一、多线程设计
1、在一个新线程中调用了 scan_face() 函数来进行人脸识别操作。根据识别结果,更新界面显示结果,最后释放资源。
def f_scan_face_thread():
var.set('刷脸')
ans = scan_face()
if ans == 0:
print("最终结果:无法识别")
var.set("最终结果:无法识别")
else:
ans_name = "最终结果:" + str(ans) + id_dict[ans]
print(ans_name)
var.set(ans_name)
global system_state_lock
print("锁被释放0")
system_state_lock = 0 #释放资源2、检查当前系统状态,如果可以开始人脸识别,则将 system_state_lock 设置为1,并启动 f_scan_face_thread() 线程进行人脸识别。
def f_scan_face():
global system_state_lock
print("\n当前锁的值为:" + str(system_state_lock))
if system_state_lock == 1:
print("阻塞,因为正在刷脸")
return 0
elif system_state_lock == 2: # 如果正在录入新面孔就阻塞
print("\n刷脸被录入面容阻塞\n" "")
return 0
system_state_lock = 1
p = threading.Thread(target=f_scan_face_thread)
p.setDaemon(True)
p.start()3、在一个新线程中执行录入新人脸的操作。它增加已知人脸数量,采集新的人脸数据,训练模型,然后修改配置文件并释放资源。
def f_rec_face_thread():
var.set('录入')
cv2.destroyAllWindows()
global Total_face_num
Total_face_num += 1
Get_new_face()
print("采集完毕,开始训练")
global system_state_lock
print("锁被释放0")
system_state_lock = 0
Train_new_face()
write_config() 4、检查系统状态并开始人脸录入操作。如果当前没有其他操作在进行中,将 system_state_lock 设为2 ,并开始 f_rec_face_thread() 线程执行录入操作。
def f_rec_face():
global system_state_lock
print("当前锁的值为:" + str(system_state_lock))
if system_state_lock == 2:
print("阻塞,因为正在录入面容")
return 0
else:
system_state_lock = 2 # 修改system_state_lock
print("改为2", end="")
print("当前锁的值为:" + str(system_state_lock))
p = threading.Thread(target=f_rec_face_thread)
p.setDaemon(True)
p.start()5、退出程序
def f_exit():
exit()二、GUI界面设计
1、基于 `tkinter` 的图形用户界面 (GUI) 应用程序
创建一个窗口 `window` 并设置了标题和大小。
创建一个标签 `Label`,用于在窗口中显示一些提示信息。
设置了三个按钮 `Button`,分别用于开始人脸识别 (`f_scan_face`)、录入人脸 (`f_rec_face`) 和退出程序 (`f_exit`)。
将按钮放置在窗口的特定位置,并通过 `command` 参数将按钮与对应的功能函数绑定。
创建了一个空白的 `Label` 控件 `panel`,可能会用于显示摄像头捕获的图像。
设置了鼠标光标为箭头样式。
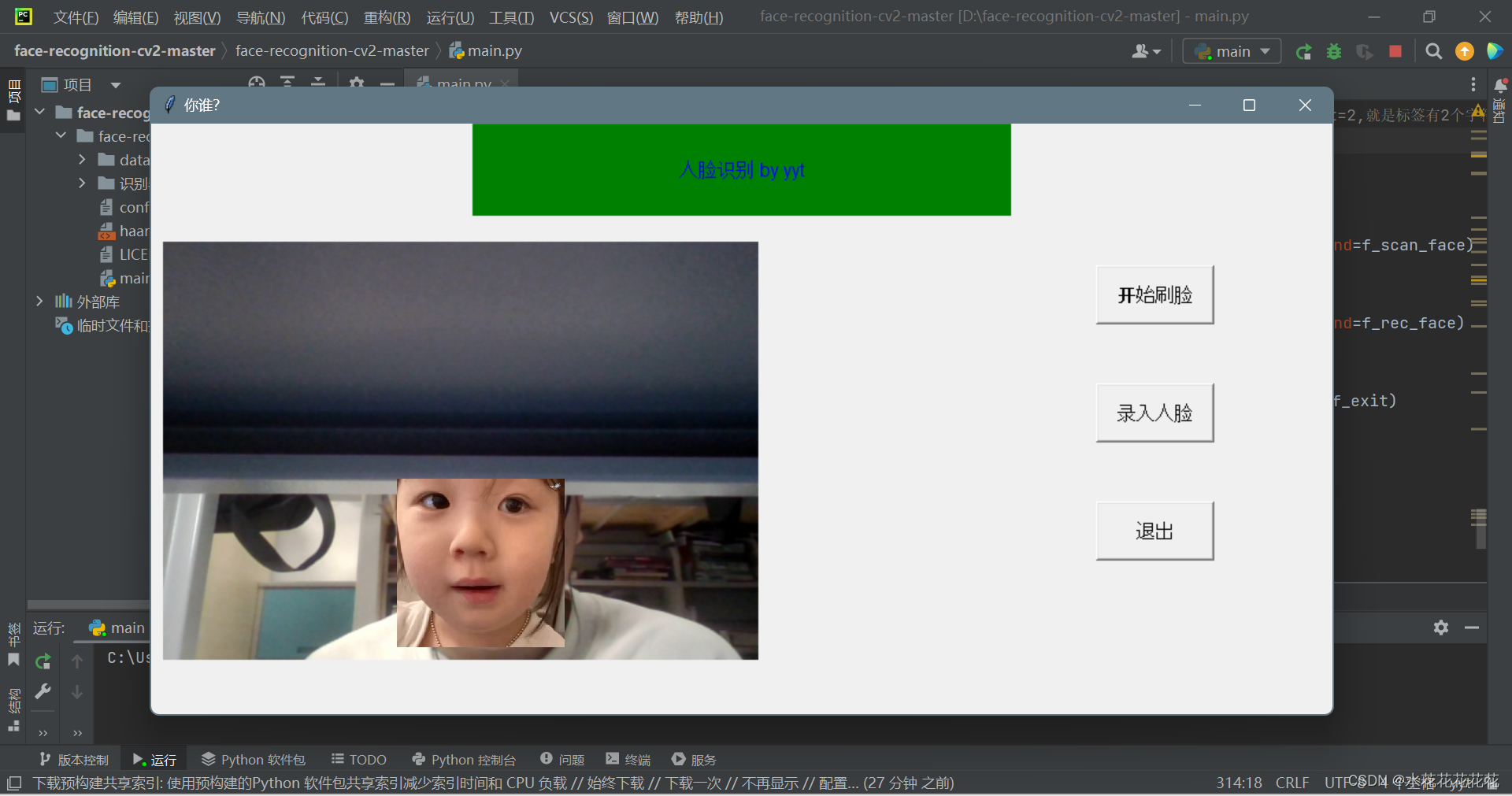
window = tk.Tk()
window.title('你谁?')
window.geometry('1000x500')
var = tk.StringVar()
l = tk.Label(window, textvariable=var, bg='green', fg='blue', font=('Arial', 12), width=50, height=4)
l.pack()
var.set('人脸识别 by yyt')
button_a = tk.Button(window, text='开始刷脸', font=('Arial', 12), width=10, height=2, command=f_scan_face)
button_a.place(x=800, y=120)
button_b = tk.Button(window, text='录入人脸', font=('Arial', 12), width=10, height=2, command=f_rec_face)
button_b.place(x=800, y=220)
button_c = tk.Button(window, text='退出', font=('Arial', 12), width=10, height=2, command=f_exit)
button_c.place(x=800, y=320)
panel = tk.Label(window, width=500, height=350)
panel.place(x=10, y=100)
window.config(cursor="arrow")2、函数首先检查全局变量 `success` 是否为真,即摄像头捕获图像成功。 如果成功,将捕获到的图像 `img` 转换成 RGBA 格式,并创建一个 `ImageTk` 对象 `imgtk` 用于在 `panel` 中显示。更新 `panel` 的图像内容,显示最新捕获到的图像。最后使用 `window.after(1, video_loop)` 实现持续更新,以实现动态展示摄像头内容。
def video_loop():
# success, img = camera.read()
global success
global img
if success:
cv2.waitKey(1)
cv2image = cv2.cvtColor(img, cv2.COLOR_BGR2RGBA)
current_image = Image.fromarray(cv2image)
imgtk = ImageTk.PhotoImage(image=current_image)
panel.imgtk = imgtk
panel.config(image=imgtk)
window.after(1, video_loop)最终效果
 参考项目源码:https://gitee.com/Cheney822/face-recognition-cv2
参考项目源码:https://gitee.com/Cheney822/face-recognition-cv2