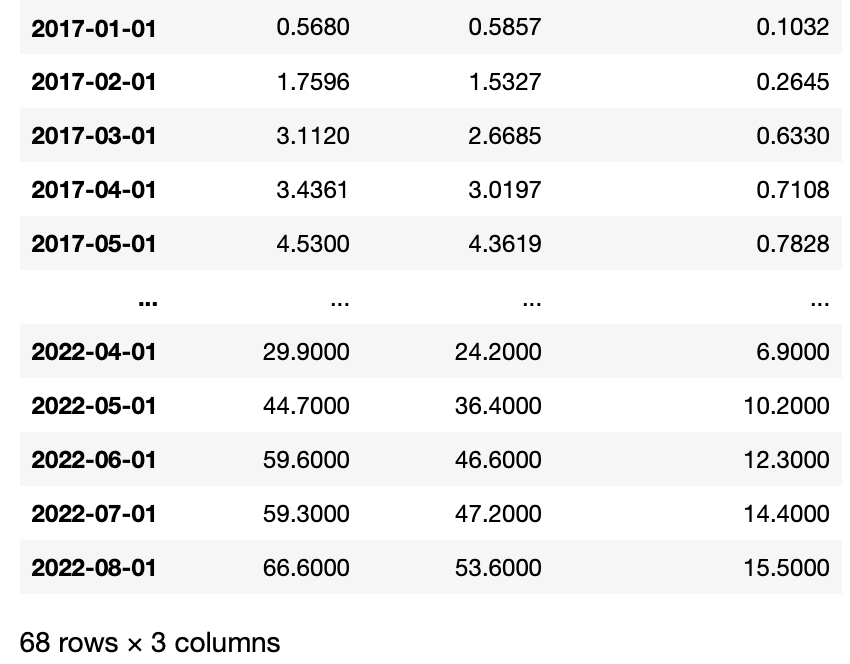
dataset = pd.read_csv('../data.csv', index_col='时间', usecols=[0,2,3,5], date_parser=lambda x:datetime.strptime(x, '%Y年%m月'))
dataset
二、数据归一化
- 将数据缩小到 0-1 范围,我这里将所有数据归到一列来,这样缩小范围就是一样的,后续可以直接用这个来转换
# 数据归一化
from sklearn.preprocessing import MinMaxScaler
values = dataset.values
# 转换成一列
values_res = values.reshape(values.shape[0] * values.shape[1], 1)
scaler = MinMaxScaler(feature_range=(0, 1))
# 训练 scaler
scaled = scaler.fit_transform(values_res)
# 再转换成原来的样子
scaled_dataset = scaled.reshape(values.shape)
scaled_dataset

三、划分训练集、测试集
- 数据需要按照时间顺序,所以这里之前前后切割 20%
# 切分训练集和测试集
split = round(len(scaled_dataset)*0.20)
train = scaled_dataset[:-split]
test = scaled_dataset[-split:]
test

四、划分标签和属性
- 数据的第一列是标签数据,第二三列是属性条件数据
# 划分标签和属性
train_x, train_y = train[:, 1:], train[:, 0]
test_x, test_y = test[:, 1:], test[:, 0]
test_x

五、转换成 LSTM 输入格式
- 转为LSTM模型的输入格式(samples, timesteps, features)
train_x_input = train_x.reshape((train_x.shape[0], 1, train_x.shape[1]))
test_x_input = test_x.reshape((test_x.shape[0], 1, test_x.shape[1]))
test_x_input

六、设计 LSTM 模型
- 设计 LSTM 模型有两个方式,第一个是知道最佳参数是什么,第二个是多输入几个参数,然后找到最佳参数
6.1 直接建模
# 设计 LSTM 模型
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(50, input_shape=(1, 2)))
model.add(Dense(1))
model.compile(loss="mae", optimizer="adam")
model.fit(train_x_input, train_y, epochs=10, batch_size=1, validation_data=(test_x_input, test_y), verbose=2, shuffle=False)
6.2 找最好
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import GridSearchCV
def build_model(optimizer):
grid_model = Sequential()
grid_model.add(LSTM(50,return_sequences=True,input_shape=(1,2)))
grid_model.add(LSTM(50))
grid_model.add(Dropout(0.2))
grid_model.add(Dense(1))
grid_model.compile(loss = 'mse',optimizer = optimizer)
return grid_model
grid_model = KerasRegressor(build_fn=build_model,verbose=1,validation_data=(test_x_input,test_y))
# 把各种可能的参数都丢上去
parameters = {'batch_size' : [1],
'epochs' : [10,11],
'optimizer' : ['adam', 'rmsprop'] }
grid_search = GridSearchCV(estimator = grid_model,
param_grid = parameters,
cv = 2)
# 训练
grid_search = grid_search.fit(train_x_input, train_y)
# 最好的参数
print(grid_search.best_params_)
# 最好参数对应的模型
model = grid_search.best_estimator_.model
七、测试与图形化展示
from matplotlib import pyplot as plt
from sklearn.metrics import mean_squared_error
import math
# 测试
pred = model.predict(test_x_input)
# 获取原始值
real = scaler.inverse_transform(test_y.reshape(1, -1)).reshape(-1, 1)
predicted = scaler.inverse_transform(pred)
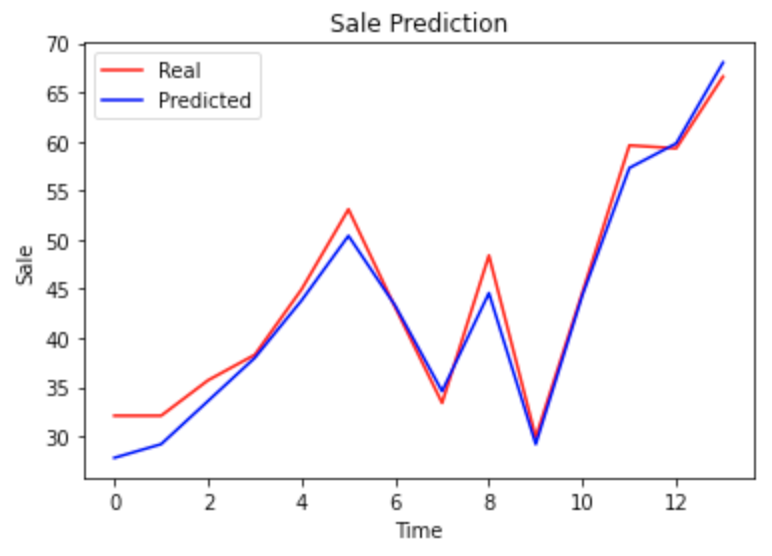
plt.plot(real, color = 'red', label = 'Real')
plt.plot(predicted, color = 'blue', label = 'Predicted')
plt.title('Sale Prediction')
plt.xlabel('Time')
plt.ylabel('Sale')
plt.legend()
plt.show()
rmse = math.sqrt(mean_squared_error(real, predicted))
print("均方根误差:" + str(rmse))
均方根误差:2.1375958318221455
八、保存模型到 pkl 文件
# 保存模型
import dill
with open('./sale_predict_model.pkl', 'wb') as outfile:
dill.dump({
'scaler': scaler,
'model': model
}, outfile)
九、模型调用
- 模型要部署到线上进行调用,直接可以写一个脚本进行调用,同时考虑到每次调用都要读取一次模型,浪费性能,直接使用 Socket 形式传参,后台形成一个常驻服务
- Socket 固定传入格式 “a,b"
9.1 Python 模型调用端
import socket
import threading
import numpy as np
import pickle
# Socket 操作
sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sk.bind(('127.0.0.1', 10001))
sk.listen(5)
count = 0
# 读取模型
file = 'sale_predict_model.pkl'
with open(file, 'rb') as f:
model = pickle.load(f)
# 模型预测
def predict(a, b):
data = np.array([[a, b]])
# 转换格式,使用的是模型训练时训练出来的编译器
data_scaled = model['scaler'].transform(data.reshape(data.shape[0] * data.shape[1], 1)).reshape(data.shape)
# 直接导入模型,一样要进行转换格式
data_res = model['model'].predict(data_scaled.reshape((data_scaled.shape[0], 1, data_scaled.shape[1])))
# 返回最终结果
return model['scaler'].inverse_transform(data_res)[0][0]
# 处理 Socket 连接
def tcp(sock, addr):
try:
print('Accept new connection from %s:%s...' % addr)
print('Request count: %d' % count)
# 读取参数
data = sock.recv(1024)
# 解码参数
data_str = data.decode('utf-8')
print("Param: %s" % data_str)
# 切割参数
data_list = data_str.split(',')
# 判断参数合法性
if len(data_list) == 2:
# 合法参数调用模型并返回数据
sock.send(str(predict(data_list[0], data_list[1])).encode('utf-8'))
print("Invoke success")
else:
sock.send(('Error param: %s' % data_str).encode('utf-8'))
print('Error param: %s' % data_str)
except Exception as e:
print('Except:', e)
sock.send('Invoke error'.encode('utf-8'))
finally:
sock.close()
if __name__ == '__main__':
while True:
# 监听连接
data, addr = sk.accept()
count += 1
# 交给线程处理
thread = threading.Thread(target=tcp, args=(data, addr))
# 启动线程
thread.start()
9.2 Java 程序调用端
package org.example.service;
import java.io.IOException;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
public class InvokeModel {
// service 测试
public static void main(String[] args){
System.out.println(invoke(54.4, 14.4));
}
// service 调用方法
public static String invoke(Double sale1, Double sale2) {
// 拼装参数
String req = sale1 + "," + sale2;
Socket socket = null;
try {
// 创建 Socket
socket = new Socket("127.0.0.1", 10001);
// 传输数据
socket.getOutputStream().write(req.getBytes(StandardCharsets.UTF_8));
System.out.println("Request param: " + req);
byte[] buf = new byte[256];
// 读取返回的数据
int len = socket.getInputStream().read(buf);
// 返回最终的结果(是一个 Double,方便操作直接用 String)
return new String(buf, 0, len);
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
try {
if (socket != null)
socket.close();
} catch (IOException e) {
System.err.println("Invoke model error");
}
}
}
}