前言
作者:小蜗牛向前冲
如果觉的博主的文章还不错的话,还请
点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正
目录
一、表的增删查改
1、表的创建
2、表的查看
3、表的修改
4、表的删除
二、字段的类型
1、数据类型
2、tinyint类型
3、bit类型
4、float类型
5、decimal类型
5、字符类型
6、日期和时间类型
7、enum和set
对表的增删查改,字段的类型:tinyint,bit,float,decimal,字符,日期和时间,enum,set类型。
一、表的增删查改
1、表的创建
语法:
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎说明:
- field 表示列名 datatype 表示列的类型
- character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
- collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
创建表案例
在创建表的时候我们要先建立库:库的建立不懂可以看这里(传送门)
这里我们建立了一个test1的数据库,并且use test。
在我们建库后在下面的路径下,可以看到的test1库,其实就是一个目录(查看这里需要root权限su -)
/var/lib/mysql 进入到目录里面后,默认只要一个db.opt的文件,里面配置了默认的字符集和校验规则。
了解完这些,我们继续来创建表
create table users(
name varchar(20) comment '用户名字',
password char(32) comment '用户密码',
birthday date comment '生日'
) charset=utf8 collate=utf8_general_ci engine=MyIsam;

说明:
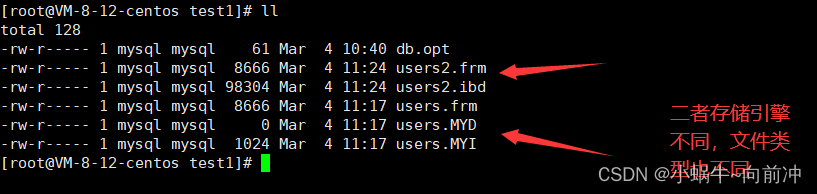
- 不同的存储引擎,创建表的文件不一样。
- users 表存储引擎是 MyISAM ,在数据目中有三个不同的文件,分别是:
- users.frm:表结构 users.MYD:表数据 users.MYI:表索引
这里我们继续创建users2 ,但我们改用了InnoDB存储引擎
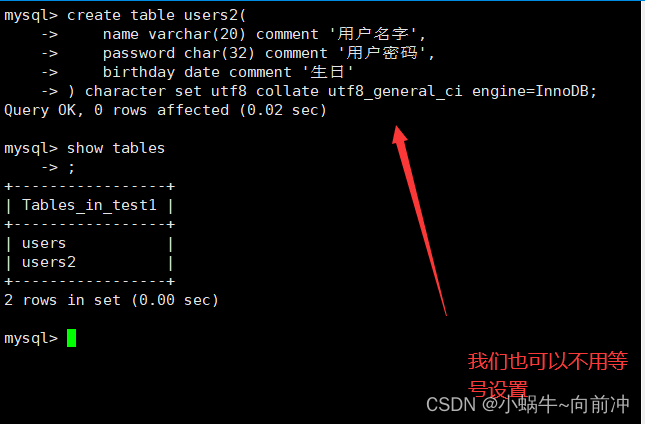
这里我们继续在数据库test1的目录下查看发现,存储引擎的不同,其实就是文件类型的不同。
 2、表的查看
2、表的查看
语法:
desc 表名;这里我们分别查看一下我们上面创建的users和users2

Field:表示字段名字
Type:表示字段的类型
当然我们也可以用下面命令查看建表的细节
show create table users \G
当我们怎么发现和我们写的代码好像,不一样?
这是因为mysql会对我们的命令进行词法语法的分析,优化成mysql的标准。
3、表的修改
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型, 表的存储引擎等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。
语法:
ALTER TABLE tablename ADD (column datatype [DEFAULT expr][,column
datatype]...);
ALTER TABLE tablename MODIfy (column datatype [DEFAULT expr][,column
datatype]...);
ALTER TABLE tablename DROP (column);案例:
将users表名字改为user1
alter table users renmae to user1;
在表中添加数据:
insert into user1 values('张三','123456','2001-2-24');
insert into user1 values('李四','242421','2012-2-1');
查看表中信息
select * from user1
在user1表添加一个字段(添加列),用于保存图片路径
alter table user1 add image_path varchar(128) comment '这是用户头像的路径' after birthday;
插入数据后是对原来数据没有影响的
删除password列
alter table user1 drop password;
删除字段一定要小心,删除字段及其对应的列数据都没了

修改name,将其长度改成60
alter table user1 modify name varchar(60);

将name列修改为xingming
alter table user1 change name xingming varchar(60);
注意这里新的字段要完整定义


4、表的删除
语法:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...这里我们删除我们以前建的users2
drop table users2;
二、字段的类型
1、数据类型
MySQL支持多种数据类型,这些类型可以分为几个主要的类别,包括数值类型、日期和时间类型、字符串类型、二进制类型等。以下是MySQL中常见的数据类型:
整数类型:
TINYINT: 1字节,范围从-128到127(有符号),0到255(无符号)。SMALLINT: 2字节,范围从-32,768到32,767(有符号),0到65,535(无符号)。MEDIUMINT: 3字节,范围从-8,388,608到8,388,607(有符号),0到16,777,215(无符号)。INT或INTEGER: 4字节,范围从-2^31到2^31-1(有符号),0到2^32-1(无符号)。BIGINT: 8字节,范围从-2^63到2^63-1(有符号),0到2^64-1(无符号)。
小数类型:
FLOAT: 单精度浮点数。DOUBLE或REAL: 双精度浮点数。DECIMAL或NUMERIC: 固定小数点数。
日期和时间类型:
DATE: 日期,格式为'YYYY-MM-DD'。TIME: 时间,格式为'HH:MM:SS'。DATETIME: 日期和时间,格式为'YYYY-MM-DD HH:MM:SS'。TIMESTAMP: 时间戳,表示自1970年1月1日以来的秒数。YEAR: 年份,格式为'YYYY'。
字符串类型:
HAR: 定长字符串。VARCHAR: 变长字符串。TEXT: 长文本字符串。ENUM: 枚举类型。SET: 集合类型。
二进制类型:
BINARY: 定长二进制数据。VARBINARY: 变长二进制数据。BLOB: 二进制大对象,用于存储大量数据。
下面进行一些比较常见类型的介绍

2、tinyint类型
我们创建一个tinyint类型的数据(取值范围:-128~127),进行插入测试:
create table t1(num tinyint)
insert into t1 values(-128);
nsert into t1 values(127);
insert into t1 values(66);
insert into t1 values(-666);
select * from t1;

- 在MySQL中,整型可以指定是有符号的和无符号的,默认是有符号的。
- 可以通过UNSIGNED来说明某个字段是无符号的
比如上面例子:只要在 创建t2的指定为为无符号的类型就可以了。
create table t1(num tinyint unsigned)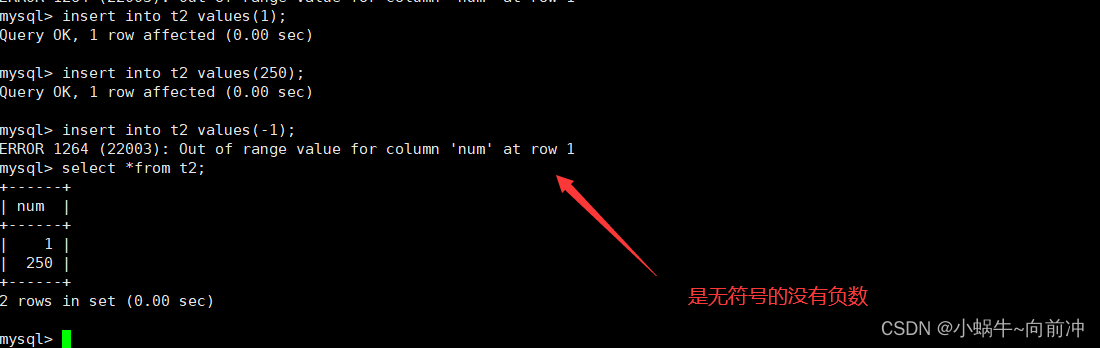
注意:我们在使用unsigned要根据场景来使用尽可能的节约资源。
3、bit类型
基本语法:
bit[(M)] : 位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。
举例:
create table t3(id int,online bit(1));
insert into t3 (id,online) values(123,0);
insert into t3 (id,online) values(456,1);
insert into t3 (id,online) values(124,4);
desc t3;
select *from t3;
 这里我们创建了标t3里面online是bit位图类型,0就表示用户不在线,1表示在线
这里我们创建了标t3里面online是bit位图类型,0就表示用户不在线,1表示在线
bit字段在显示时,是按照ASCII码对应的值显示。这里我们继续把位图改大
并且分别以ASCII码对应的值显示和十进制显示。
alter table t3 modify online bit(64);
insert into t3 (id,online) values(234,42);
desc t3;
select *from t3;
select id,hex(online) from t3;

4、float类型
语法:
float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节
案例
小数:float(4,2)表示的范围是-99.99 ~ 99.99,MySQL在保存值时会进行四舍五入。
这里我们继续创建表t4,并且对里面数据进行插入内容,salary我们设置为float型。
insert into t4(id,salary) values(1,99.99);
insert into t4(id,salary) values(2,-99.99);
insert into t4(id,salary) values(3,23.23);
insert into t4(id,salary) values(3,2.123);
insert into t4(id,salary) values(3,100);
insert into t4(id,salary) values(3,2.129);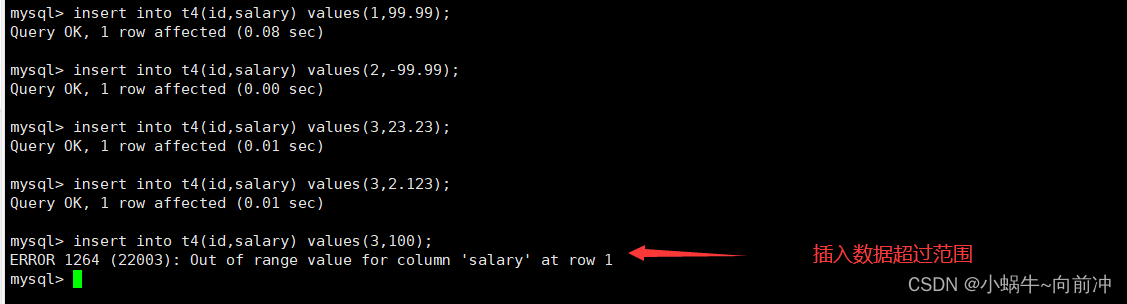 当我们对salary插入100肯定是被mysql约束不允许插入的,但我们也可以观察到float类型是有四舍五入的。
当我们对salary插入100肯定是被mysql约束不允许插入的,但我们也可以观察到float类型是有四舍五入的。

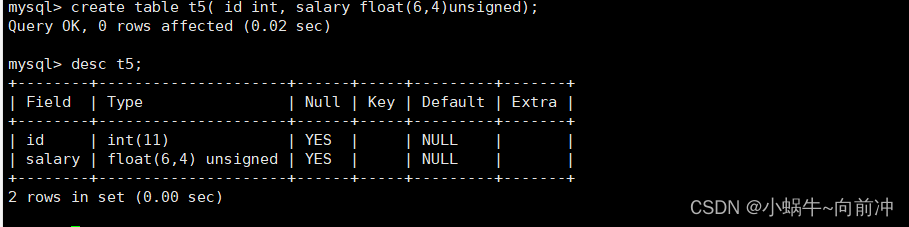
这里我继续建立t5试试float类型的无符号类型
如果定义的是float(6,4) unsigned 这时,因为把它指定为无符号的数,范围是 0 ~ 99.99
为表插入一些数据
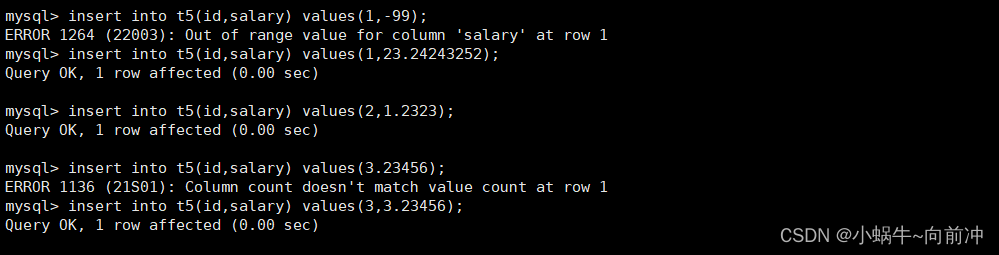
seletc *from t5;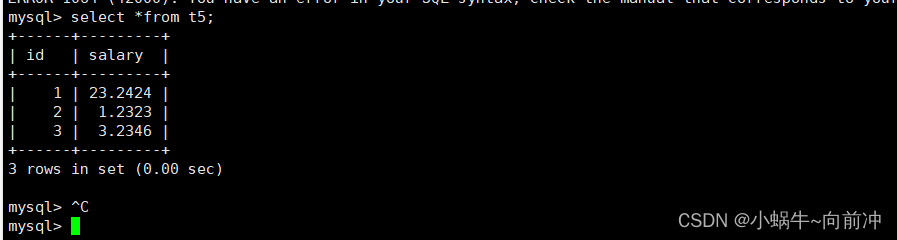
5、decimal类型
语法:
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数
- decimal(5,2) 表示的范围是 -999.99 ~ 999.99
- decimal(5,2) unsigned 表示的范围 0 ~ 999.99
- decimal和float很像,但是有区别: float和decimal表示的精度不一样
这里我们分别插入数据:
insert into t6(id,salary1,salary2) values(1, 25.12345678,25.12345678);

明明我们插入的值是一样的,但是salary1和salary2存储的值却不一样,这是因为, float表示的精度大约是7位。而decimal的精度却很高。
- decimal整数最大位数m为65。支持小数最大位数d是30。如果d被省略,默认为0.如果m被省略, 默认是10
- 建议:如果希望小数的精度高,推荐使用decimal。
5、字符类型
char语法:
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255
但是我们这里要注意的是,这里说的是字符长度不是子节长度 。
char(1),可以插入1字母,也可1个中文(在UTF8的校验码占三个字节)。
举例:
varcahr语法:
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节
关于varchar(len),len到底是多大,这个len值,和表的编码密切相关:
- varchar长度可以指定为0到65535之间的值,但是有1 - 3 个字节用于记录数据大小,所以说有效字 节数是65532。
- 当我们的表的编码是utf8时,varchar(n)的参数n最大值是65532/3=21844[因为utf中,一个字符占 用3个字节],如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符 占用2字节)。
见一见 varcahr
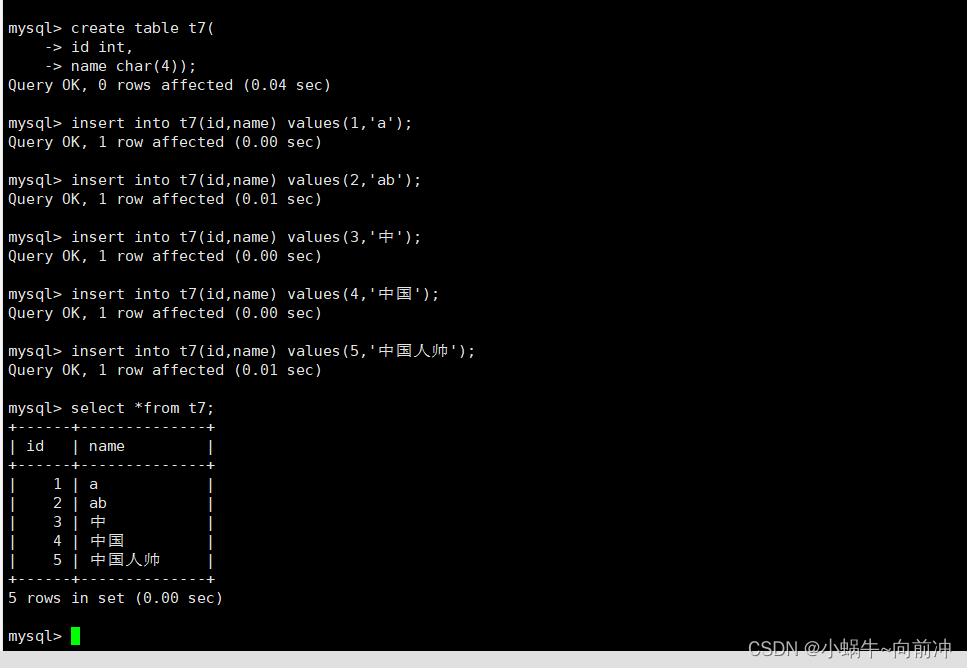
create table t8( id int, name varchar(4));
insert into t8(id,name) values(1,'小明');
insert into t8(id,name) values(2,'中国是我心中最好的国家');//error
mysql> alter table t8 modify name varchar(65535);//1:error
mysql> alter table t8 modify name varchar(21845);//2:error
mysql> alter table t8 modify name varchar(21843);//3:error
alter table t8 modify name varchar(21842);
insert into t8(id,name) values(2,'中国是我心中最好的国家');
select *from t8;
这里我在修改 varcahr大小的时候报了三次错误,
错误1,2上面已经解释过了,但是为什么我明明都已经预留了存放1 - 3 个字节用于记录数据大小的字节数,还是报错误3,那是因为id也在同一行中,也会占字节大小。

char和varcahr比较
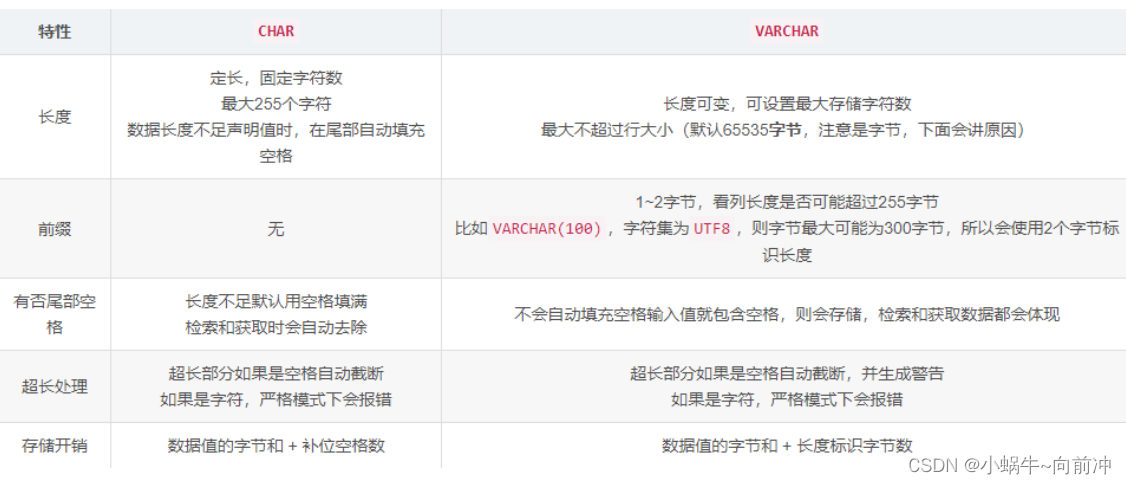
如何选择定长或变长字符串?
- 如果数据确定长度都一样,就使用定长(char),比如:身份证,手机号。
- 如果数据长度有变化,就使用变长(varchar), 比如:名字,地址。
- 但是你要保证最长的能存的进去。 定长的磁盘空间比较浪费,但是效率高。
- 变长的磁盘空间比较节省,但是效率低。
- 定长的意义是,直接开辟好对应的空间。
- 变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
6、日期和时间类型
常用的日期有如下三个:
- date :日期 'yyyy-mm-dd' ,占用三字节
- datetime 时间日期格式 'yyyy-mm-dd HH:ii:ss' 表示范围从 1000 到 9999 ,占用八字节
- timestamp :时间戳,从1970年开始的 yyyy-mm-dd HH:ii:ss 格式和 datetime 完全一致,占用 四字节
举例:
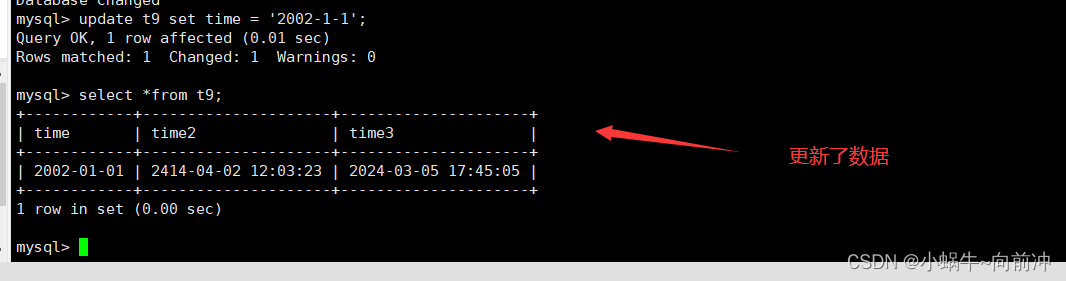
create table t9( time date, time2 datetime, time3 timestamp);
insert into t9(time,time2) values('1990-2-4','2414-4-2 12:3:23');
select *from t9;

update t9 set time = '2002-1-1';
select *from t9;
更新了time的数据,其中tiem3时间戳的数据也会更新。
7、enum和set
语法:
enum:枚举,“单选”类型; enum('选项1','选项2','选项3',...);、
该设定只是提供了若干个选项的值,最终一个单元格中,实际只存储了其中一个值;而且出于效率考 虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,3,....最多65535 个;当我们添加枚举值时,也可以添加对应的数字编号。
set:集合,“多选”类型; set('选项值1','选项值2','选项值3', ...);
该设定只是提供了若干个选项的值,最终一个单元格中,设计可存储了其中任意多个值;而且出于效率 考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,4,8,16,32,.... 最多64个。
案例:
create table votes( username varchar(20),
gender enum('男','女'),
hobby set('跑步','美食','看电影','打球')
);
insert into votes values('张三','男','跑步');
insert into votes values('李四','女','美食');
insert into votes values('赵六','男','3');
insert into votes values('老陈','1','打球,看电影,跑步');
select * from votes;
为什么我在存存放赵六hobby的时候,填3会存放的是跑步,而填老陈性别写1会是男。
因为这些是存放在放在位图中的,对赵六
爱好有4个所以对应的位图是0000;变1就是有这个爱好
当我们填3--->位图0011。而位图中不就是表示赵六的爱好为跑步和美食。
对来陈
性别有二种:位图为00,变1就是对应的选择(男或者女)
填1--->位图01。位图就表示男。
enum和set的选择
select * from votes where hobby='美食';

但是这样我们仅仅查到了有美食爱好的只有李四,赵六不也是有这个爱好吗
因为这语句过滤出了所有"hobby"列值为"美食"的行,如果含义其他的就查出来了。
集合查询使用find_ in_ set函数:
- find_in_set(sub,str_list) :
- 如果 sub 在 str_list 中,则返回下标;
- 如果不在,返回0; str_list 用逗号分隔的字符串。
select * from votes where find_in_set('美食', hobby);
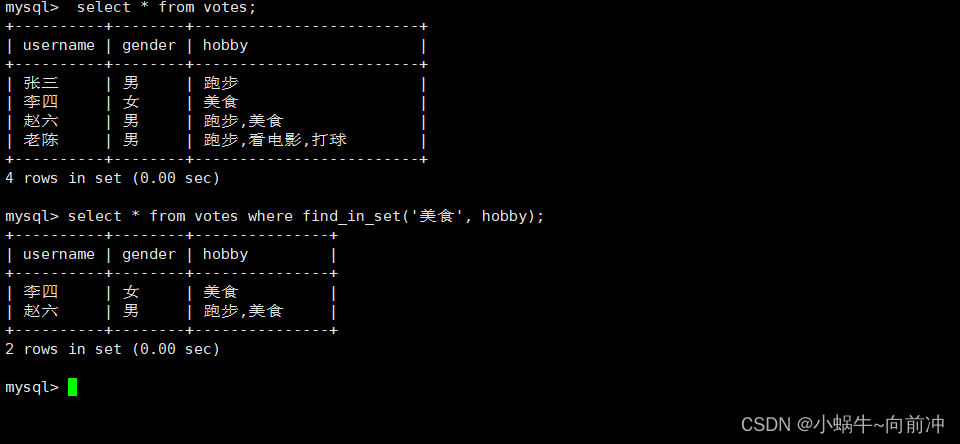
通过find_in_set就可以找到我们想要的分类。
![[力扣 Hot100]Day48 路径总和 III](https://img-blog.csdnimg.cn/direct/be2278fcc40b4f53b52f232651de210c.png)